[C# 中的序列化與反序列化](.NET 原始碼學習)
[C# 中的序列化與反序列化](.NET 原始碼學習)
關鍵詞:序列化(概念與分析) 三種序列化(底層原理 原始碼) Stream(底層原理 原始碼) 反射(底層原理 原始碼)
假如有一天我們要在在淘寶上買桌子,桌子這種很不規則不東西,該怎麼從一個城市運輸到另一個城市,這時候一般都會把它拆掉成板子,再裝到箱子裡面,就可以快遞寄出去了。這個過程就類似我們的序列化的過程(把資料轉化為可以儲存或者傳輸的形式)。當買家收到貨後,就需要自己把這些板子組裝成桌子的樣子,這個過程就像反序列的過程(轉化成當初的資料物件)。
序列化是指將物件轉換成位元組流,從而儲存物件或將物件傳輸到記憶體、資料庫或檔案的過程。 它的主要用途是儲存物件的狀態,以便能夠在需要時重新建立物件。反向過程稱為「反序列化」。有點類似於壓縮與解壓的過程。
【# 請先閱讀注意事項】
【注:
(1) 文章篇幅較長,可直接轉跳至想閱讀的部分。
(2) 以下提到的複雜度僅為演演算法本身,不計入演演算法之外的部分(如,待排序陣列的空間佔用)且時間複雜度為平均時間複雜度。
(3) 除特殊標識外,測試環境與程式碼均為 .NET 6/C# 10。
(4) 預設情況下,所有解釋與用例的目標資料均為升序。
(5) 預設情況下,圖片與文字的關係:圖片下方,是該幅圖片的解釋。
(6) 文末「 [ # … ] 」的部分僅作補充說明,非主題(演演算法)內容,該部分屬於 .NET 底層執行邏輯,有興趣可自行參閱。
(7) 本文內容基本為本人理解所得,可能存在較多錯誤,歡迎指出並提出意見,謝謝。】
【注:
1. 本文在此僅介紹序列化的使用方法及相關表層內容,礙於篇幅,原始碼分析將在之後的文章中進一步介紹】
2. 本文每一個分析過程間的聯絡性可能較低,建議先閱讀總結部分,再閱讀正文
3. 此篇文章內容較為複雜,篇幅較大建議分段閱讀、先看總結再看內容】
一、序列化的作用與意義
先考慮壓縮與解壓。我們與一堆儲存了資訊的檔案,現在需要將其通過網路傳送給其他人。相信我們不會直接一個一個檔案的傳,而是將其放在一個資料夾或作為一個壓縮包後在傳遞。這樣,即節省了空間,又加快了傳輸,同時將其打包後也讓我們在之後對這一堆檔案有更好的管理。
- 傳輸。舉個例子,一座大廈好比一個物件,現在計劃要把這座大廈搬到另一個地方去,直接挪肯定不太現實。(一般地,網路傳輸只能通過位元組流,不能直接傳輸物件)。因此我們就把大廈拆成每一塊磚,給每塊磚定一個編號,知道這是在大廈的哪一部分。在這個過程中序列化就起到了將大廈分成磚頭的作用,方便資料的互動。
- 儲存。在某些程式執行時會產生一些物件,這些物件隨著程式的停止而消失,但如果我們想把某些物件儲存下來,在程式終止執行後,繼續讓這些物件存在,可以使程式再次執行時讀取這些物件的值,或在其他程式中利用這些儲存下來的物件。我們將這個過程命名為序列化。最常見的:Ctrl C / X,Ctrl V。
這時候就又有一個問題:為什麼要將其序列化後再讀寫而不直接對物件本身進行讀寫?
我們要將物件寫入一個磁碟檔案,再將其讀出來,會產生什麼問題?其中一個最大的問題就是物件參照。再舉個例子,假設現在有兩個類,A 與 B。B類中含有一個指向A類物件的參照,現在我們對兩個類進行範例化 { A a = new A(); B b = new B(); },這時在記憶體中實際上分配了兩個空間,一個儲存物件a,一個儲存物件b。接下來我們將它們寫入到磁碟的一個檔案中去,就在寫入檔案時出現了問題。因為物件b包含對於物件a的參照,所以系統會自動的將a的資料複製一份到b,這樣的話當我們從檔案中恢復物件時(也就是重新載入到記憶體中)時,記憶體分配了三個空間,而物件a同時在記憶體中存在兩份【注意:此處的複製指的是檔案的複製,並非程式執行時的淺層複製,因此對於 a 會產生新的兩個無關物件】。此時,若想在檔案上修改物件a的資料的話,就要搜尋它的每一份拷貝來達到物件資料的一致性這樣增加了不少負擔。而序列化就解決了這樣的問題。
序列化的機制:
(1)儲存到磁碟的所有物件都獲得一個序列號(1, 2, 3…)
(2)當要儲存一個物件時,先檢查該物件是否被儲存了。
(3)如果以前儲存過,只需寫入與已經儲存的具有序列號 k 的物件相同的標記;否則,儲存該物件
利用編號的方法,解決了物件參照的問題,類似於程式設計中的複用。
小結,需要序列化的原因:
- 因為在網路傳輸時,一般只能使用資料流的形式,需要將物件轉換為便於傳輸形式。
- 某些情況下需要儲存一些物件的特定情況,供其他時候使用。
二、基本序列化方式及其效率
使用 BinaryFormatter 進行序列化的二進位制形式序列化(必須新增 System.Runtime.Serialization.Formatters.Binary; 名稱空間);
使用SOAP協定進行的序列化;
使用 XmlSerializer 進行序列化的XML形式序列化物件;
JSON 序列化。
【注:如果一個類所建立的物件,能夠被序列化,那麼要求必須給這個類加上 [Serializable] 特性】
(一) 二進位制序列化
需要引入名稱空間
![]()
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
定義一個類,用於作為序列化的物件
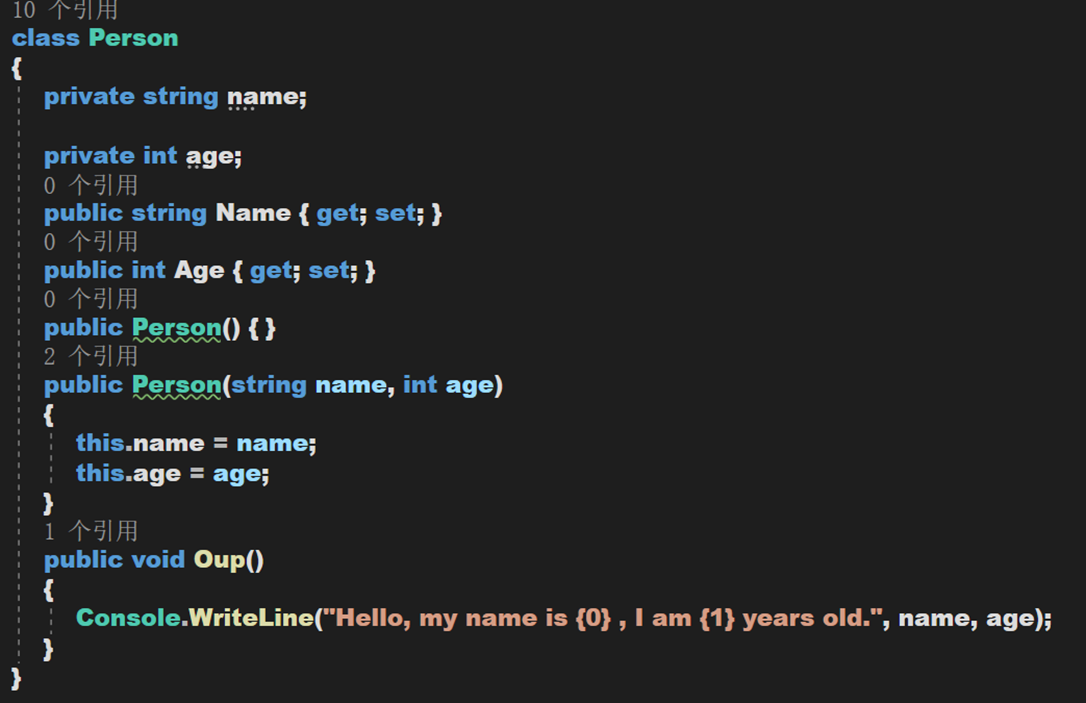
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
定義待處理物件

—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
定義一下序列化與反序列化方法
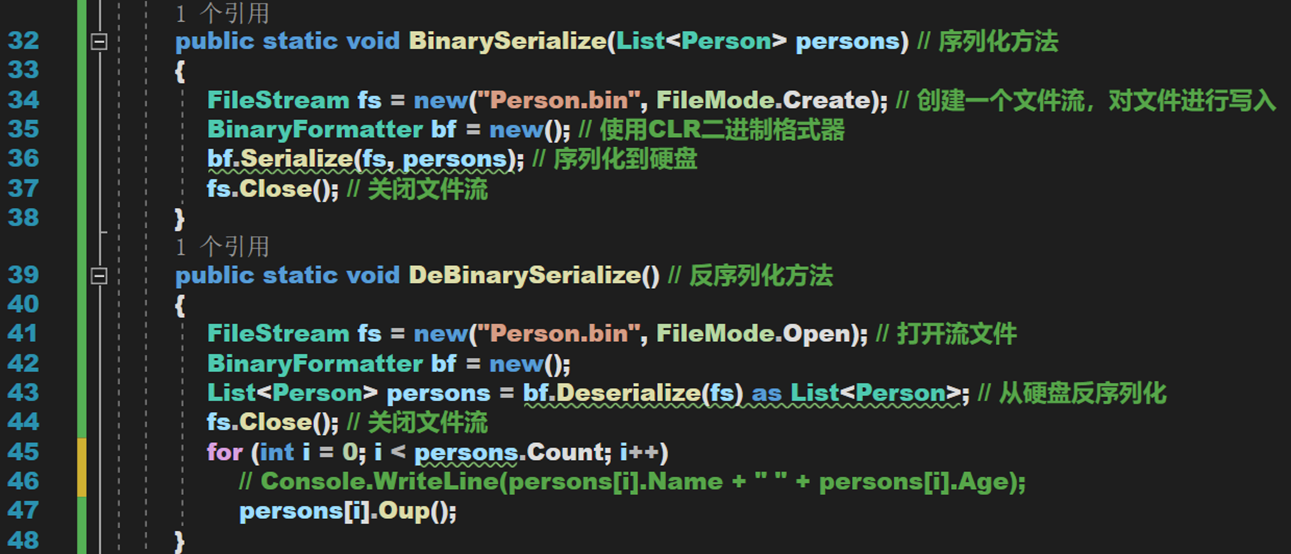
【思考:為什麼不能用 Line 46 行的語句?】
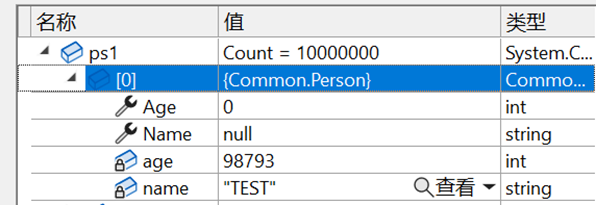
因為在類中,我們採用的是簡便屬性,且採用構造方法對欄位直接賦值。而簡便屬性似乎無法返回直接通過欄位賦值的欄位值(此推論和本人之前的映像不太相符,歡迎各位學者提出觀點)因此該物件的此屬性值恆為 null。
如果將屬性補全,則可以避免這樣的問題:

—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
然而,執行的時候發現了問題:
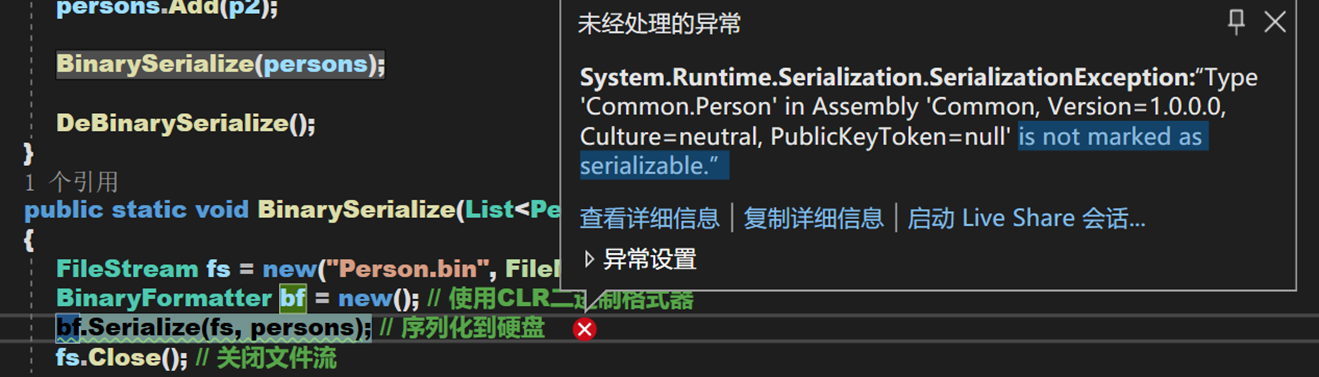
- 由此得出一個結論:需要用 [Serializable] 特性修飾對應的類,否則無法將該類的物件序列化;但個人認為,應該是在不需的地方加上NonSerialized才更合理。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
我們為這個類加上相應標籤再來跑一次
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
序列化後檔案中的內容:
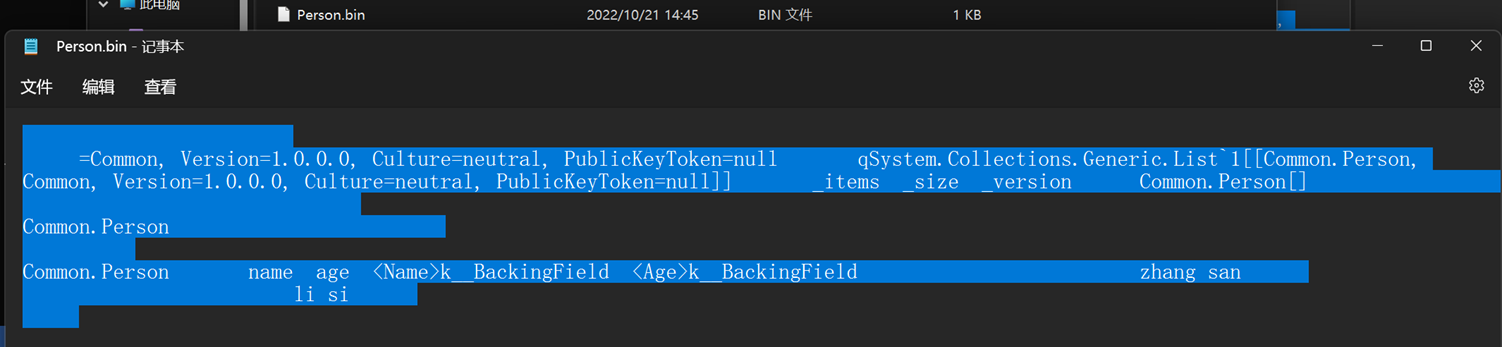
在程式所在的相關的資料夾內生成了一個 .bin 型別的檔案,說實話我有點看不懂它為什麼要儲存成這樣的形式(不排除我的編碼型別導致的問題),理論上應該是以二進位制的方式呈現資料。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
反序列化後的結果:

—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
從剛才得出的結論再入手,那我們可不可以指定某些元素不讓其序列化呢?答案是可以的
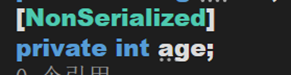
只需要在相應元素前加上這個特性即可。
看看效果:


