深度學習之折積模型應用
宣告
資料下載
連結:https://pan.baidu.com/s/1xANUtgIWgt7gcul6dnInhA
提取碼:oajj,請在開始之前下載好所需資料
1 - Packages
首先,我們要匯入一些庫
import math import numpy as np import h5py import matplotlib.pyplot as plt from matplotlib.pyplot import imread import scipy from PIL import Image import pandas as pd import tensorflow as tf import tensorflow.keras.layers as tfl from tensorflow.python.framework import ops from cnn_utils import * from test_utils import summary, comparator %matplotlib inline np.random.seed(1)
資料集我們使用的是 Happy House dataset
載入一下資料集吧!
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_happy_dataset() # Normalize image vectors X_train = X_train_orig/255. X_test = X_test_orig/255. # Reshape Y_train = Y_train_orig.T Y_test = Y_test_orig.T print ("number of training examples = " + str(X_train.shape[0])) print ("number of test examples = " + str(X_test.shape[0])) print ("X_train shape: " + str(X_train.shape)) print ("Y_train shape: " + str(Y_train.shape)) print ("X_test shape: " + str(X_test.shape)) print ("Y_test shape: " + str(Y_test.shape))
number of training examples = 600 number of test examples = 150 X_train shape: (600, 64, 64, 3) Y_train shape: (600, 1) X_test shape: (150, 64, 64, 3) Y_test shape: (150, 1)
結果發現我們使用的是64✖64,3通道的圖片
我們隨機的看張圖片
index = 120 plt.imshow(X_train_orig[index]) #display sample training image plt.show()

happyModel
- ZeroPadding2D: 填充三層 ,輸入應該為64 x 64 x 3
- Conv2D: 使用 32 個7x7 filters, stride 1
- BatchNormalization: for axis 3
- ReLU
- MaxPool2D: Using default parameters
- Flatten the previous output.
Fully-connected (Dense) layer: Apply a fully connected layer with 1 neuron and a sigmoid activation.
def happyModel(): """ 實現二進位制分類模型的正向傳播: ZEROPAD2D -> CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> FLATTEN -> DENSE 注意,為了簡化和分級,您將對所有值進行寫死 例如步幅和核心(濾波器)大小。 通常,函數應將這些值作為函數引數。 Arguments: None Returns: model -- TF Keras model (包含整個培訓過程資訊的物件) """ model = tf.keras.Sequential([ tf.keras.Input(shape=(64 , 64 ,3)), ## ZeroPadding2D with padding 3, input shape of 64 x 64 x 3 tfl.ZeroPadding2D(padding=3), # As import tensorflow.keras.layers as tfl ## Conv2D with 32 7x7 filters and stride of 1 tfl.Conv2D(filters=32,kernel_size=7,strides=1), ## BatchNormalization for axis 3 tfl.BatchNormalization(axis=3, momentum=0.99, epsilon=0.001), ## ReLU tfl.ReLU(), ## Max Pooling 2D with default parameters tfl.MaxPool2D(), ## Flatten layer tfl.Flatten(), ## Dense layer with 1 unit for output & 'sigmoid' activation tfl.Dense(1,activation='sigmoid') ]) return model
我們來測試一下:
happy_model = happyModel() # Print a summary for each layer for layer in summary(happy_model): print(layer)
['ZeroPadding2D', (None, 70, 70, 3), 0, ((3, 3), (3, 3))] ['Conv2D', (None, 64, 64, 32), 4736, 'valid', 'linear', 'GlorotUniform'] ['BatchNormalization', (None, 64, 64, 32), 128] ['ReLU', (None, 64, 64, 32), 0] ['MaxPooling2D', (None, 32, 32, 32), 0, (2, 2), (2, 2), 'valid'] ['Flatten', (None, 32768), 0] ['Dense', (None, 1), 32769, 'sigmoid']
現在您的模型已經建立,您可以編譯它,以便使用優化器進行訓練,而不必選擇。當字串精度指定為度量時,所使用的精度型別將根據所使用的損失函數自動轉換。這是TensorFlow內建的眾多優化之一,可以讓您的生活更輕鬆!
