面試回答:MySQL每張表最好不超過2000萬資料,對不對?
事情是這樣的
下面是我朋友的面試記錄:
面試官:講一下你實習做了什麼。
朋友:我在實習期間做了一個儲存使用者操作記錄的功能,主要是從MQ獲取上游服務傳送過來的使用者操作資訊,然後把這些資訊存到MySQL裡面,提供給數倉的同事使用。
朋友:由於資料量比較大,每天大概有四五千多萬條,所以我還給它做了分表的操作。每天定時生成3張表,然後將資料取模分別存到這三張表裡,防止表內資料過多導致查詢速度降低。
這表述,好像沒什麼問題是吧,別急,接著看:
面試官:那你為什麼要分三張表呢,兩張表不行嗎?四張表不行嗎?
朋友:因為MySQL每張表最好不超過2000萬條資料,否則會導致查詢速度降低,影響效能。我們每天的資料大概是在五千萬條左右,所以分成三張表比較穩妥。
面試官:還有嗎?
朋友: 沒有了……你幹嘛,哎呦
面試官:那你先回去等通知吧。
講完了,看出什麼了嗎,你們覺得我這位朋友回答的有什麼問題嗎?
前言
很多人說,MySQL每張表最好不要超過2000萬條資料,否則就會導致效能下降。阿里的Java開發手冊上也提出:單錶行數超過 500 萬行或者單表容量超過 2GB,才推薦進行分庫分表。
但實際上,這個2000萬或者500萬都只是一個大概的數位,並不適用於所有場景,如果盲目的以為表資料只要不超過2000萬條就沒問題了,很可能會導致系統的效能大幅下降。
實際情況下,每張表由於自身的欄位不同、欄位所佔用的空間不同等原因,它們在最佳效能下可以存放的資料量也就不同。
那麼,該如何計算出每張表適合的資料量呢?別急,慢慢往下看。
本文適合的讀者
閱讀本文你需要有一定的MySQL基礎,最好對InnoDB和B+樹都有一定的瞭解,可能需要有一年以上的MySQL學習經驗(大概一年?),知道 「InnoDB中B+樹的高度一般保持在三層以內會比較好」 這條理論知識。
本文主要是針對 「InnoDB中高度為3的B+樹最多可以存多少資料」 這一話題進行講解的。且本文對資料的計算比較嚴格(至少比網上95%以上的相關博文都要嚴格),如果你比較在意這些細節並且目前不太清楚的話,請繼續往下閱讀。
閱讀本文你大概需要花費10-20分鐘的時間,如果你在閱讀的過程中對資料進行驗算的話,可能要花費30分鐘左右。
本文思維導圖
千萬級資料並行如何處理?進入學習
基礎知識快速回顧
眾所周知,MySQL中InnoDB的儲存結構是B+樹,B+樹大家都熟悉吧?特性大概有以下幾點,一起快速回顧一下吧!
注:下面這這些內容都是精華,看不懂或者不理解的同學建議先收藏本文,之後有知識基礎了再回來看。??
一張資料表一般對應一顆或多顆樹的儲存,樹的數量與建索引的數量有關,每個索引都會有一顆單獨的樹。
聚簇索引和非聚簇索引:
主鍵索引也是聚簇索引,非主鍵索引都是非聚簇索引。除格式資訊外,兩種索引的非葉子節點都是隻存索引資料的,比如索引為id,那非葉子節點就是存的id資料。
葉子節點的區別如下:
- 聚簇索引的葉子節點一般情況下存的是這條資料的所有欄位資訊。所以我們
select * from table where id = 1的時候,都是要去葉子節點拿資料的。 - 非聚簇索引的葉子節點存的是這條資料所對應的主鍵和索引列資訊。比如這條非聚簇索引是username,然後表的主鍵是id,那該非聚簇索引的葉子節點存的就是 username 和 id,而不存其他欄位。 相當於是先從非聚簇索引查到主鍵的值,再根據主鍵索引去查資料內容,一般情況下要查兩次(除非索引覆蓋),這也稱之為 回表 ,就有點類似於存了個指標,指向了資料存放的真實地址。
- 聚簇索引的葉子節點一般情況下存的是這條資料的所有欄位資訊。所以我們
B+樹的查詢是從上往下一層層查詢的,一般情況下我們認為B+樹的高度保持在3層以內是比較好的,也就是上兩層是索引,最後一層存資料,這樣查表的時候只需要進行3次磁碟IO就可以了(實際上會少一次,因為根節點會常駐記憶體),且能夠存放的資料量也比較可觀。
如果資料量過大,導致B+數變成4層了,則每次查詢就需要進行4次磁碟IO了,從而使效能下降。所以我們才會去計算InnoDB的3層B+樹最多可以存多少條資料。
MySQL每個節點大小預設為16KB,也就是每個節點最多存16KB的資料,可以修改,最大64KB,最小4KB。
擴充套件:那如果某一行的資料特別大,超過了節點的大小怎麼辦?