可以發現,因為沒有序列化欄位 age,因此檔案中也沒有了 age 的身影;反序列後輸出了 int 型別的預設初始值。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
既然有三種序列化的方式,那當然要比較一下其效能。
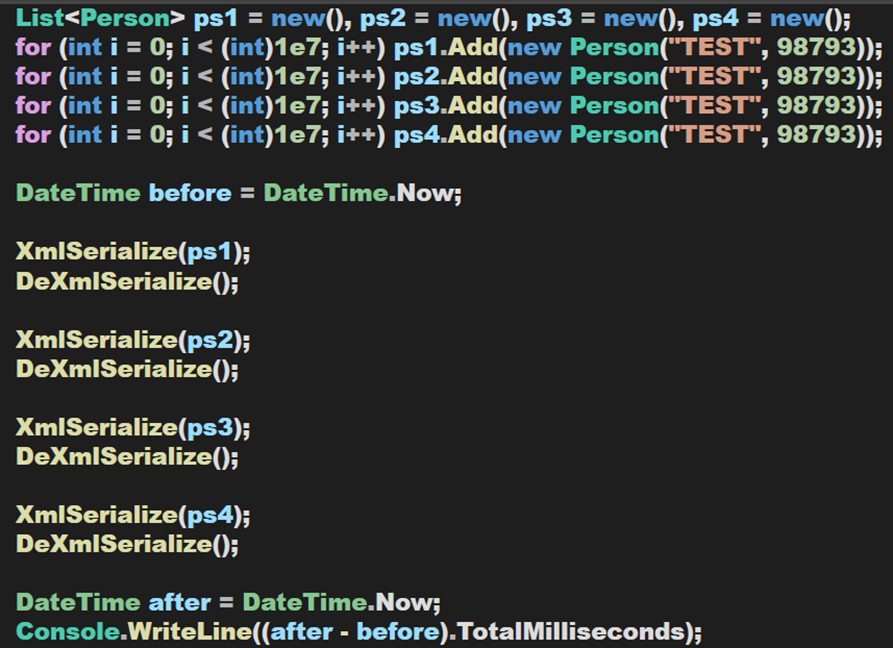
為了較好的得出能效差異,此處採用4個物件進行序列化與反序列化操作,每個物件包含 1e7(實測為該狀態下本人電腦的極限值) 個其他物件,這些物件中每個包含兩個欄位,如下圖:
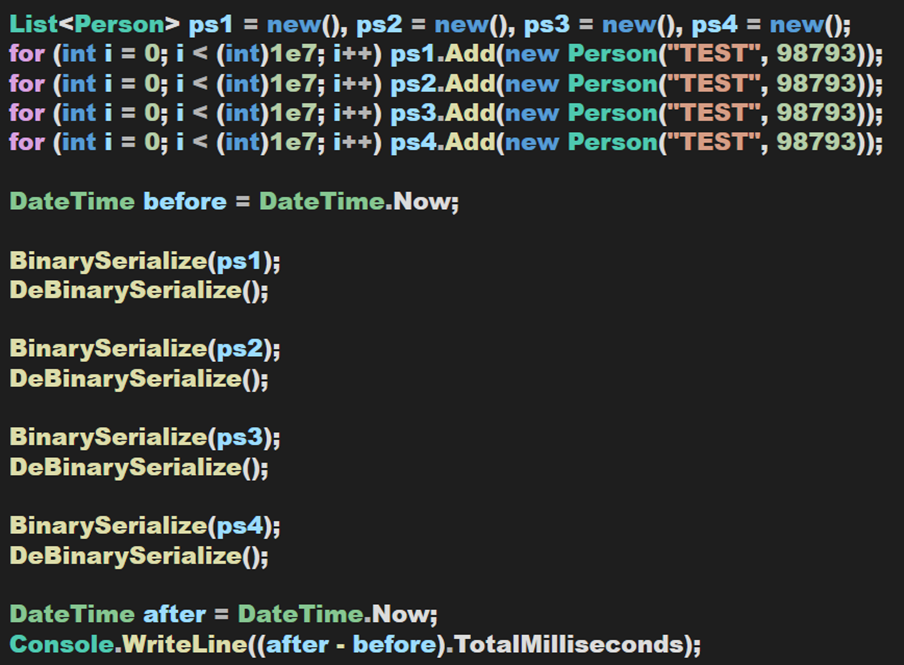
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
結果:(執行時間與生成檔案的大小)
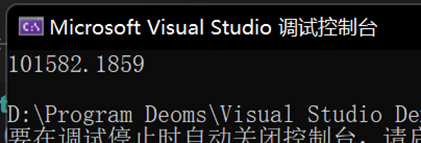
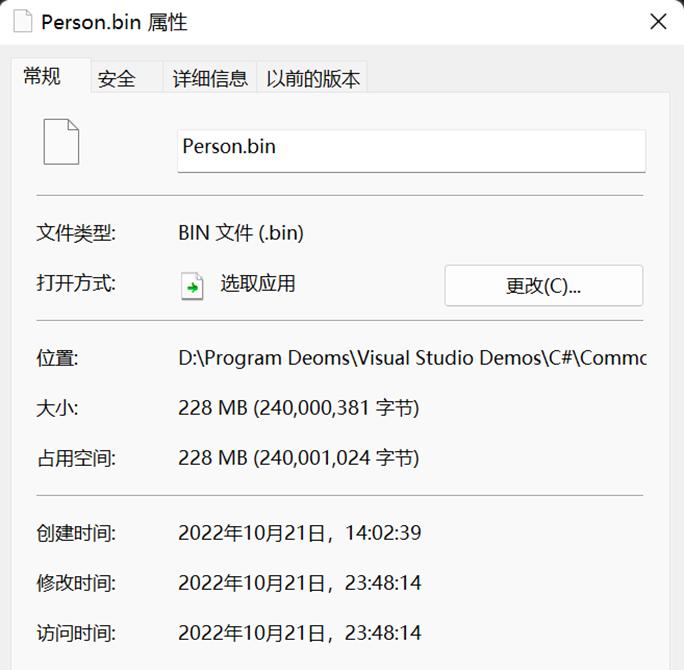
由於每次進行一個週期均會覆蓋原序列化的文字,因此此處的檔案大小,僅代表一個週期(一次序列化 + 一次反序列化)生成的檔案大小,即 1e7 的物件數量。
(二) XML 序列化
首先簡單介紹一下 XML 格式。
可延伸標示語言( eXtensible Markup Language,標準通用標示語言的子集)是一種簡單的資料儲存語言。使用一系列簡單的標記描述資料,而這些標記可以用方便的方式建立,雖然可延伸標示語言佔用的空間比二進位制資料要佔用更多的空間,但可延伸標示語言極其簡單易於掌握和使用。
總結一下特點:利用更簡單的一些標記去描述資料,使得資料使用更加方便,用空間換取便捷。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
需要引入名稱空間

—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
還是用那個類,定義一下序列化與反序列化方法
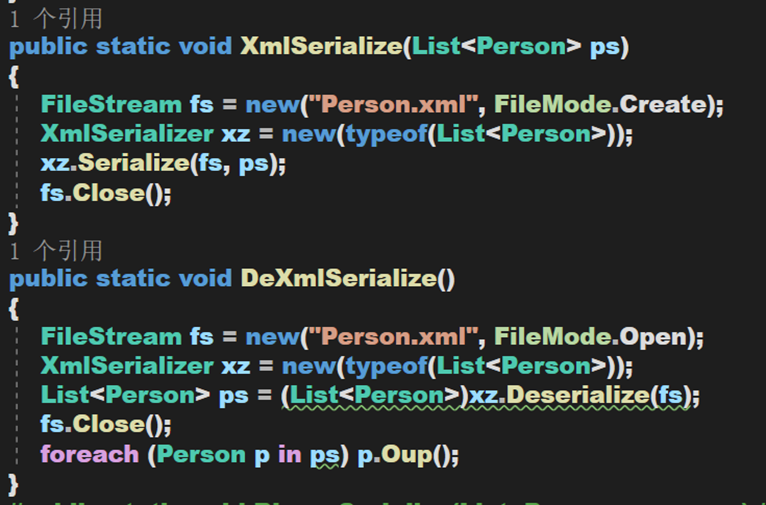
可以發現,二者在格式上其實差別不大,過程均是確定檔案、序列化或反序列化、寫入或讀取。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
簡單看一下效果
但偵錯過程中發生了錯誤:

注意看此處的報錯,「Only public types can be processed」 也就是說,只有公共型別,才能被 xml 序列化。因此,需要將類 Person 標記為 public。
不過對於 XML 序列化,並不需要將序列化物件標記為 [Serialize]。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
結果如下:


—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
不知道各位有沒有注意到一個問題
二進位制序列化:
Xml 序列化:
對比可以發現,二進位制序列化時存取的是物件的欄位;Xml 序列化時存取的是物件的屬性。所以當使用簡便屬性,且通過構造方法直接對欄位賦值時,因為無法通過屬性獲取到欄位的值,因此在進行 Xml 序列化時會出現異常:

—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
同樣,來測試一下效能:
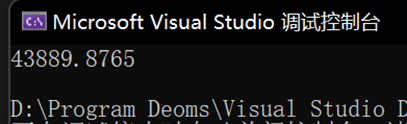
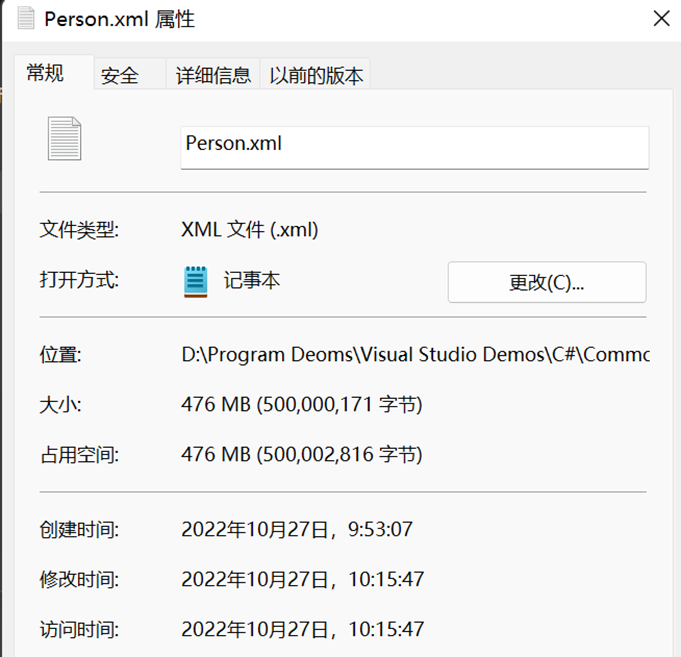
同理,由於每次進行一個週期均會覆蓋原序列化的文字,因此此處的檔案大小,僅代表一個週期(一次序列化 + 一次反序列化)生成的檔案大小,即 1e7 的物件數量。
可以看到,相較於二進位制序列化,Xml在時間上明顯減少,但消耗了接近兩倍的空間,頗有一種空間換時間的感覺。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
(三) 基於 SOAP 協定的序列化
SOAP 和在操作上二進位制流序列化差別不大;結果上和 Xml 差別不大,只是 SOAP 不能序列化泛型物件,因此在序列化時要將待序列化的物件轉換成陣列形式。。
先來介紹一下 SOAP 協定:SOAP 是基於 XML 的簡易協定,可使應用程式在 HTTP 之上進行資訊交換。更簡單地說:SOAP 是用於存取網路服務的協定。

—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
【注:由於無法載入名稱空間 System.Runtime.Serialization.Formatters.Soap ;微軟檔案也沒有查詢到相關資訊,因此在此不作演示】
(四) JSON 序列化
JSON(JavaScript Object Notation, JS物件簡譜)是一種輕量級的資料交換格式。它基於 ECMAScript(European Computer Manufacturers Association, 歐洲計算機協會制定的js規範)的一個子集,採用完全獨立於程式語言的文字格式來儲存和表示資料。簡潔和清晰的層次結構使得 JSON 成為理想的資料交換語言。 易於人閱讀和編寫,同時也易於機器解析和生成,並有效地提升網路傳輸效率。【百度百科 JSON_百度百科 (baidu.com)】
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
需要引入名稱空間

據微軟的說法:
後續在學習原始碼時,會進一步分析二者異同。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
定義序列化與反序列化方法
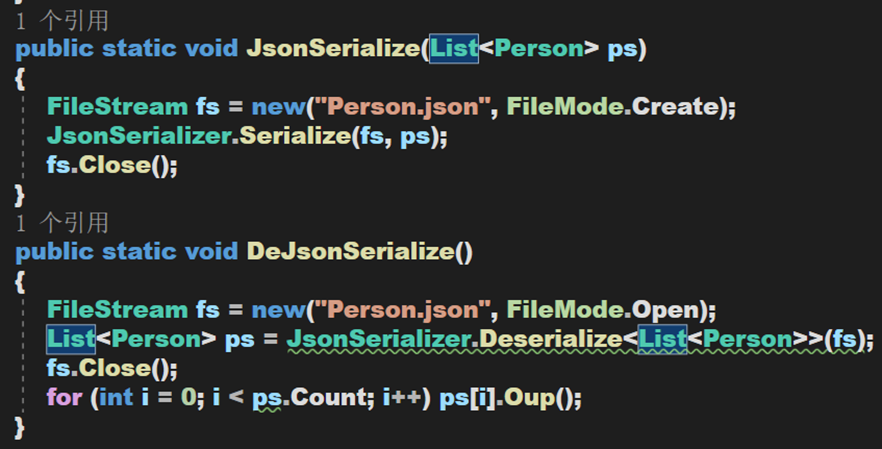
可以發現,其無需初始化用於序列化的物件,推測應該是方法在該類中被定義為 static。這樣的方式使得使用更加便捷,也在一定程度上節省了空間。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
結果展示

其和 Xml 也是一樣,讀取物件的屬性而不讀取欄位。且儲存本質為字串,非常簡潔。這也為其高效傳輸與廣泛應用奠定了基礎。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
效能測試:


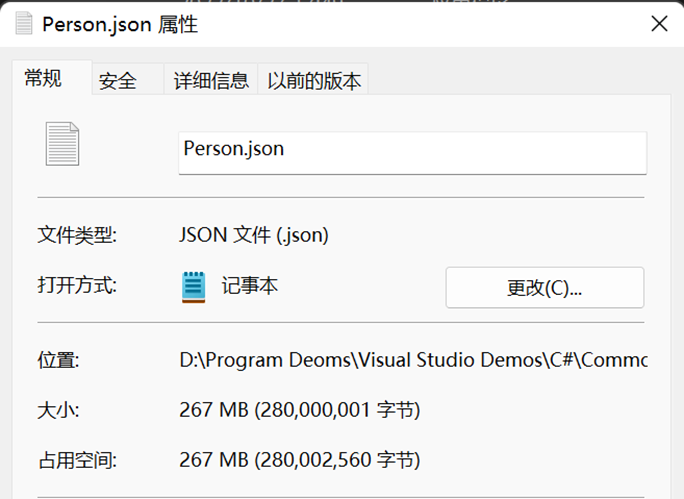
可以看到,單從表象,JSON 序列化幾乎整合了二進位制序列化和 XML 序列化的優點:不僅生成的檔案體積小、週期執行速度也快。
總結
1. 序列化是一種處理資料的方式,將程式碼中的物件或元素轉化為某種具有意義和規律的流形式(文字流,字串流等),便於進行儲存、分析與傳輸。
2. 序列化主要用在資料持久化和遠端呼叫。把物件狀態儲存到流中,達到持久化(或遠端呼叫)的作用,比如有一個類有100個屬性欄位,如果在其他地方使用這個被範例化的類就必須讀取100次它的屬性以獲取物件的狀態資訊,才能利用這些資訊構建新類。而有了序列化就可以將類資訊儲存到一個流中,要構造新類時候直接反序列化,將所有屬性直接付給新範例。這比手工寫程式碼讀取屬性方便,還實現了持久化。
3. 三種序列化的對比:
(1)二進位制流序列化:
效能測試結果:時間 101582.1859 ms,空間 228 MB * 4。
需要對序列化物件進行特性 [Serialize] 標記。
- 優點:對資料的保真度很高,對於多次呼叫應用程式時保持物件狀態非常有用。例如,通過將物件序列化到剪貼簿,可在不同的應用程式之間共用物件;將物件序列化到流、磁碟、記憶體和網路等;遠端處理使用序列化;「按值」在計算機或應用程式域之間傳遞物件。
- 缺點:
a) 如果使用不同的 .NET 版本序列化和反序列化以 UTF-8 或 UTF-7 編碼的物件,則不保留該物件的狀態。即,在不同框架與編碼型別下,可能會產生衝突異常或不儲存物件。
b)序列化/反序列化所用時間較長,且序列化內容不易被直接看懂。
(2)XML 序列化:
效能測試結果:時間 43889.8765 ms,空間 476 MB * 4。
需要將物件進行標記為 public。
- 優點:
a) 相較於二進位制流序列化,在時間效率上有所提升。
b) 序列化結果具有一定可讀性。
c) 基於其衍生出的 SOAP 協定序列化方式,具有安全性、可延伸性、跨語言、跨平臺以及支援多種傳輸形式等優點。
d) 只序列化公共屬性和欄位,當希望提供或使用資料而不限制使用該資料的應用程式時,這一點非常有用。由於 XML 是開放式的標準,因此它對於通過 Web 共用資料來說是一個理想選擇;SOAP 同樣是開放式的標準,這使它也成為一個理想選擇。
- 缺點:由於採用大量標記去標識每個物件,使得序列化結果冗長複雜,對空間的額外開銷增大。
(3)JSON 序列化:
效能測試結果:時間 24381.7978 ms,空間 267 MB * 4。
- 優點:
a) 整合了二進位制序列化佔用空間小與 XML 序列化速度快的優點。
b) 序列化結果具有極佳的可讀性與簡潔性。
c) 相對於 XML 協定解析速度更快。
d) 只序列化公共屬性,且JSON 是開放式的標準,對於通過 Web 共用資料來說是一個理想選擇。
- 缺點:
a) 沒有統一可用的 IDL(Interface description language 介面描述語言)即,跨平臺介面,延長了開發週期。
b) 在某些語言中需要採用反射機制,不適用於 ms 級響應。
三、三種序列化方式的實現原理
【注:由於關於該部分原始碼分析的內容與資料較少,且本人水平有限,不能闡述得很清晰或完全正確,還請各位讀者指正與提出意見,謝謝】
(一) 二進位制序列化 BinaryFormatter
1. 基本資訊


位於程式集 System.Runtime.Serialization.Formatters.dll,名稱空間 System.Runtime.Serialization.Formatters.Binary 中。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——

密封類,繼承了介面 IFormatter。該介面包含兩個方法 Serialize() 與 Deserialize(),主要用於提供格式化序列化物件的功能,在不同情況下根據需要覆蓋介面中的方法,以達到多型的目的。
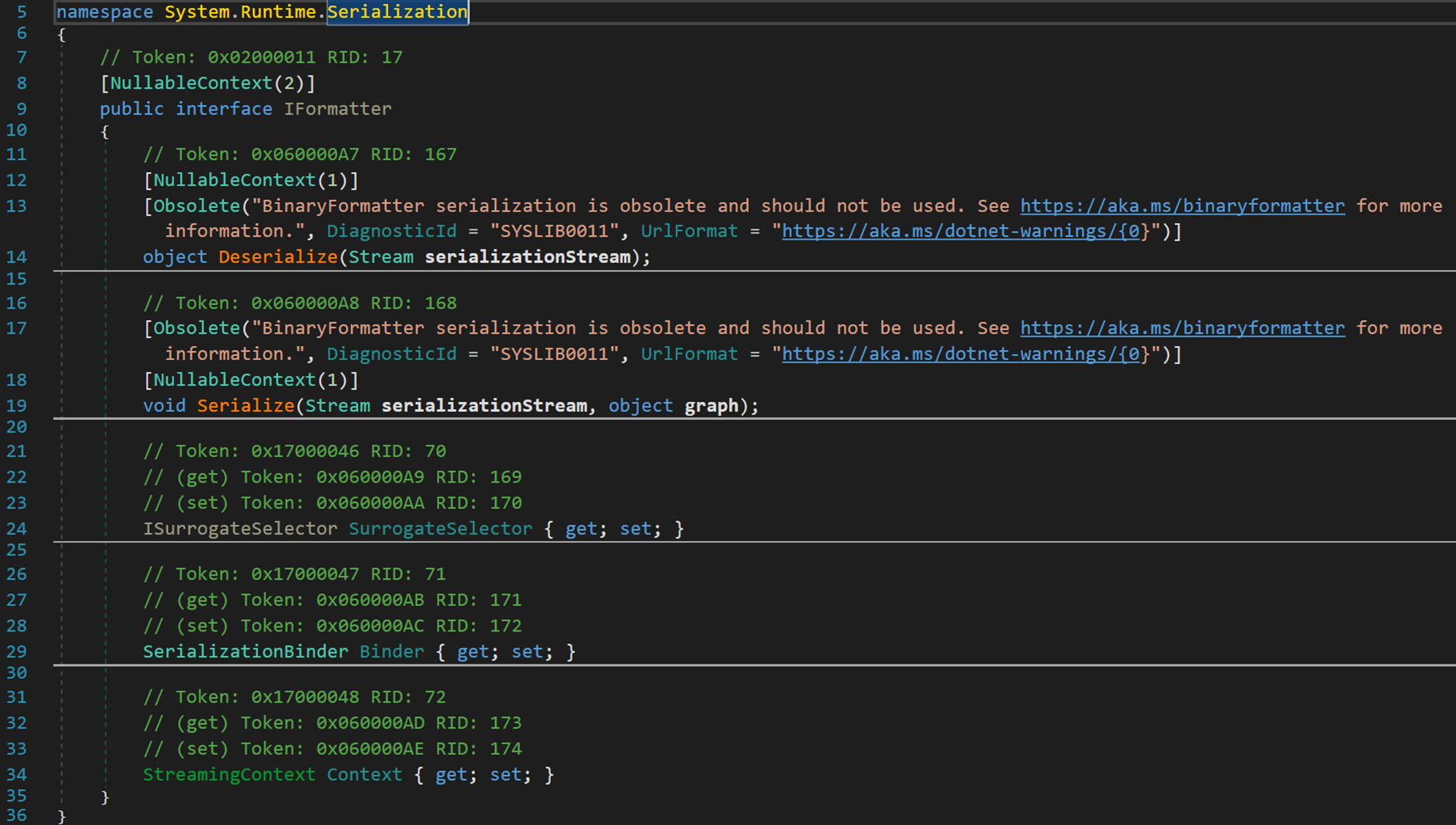
該介面專門用於定義具體的序列化和反序列化方式
- Line 14:返回值型別為 object,引數為 Stream 型別的反序列化方法。【有關 Stream 會在文末進行補充說明】
- Line 19:無返回值,引數為 Stream 型別與 object 型別的序列化方法。
- Line 13、17:注意到這兩個方法均被標記為 Obsolete(過時的),也就是說出於某種原因,這種方法已被廢棄,存在某些更新的方法代替。
- Line 24:型別為 ISurrogateSelector 屬性 SurrogateSelector。其中,介面 ISurrogateSelector 的作用是幫助格式化程式選擇代理以委託給其他物件的序列化或反序列化。
解釋一下,為了使序列化/反序列化機制工作起來,需要定義一個」代理型別」,它接受對現有型別進行序列化和反序列化的操作。在正式執行前,先向格式化器記錄該代理型別的一個範例,告訴格式化器,代理型別要作用於現有的哪一個型別。格式化器檢測到它正要對現在型別的一個範例進行序列化和反序列化時,會呼叫由該代理物件定義的方法。
【注:具體執行流程將在後文分析】
- Line 29:類 SerializationBinder,允許使用者控制類的載入並指定要載入的類,用於控制在序列化和反序列化期間使用的實際型別。
在序列化過程中,格式化程式傳輸需要建立正確型別和對應版本的物件範例的資訊,通常包括物件的完整型別名稱和程式集名稱。預設情況下,反序列化可使用此資訊建立相同物件的範例。由於原始類可能在執行反序列化的計算機上不存在,如:原始類已在程式集之間移動,或者伺服器和使用者端要求使用不同的類版本,因此有些使用者可能需要控制要序列化和反序列化哪個類。
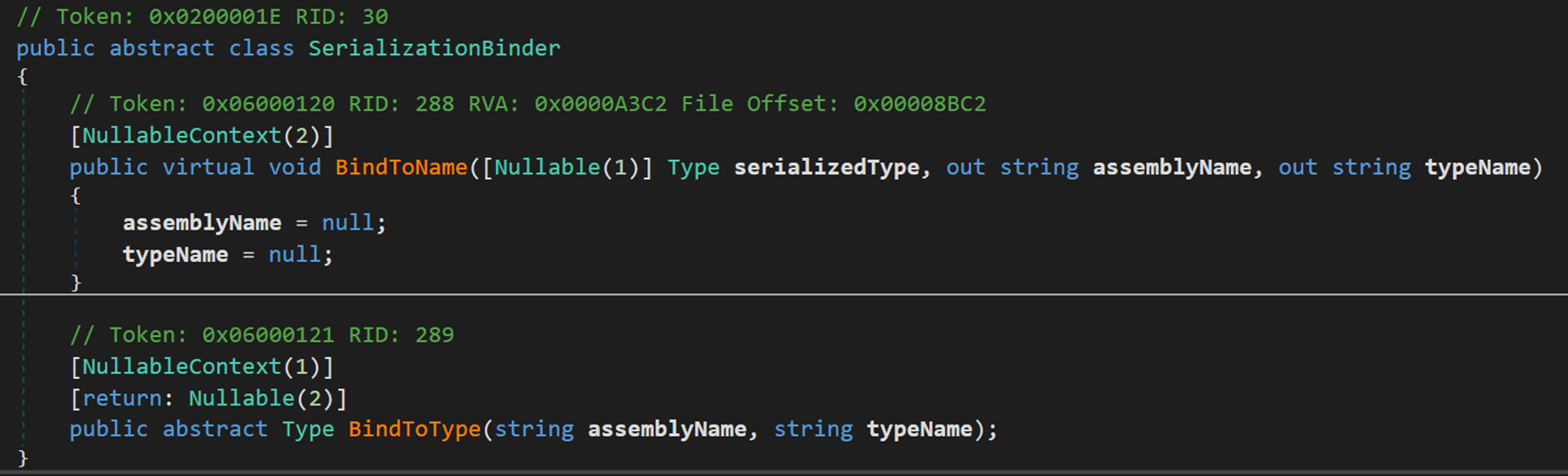
在建立和記錄資訊時有兩種方式:
(1)BindtoName(),記錄物件的型別(Type),返回物件所在的的程式集名(assemblyName)與所屬的型別名稱(typeName)。
(2)BindToType(),記錄物件所在的的程式集名(assemblyName)與所屬的型別名稱(typeName),返回物件的型別(Type)。
- Line 34:結構體 StreamingContext,用於說明給定序列化流的源和目標,並提供另一個呼叫方定義的上下文。簡單來說就是新增一些資訊,是的資料的來源去向清晰化。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
1 個唯讀變數和7 個欄位
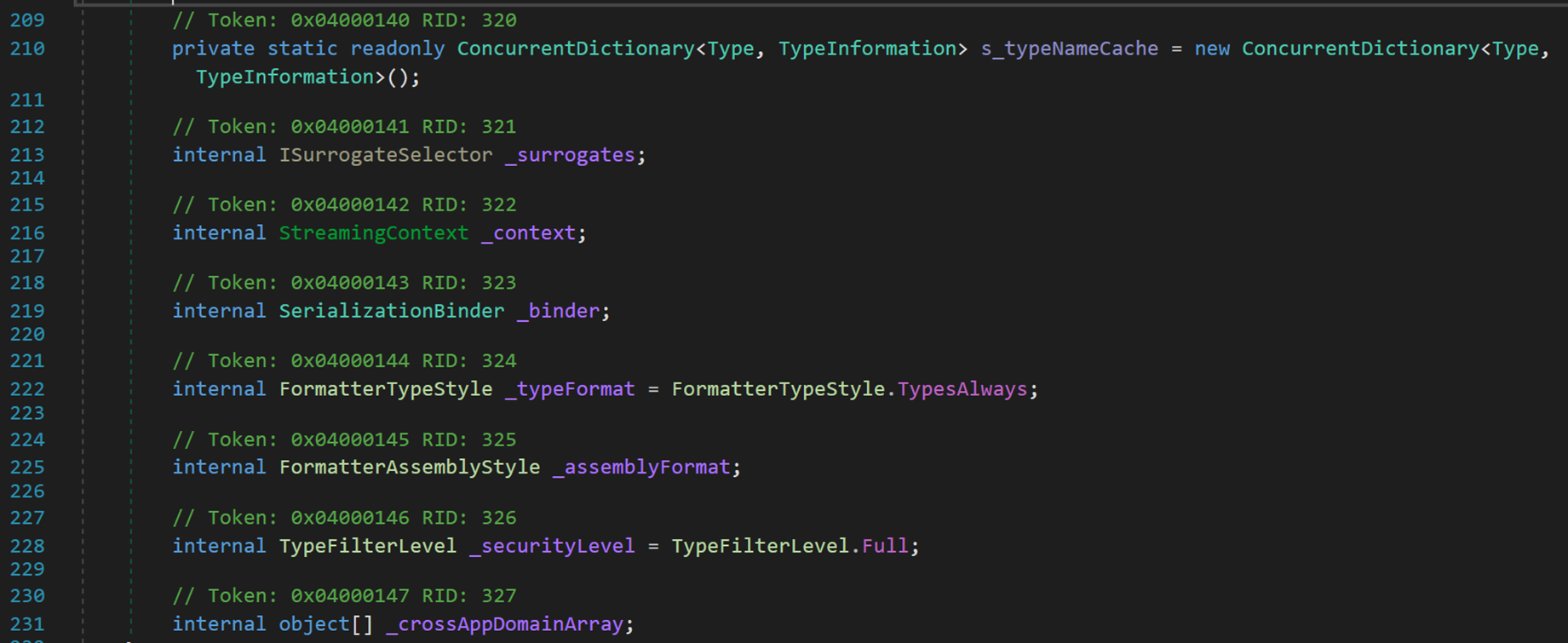
- Line 210:類 ConcurrentDictionary<TKey,TValue> 表示可由多個執行緒同時存取的鍵/值對的執行緒安全集合。其中,所有公共成員和受保護成員 ConcurrentDictionary<TKey,TValue> 都是執行緒安全的,並且可以從多個執行緒並行使用。但是,通過實現(包括擴充套件方法) ConcurrentDictionary<TKey,TValue> 之一存取的成員不能保證執行緒安全,並且可能需要由呼叫方同步。
- Line 213:介面 ISurrogateSelector 指示序列化代理項選擇器類。代理項選擇器實現 ISurrogateSelector 介面,以幫助格式化程式選擇代理以委託給其他物件的序列化或反序列化。有關代理器更多內容,之後會提到。
- Line 216:結構體 StreamingContext 說明給定序列化流的源和目標,並提供另一個呼叫方定義的上下文。主要用於資訊的儲存,包括但不限於序列化前後的物件內容。
- Line 219:類 SerializationBinder 允許使用者控制類載入並指定要載入的類。主要配合代理選擇器使用,加上版本容錯機制,可以在一定程度上實現不同版本間的序列化與反序列化操作。
- Line 222、225、228:此處的三個列舉在後文均有提及,在此不做介紹。
- Line 213:一個型別為 object 的陣列,用於儲存序列化後的結果,作為一份「備份」記錄結果,供反序列化時使用。
2. 序列化流程
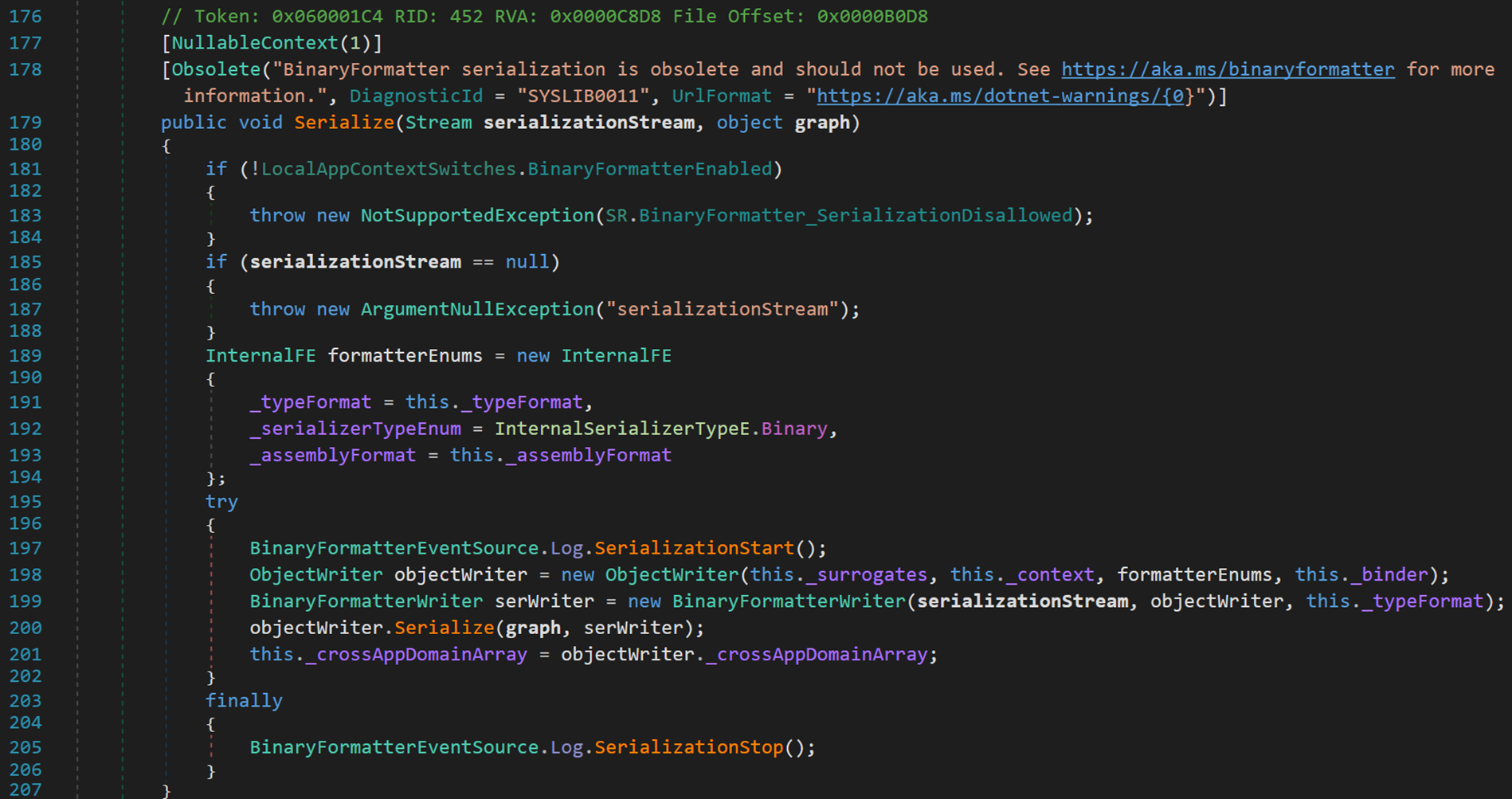
- Line 179:引數 serializationStream 表示待序列化的資料流型別(主要包括:檔案流 FileStream、記憶體流 MemoryStream、網路流 NetworkStream、加密流 CryptoStream、文字讀寫 StreaReader 與 StreamWriter、二進位制讀寫 BinaryReader 與 BinaryWirter);graph 表示待序列化的物件。
- Line 181:用於判斷當前狀態下能否進行二進位制序列化。據微軟的說法,由於存在安全漏洞,該方法現已過時,並生成 ID 為 SYSLIB0011 的編譯時警告。此外,在 .NET 7 及 ASP.NET Core 5.0 及更高版本的應用中,除非 Web 應用已重新啟用 BinaryFormatter 功能,否則它們會引發 NotSupportedException 的異常(詳細內容請參閱 中斷性變更:BinaryFormatter 序列化方法已過時,並且已在 ASP.NET 應用中禁用 - .NET | Microsoft Learn)。
- Line 185:如果待序列化物件為空,則不能進行序列化操作。
- Line 189:定義格式化列舉並賦值,為後續的序列化做準備。
其中,類 InternalFE,內部儲存了 4 類列舉
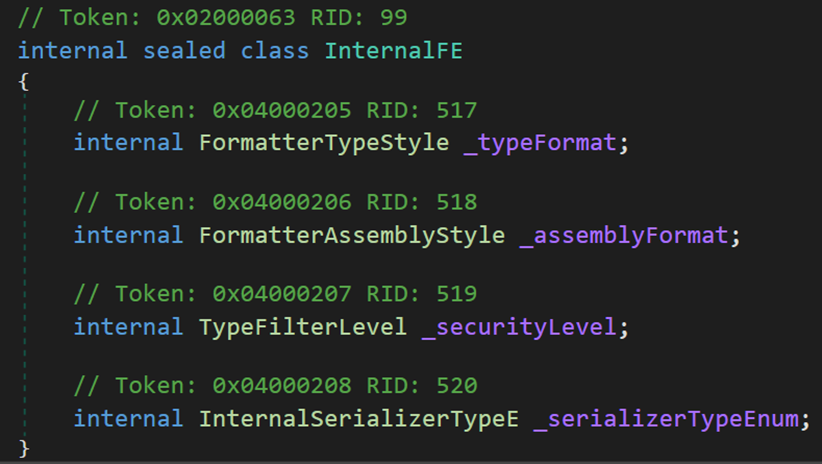
(1)FormatterTypeStyle 表示在序列化流中的佈局格式
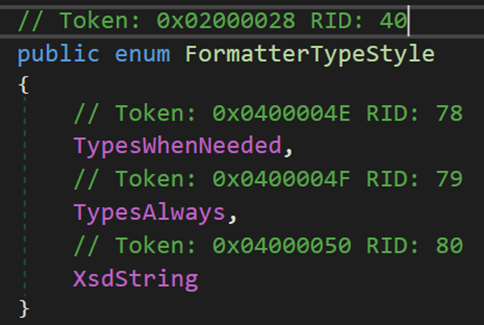
其中,TypesWhenNeeded 表示格式只能為物件陣列、Object型別與 ISerialized 非基元值型別所宣告的型別;TypesAlways 表示格式可以為所有物件成員和 ISerializable 物件成員;XsdString 表示可以採用 XSD(XML Schema Definition)格式(而不是 SOAP 格式)來提供字串。
(2)FormatterAssemblyStyle 用於定位和載入程式集的方法,一定程度上規定了相容性的問題。
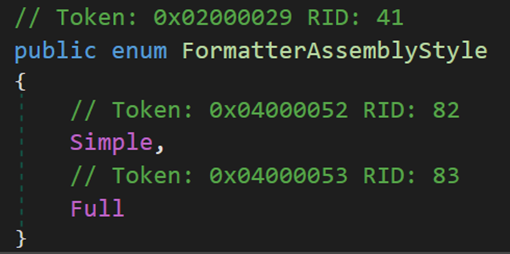
Simple 表示在簡單模式下,反序列化期間所用的程式集不需要與序列化期間所用的程式集完全匹配。具體而言,當 LoadWithPartialName 方法載入程式集時,版本號不需要匹配。
Full 表示在完全模式下,反序列化期間所用的程式集必須與序列化期間所用的程式集完全匹配;使用 Assembly 類的 Load 方法載入程式集。
(3)TypeFilterLevel 指定用於 .NET Framework 遠端處理的自動反序列化的級別,一定程度上規定了能進行處理的資料型別。
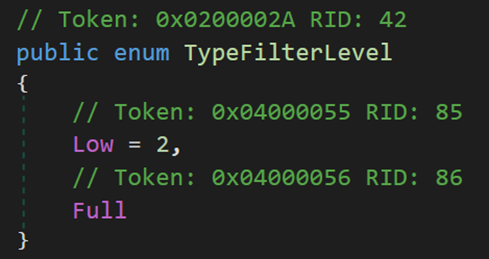
Low = 2,表示 .NET Framework 遠端處理的 Low (低)反序列化級別,支援與基本遠端處理功能相關聯的型別。
Full,表示 .NET Framework 遠端處理的 Full (完全)反序列化級別,它支援遠端處理在所有情況下支援的所有型別。
(4)InternalSerializerTypeE指定需要進行的序列化型別。
- Line 197:開始進行序列化,並記錄紀錄檔。
- Line 198:定義一個物件寫入器,並傳入引數包括代理型別、上下文資訊、格式化器列舉、序列化/反序列化所控制的實際型別。
- Line 199:定義二進位制寫入器,並傳入引數包括待序列化的資料流型別、物件寫入器、序列化流中的佈局格式。
- Line 200:呼叫物件寫入器中的序列化方法。【這一步才是真正的開始序列化】
- Line 205:序列化結束,並記錄紀錄檔。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
下面分析一下 Line 200 處的詳細過程:

- Line 32:開始寫入。
- Line 38:獲取一個特殊的 ID 編號。【注:該方法內部涉及很多其他方法的呼叫,在此不一一分析,僅對過程做出說明】
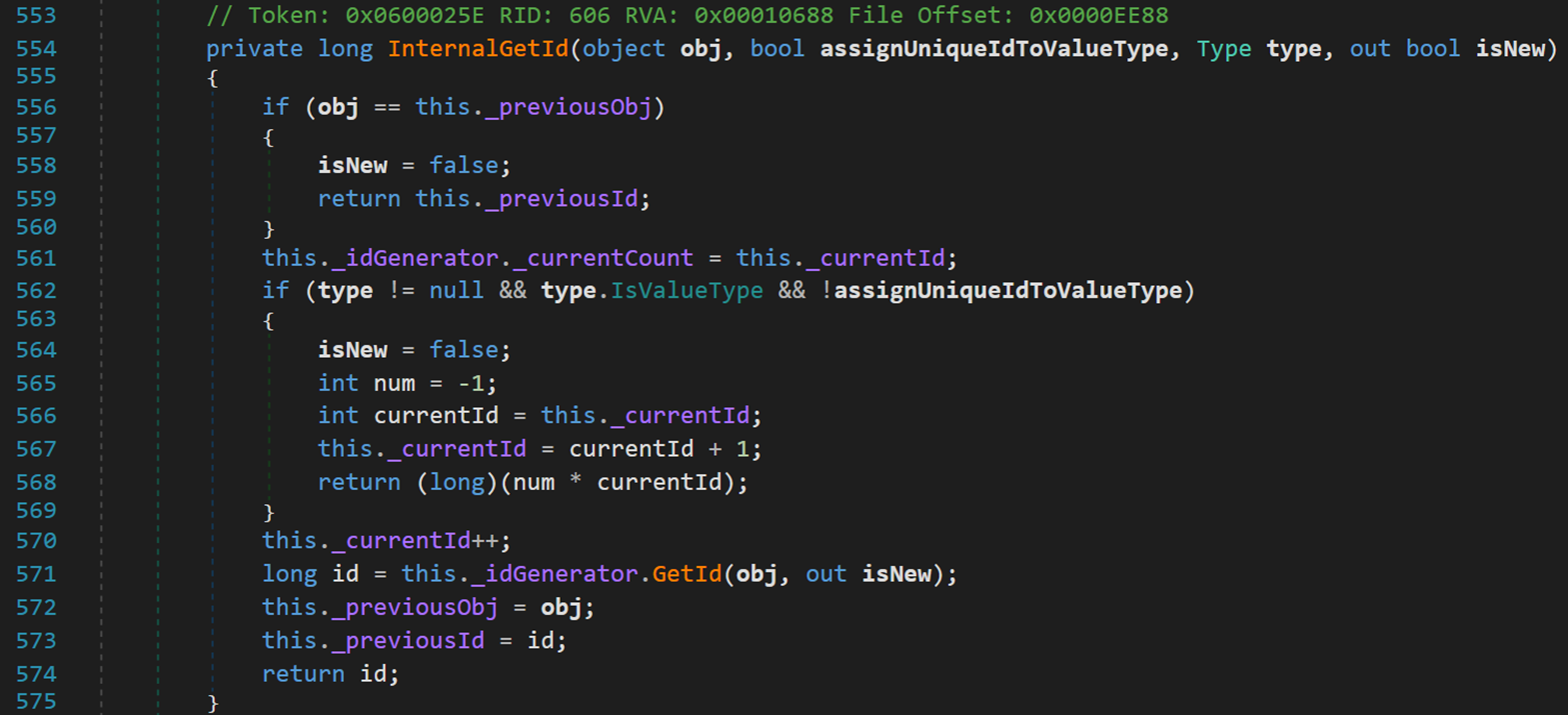
首先對方法 InternalGetId() 傳入引數:待序列化物件、是否將唯一 ID 分配給值型別、物件型別的資訊、是否新物件(此處的「新」值得是該物件在之前是否進行過序列化操作)。
Line 556:若該物件是之前(已經進行過序列化)的物件,則直接返回其先前序列化後被分配的 ID。
Line 562:若該物件在之前沒有進行過序列化操作,且描述物件資訊不為空、沒有被分配過唯一的 ID,則為該待序列化物件計算一個唯一的 ID。
Line 571:若該物件在之前沒有進行過序列化操作,但出於某種原因無法計算新的 ID,則呼叫一個上層類(ObjectIDGenerator)中的公共方法,以獲得 ID。
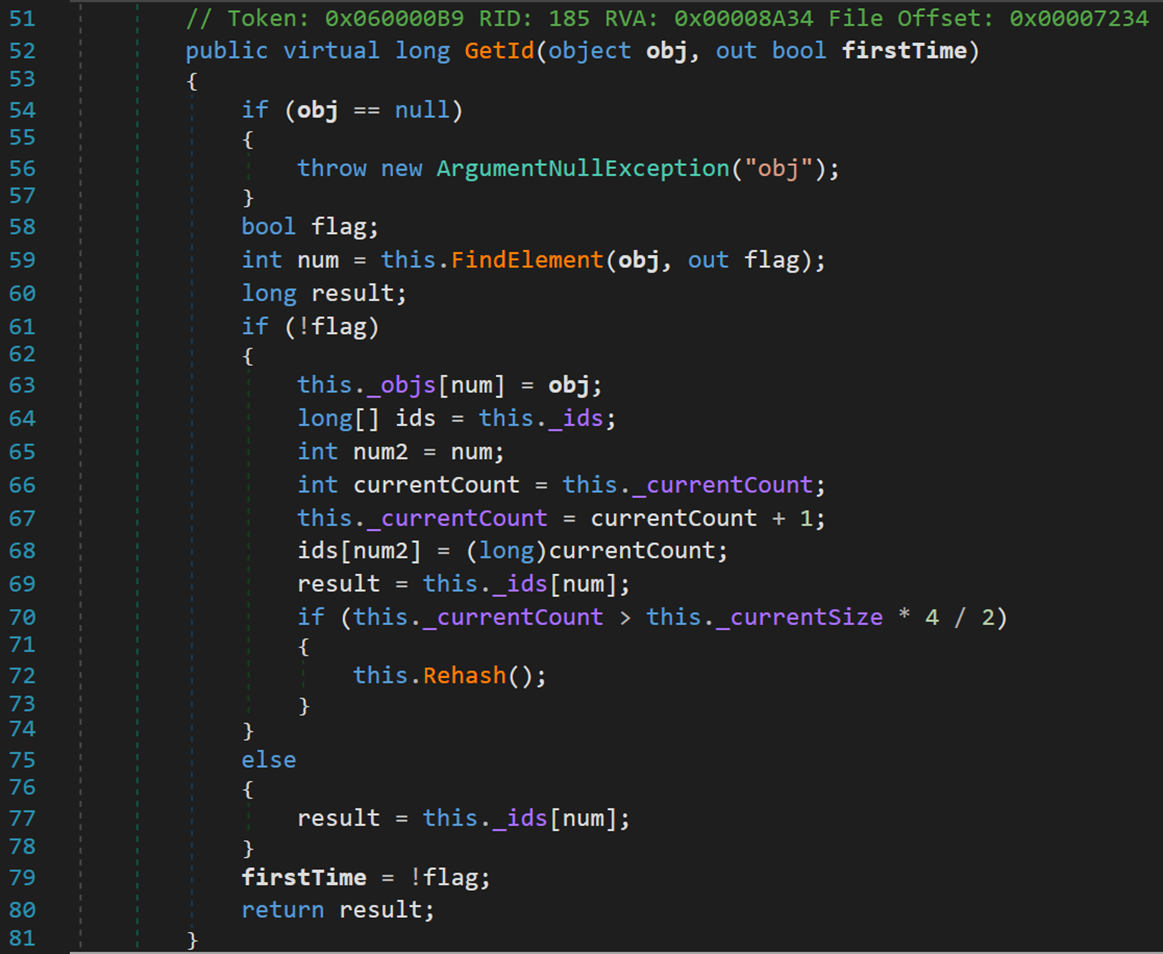
Line 59:方法 FindElement(),元素定位,利用元素的雜湊值在陣列 _objs 中查詢待序列化物件 obj,並返回其所在位置以及是否存在的標誌(flag)。
Line 61 ~ 78:若未找到相應物件,則將其記錄至陣列中,並計算相應 ID;否則直接返回其對應的 ID。(此處的 ID 是根據物件的雜湊值得出,類似於「記憶化搜尋」,記錄已經處理過的物件,以便後續直接使用)。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
- Line 40:方法 WriteSerializedStreamHeader(),初始化序列化寫入流的起始器。
- Line 41:將待序列化物件加入到準備佇列中。
- Line 44:方法 GetNext(),依次從準備佇列中取出元素與其對應的 ID,直到佇列為空。
- Line 47~55:將佇列中的元素轉換為 WriteObjectInfo 型別,該型別資料流 Stream 型別中的一種,主要用於流的寫入。
- Line 57:型別 NameInfo,記錄物件的詳細資訊,包括以下內容:

- Line 58:正式開始進行寫入。

Line 78:objectInfo 待寫入的物件;memberNameInfo 與 typeNameInfo 傳入的為同一個內容,儲存了物件的詳細資訊。
Line 87:Converter.s_typeofString,相當於字串型別。若待序列化物件為字串型別,則以字串的形式進行寫入。
Line 93:若待序列化物件為陣列型別,則以陣列的形式進行寫入。
【礙於篇幅,在此對於方法 WriteObjectString() 與 WriteArray() 就不放出原始碼,僅做簡單說明】
對於方法 WriteObjectString(),首先處理 Null 的部分。該過程根據物件中的 Null 數量,將所有 Null 進行處理,確保在之後的寫入中遇到 Null 時不會觸發異常 NullReference,Null 處理完後再對剩餘部分進行序列化。整個序列化過程由方法 WriteByte()、WriteInt32() 與 WriteString() 完成,其作用是將一個位元組/整數/字串寫入檔案流中的當前位置。
對於方法 WriteArray(),通過遍歷的方式,說簡單些就是依次將陣列中的每個元素轉換後寫入檔案流。
Line 101:若待序列化元素既不是字串型別,也不是陣列型別,則獲取物件在快取 cache 中的名稱、型別以及資料本身,分別儲存到陣列 array、array2 與 array3 中。在初始化時已經將物件內部的個元素資訊分別儲存到了類的欄位中,在此處進行賦值。其按照存取每個元素的方式,將每個元素的資訊儲存到陣列中,這樣做的原因可能是同一個物件中可能存在不同型別的元素,需要以不同方式進行序列化。
Line 102:若物件可以進行序列化操作,則標記並記錄資訊供後續使用。

Line 112:獲取型別。
Line 113:將該型別 type 轉換為某種編碼,判斷其是否為基元型別 && 判斷其是否不為字串型別。
Line 115~124:若元素不為空,則將元素操作後儲存與陣列 array4 中;否則根據元素型別,將操作後的資訊儲存於陣列 array4 中。
至此,初步轉換已經完成,之後再根據 array4 中的資訊,將物件的每個元素寫入 BinaryObjectWithMap 型別的遍歷中,並新增到 _objectMapTable,最終再根據 FileStream 寫入檔案。
小結一
1. 總結一下二進位制序列化的流程:將待序列化物件分解為最小單元並獲取其型別,依次遍歷最小單元並在陣列中儲存其相關資訊,將其寫入資料流中,並複製一份結果儲存在陣列中。
2. 二進位制序列化過程比較複雜,其需要針對每一位不同的元素型別以及出現的位置,將其轉換為能夠儲存這些資訊的二進位制碼,因此存在許多遍歷於轉換,效率較低。同時這也導致了反序列化的效率較低。雖然計算機對二進位制數處理有著天然的優勢,但是在進行轉換與逆轉換的時候效率確實不高。
3. 根據自然規律,越少的表示單元就需要越多的組合來表示一個資訊,二進位制碼只有 0 與 1 兩種單元,其需要儲存元素型別、位置、狀態及其他內容,使得一個元素需要轉換出很長的一串二進位制碼,使得空間佔用過多。
4. 二進位制反序列化的時候會自動相容處理序列化一方新增的資料。但是在個別情況下會出現反序列化的過程中遇到異常的情況。目前發現的出現反序列化異常的資料型別包括,泛型集合與陣列。這兩種資料結構並非是一定會導致二進位制反序列化報錯,而是有一定的條件。泛型集合出現反序列化異常的條件有三個:
(1)序列化的物件新增了泛型集合;
(2)泛型使用的是新增的類;
(3)新增的類在反序列化的時候不存在;
陣列也是類似的,只有滿足上述三個條件的時候,才會導致二進位制反序列化失敗。
具體原因可能與其版本容錯機制(Version Tolerant Serialization,VTS)有關。詳細內容請參閱(Version tolerant serialization | Microsoft Learn)
5. 據微軟官方的說法:


究其原因是:其會不安全地處理請求有效負載的威脅類別,可導致目標應用內出現拒絕服務 (DoS)、資訊洩露或遠端程式碼執行。其中的 Deserialize() 方法可用作攻擊者對使用中的應用執行 DoS 攻擊的載體。這些攻擊可能導致應用無響應或程序意外終止。且使用 SerializationBinder 或任何其他 BinaryFormatter 設定開關都無法緩解此類攻擊。.NET 認為此行為是設計使然,因此不會發布程式碼更新來修改此行為,所以微軟不建議使用二進位制序列化。(感興趣的讀者可以深入研究,在此不作更多解釋)
當然,二進位制序列化還是有一些優點:
6. 資料保密性強。這一點和可閱讀性是相反的,可閱讀性低則保密性強。
7. 序列化後的檔案,由於時二進位制形式,因此便於計算機直接分析與操作。
(二) XML 序列化
1. 基本資訊


位於程式集 System.Private.Xml.dll,名稱空間 System.Xml.Serialization 中。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——

Xml 沒有繼承任何類以及介面,通過自定義序列化與反序列化方法,與很多過載方法,實現一種新的序列化形式。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
共 11 個欄位
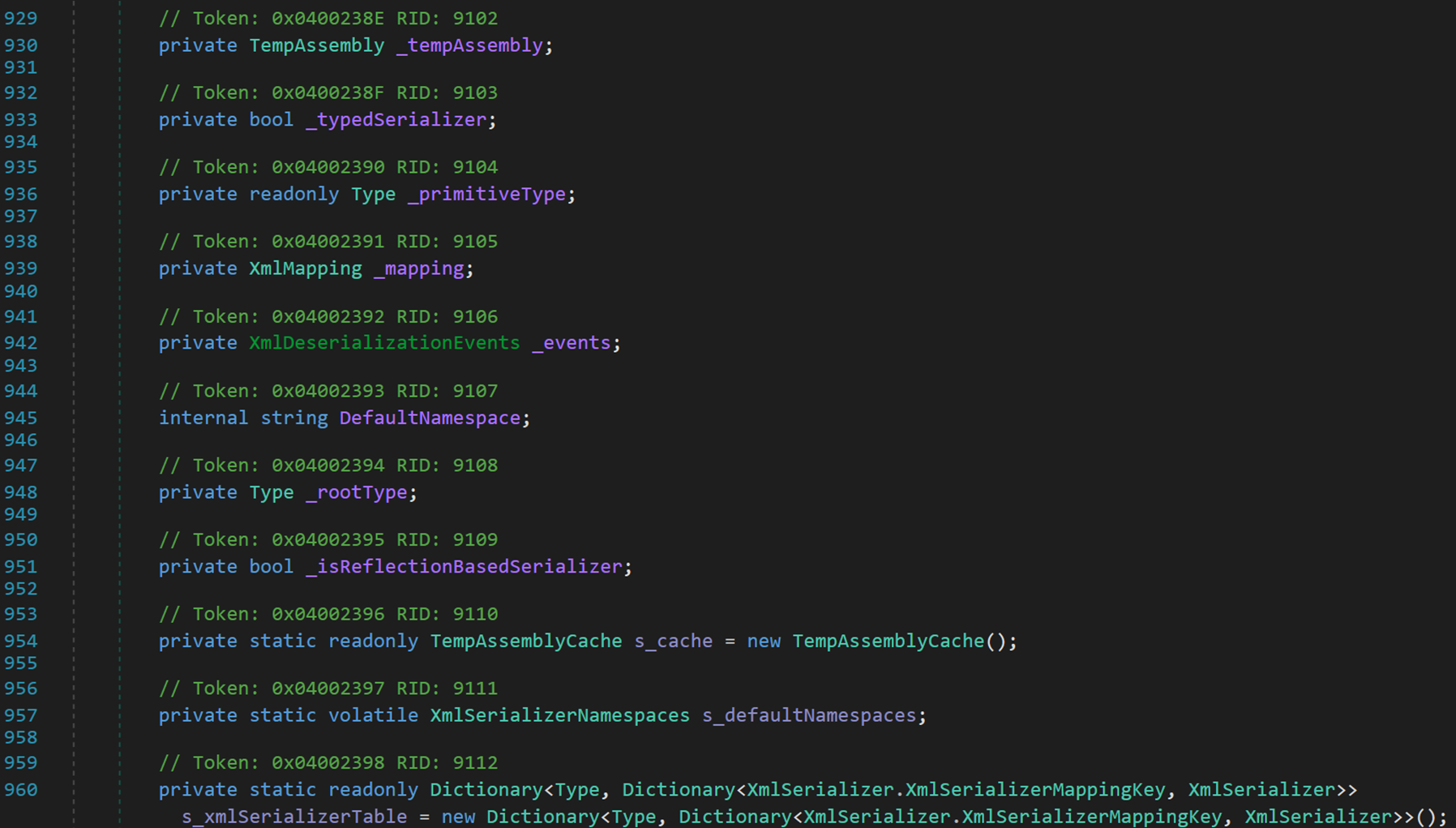
- Line 930:類 TempAssembly,與類 Assembly 關聯,基於反射可以獲得正在執行的裝配件資訊,也可以動態的載入裝配件,以及在裝配件中查詢型別資訊,並建立該型別的範例。可以使用反射動態地建立型別的範例,將型別繫結到現有物件,或從現有物件中獲取型別,然後呼叫其方法或存取器欄位和屬性。
【注:有關反射 Reflection 會在文末補充說明】
- Line 933:欄位 _typedSerializer,表示物件之前是否已經進行過 XML 序列化操作。
- Line 936:抽象類Type,用來包含型別的特性,使用這個類的物件能讓我們獲取程式使用的型別的資訊。
補充一些關於這個類的資訊:
(1)對於程式中用到的每一個型別,CLR都會建立一個包含這個型別資訊的Type型別的物件。
(2)程式中用到的每一個型別都會關聯到獨立的Type型別的物件。
(3)不管建立的型別有多少個範例,只有一個Type物件會關聯到所有這些範例。
- Line 939:抽象類 XmlMapping,支援 .NET 型別和 XML 架構資料型別之間的對映,相當於是一種規則,用於序列化與反序列化的正常進行。
- Line 942:結構體 XmlDeserializationEvents,包含可用於將事件委託傳遞給 Deserialize 的執行緒安全的 XmlSerializer 方法的欄位。
- Line 945:欄位 DefaultNamespace,獲取預設名稱空間的名稱空間 URI(Uniform Resource Identifier 標識、定位任何資源的字串),如果沒有預設名稱空間,則為空字串。
- Line 948:與 Line 936 處的欄位為同一型別,推測 _primitiveType 表示物件的基元型別(16種),_rootType 表示物件派生於的型別(System.ValueType、System.Enum、System.Object)。
- Line 951:欄位 _isReflectionBasedSerializer 表示物件是否是基於反射而實現序列化。
- Line 954:類 TempAssemblyCache,儲存物件在快取內的資訊,包括但不限於:資料型別、反射資訊。
- Line 957:類 XmlSerializerNamespaces,包含 XmlSerializer 用於在 XML 檔案範例中生成限定名的 XML 名稱空間和字首。
- Line 960:定義字典,以型別為 Key,記錄對映關係(XmlMapping)與 序列化器。
2. 序列化流程
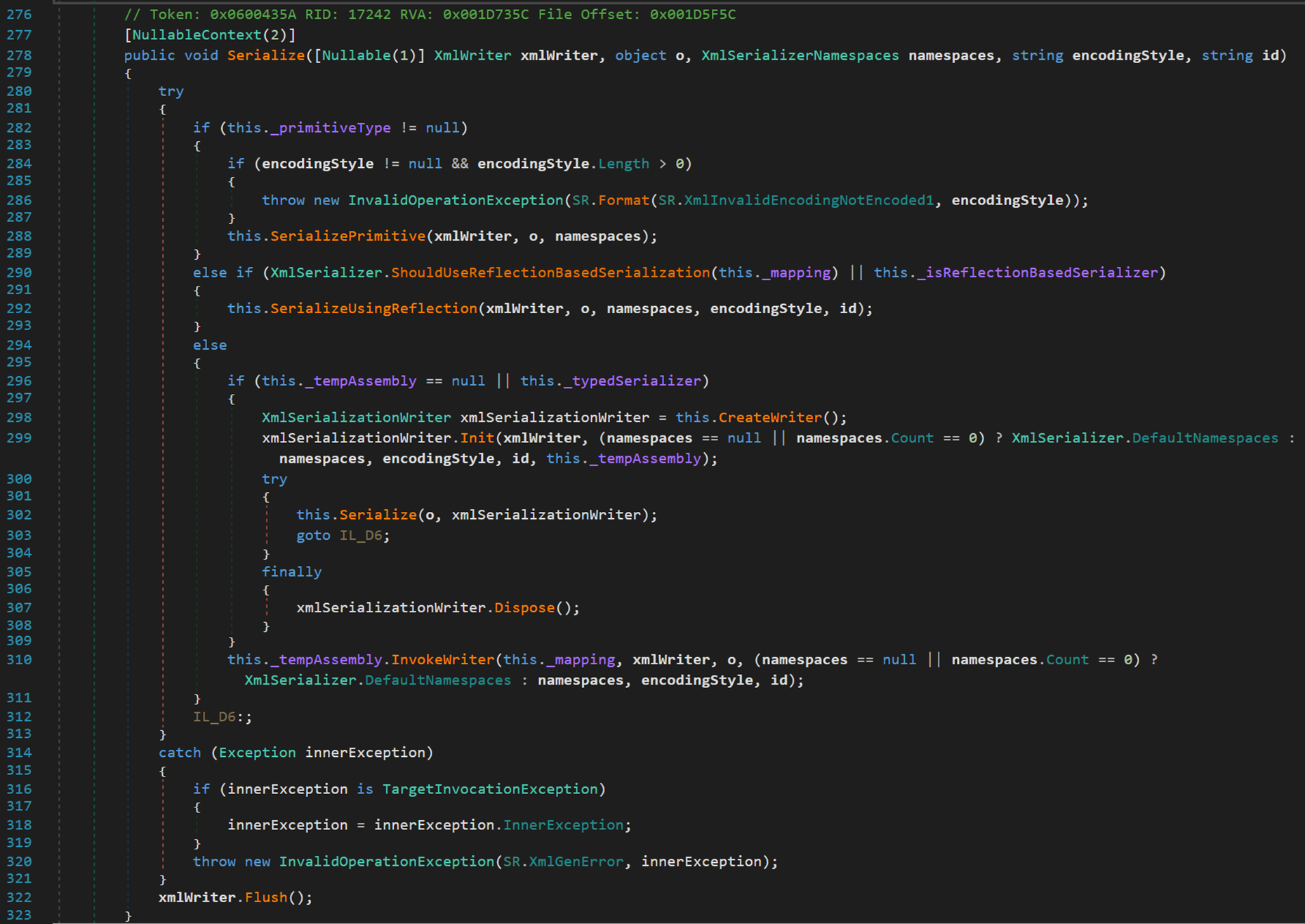
- Line 278:引數
(1)xmlWriter 一個寫入器,提供一種快速、非快取和只寫入方式以生成包含 XML 資料的流或檔案;
(2)o 表示待序列化物件;
(3)namespace 包含 XmlSerializer 用於在 XML 檔案範例中生成限定名的 XML 名稱空間和字首;
(4)encodingStyle 物件的編碼型別,包括但不限於 UTF8,Unicode,ASCII。
(5)id 是記錄同一物件的唯一識別符號。
- Line 288:若物件為基元型別,且具有一定的編碼型別,則按照基元型別的操作進行序列化。
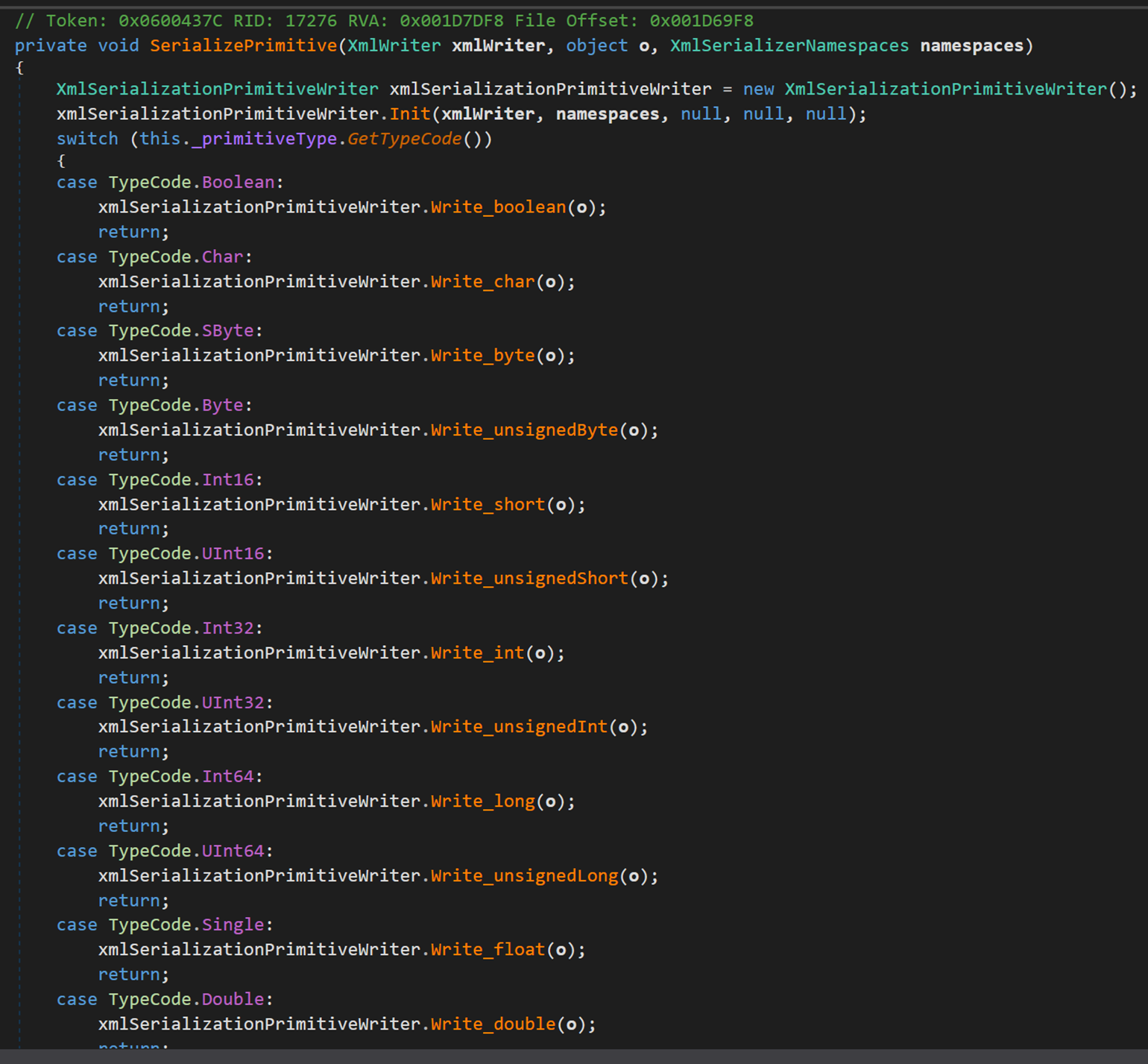