好了,讓我們去編譯它吧!
happy_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
是時候用.summary()方法檢查模型的引數了。這將顯示您擁有的圖層型別、輸出的形狀以及每個圖層中的引數數量。
happy_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
zero_padding2d (ZeroPadding (None, 70, 70, 3) 0
2D)
conv2d (Conv2D) (None, 64, 64, 32) 4736
batch_normalization (BatchN (None, 64, 64, 32) 128
ormalization)
re_lu (ReLU) (None, 64, 64, 32) 0
max_pooling2d (MaxPooling2D (None, 32, 32, 32) 0
)
flatten (Flatten) (None, 32768) 0
dense (Dense) (None, 1) 32769
=================================================================
Total params: 37,633
Trainable params: 37,569
Non-trainable params: 64
_________________________________________________________________
Train and Evaluate the Model
在建立了模型,使用您選擇的優化器和損失函數對其進行編譯,並對其內容進行了完整性檢查之後,現在就可以開始構建了!
只需呼叫.fit()進行訓練。就是這樣!無需進行小批次、節省或複雜的反向傳播計算。這一切都是為您完成的,因為您使用的是已經指定批次的TensorFlow資料集。如果您願意,您可以選擇指定紀元編號或小批次大小(例如,在未批次處理資料集的情況下)。
happy_model.evaluate(X_test, Y_test)
[0.14378029108047485, 0.9399999976158142]
很簡單,對吧?但是,如果您需要構建一個具有共用層、分支或多個輸入和輸出的模型呢?這正是Sequential憑藉其簡單而有限的功能無法幫助您的地方。
下一步:進入Functional API,這是一個稍微複雜、高度靈活的朋友。
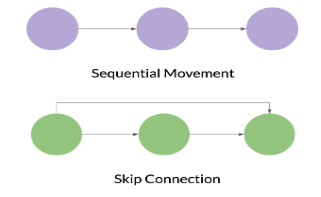
歡迎來到作業的下半部分,您將使用Keras靈活的Functional API構建一個ConvNet,它可以區分6個手語數位。
Functional API可以處理具有非線性拓撲、共用層以及具有多個輸入或輸出的層的模型。想象一下,當Sequential API要求模型以線性方式在其層中移動時,Functional API允許更大的靈活性。在Sequential是一條直線的情況下,Functional模型是一個圖,其中層的節點可以以多種方式連線。
在下面的視覺範例中,順序模型顯示了一個可能的運動方向,與跳過連線形成對比,這只是構建功能模型的多種方式之一。您可能已經猜到,跳過連線會跳過網路中的某一層,並將輸出饋送到網路中的稍後一層。別擔心,你很快就會花更多時間在跳過連線上!
我們載入一下資料集
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_signs_dataset()
隨機看一個資料
index = 4 plt.imshow(X_train_orig[index]) print ("y = " + str(np.squeeze(Y_train_orig[:, index])))
y = 2

在之前的學習中,
您為該資料集構建了一個完全連線的網路。但由於這是一個影象資料集,因此將ConvNet應用於它更為自然。
首先,讓我們檢查資料的形狀。
X_train = X_train_orig/255. X_test = X_test_orig/255. Y_train = convert_to_one_hot(Y_train_orig, 6).T Y_test = convert_to_one_hot(Y_test_orig, 6).T print ("number of training examples = " + str(X_train.shape[0])) print ("number of test examples = " + str(X_test.shape[0])) print ("X_train shape: " + str(X_train.shape)) print ("Y_train shape: " + str(Y_train.shape)) print ("X_test shape: " + str(X_test.shape)) print ("Y_test shape: " + str(Y_test.shape))
number of training examples = 1080 number of test examples = 120 X_train shape: (1080, 64, 64, 3) Y_train shape: (1080, 6) X_test shape: (120, 64, 64, 3) Y_test shape: (120, 6)
Forward Propagation
- Conv2D:8個4✖4的 filters, stride 1, 填充 is "SAME"
- ReLU
- MaxPool2D: 使用一個8✖8 filter size and 一個(8,8)步長, padding is "SAME"
- Conv2D: Use 16 2 by 2 filters, stride 1, padding is "SAME"
- ReLU
- MaxPool2D: Use a 4 by 4 filter size and a 4 by 4 stride, padding is "SAME"
- Flatten the previous output.
