記一次spark資料傾斜實踐
參考文章:
巨量資料專案——傾斜資料的分割區優化
資料傾斜概念
什麼是資料傾斜
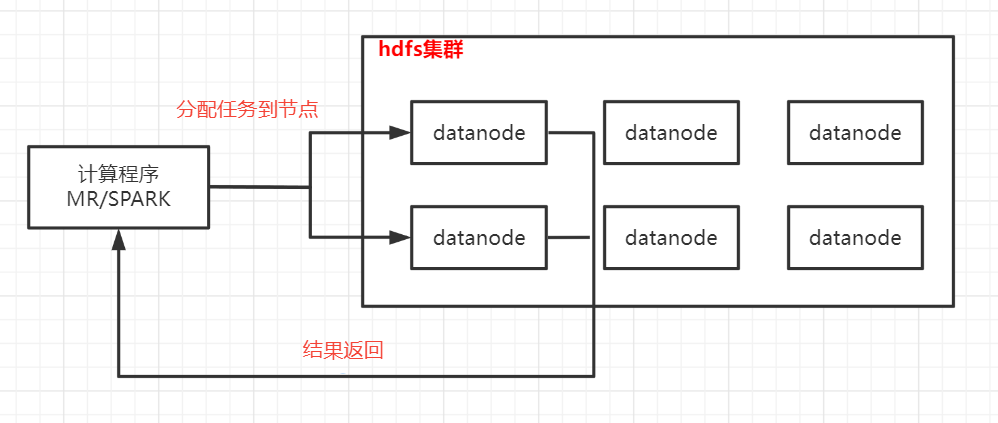
巨量資料下大部分框架的處理原理都是參考mapreduce的思想:分而治之和移動計算,即提前將計算程式生成好然後傳送到不同的節點起jvm程序執行任務,每個任務處理一小部分資料,最終將每個任務的處理結果彙總,完成一次計算。
如果在分配任務的時候,資料分配不均,導致一個任務要處理的資料量遠遠大於其他任務,那麼整個作業一直在等待這個任務完成,而其他機器的資源完全沒利用起來,導致效率極差;如果資料量過大,可能發生傾斜的任務會出現OOM(記憶體溢位)的異常,使得整個作業失敗。因此對於資料傾斜要能改則改
案例現象
案例為紀錄檔資料,已做清洗,欄位如第一行,重點欄位是client_ip和target_ip,需求是求不同target_ip的UV。
實現方式大致是:
1.讀取檔案,按,切分取2個目標欄位client_ip和target_ip
2.按target_ip分組,彙總所有client_ip到一個列表
3.對client_ip列表統計去重數量,輸出 <target_ip,UV>
因為是傾斜案例,在1中可以過濾出幾個樣例ip模擬傾斜場景。

程式碼
package skew
import org.apache.spark.{SparkConf, SparkContext}
import java.util
object SkewSample {
def main(args: Array[String]): Unit = {
skew1()
}
def skew1():Unit = {
// val conf = new SparkConf().setAppName("DataSkewTest01").setMaster("local[4]")
val conf = new SparkConf().setAppName("DataSkewTest01")
val spark = new SparkContext(conf)
val rawRDD = spark.textFile("/root/data/skewdata.csv")//讀取資料來源
/**篩選滿足需要的資料,已到達資料傾斜的目的*/
val filteredRDD = rawRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185") || target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
/**根據目的ip進行彙總,將存取同一個目的ip的所有使用者端ip進行彙總*/
val reducedRDD = filteredRDD.map(line => {
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index) //為了讓後續聚合後的value資料量儘可能的少,只取ip的前段部分
(target_ip,Array(subClientIP))
}).reduceByKey(_++_,4)//將Array中的元素進行合併,然後將分割區調整為已知的4個
//reducedRDD.foreach(x => println(x._1, x._2.length)) //檢視傾斜key
/**將存取同一個目的ip的使用者端,再次根據使用者端ip進行進一步統計*/
val targetRDD = reducedRDD.map(kv => {
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