注意到,除了基元型別外,還包括其他 4 種型別,也被歸於初始型別(primtiveType)。
其中的 Write_xxx() 方法,此處以 Write_string 為例:
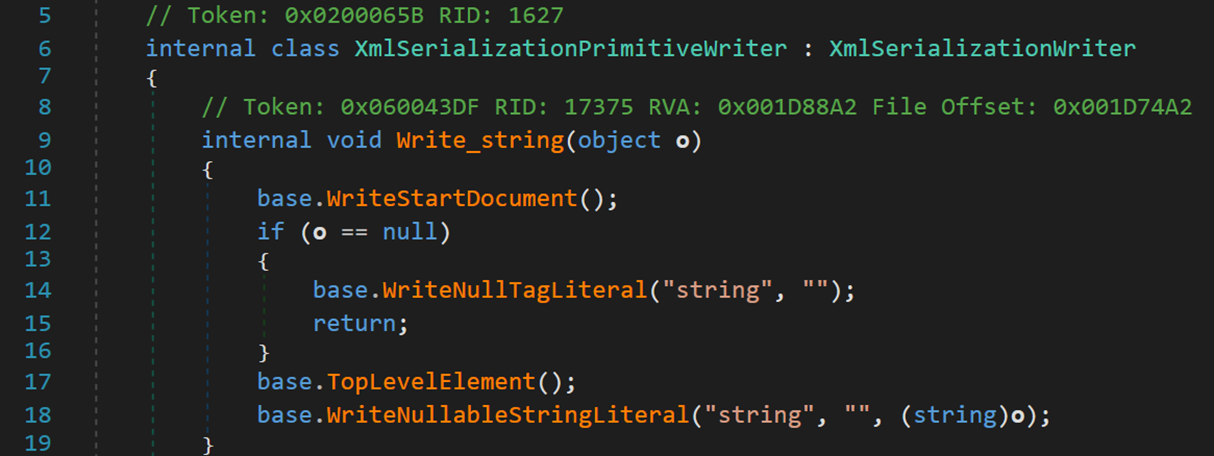
其內部的語句以及呼叫的方法,對檔案寫入後,就是我們在檔案中看到的內容,寫入的內容包括編碼型別、物件與其內部元素的資料型別、元素間的關係、物件當前狀態等。礙於篇幅,在此不作展開。
- Line 292:若物件不是基元型別 + 額外增添的 4 種型別,且是基於或需要使用反射的,則利用反射進行序列化。

類 ReflectionXmlSerializationWriter,派生自類 XmlSerializationWriter,該基礎類別有兩個子類,另一個是 XmlSerializationPrimitiveWriter,也是用來進行序列化操作。由此可知,基礎類別 XmlSerializationWriter 相當於用來提供不同實現形式的序列化器。
對於 XmlMapping,其原理類似於字典的形式,將不同型別的元素與序列化方式一一對應做出對映,根據對映規則執行不同的序列化操作與反序列化操作。
- Line 296:若物件有關反射的資訊為 null 或在此之前已經進行過 Xml 序列化操作,則定義一個新的並利用現有的資訊直接初始化序列化器。如果內部元素不為空,則轉到標籤 IL_D6,否則執行方法 InvokeWriter(),該方法是一種基於 Xml 的 Soap 的序列化方法。
- Line 322:方法 Flush(),把寫在緩衝區的內容寫入檔案,清理當前編寫器的所有緩衝區,並使所有緩衝資料寫入基礎流。
區別於方法 Close():暫時關閉。關閉當前流並釋放與之關聯的所有資源(如通訊端和檔案控制程式碼)。不直接呼叫此方法,而應確保流得以正確釋放。
區別於方法 Dispose():清理記憶體。釋放某一物件使用的所有資源。Dispose 會負責 Close 的一切事務,額外還有銷燬物件的工作,即Dispose包含Close。
一般我們使用 StreamWriter 等類時,先呼叫 Flush() 將資料寫入檔案,再呼叫 Dispose() 銷燬流物件。
反序列化過程區別不大,對不同資料型別採用不同的方法,最後返回一個型別為 object 的物件。
小結二
1. 總結一下 Xml 序列化的流程:根據物件的不同型別,採取不同的標記方式,並寫入檔案;反序列化就直接從字串中讀取買個標記塊並恢復為物件。
2. 其因為不需要對結果進行復制儲存操作,因此在效率上比二進位制更快;但由於對物件中的每一個元素都要進行相應的字串標記,因此生成的檔案會大很多,這也導致了在傳輸過程中浪費資源。
3. 雖然其生成的結果檔案很大,但其可指定元素或特性的名稱,且檔案可讀性高,以及物件共用和使用的靈活性。XML 序列化將物件的公共欄位和屬性或方法的引數和返回值序列化成符合特定XML格式的流,只要生成的XML流符合給定的架構,則對於所開發的應用程式就沒有約束。
4. 不過,其不如二進位制序列化更廣泛。。序列化資料只包含資料本身以及類的結構,不包括型別標識和程式集資訊;類必須有一個將由 XmlSerializer 序列化的預設建構函式,且只能序列化公共屬性和欄位,不能序列化方法、索引器、私有欄位或唯讀屬性(唯讀集合除外)。
(三) JSON 序列化
1. 基本資訊

位於程式集 System.Text.Json.dll,名稱空間 System.Text.Json 中。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——