- Fully-connected (Dense) layer:應用具有6個神經元的完全連線層和softmax啟用。
下面我們建立模型
def convolutional_model(input_shape): """ Implements the forward propagation for the model: CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> DENSE 注意,為了簡化和分級,您將寫死一些值 例如步幅和核心(濾波器)大小。 通常,函數應將這些值作為函數引數。 Arguments: input_img -- input dataset, of shape (input_shape) Returns: model -- TF Keras model (包含整個培訓過程資訊的物件) """ input_img = tf.keras.Input(shape=input_shape) ## CONV2D: 8 filters 4x4, stride of 1, padding 'SAME' Z1 = tfl.Conv2D(filters= 8. , kernel_size=4 , padding='same',strides=1)(input_img) ## RELU A1 = tfl.ReLU()(Z1) ## MAXPOOL: window 8x8, stride 8, padding 'SAME' P1 = tfl.MaxPool2D(pool_size=8, strides=8, padding='SAME')(A1) ## CONV2D: 16 filters 2x2, stride 1, padding 'SAME' Z2 = tfl.Conv2D(filters= 16. , kernel_size=2 , padding='same',strides=1)(P1) ## RELU A2 = tfl.ReLU()(Z2) ## MAXPOOL: window 4x4, stride 4, padding 'SAME' P2 = tfl.MaxPool2D(pool_size=4, strides=4, padding='SAME')(A2) ## FLATTEN F = tfl.Flatten()(P2) ## 全連線層 ##輸出層6個神經元。提示:其中一個引數應該是「activation='softmax'」 outputs = tfl.Dense(units= 6 , activation='softmax')(F) model = tf.keras.Model(inputs=input_img, outputs=outputs) return model
編譯並檢查模型的引數
conv_model = convolutional_model((64, 64, 3)) conv_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) conv_model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 64, 64, 3)] 0
conv2d_1 (Conv2D) (None, 64, 64, 8) 392
re_lu_1 (ReLU) (None, 64, 64, 8) 0
max_pooling2d_1 (MaxPooling (None, 8, 8, 8) 0
2D)
conv2d_2 (Conv2D) (None, 8, 8, 16) 528
re_lu_2 (ReLU) (None, 8, 8, 16) 0
max_pooling2d_2 (MaxPooling (None, 2, 2, 16) 0
2D)
flatten_1 (Flatten) (None, 64) 0
dense_1 (Dense) (None, 6) 390
=================================================================
Total params: 1,310
Trainable params: 1,310
Non-trainable params: 0
_________________________________________________________________
Train the Model
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, Y_train)).batch(64) test_dataset = tf.data.Dataset.from_tensor_slices((X_test, Y_test)).batch(64) history = conv_model.fit(train_dataset, epochs=100, validation_data=test_dataset)
Epoch 59/100 17/17 [==============================] - 1s 63ms/step - loss: 0.5240 - accuracy: 0.8296 - val_loss: 0.6141 - val_accuracy: 0.8000 Epoch 60/100 17/17 [==============================] - 1s 45ms/step - loss: 0.5175 - accuracy: 0.8333 - val_loss: 0.6084 - val_accuracy: 0.8083 Epoch 61/100 17/17 [==============================] - 1s 53ms/step - loss: 0.5093 - accuracy: 0.8352 - val_loss: 0.6047 - val_accuracy: 0.8250 Epoch 62/100 17/17 [==============================] - 1s 50ms/step - loss: 0.5044 - accuracy: 0.8370 - val_loss: 0.5991 - val_accuracy: 0.8083 Epoch 63/100 17/17 [==============================] - 1s 53ms/step - loss: 0.4981 - accuracy: 0.8333 - val_loss: 0.5955 - val_accuracy: 0.8167 Epoch 64/100 17/17 [==============================] - 1s 57ms/step - loss: 0.4902 - accuracy: 0.8380 - val_loss: 0.5926 - val_accuracy: 0.8250 Epoch 65/100 17/17 [==============================] - 1s 48ms/step - loss: 0.4853 - accuracy: 0.8444 - val_loss: 0.5882 - val_accuracy: 0.8083 Epoch 66/100 17/17 [==============================] - 1s 48ms/step - loss: 0.4794 - accuracy: 0.8472 - val_loss: 0.5839 - val_accuracy: 0.8083 Epoch 67/100 17/17 [==============================] - 