targetRDD.foreach(x => println(x._1, x._2.size()))
// targetRDD.saveAsTextFile("tmp/DataSkew01") //結果資料儲存目錄
// Thread.sleep(600000)
}
}
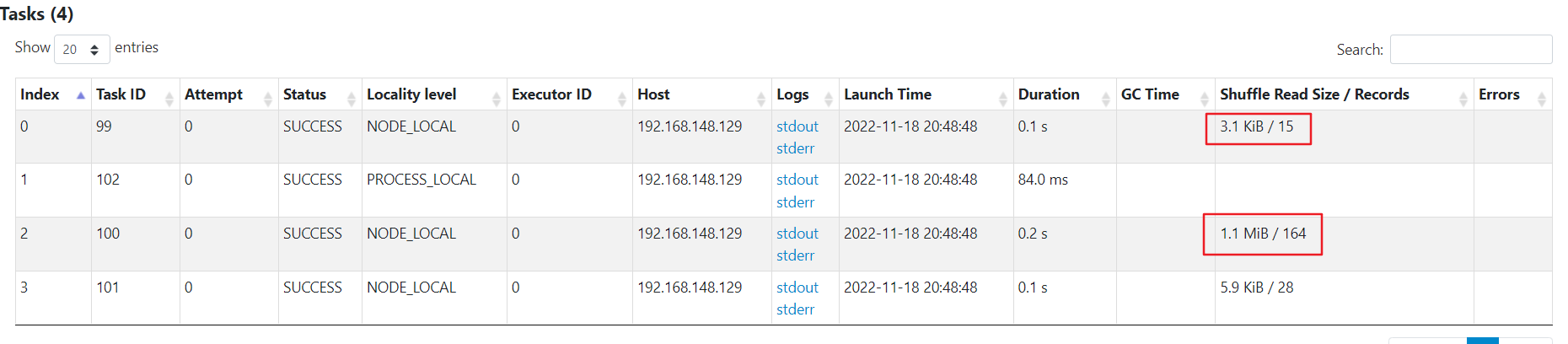
傾斜現象
因為資料量小,所以沒有執行很長的時間,但是可以看到有一個任務處理的資料量是其他的百倍左右。
問題分析
案例中最終的分割區數量,以及分割區鍵,還有傾斜鍵都是一個確定的值,因此可以考慮兩種優化方式:
-
單獨處理:案例只有一個傾斜鍵,可以考慮將這個傾斜鍵和非傾斜鍵的資料過濾到2個RDD中,單獨處理。這種方式會生成2個JOB,讀兩次源資料,雖然可以用快取來提速,但是資料量大了以後快取也是要落盤的,所以不是特別好
-
加鹽減鹽:對於傾斜鍵進行加鹽,即在傾斜鍵本身後加上0-100的數位,改變它的hash值以便將資料分散到不同的分割區中,然後對結果進行聚合,這樣可以顯著改善傾斜情況,最終還要對加鹽的資料進行去鹽,即將傾斜鍵後面的0-100數位去掉,然後再一次彙總,得到最終結果。 實踐的時候又可以將去鹽分為兩步由100->10,10->1這樣,降低資料波動,後續有一次去鹽和二次去鹽的結果對比。
優化結果對比
未優化
單個任務處理的最巨量資料量為1M

單獨處理
可以看到spark起了2個job來處理,傾斜鍵的job已經將資料均勻分散到多個任務了。如果資料量很大,即使用了快取,效果也不一定好,可能還更差。

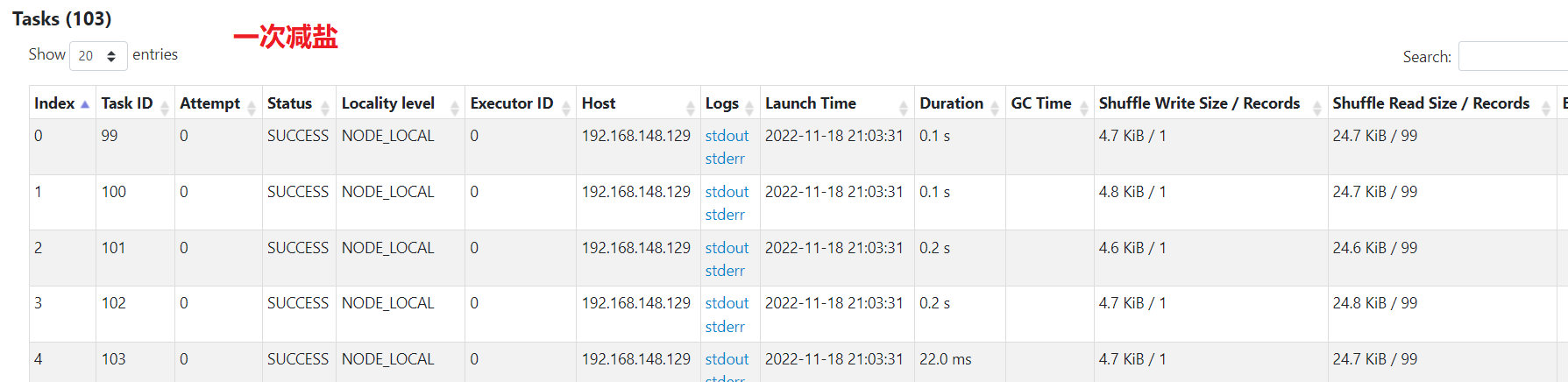
一次減鹽
資料已經被均分到多個任務,不再傾斜。不過最後彙總還是單個任務彙總,處理的最巨量資料量為400kb

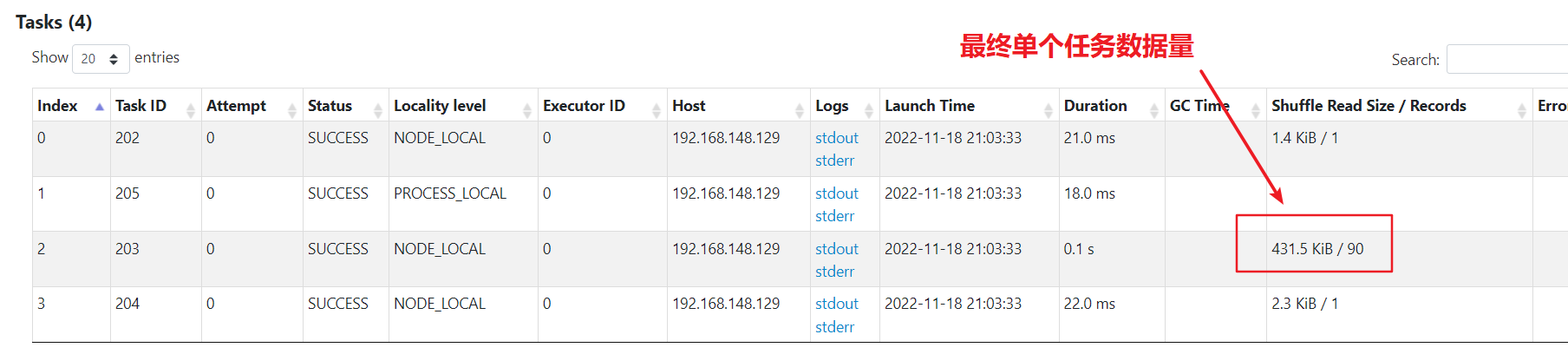
二次減鹽
資料已經被均分到多個任務,不再傾斜。比一次減鹽多了一次shuffle,最後單個任務彙總處理的最巨量資料量為50kb,比較均勻
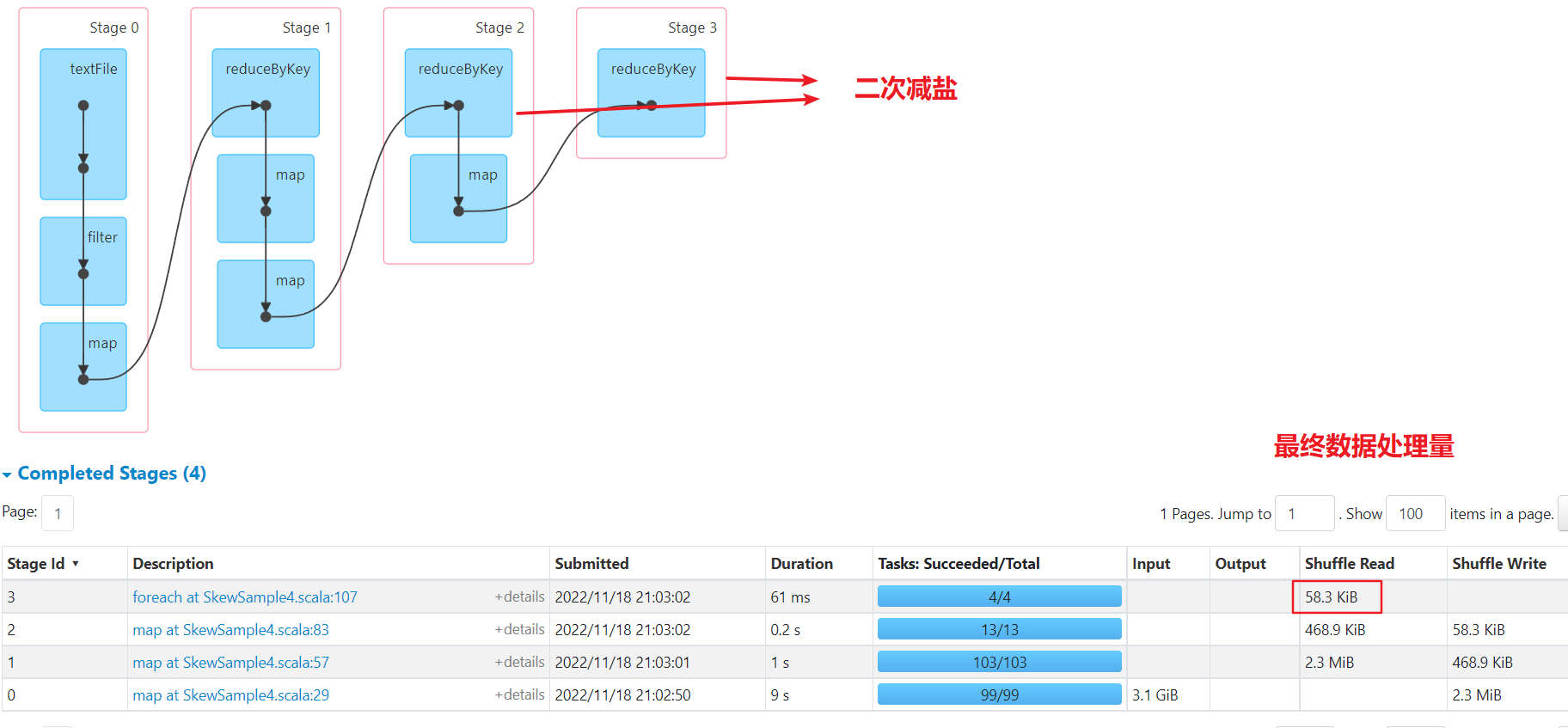


綜合對比
綜合來看,
- 單獨處理:其實原理和加鹽減鹽也差不多,都是將傾斜鍵想辦法分配到多個任務。但是要多一個job,感覺使用的場景會比較少
- 一次減鹽:shuffle次數少,如果彙總計算是簡單計算,最後結果資料量小,則效能較好
- 二次減鹽:shuffle次數多了一次,但是整體每個任務處理的資料量都比較均勻,如果彙總計算生成的結果比較複雜,建議多次減鹽。
分割區問題
可以看到最後的分割區彙總時,4個任務裡有1個任務在空轉,沒有處理資料,這是因為預設shuffle時是按 HashPartitioner來進行分割區,原理是取 key的hashcode然後對分割區數量取模:
key.hashCode % numPartition = 對應的最終分割區

解決思路
-
根據key特性進行分割區:公眾號文章中的方式比較取巧,最終4個key是ip,最後一位數位不同,且最後一位數模4結果都不同,因此可以用這種方式建立自定義分割區器處理
-
提前取出去重後的所有key,做好到分割區的對映,然後將對映傳入到自定義分割區器中使用。優點是可以完全按自己需求來分割區,缺點也是有兩個job
-
利用分散式鎖:利用redis或者zk等元件做一把分散式鎖,鎖的value當做分割區值,並快取已有的key和分割區對映,每個task取分割區時先獲取鎖,然後判斷是否在快取內有對應分割區,有則取出返回,無則將鎖的value作為分割區返回,並將此關係快取,value加1。 優點是效能會比第二種方式好,但是需要引入新的元件,可能會有元件和並行問題。 因為我電腦沒裝redis和zk,直接用mysql的寫鎖作為分散式鎖來實現了

最終程式碼
傾斜鍵單獨處理