MySQL5.7檔案的解釋是:
對於 4KB、8KB、16KB 和 32KB設定 ,最大行長度略小於資料庫頁面的一半 。例如:對於預設的 16KB頁大小,最大行長度略小於 8KB ,預設32KB的頁大小,則最大行長度略小於16KB。
而對於 64KB 頁面,最大行則長度略小於 16KB。
如果行超過最大行長度, 則將可變長度列用外部頁儲存,直到該行符合最大行長度限制。就是說把varchar、text這種長度可變的存到外部頁中,來減小這一行的資料長度。

檔案地址:
MySQL查詢速度主要取決於磁碟的讀寫速度,因為MySQL查詢的時候每次唯讀取一個節點到記憶體中,通過這個節點的資料找到下一個要讀取的節點位置,再讀取下一個節點的資料,直到查詢到需要的資料或者發現資料不存在。
肯定有人要問了,每個節點內的資料難道不用查詢嗎?這裡的耗時怎麼不計算?
這是因為讀取完整個節點的資料後,會存到記憶體當中,在記憶體中查詢節點資料的耗時其實是很短的,再配合MySQL的查詢方式,時間複雜度差不多為 ,相比磁碟IO來說,可以忽略不計。
MySQL InnoDB 節點的儲存內容
在Innodb的B+樹中,我們常說的節點被稱之為 頁(page),每個頁當中儲存了使用者資料,所有的頁合在一起組成了一顆B+樹(當然實際會複雜很多,但我們只是要計算可以存多少條資料,所以姑且可以這麼理解?)。
頁 是InnoDB儲存引擎管理資料庫的最小磁碟單位,我們常說每個節點16KB,其實就是指每頁的大小為16KB。
這16KB的空間,裡面需要儲存 頁格式 資訊和 行格式 資訊,其中行格式資訊當中又包含一些後設資料和使用者資料。所以我們在計算的時候,要把這些資料的都計算在內。
頁格式
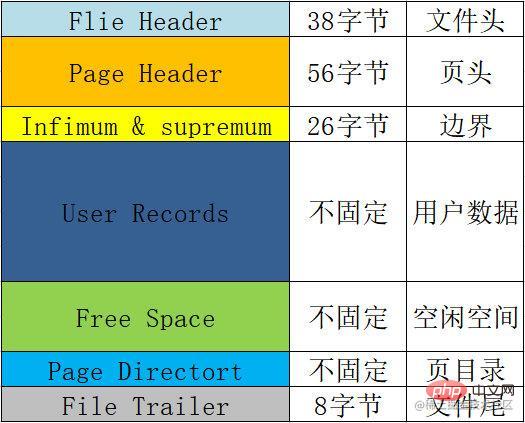
每一頁的基本格式,也就是每一頁都會包含的一些資訊,總結表格如下:
| 名稱 | 空間 | 含義和作用等 |
|---|---|---|
File Header | 38位元組 | 檔案頭,用來記錄頁的一些頭資訊。 包括校驗和、頁號、前後節點的兩個指標、 頁的型別、表空間等。 |
Page Header | 56位元組 | 頁頭,用來記錄頁的狀態資訊。 包括頁目錄的槽數、空閒空間的地址、本頁的記錄數、 已刪除的記錄所佔用的位元組數等。 |
Infimum & supremum | 26位元組 | 用來限定當前頁記錄的邊界值,包含一個最小值和一個最大值。 |
User Records | 不固定 | 使用者記錄,我們插入的資料就儲存在這裡。 |
Free Space | 不固定 | 空閒空間,使用者記錄增加的時候從這裡取空間。 |
Page Directort | 不固定 | 頁目錄,用來儲存頁當中使用者資料的位置資訊。 每個槽會放4-8條使用者資料的位置,一個槽佔用1-2個位元組, 當一個槽位超過8條資料的時候會自動分成兩個槽。 |
File Trailer | 8位元組 | 檔案結尾資訊,主要是用來校驗頁面完整性的。 |
示意圖:
頁格式這塊的內容,我在官網翻了好久,硬是沒找到?。。。。不知道是沒寫還是我眼瞎,有找到的朋友希望可以在評論區幫我掛出來?。
所以上面頁格式的表格內容主要是基於一些部落格中學習總結的。
另外,當新記錄插入到 InnoDB 聚集索引中時,InnoDB 會嘗試留出 1/16 的頁面空閒以供將來插入和更新索引記錄。如果按順序(升序或降序)插入索引記錄,則生成的頁大約可用 15/16 的空間。如果以隨機順序插入記錄,則頁大約可用 1/2 到 15/16 的空間。參考檔案:
除了 User Records和Free Space 以外所佔用的記憶體是 位元組,每一頁留給使用者資料的空間就還剩 位元組(保留了1/16)。
當然,這是最小值,因為我們沒有考慮頁目錄。頁目錄留在後面根據再去考慮,這個得根據表欄位來計算。
行格式
首先,我覺得有必要提一嘴,MySQL5.6的預設行格式為COMPACT(緊湊),5.7及以後的預設行格式為DYNAMIC(動態),不同的行格式儲存的方式也是有區別的,還有其他的兩種行格式,本文後續的內容主要是基於DYNAMIC(動態)進行講解的。