1s 44ms/step - loss: 0.4724 - accuracy: 0.8519 - val_loss: 0.5809 - val_accuracy: 0.8167 Epoch 68/100 17/17 [==============================] - 1s 54ms/step - loss: 0.4680 - accuracy: 0.8528 - val_loss: 0.5760 - val_accuracy: 0.8083 Epoch 69/100 17/17 [==============================] - 1s 46ms/step - loss: 0.4623 - accuracy: 0.8546 - val_loss: 0.5719 - val_accuracy: 0.8250 Epoch 70/100 17/17 [==============================] - 1s 49ms/step - loss: 0.4559 - accuracy: 0.8574 - val_loss: 0.5692 - val_accuracy: 0.8083 Epoch 71/100 17/17 [==============================] - 1s 57ms/step - loss: 0.4518 - accuracy: 0.8593 - val_loss: 0.5650 - val_accuracy: 0.8083 Epoch 72/100 17/17 [==============================] - 1s 60ms/step - loss: 0.4452 - accuracy: 0.8620 - val_loss: 0.5624 - val_accuracy: 0.8250 Epoch 73/100 17/17 [==============================] - 1s 52ms/step - loss: 0.4415 - accuracy: 0.8639 - val_loss: 0.5590 - val_accuracy: 0.8167 Epoch 74/100 17/17 [==============================] - 1s 55ms/step - loss: 0.4361 - accuracy: 0.8648 - val_loss: 0.5554 - val_accuracy: 0.8250 Epoch 75/100 17/17 [==============================] - 1s 58ms/step - loss: 0.4298 - accuracy: 0.8704 - val_loss: 0.5528 - val_accuracy: 0.8333 Epoch 76/100 17/17 [==============================] - 1s 62ms/step - loss: 0.4262 - accuracy: 0.8685 - val_loss: 0.5490 - val_accuracy: 0.8250 Epoch 77/100 17/17 [==============================] - 1s 48ms/step - loss: 0.4215 - accuracy: 0.8713 - val_loss: 0.5460 - val_accuracy: 0.8250 Epoch 78/100 17/17 [==============================] - 1s 46ms/step - loss: 0.4151 - accuracy: 0.8787 - val_loss: 0.5436 - val_accuracy: 0.8250 Epoch 79/100 17/17 [==============================] - 1s 43ms/step - loss: 0.4113 - accuracy: 0.8787 - val_loss: 0.5407 - val_accuracy: 0.8167 Epoch 80/100 17/17 [==============================] - 1s 43ms/step - loss: 0.4062 - accuracy: 0.8806 - val_loss: 0.5384 - val_accuracy: 0.8167 Epoch 81/100 17/17 [==============================] - 1s 48ms/step - loss: 0.4020 - accuracy: 0.8806 - val_loss: 0.5348 - val_accuracy: 0.8167 Epoch 82/100 17/17 [==============================] - 1s 50ms/step - loss: 0.3962 - accuracy: 0.8824 - val_loss: 0.5323 - val_accuracy: 0.8167 Epoch 83/100 17/17 [==============================] - 1s 45ms/step - loss: 0.3927 - accuracy: 0.8824 - val_loss: 0.5297 - val_accuracy: 0.8250 Epoch 84/100 17/17 [==============================] - 1s 51ms/step - loss: 0.3881 - accuracy: 0.8843 - val_loss: 0.5272 - val_accuracy: 0.8250 Epoch 85/100 17/17 [==============================] - 1s 46ms/step - loss: 0.3832 - accuracy: 0.8870 - val_loss: 0.5249 - val_accuracy: 0.8250 Epoch 86/100 17/17 [==============================] - 1s 53ms/step - loss: 0.3796 - accuracy: 0.8898 - val_loss: 0.5215 - val_accuracy: 0.8250 Epoch 87/100 17/17 [==============================] - 1s 56ms/step - loss: 0.3743 - accuracy: 0.8889 - val_loss: 0.5196 - val_accuracy: 0.8250 Epoch 88/100 17/17 [==============================] - 1s 48ms/step - loss: 0.3710 - accuracy: 0.8907 - val_loss: 0.5164 - val_accuracy: 0.8250 Epoch 89/100 17/17 [==============================] - 1s 45ms/step - loss: 0.3660 - accuracy: 0.8917 - val_loss: 0.5139 - val_accuracy: 0.8333 Epoch 90/100 17/17 [==============================] - 1s 45ms/step - loss: 0.3626 - accuracy: 0.8917 - val_loss: 