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import java.util
import java.util.Map.Entry
import scala.util.Random
object SkewSample3 {
def main(args: Array[String]): Unit = {
skew3()
}
/**
* 傾斜key單獨拿出來跑
*/
def skew3():Unit = {
val conf = new SparkConf().setAppName("DataSkewTest03")
val spark = new SparkContext(conf)
val rawRDD = spark.textFile("/root/data/skewdata.csv")//讀取資料來源
/**篩選滿足需要的資料,已到達資料傾斜的目的*/
val filteredRDD = rawRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185") || target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
filteredRDD.cache()
val normalKeyRDD = filteredRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
val skewKeyRDD = filteredRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185")
})
/**根據目的ip進行彙總,將存取同一個目的ip的所有使用者端ip進行彙總*/
val reducedRDD1 = normalKeyRDD.map(line => {
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index) //為了讓後續聚合後的value資料量儘可能的少,只取ip的前段部分
(target_ip,Array(subClientIP))
}).reduceByKey(_++_,3)//將Array中的元素進行合併,然後將分割區調整為已知的4個
//reducedRDD.foreach(x => println(x._1, x._2.length)) //檢視傾斜key
/**將存取同一個目的ip的使用者端,再次根據使用者端ip進行進一步統計*/
val targetRDD1 = reducedRDD1.map(kv => {
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
/**根據目的ip進行彙總,將存取同一個目的ip的所有使用者端ip進行彙總*/
val reducedRDD2 = skewKeyRDD.map(line => {
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index) //為了讓後續聚合後的value資料量儘可能的少,只取ip的前段部分
(target_ip,Array(subClientIP))
}).reduceByKey(new MySkewPartitioner(100), _++_)// 將資料隨機分配到100個分割區中
//reducedRDD.foreach(x => println(x._1, x._2.length)) //檢視傾斜key
/**將存取同一個目的ip的使用者端,再次根據使用者端ip進行進一步統計*/
val targetRDD2 = reducedRDD2.map(kv => {