官方檔案連結:(包括下面的行格式內容大都可以在裡面找到)

每行記錄都包含以下這些資訊,其中大都是可以從官方檔案當中找到的。我這裡寫的不是特別詳細,僅寫了一些能夠我們計算空間的知識,更詳細內容可以去網上搜尋 「MySQL 行格式」。
| 名稱 | 空間 | 含義和作用等 |
|---|---|---|
| 行記錄頭資訊 | 5位元組 | 行記錄的檔頭資訊 包含了一些標誌位、資料型別等資訊 如:刪除標誌、最小記錄標誌、排序記錄、資料型別、 頁中下一條記錄的位置等 |
| 可變長度欄位列表 | 不固定 | 來儲存那些可變長度的欄位佔用的位元組數,比如varchar、text、blob等。 若變長欄位的長度小於 255位元組,就用 1位元組表示;若大於 255位元組,用 2位元組表示。表欄位中有幾個可變長欄位該列表中就有幾個值,如果沒有就不存。 |
| null值列表 | 不固定 | 用來儲存可以為null的欄位是否為null。 每個可為null的欄位在這裡佔用一個bit,就是bitmap的思想。 該列表佔用的空間是以位元組為單位增長的,例如,如果有 9 到 16 個 可以為null的列,則使用兩個位元組,沒有佔用1.5位元組這種情況。 |
| 事務ID和指標欄位 | 6+7位元組 | 瞭解MVCC的朋友應該都知道,資料行中包含了一個6位元組的事務ID和 一個7位元組的指標欄位。 如果沒有定義主鍵,則還會多一個6位元組的行ID欄位 當然我們都有主鍵,所以這個行ID我們不計算。 |
| 實際資料 | 不固定 | 這部分就是我們真實的資料了。 |
示意圖:

另外還有幾點需要注意:
溢位頁(外部頁)的儲存
注意:這一點是DYNAMIC的特性。
當使用 DYNAMIC 建立表時,InnoDB 會將較長的可變長度列(比如 VARCHAR、VARBINARY、BLOB 和 TEXT 型別)的值剝離出來,儲存到一個溢位頁上,只在該列上保留一個 20 位元組的指標指向溢位頁。
而 COMPACT 行格式(MySQL5.6預設格式)則是將前 768 個位元組和 20 位元組的指標儲存在 B+ 樹節點的記錄中,其餘部分儲存在溢位頁上。
列是否儲存在頁外取決於頁大小和行的總大小。當一行太長時,選擇最長的列進行頁外儲存,直到聚集索引記錄適合 B+ 樹頁(檔案裡沒說具體是多少?)。小於或等於 40 位元組的 TEXT 和 BLOB 直接儲存在行內,不會分頁。
優點
DYNAMIC 行格式避免了用大量資料填充 B+ 樹節點從而導致長列的問題。
DYNAMIC 行格式的想法是,如果長資料值的一部分儲存在頁外,則通常將整個值儲存在頁外是最有效的。
使用 DYNAMIC 格式,較短的列會盡可能保留在 B+ 樹節點中,從而最大限度地減少給定行所需的溢位頁數。
字元編碼不同情況下的儲存
char 、varchar、text 等需要設定字元編碼的型別,在計算所佔用空間時,需要考慮不同編碼所佔用的空間。
varchar、text等型別會有長度欄位列表來記錄他們所佔用的長度,但char是固定長度的型別,情況比較特殊,假設欄位 name 的型別為 char(10) ,則有以下情況:
對於長度固定的字元編碼(比如ASCII碼),欄位 name 將以固定長度格式儲存,ASCII碼每個字元佔一個位元組,那 name 就是佔用 10 個位元組。
對於長度不固定的字元編碼(比如utf8mb4),至少將為 name 保留 10 個位元組。如果可以,InnoDB會通過修剪尾部空格空間的方式來將其存到 10 個位元組中。
如果空格剪完了還存不下,則將尾隨空格修剪為 列值位元組長度的最小值(一般是 1 位元組)。
列的最大長度為: ,比如 name 欄位的編碼為 utf8mb4,那就是 。
大於或等於 768 位元組的 char 列會被看成是可變長度欄位(就像varchar一樣),可以跨頁儲存。例如,utf8mb4 字元集的最大位元組長度為 4,則 char(255) 列將可能會超過 768 個位元組,進行跨頁儲存。