0.5106 - val_accuracy: 0.8333 Epoch 91/100 17/17 [==============================] - 1s 48ms/step - loss: 0.3579 - accuracy: 0.8944 - val_loss: 0.5090 - val_accuracy: 0.8500 Epoch 92/100 17/17 [==============================] - 1s 49ms/step - loss: 0.3547 - accuracy: 0.8935 - val_loss: 0.5060 - val_accuracy: 0.8417 Epoch 93/100 17/17 [==============================] - 1s 44ms/step - loss: 0.3501 - accuracy: 0.8944 - val_loss: 0.5038 - val_accuracy: 0.8500 Epoch 94/100 17/17 [==============================] - 1s 47ms/step - loss: 0.3468 - accuracy: 0.8954 - val_loss: 0.5014 - val_accuracy: 0.8417 Epoch 95/100 17/17 [==============================] - 1s 43ms/step - loss: 0.3424 - accuracy: 0.8954 - val_loss: 0.4996 - val_accuracy: 0.8500 Epoch 96/100 17/17 [==============================] - 1s 64ms/step - loss: 0.3395 - accuracy: 0.8963 - val_loss: 0.4970 - val_accuracy: 0.8417 Epoch 97/100 17/17 [==============================] - 1s 47ms/step - loss: 0.3351 - accuracy: 0.9000 - val_loss: 0.4950 - val_accuracy: 0.8417 Epoch 98/100 17/17 [==============================] - 1s 54ms/step - loss: 0.3323 - accuracy: 0.8981 - val_loss: 0.4933 - val_accuracy: 0.8333 Epoch 99/100 17/17 [==============================] - 1s 48ms/step - loss: 0.3280 - accuracy: 0.9000 - val_loss: 0.4916 - val_accuracy: 0.8417 Epoch 100/100 17/17 [==============================] - 1s 57ms/step - loss: 0.3251 - accuracy: 0.9028 - val_loss: 0.4894 - val_accuracy: 0.8333
history物件是.fit()操作的輸出,並提供記憶體中所有損失和度量值的記錄。它儲存為字典,您可以在history中檢索。history:
history.history
{'loss': [1.7924431562423706,
1.7829910516738892,
1.7774927616119385,
1.7714649438858032,
1.7632440328598022,
1.7526339292526245,
1.7386524677276611,
1.7180964946746826,
1.6927790641784668,
1.662406325340271,
1.6234209537506104,
1.5787827968597412,
1.530578374862671,
1.4795559644699097,
1.4249759912490845,
1.366114616394043,
1.306186556816101,
1.2475863695144653,
1.1895930767059326,
1.1388928890228271,
1.097584843635559,
1.0567398071289062,
1.022887110710144,
0.988143265247345,
0.958622932434082,
0.9344858527183533,
0.9079993367195129,
0.885870635509491,
0.8637591600418091,
0.8459751605987549,
0.8278167247772217,
0.8083643913269043,
0.7896391153335571,
0.7741439938545227,
0.7585340142250061,
0.7439262866973877,
0.7297463417053223,
0.7170448303222656,
0.7035995125770569,
0.6920593976974487,
0.679717481136322,
0.6682245135307312,
0.6566773653030396,
0.6468732953071594,
0.636225163936615,
0.6263309121131897,
0.6172266602516174,
0.6075870990753174,
0.5992370247840881,
0.590358316898346,
0.5821788907051086,
0.5736473798751831,
0.5663847327232361,
0.5585536956787109,
0.5508677959442139,
0.5444035530090332,
0.5386385917663574,
0.5295939445495605,
0.5240201354026794,
0.5174545049667358,
0.5093420743942261,
0.5043843984603882,
0.4980504810810089,
0.4902321696281433,
0.48526430130004883,
0.4794261157512665,
0.47238555550575256,
0.4679552912712097,
0.4623057246208191,
0.45586806535720825,
0.4517609477043152,
0.4452061355113983,
0.4414933919906616,
0.43607473373413086,
0.42984598875045776,
0.426226943731308,
0.42150384187698364,
0.41507458686828613,
0.411263108253479,
0.40617814660072327,
0.4020026624202728,
0.3962164521217346,
0.3927241563796997,
0.388070285320282,
0.3831581771373749,
0.3795756697654724,
0.3743235170841217,
0.370996356010437,
0.36598825454711914,
0.36259210109710693,