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
// 合併結果
val targetRDD3 = targetRDD2.reduceByKey((v1, v2) => {
val newMap = new util.HashMap[String,Int]()
newMap.putAll(v1)
val value: util.Iterator[Entry[String, Int]] = v2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (newMap.containsKey(value1.getKey)) {
val sum = newMap.get(value1.getKey) + value1.getValue
newMap.put(value1.getKey,sum)
} else {
newMap.put(value1.getKey, value1.getValue)
}
}
newMap
}, 1)
targetRDD1.foreach(x => println(x._1, x._2.size()))
targetRDD3.foreach(x => println(x._1, x._2.size()))
// targetRDD1.saveAsTextFile("tmp/DataSkew01") //結果資料儲存目錄
}
class MySkewPartitioner(partitions: Int) extends Partitioner{
override def numPartitions: Int = partitions
override def getPartition(key: Any): Int = {
Random.nextInt(partitions)
}
}
}
二次減鹽
一次減鹽不寫了,去掉第一段減鹽即可
import org.apache.spark.{SparkConf, SparkContext}
import java.util
import java.util.Map.Entry
import scala.util.Random
object SkewSample4 {
def main(args: Array[String]): Unit = {
skew4()
}
/**
* 傾斜key單獨拿出來跑
*/
def skew4():Unit = {
val conf = new SparkConf().setAppName("DataSkewTest04")
val spark = new SparkContext(conf)
val rawRDD = spark.textFile("/root/data/skewdata.csv")//讀取資料來源
// val rawRDD = spark.textFile("D:\\BaiduNetdiskDownload\\尚矽谷\\上網DNS紀錄檔資料\\part-00000-7dc7257d-dd48-4e7f-9865-d7181c3c4c37-c000.csv")//讀取資料來源
/**篩選滿足需要的資料,已到達資料傾斜的目的*/
val filteredRDD = rawRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185") || target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
val reducedRDD_01 = filteredRDD.map(line => {/**解決傾斜第一步:加鹽操作將原本1個分割區的資料擴大到100個分割區*/