說實話對char的這個設計我是不太理解的,儘管看了很久,包括官方檔案和一些部落格?,希望懂的同學可以在評論區解惑:
對於長度不固定的字元編碼這塊,char是不是有點像是一個長度可變的型別了?我們常用的 utf8mb4,佔用為 1 ~ 4 位元組,那麼 char(10) 所佔用的空間就是 10 ~ 40 位元組,這個變化還是挺大的啊,但是它並沒有留足夠的空間給它,也沒有使用可變長度欄位列表去記錄char欄位的空間佔用情況,就很特殊?
開始計算
好了,我們已經知道每一頁當中具體儲存的東西了,現在我們已經具備計算能力了。
由於頁的剩餘空間我已經在上面頁格式的地方計算過了,每頁會剩餘 15232 位元組可用,下面我們直接計算行。
非葉子節點計算
單個節點計算
索引頁就是存索引的節點,也就是非葉子節點。
每一條索引記錄當中都包含了當前索引的值 、 一個 6位元組 的指標資訊 、一個 5 位元組的行檔頭,用來指向下一層資料頁的指標。
索引記錄當中的指標占用空間我沒在官方檔案裡找到?,這個 6 位元組是我參考其他博文的,他們說原始碼裡寫的是6位元組,但具體在哪一段原始碼我也不知道?。
希望知道的同學可以在評論區解惑。
假設我們的主鍵id為 bigint 型,也就是8個位元組,那索引頁中每行資料佔用的空間就等於 位元組。每頁可以存 條索引資料。
那算上頁目錄的話,按每個槽平均6條資料計算的話,至少有 個槽,需要佔用 268 位元組的空間。
把存資料的空間分一點給槽的話,我算出來大約可以存 787 條索引資料。
如果是主鍵是 int 型的話,那可以存更多,大約有 993 條索引資料。
前兩層非葉子節點計算
在 B+ 樹當中,當一個節點索引記錄為 條時,它就會有 個子節點。由於我們 3 層B+樹的前兩層都是索引記錄,第一層根節點有 條索引記錄,那第二層就會有 個節點,每個節點資料型別與根節點一致,仍然可以再存 條記錄,第三層的節點個數就會等於 。
則有:
- 主鍵為 bigint 的表可以存放 個葉子節點
- 主鍵為 int 的表可以存放 個葉子節點
OK計算完畢。
資料條數計算
最少存放記錄數
前面我們提到,最大行長度略小於資料庫頁面的一半,之所以是略小於一半,是由於每個頁面還留了點空間給頁格式 的其他內容,所以我們可以認為每個頁面最少能放兩條資料,每條資料略小於8KB。如果某行的資料長度超過這個值,那InnoDB肯定會分一些資料到 溢位頁 當中去了,所以我們不考慮。
那每條資料8KB的話,每個葉子節點就只能存放 2 條資料,這樣的一張表,在主鍵為 bigint 的情況下,只能存放 條資料,也就是一百二十多萬條,這個資料量,沒想到吧??。
較多的存放記錄數
假設我們的表是這樣的:
-- 這是一張非常普通的課程安排表,除id外,僅包含了課程id和老師id兩個欄位
-- 且這幾個欄位均為 int 型(當然實際生產中不會這麼設計表,這裡只是舉例)。
CREATE TABLE `course_schedule` (
`id` int NOT NULL,
`teacher_id` int NOT NULL,
`course_id` int NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
登入後複製先來分析一下這張表的行資料:無null值列表,無可變長欄位列表,需要算上事務ID和指標欄位,需要算上行記錄頭,那麼每行資料所佔用的空間就是 位元組,每個葉子節點可以存放 條資料。
算上頁目錄的槽位所佔空間,每個葉子節點可以存放 502 條資料,那麼三層B+樹可以存放的最巨量資料量就是 ,將近5億條資料!沒想到吧??。
常規表的存放記錄數
大部分情況下我們的表欄位都不是上面那樣的,所以我選擇了一場比較常規的表來進行分析,看看能存放多少資料。表情況如下:
CREATE TABLE `blog` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '部落格id',