0.3579387068748474,
0.3546842932701111,
0.3501478433609009,
0.3468477129936218,
0.3424193859100342,
0.33947113156318665,
0.33507341146469116,
0.33227092027664185,
0.3280133008956909,
0.3250682055950165],
'accuracy': [0.18703703582286835,
0.23888888955116272,
0.25740739703178406,
0.2620370388031006,
0.31018519401550293,
0.35185185074806213,
0.3731481432914734,
0.39351850748062134,
0.42500001192092896,
0.4472222328186035,
0.4722222089767456,
0.4833333194255829,
0.5027777552604675,
0.519444465637207,
0.5370370149612427,
0.5574073791503906,
0.5694444179534912,
0.5981481671333313,
0.6277777552604675,
0.6425926089286804,
0.6518518328666687,
0.6564815044403076,
0.6685185432434082,
0.6722221970558167,
0.6879629492759705,
0.6953703761100769,
0.7009259462356567,
0.7120370268821716,
0.7212963104248047,
0.7324073910713196,
0.7388888597488403,
0.7425925731658936,
0.7509258985519409,
0.7537037134170532,
0.7564814686775208,
0.7638888955116272,
0.769444465637207,
0.7740740776062012,
0.7731481194496155,
0.7824074029922485,
0.7842592597007751,
0.7916666865348816,
0.7962962985038757,
0.7990740537643433,
0.8009259104728699,
0.8018518686294556,
0.8064814805984497,
0.8083333373069763,
0.8101851940155029,
0.8092592358589172,
0.8120370507240295,
0.8157407641410828,
0.8203703761100769,
0.8194444179534912,
0.8203703761100769,
0.8222222328186035,
0.8222222328186035,
0.8296296000480652,
0.8296296000480652,
0.8333333134651184,
0.835185170173645,
0.8370370268821716,
0.8333333134651184,
0.8379629850387573,
0.8444444537162781,
0.8472222089767456,
0.8518518805503845,
0.8527777791023254,
0.854629635810852,
0.8574073910713196,
0.8592592477798462,
0.8620370626449585,
0.8638888597488403,
0.864814817905426,
0.8703703880310059,
0.8685185313224792,
0.8712962865829468,
0.8787037134170532,
0.8787037134170532,
0.8805555701255798,
0.8805555701255798,
0.8824074268341064,
0.8824074268341064,
0.8842592835426331,
0.8870370388031006,
0.8898147940635681,
0.8888888955116272,
0.8907407522201538,
0.8916666507720947,
0.8916666507720947,
0.894444465637207,
0.8935185074806213,
0.894444465637207,
0.895370364189148,
0.895370364189148,
0.8962963223457336,
0.8999999761581421,
0.8981481194496155,
0.8999999761581421,
0.9027777910232544],
'val_loss': [1.7880679368972778,
1.7836401462554932,
1.7796905040740967,
1.7741940021514893,
1.7678734064102173,
1.758245825767517,
1.7452706098556519,
1.726967692375183,
1.702684998512268,
1.6717331409454346,
1.6347414255142212,
1.5910009145736694,
1.5450935363769531,
1.4938915967941284,
1.4376522302627563,
1.3787978887557983,
1.3131662607192993,
1.2557700872421265,
1.2034367322921753,
1.1515480279922485,
1.111528754234314,
1.0731432437896729,
1.0447036027908325,
1.0127633810043335,
0.9859100580215454,
0.9654880166053772,
0.9404958486557007,
0.9209955930709839,
0.8992679119110107,
0.8814808130264282,
0.8653653860092163,
0.8504172563552856,
0.8345377445220947,
0.8210867643356323,
0.8074197173118591,
0.7955043315887451,
0.7829695343971252,
0.7711904048919678,
0.759569525718689,
0.7491328120231628,
0.738180935382843,
0.7290382385253906,
0.7184242010116577,
0.7106221914291382,
0.7016199827194214,
0.6938892006874084,
0.6858749985694885,
0.6783573031425476,
0.6711333394050598,
0.6637560129165649,
0.6570908427238464,
0.6508013606071472,
0.6447855234146118,
0.6384889483451843,
0.6340672969818115,
0.6277063488960266,