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index)//為了讓後續聚合後的value資料量儘可能的少,只取ip的前段部分
if (target_ip.equals("106.38.176.185")){/**針對特定傾斜的key進行加鹽操作*/
val saltNum = 99 //將原來的1個key增加到100個key
val salt = new Random().nextInt(saltNum)
(target_ip + "-" + salt,Array(subClientIP))
}
else (target_ip,Array(subClientIP))
}).reduceByKey(_++_,103)//將Array中的元素進行合併,並確定分割區數量
val targetRDD_01 = reducedRDD_01.map(kv => {/**第二步:將各個分割區中的資料進行初步統計,減少單個分割區中value的大小*/
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {//對clientIP進行統計
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
val reducedRDD_02 = targetRDD_01.map(kv => {/**第3步:對傾斜的資料進行減鹽操作,將分割區數從100減到10*/
val targetIPWithSalt01 = kv._1
val clientIPMap = kv._2
if (targetIPWithSalt01.startsWith("106.38.176.185")){
val targetIP = targetIPWithSalt01.split("-")(0)
val saltNum = 9 //將原來的100個分割區減少到10個分割區
val salt = new Random().nextInt(saltNum)
(targetIP + "-" + salt,clientIPMap)
}
else kv
}).reduceByKey((map1,map2) => { /**合併2個map中的元素,key相同則value值相加*/
//將map1和map2中的結果merge到map3中,相同的key,則value相加
val map3 = new util.HashMap[String,Int](map1)
val value: util.Iterator[Entry[String, Int]] = map2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (map3.containsKey(value1.getKey)) {
val sum = map3.get(value1.getKey) + value1.getValue
map3.put(value1.getKey,sum)
} else {
map3.put(value1.getKey, value1.getValue)
}
}
map3
},13)//調整分割區數量
val finalRDD = reducedRDD_02.map(kv => {/**第4步:繼續減鹽,將原本10個分割區數的資料恢復到1個*/
val targetIPWithSalt01 = kv._1
val clientIPMap = kv._2
if (targetIPWithSalt01.startsWith("106.38.176.185")){
val targetIP = targetIPWithSalt01.split("-")(0)
(targetIP,clientIPMap)//徹底將鹽去掉