`author_id` bigint unsigned NOT NULL COMMENT '作者id',
`title` varchar(50) CHARACTER SET utf8mb4 NOT NULL COMMENT '標題',
`description` varchar(250) CHARACTER SET utf8mb4 NOT NULL COMMENT '描述',
`school_code` bigint unsigned DEFAULT NULL COMMENT '院校程式碼',
`cover_image` char(32) DEFAULT NULL COMMENT '封面圖',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '建立時間',
`release_time` datetime DEFAULT NULL COMMENT '首次發表時間',
`modified_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改時間',
`status` tinyint unsigned NOT NULL COMMENT '發表狀態',
`is_delete` tinyint unsigned NOT NULL DEFAULT 0,
PRIMARY KEY (`id`),
KEY `author_id` (`author_id`),
KEY `school_code` (`school_code`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_general_mysql500_ci ROW_FORMAT=DYNAMIC;
登入後複製這是我的開源專案「校園部落格」(GitHub地址:) 中的部落格表,用於存放部落格的基本資料。
分析一下這張表的行記錄:
行記錄頭資訊:肯定得有,佔用5位元組。
可變長度欄位列表:表中
title佔用1位元組,description佔用2位元組,共3位元組。null值列表:表中僅
school_code、cover_image、release_time3個欄位可為null,故僅佔用1位元組。事務ID和指標欄位:兩個都得有,佔用13位元組。
欄位內容資訊:
id、author_id、school_code均為bigint型,各佔用8位元組,共24位元組。create_time、release_time、modified_time均為datetime型別,各佔8位元組,共24位元組。status、is_delete為tinyint型別,各佔用1位元組,共2位元組。cover_image為char(32),字元編碼為表預設值utf8,由於該欄位實際存的內容僅為英文字母(存url的),結合前面講的字元編碼不同情況下的儲存 ,故僅佔用32位元組。title、description分別為varchar(50)、varchar(250),這兩個應該都不會產生溢位頁(不太確定),字元編碼均為utf8mb4,實際生產中70%以上都是存的中文(3位元組),25%為英文(1位元組),還有5%為4位元組的表情?,則存滿的情況下將佔用 位元組。
統計上面的所有分析,共佔用 869 位元組,則每個葉子節點可以存放 條,算上頁目錄,仍然能放 17 條。
則三層B+樹可以存放的最巨量資料量就是 ,約一千萬條資料,再次沒想到吧?。
資料計算總結
根據上面三種不同情況下的計算,可以看出,InnoDB三層B+樹情況下的資料儲存量範圍為 一百二十多萬條 到 將近5億條,這個跨度還是非常大的,同時我們也計算了一張部落格資訊表,可以儲存 約一千萬條 資料。
所以啊,我們在做專案考慮分表的時候還是得多關注一下表的實際情況,而不是盲目的認為兩千萬資料就是那個臨界點。
如果面試時談到這塊的問題,我想面試官也並不是想知道這個數位到底是多少,而是想看你如何分析這個問題,看你得出這個數位的過程。