同樣沒有繼承任何類與介面,也是通過自定義序列化與反序列化方法,進行多次過載。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
共 6 個欄位
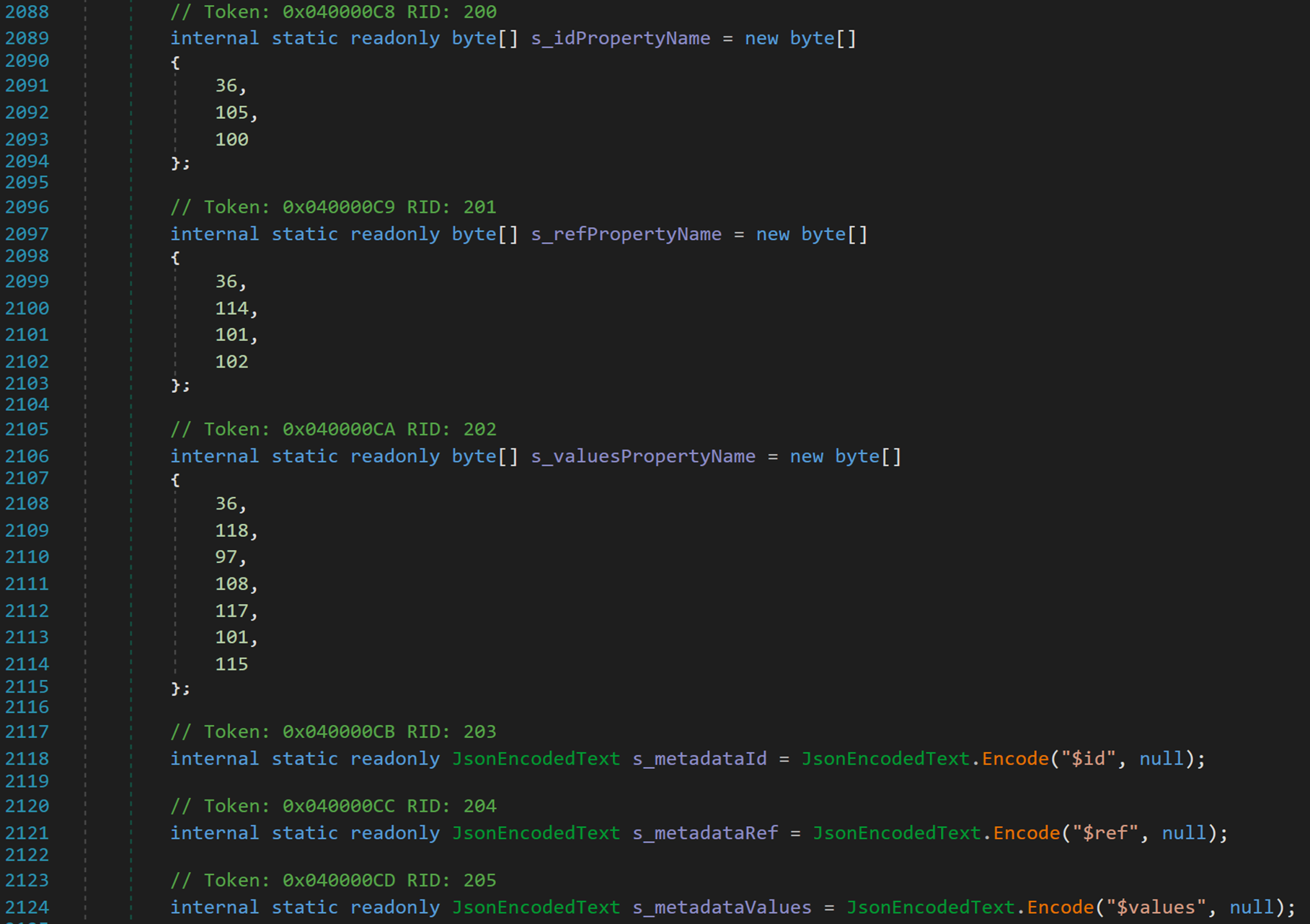
這六個欄位均為內部唯讀欄位,用於在不同情況下,選用不同的標識,以完成相應的序列化操作。
- Line 2089、2097、2106:PropertyName 直譯是「屬性名稱」。
- Line 2118、2121、2124:metadata 直譯是「後設資料」。其中,結構體 JsonEncodedText 提供將 UTF-8 或 UTF-16 編碼文字轉換為適用於 JSON 的表單的方法,此型別可用於快取和儲存用於提前編寫 JSON 的已知字串,方法是預先對其進行編碼。Encode() 方法是將指定型別的文字轉換為 JSON 字串,即序列化後的結果表現形式。
根據欄位的字首可以推測 s_id 表示給物件的唯一識別符號;s_ref 表示參照地址;s_values 表示物件值。
2. 序列化流程
【注:由於存在多個過載方法,此處分析的是前文(第二部分第(四)點 JSON 序列化)所呼叫的序列化方法】
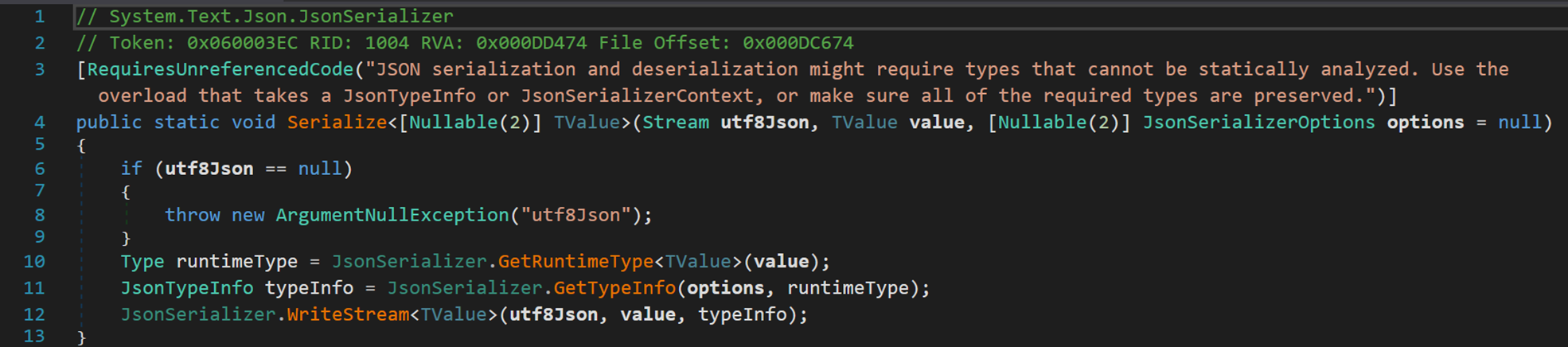
- Line 3:先來看看這個特性 RequiresUnreferencedCode 剪裁警告。
剪裁:將打包的應用取出某一部分,單獨使用。
在釋出應用程式時,.NET SDK 會分析整個應用程式並刪除所有未使用的程式碼。但可能很難確定什麼是未使用的,或者更準確地說是使用了什麼。為了防止剪裁應用程式時行為發生變化,.NET SDK 通過「剪裁警告」提供剪裁相容性的靜態分析。當剪裁器發現可能與剪裁不相容的程式碼時,剪裁器會生成剪裁警告。 與剪裁不相容的程式碼可能會在剪裁後的應用程式中產生行為變更,甚至崩潰。理想情況下,所有使用剪裁的應用程式都不應有剪裁警告。如果有任何剪裁警告,則應在剪裁後徹底測試應用,以確保沒有行為變更。
- Line 4:注意到該方法為泛型方法,其中泛型型別可空。
- Line 4:utf8Json 表示序列化後輸入輸出的流資料型別(在之前的演示中,採用的是檔案流 FileStream);value 為待序列化物件;options 表示 Json 序列化操作的某些特定選項,預設為 null。
- Line 10:類 Type 在之前提到過,用於儲存物件的相關資訊。
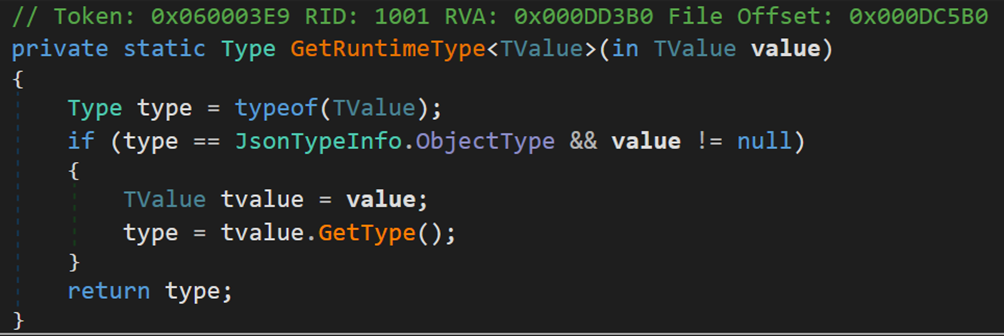
該方法用於將物件轉換為某種特定的統一型別,以便後面序列化使用。
- Line 11:類 JsonTypeInfo,提供有關型別的 JSON 序列化相關後設資料。方法 GetType() 根據不同的 options 針對剛才轉換後的物件 runtimeType 獲取其內部詳細資訊。
- Line 12:正式開始序列化。
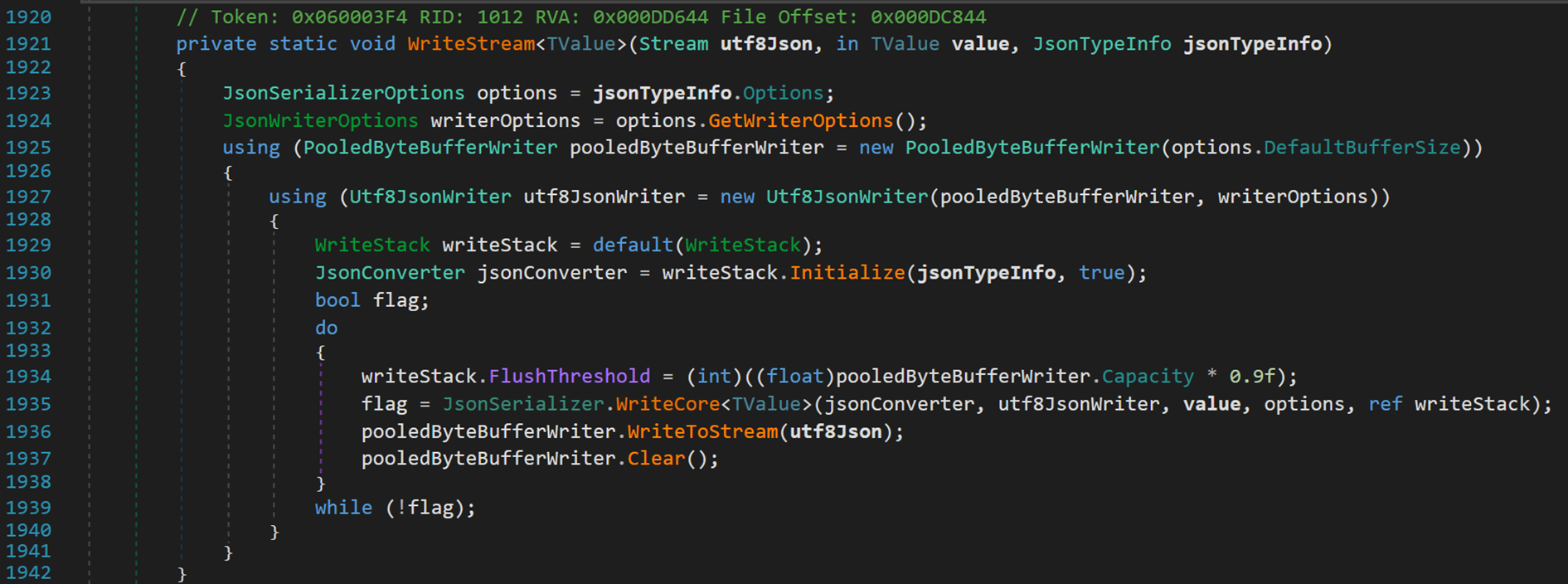
- Line 1923:類 JsonSerializerOptions,提供與 JsonSerializer 一起使用的選項。此處獲取 JsonSerializerOptions 與當前JsonTypeInfo範例關聯的值。
- Line 1924:結構體 JsonWriterOptions,允許使用者在使用 Utf8JsonWriter 編寫 JSON 時定義自定義行為。此處儲存 options 中對於寫入的行為規則(即,方式)。
- Line 1925:類 PooledByteBufferWriter,繼承了介面 IBufferWriter<byte>,表示可以向其中寫入byte 資料的一個輸出接收器;初始化大小為預設緩衝器 Buffer 的大小,其中,具體值為整型16384。
- Line 1927:類 Utf8JsonWriter,提供高效能的 API,以便提供 UTF-8 編碼 JSON 文字的只進和非快取編寫許可權。以無快取的形式順序寫入文字,預設情況下遵循 JSON RFC,但編寫註釋除外。此處,使用要寫入輸出的指定流和自定義選項初始化 Utf8JsonWriter 類的新範例。
- Line 1929:結構體 WriteStack,相當於一個寫入器,將待序列化元素依次通過流寫入檔案。
- Line 1930:類 JsonConverter,用於將物件或值轉換為 JSON,或是從 JSON 轉換為物件或值。此處儲存寫入器的初始狀態,將待序列化物件放入棧中。
- Line 1934:根據緩衝器的容量計算出一個標稱值,表示當前棧頂的物件(當前待序列化的物件)。
- Line 1935:判斷當前棧是否為空,是否可以繼續進行序列化。
- Line 1936:以 utf8 的形式將當前物件進行序列化。

- Line 1937:清空當前臨時變數中的物件,獲取下一個物件,繼續重複直到棧中沒有元素。
小結三
1. 總結流程:判斷是否有特殊需求(options),獲取資訊,壓入棧依次遍歷寫入流。
2. 其不需要大量的註釋性字串,只保留關鍵資訊。因此資料格式比較簡單, 易於讀寫, 格式都是壓縮的, 佔用頻寬小;檔案大小比 XML 序列化小很多,和二進位制序列化差別不大。
3. 時間方面,其不需要像二進位制序列化一樣進行過長的前搖以及頻繁的陣列複製,因此時間上比較快,但對資料的描述性比XML較差。
4. 對於二進位制序列化和 XML,其實生成的結果更加易讀、更便於肉眼檢查。
5. JSON 格式支援多種語言;能夠直接為伺服器端程式碼使用,大大簡化了伺服器端和使用者端的程式碼開發量,但是完成的任務不變,且易於維護。
6. 目前,在 C# 中JSON 序列化有三種形式使用 DataContractJsonSerialize r類、使用 JavaScriptSerialize r類、使用 JSON.NET 類庫。具體詳細資訊在此暫不做解釋,在此僅簡要說明三種方式優缺點:
(1)DataContract 和 Newtonsoft.Json 這兩種方式效率差別不大,隨著數量的增加 JavaScriptSerializer 的效率相對來說會低些,反序列化和其他兩種相差不大。。
(2)對於 DataTabl e的序列化,如果要使用 Json 資料通訊,使用 Newtonsoft.Json 更合適;如果是用 XML 做持久化,使用 DataContract 合適。
(3)在容錯方便,還是 Newtonsoft.Json 比較強。
【有關 C# 中的 Stream】
【參考文獻:Stream 類 (System.IO) | Microsoft Learn && C# 溫故而知新:Stream篇(—) - 逆時針の風 - 部落格園 (cnblogs.com)】
【注:礙於篇幅在此僅對該內容作簡要說明,更多詳細內容請參閱 Stream 類 (System.IO) | Microsoft Learn 】
一、相關基礎概念
1. 流:提供位元組序列的一般檢視。
2. 位元組序列:位元組物件都被儲存為連續的位元組序列,位元組按照一定的順序進行排序組成了位元組序列。
那麼流就可以稱為:供位元組序列流動的通道。在程式中反應為將物件排列起來,順序流向(放到)記憶體、檔案等地方。
二、 類 Stream