0.6241180300712585,
0.6192630529403687,
0.6140884757041931,
0.6084011197090149,
0.6047238707542419,
0.5990610122680664,
0.5955398678779602,
0.5925867557525635,
0.5882076025009155,
0.5839186310768127,
0.5809137225151062,
0.5759595632553101,
0.5718620419502258,
0.5692002773284912,
0.5650399327278137,
0.5624229907989502,
0.5589754581451416,
0.5554342865943909,
0.5528450012207031,
0.548973798751831,
0.5460191965103149,
0.5436446070671082,
0.5407302379608154,
0.5384419560432434,
0.5347636938095093,
0.5323173999786377,
0.5297467112541199,
0.5271559953689575,
0.5248605608940125,
0.5214855074882507,
0.5195692181587219,
0.5163654685020447,
0.5138646960258484,
0.5105695128440857,
0.5090406537055969,
0.506039023399353,
0.5038312077522278,
0.5013726353645325,
0.4996020495891571,
0.4970282018184662,
0.49498558044433594,
0.4933158755302429,
0.49158433079719543,
0.4893797039985657],
'val_accuracy': [0.19166666269302368,
0.22499999403953552,
0.19166666269302368,
0.23333333432674408,
0.2916666567325592,
0.3499999940395355,
0.34166666865348816,
0.3333333432674408,
0.36666667461395264,
0.375,
0.4166666567325592,
0.46666666865348816,
0.5083333253860474,
0.5,
0.5416666865348816,
0.574999988079071,
0.6083333492279053,
0.5833333134651184,
0.6166666746139526,
0.6416666507720947,
0.6416666507720947,
0.625,
0.6333333253860474,
0.6416666507720947,
0.6499999761581421,
0.6499999761581421,
0.6583333611488342,
0.6666666865348816,
0.6666666865348816,
0.6666666865348816,
0.6666666865348816,
0.675000011920929,
0.6833333373069763,
0.699999988079071,
0.7083333134651184,
0.7083333134651184,
0.7083333134651184,
0.7250000238418579,
0.7333333492279053,
0.7416666746139526,
0.7583333253860474,
0.7666666507720947,
0.7749999761581421,
0.7749999761581421,
0.7749999761581421,
0.7749999761581421,
0.7833333611488342,
0.7916666865348816,
0.7916666865348816,
0.800000011920929,
0.800000011920929,
0.8083333373069763,
0.8083333373069763,
0.8083333373069763,
0.8083333373069763,
0.800000011920929,
0.800000011920929,
0.8166666626930237,
0.800000011920929,
0.8083333373069763,
0.824999988079071,
0.8083333373069763,
0.8166666626930237,
0.824999988079071,
0.8083333373069763,
0.8083333373069763,
0.8166666626930237,
0.8083333373069763,
0.824999988079071,
0.8083333373069763,
0.8083333373069763,
0.824999988079071,
0.8166666626930237,
0.824999988079071,
0.8333333134651184,
0.824999988079071,
0.824999988079071,
0.824999988079071,
0.8166666626930237,
0.8166666626930237,
0.8166666626930237,
0.8166666626930237,
0.824999988079071,
0.824999988079071,
0.824999988079071,
0.824999988079071,
0.824999988079071,
0.824999988079071,
0.8333333134651184,
0.8333333134651184,
0.8500000238418579,
0.8416666388511658,
0.8500000238418579,
0.8416666388511658,
0.8500000238418579,
0.8416666388511658,
0.8416666388511658,
0.8333333134651184,
0.8416666388511658,
0.8333333134651184]}
現在,使用history.history視覺化時間損失:
df_loss_acc = pd.DataFrame(history.history) df_loss= df_loss_acc[['loss','val_loss']] df_loss.rename(columns={'loss':'train','val_loss':'validation'},inplace=True) df_acc= df_loss_acc[['accuracy','val_accuracy']] df_acc.rename(columns={'accuracy':'train','val_accuracy':'validation'},inplace=True) df_loss.plot(title='Model loss',figsize=(12,8)).set(xlabel='Epoch',ylabel='Loss') df_acc.plot(title='Model Accuracy',figsize=(12,8)).set(xlabel='Epoch',ylabel='Accuracy') plt.show()