一個抽象類,繼承了類 MarshalByRefObject,兩個介面 IDisposable,IAsyncDisposable。
其中,類 MarshalByRefObject 用於允許在支援遠端處理的應用程式中跨應用程式域邊界存取物件,簡單來說是跨區域存取的;介面 IDisposable 用於自動解構物件,自動釋放非託管資源;IAsyncDisposable 提供一種用於非同步釋放非託管資源的機制。
—— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— —— ——
(一) 八個屬性
1. 唯讀的 Can 家族
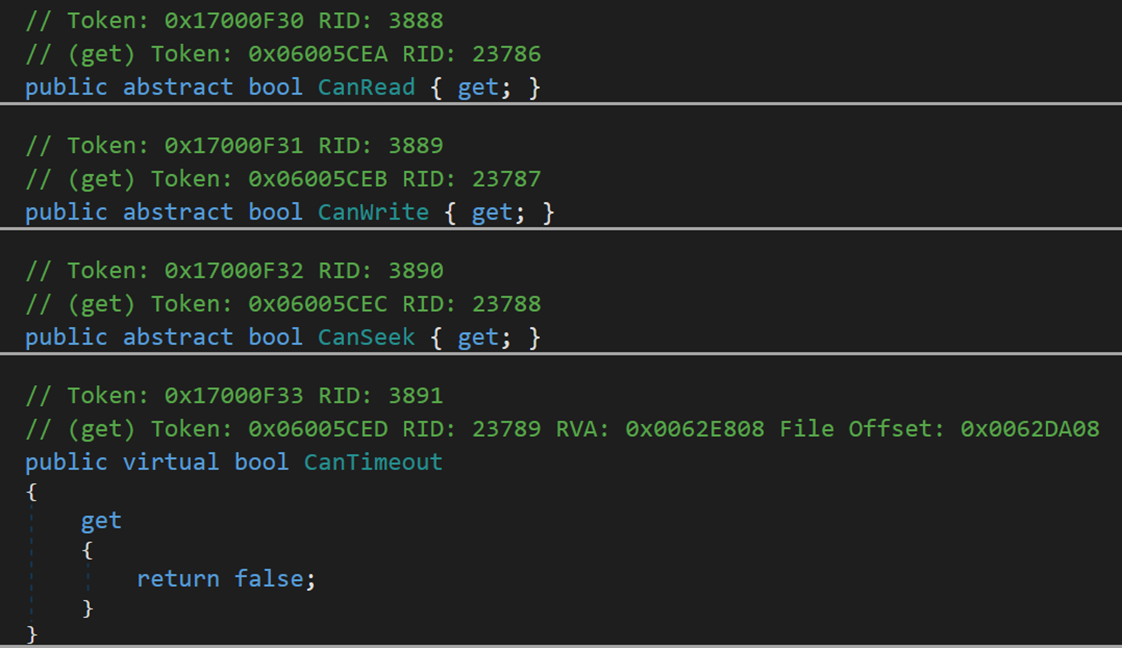
CanRead:判斷該流是否能夠讀取;
CanSeek:判斷該流是否支援跟蹤查詢;
CanWrite:判斷當前流是否可寫;
CanTimeOut 獲取一個值,該值確定當前流是否可以超時,如果網路連線中斷或丟失,會超時;如果要實現的流必須能夠超時,則應重寫此屬性以返回 true。
2. Length
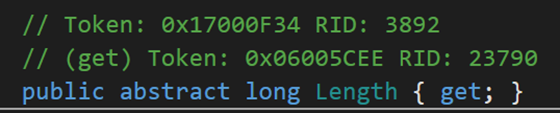
表示流的長度(以位元組為單位)。
3. Position
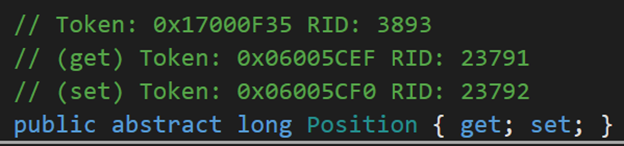
獲取或設定當前流中的位置。
雖然從字面中可以看出這個 Position 屬性只是標示了流中的一個位置而已,可是在實際開發中會發現,在很多ASP,NET 專案中上傳檔案或圖片時,會經歷過這樣一個痛苦:Stream物件被快取了,導致了 Position 屬性在流中無法找到正確的位置,因此每次使用流前必須將 Stream.Position 設定成0,但是這還不能根本上解決問題,最好的方法就是用 Using 語句將流物件包裹起來,用完後關閉回收即可。
4. Timeout 家族
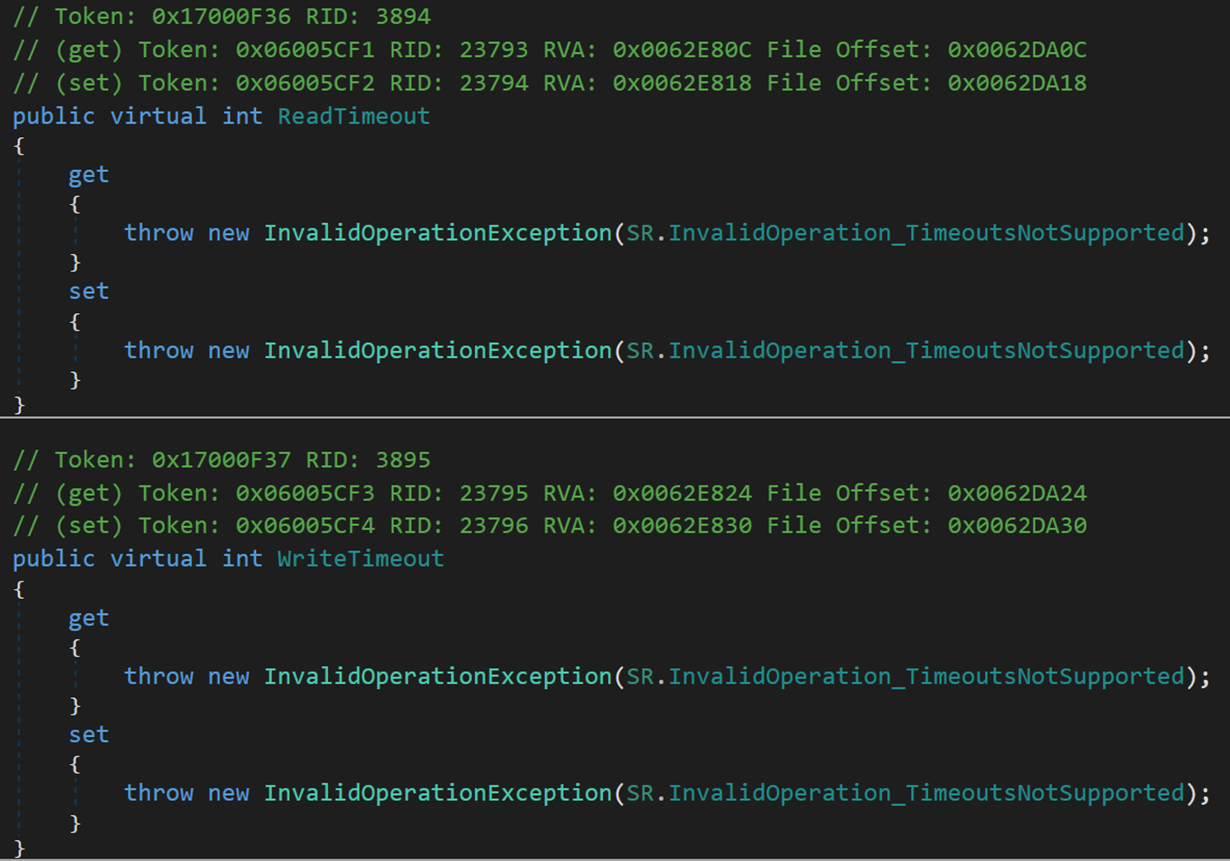
獲取或設定一個值(以毫秒為單位),該值確定流在超時前將嘗試讀取/寫入的時間,如果流不支援超時,則此屬性應引發異常。
(三) 常用方法
1. Write()
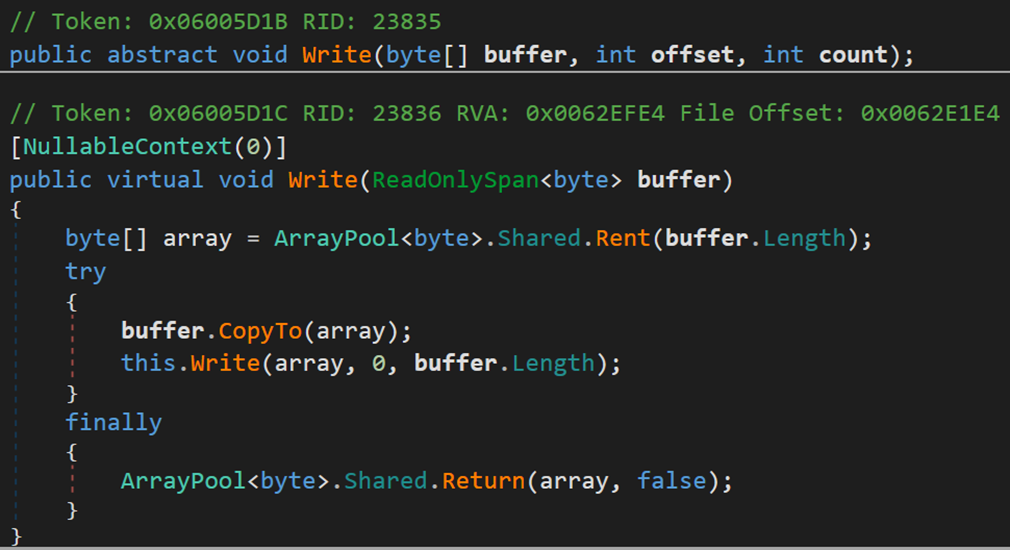
向當前流中寫入位元組序列,並將此流中的當前位置提升寫入的位元組數。(依次寫入)
buffer 陣列表示此方法將 count 個位元組從 buffer 複製到當前流;
offset 表示 buffer 中的從零開始的位元組偏移量,從此處開始將位元組複製到當前流;
count 為要寫入當前流的位元組數。
ReadOnlySpan<Byte> buffer 表示一個記憶體的區域,此方法將此區域的內容複製到當前流。
2. Read()
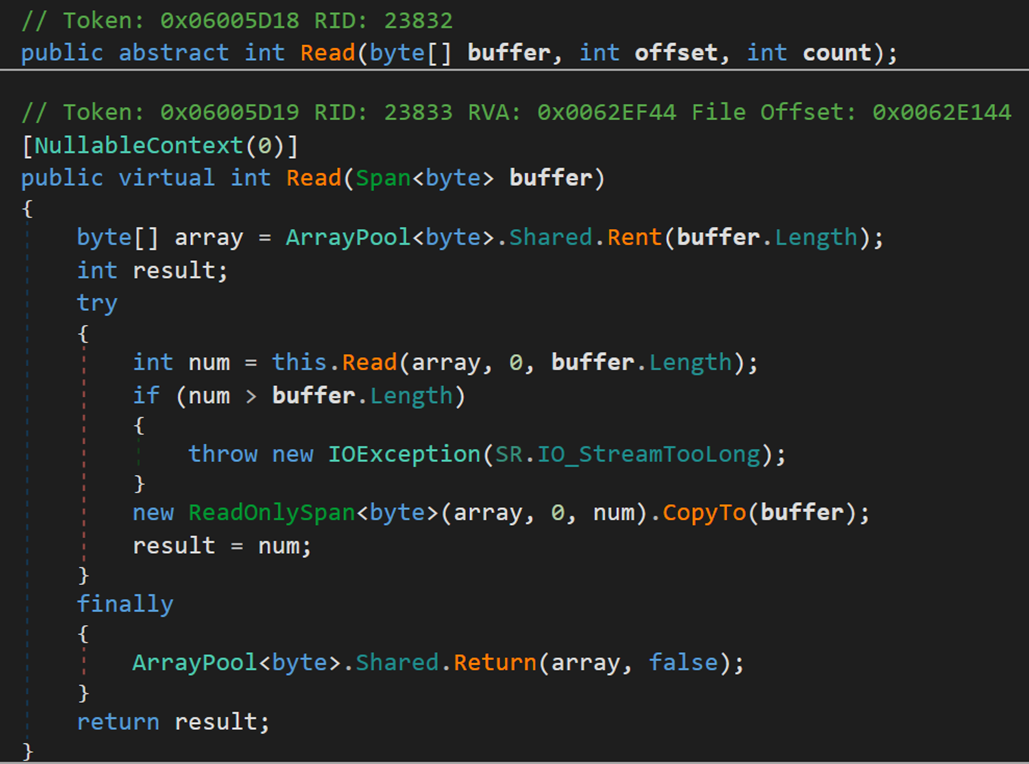
從當前流讀取位元組序列,並將此流中的位置提升讀取的位元組數。(依次讀取)
buffer 陣列,當此方法返回時,此緩衝區包含指定的字元陣列,此陣列中 offset 和 (offset + count - 1) 之間的值被從當前源中讀取的位元組所替換;
offset 表示 buffer 中的從零開始的位元組偏移量,從此處開始儲存從當前流中讀取的資料;
count 要從當前流中最多讀取的位元組數。
ReadOnlySpan<Byte> buffer 表示一個記憶體的區域,當此方法返回時,此區域的內容將替換為從當前源讀取的位元組。
3. Seek()

設定當前流中的位置。
還記得Position屬性麼?其實Seek方法就是重新設定流中的一個位置:如果 offset 為負,則要求新位置位於 origin 指定的位置之前,其間隔相差 offset 指定的位元組數;如果 offset 為零,則要求新位置位於由 origin 指定的位置處;如果 offset 為正,則要求新位置位於 origin 指定的位置之後,其間隔相差 offset 指定的位元組數。如:
Stream. Seek(-3, Origin.End); 表示在流末端往前數第3個位置。
Stream. Seek(0, Origin.Begin); 表示在流的開頭位置。
Stream. Seek(3, Origin.Current); 表示在流的當前位置往後數第三個位置。
4. Close()
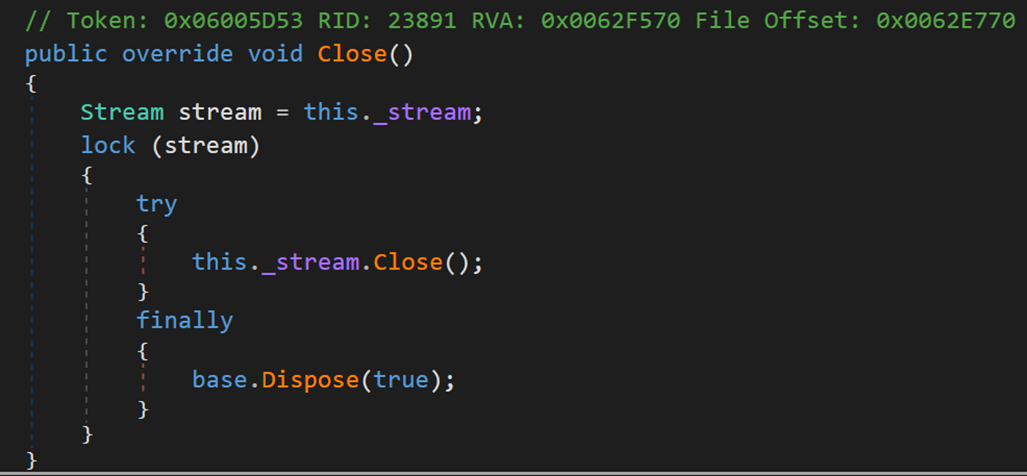
關閉當前流並釋放與之關聯的所有資源(如通訊端和檔案控制程式碼)。 不直接呼叫此方法,而應確保流得以正確釋放。
此方法呼叫方法 Dispose(),指定 true 以釋放所有資源。注意,在流關閉後嘗試操作流可能會引發 ObjectDisposedException;不關閉流可能導致資料被篡改或丟失。
總結
Stream 是所有流的抽象基礎類別。流是位元組序列的抽象,例如檔案、輸入/輸出裝置、程序中通訊管道或 TCP/IP 通訊端等。Stream 類及其派生類提供這些不同型別的輸入和輸出的一般檢視(方法/途徑),並將程式設計師與作業系統和基礎裝置的具體詳細資訊隔離開來。
流涉及三個基本操作:
- 可以從流中讀取。讀取是將資料從流傳輸到資料結構(如位元組陣列)中。
- 可以寫入流。寫入是指將資料從資料結構傳輸到流中。
- 流可以支援查詢。查詢是指查詢和修改流中的當前位置。 查詢功能取決於流具有的後備儲存的型別。例如,網路流沒有當前位置的統一概念,因此通常不支援查詢。
【有關 C# 中的反射 Reflection】
【參考文獻:反射 (C#) | Microsoft Learn && [整理]C#反射(Reflection)詳解 - SamWang - 部落格園 (cnblogs.com)】
【注:礙於篇幅在此僅對該內容作簡要說明,更多詳細內容請參閱 反射 (C#) | Microsoft Learn && C# 反射(Reflection) | 菜鳥教學 (runoob.com)】
一、反射的基本概念
用ILDasm工具瀏覽一個dll和exe的構成,這種機制稱為反射。這是 .Net 中獲取執行時型別資訊的方式,它用於在執行時通過程式設計方式獲得型別資訊。反射可以獲取已載入的程式集和在其中定義的型別(如類、介面和值型別)資訊。也可以使用反射在執行時建立型別範例,以及呼叫和存取這些範例。反射的一個主要功能就是查詢程式集的資訊。
二、執行時資訊的作用
舉個例子來說明,很多開發者喜歡在自己的軟體中留下一些介面,其他人可以編寫一些外掛來擴充軟體的功能,比如有一個媒體播放器,我希望以後可以很方便的擴充套件識別的格式,那麼我宣告一個介面。這個介面中包含一個Extension屬性,這個屬性返回支援的擴充套件名,另一個方法返回一個解碼器的物件(這裡假設了一個 Decoder 的類,這個類提供把檔案流解碼的功能,擴充套件外掛可以派生之),通過解碼器物件我就可以解釋檔案流。
那麼規定所有的解碼外掛都必須派生一個解碼器,並且實現這個介面,在GetDecoder方法中返回解碼器物件,並且將其型別的名稱設定到我的組態檔裡面。
這樣的話,我就不需要在開發播放器的時侯知道將來擴充套件的格式的型別,只需要從組態檔中獲取現在所有解碼器的型別名稱,而動態的建立媒體格式的物件,將其轉換為 IMediaFormat介面來使用。
三、優缺點
優點:
1. 反射提高了程式的靈活性和擴充套件性。
2. 降低耦合性,提高自適應能力。
3. 它允許程式建立和控制任何類的物件,無需提前寫死目標類。
缺點:
1. 效能問題:使用反射基本上是一種解釋操作,用於欄位和方法接入時要遠慢於直接程式碼。因此反射機制主要應用在對靈活性和拓展性要求很高的系統框架上,普通程式不建議使用。
2. 使用反射會模糊程式內部邏輯;程式設計師希望在原始碼中看到程式的邏輯,反射卻繞過了原始碼的技術,因而會帶來維護的問題,反射程式碼比相應的直接程式碼更復雜。