}
else kv
}).reduceByKey((map1,map2) => { /**合併2個map中的元素,key相同則value值相加*/
//將map1和map2中的結果merge到map3中,相同的key,則value相加
val map3 = new util.HashMap[String,Int](map1)
val value: util.Iterator[Entry[String, Int]] = map2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (map3.containsKey(value1.getKey)) {
val sum = map3.get(value1.getKey) + value1.getValue
map3.put(value1.getKey,sum)
} else {
map3.put(value1.getKey, value1.getValue)
}
}
map3
},4)//調整分割區數量
finalRDD.foreach(x => println(x._1, x._2.size()))
// targetRDD1.saveAsTextFile("tmp/DataSkew01") //結果資料儲存目錄
}
}
自定義分割區
package skew
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import org.spark_project.jetty.server.Connector
import org.spark_project.jetty.util.component.{Container, LifeCycle}
import java.sql.{Connection, DriverManager, ResultSet, Statement}
import java.util
import java.util.Map.Entry
import scala.util.Random
object SkewSample7 {
def main(args: Array[String]): Unit = {
skew4()
}
/**
* 傾斜key單獨拿出來跑
*/
def skew4():Unit = {
val conf = new SparkConf().setAppName("DataSkewTest01").setMaster("local[4]")
val spark = new SparkContext(conf)
// val rawRDD = spark.textFile("/root/data/skewdata.csv")//讀取資料來源
val rawRDD = spark.textFile("D:\\BaiduNetdiskDownload\\尚矽谷\\上網DNS紀錄檔資料\\part-00000-7dc7257d-dd48-4e7f-9865-d7181c3c4c37-c000.csv")//讀取資料來源
/**篩選滿足需要的資料,已到達資料傾斜的目的*/
val filteredRDD = rawRDD.filter(line => {
val array = line.split(",")
val target_ip = array(3)
target_ip.equals("106.38.176.185") || target_ip.equals("106.38.176.117") || target_ip.equals("106.38.176.118") || target_ip.equals("106.38.176.116")
})
val reducedRDD_01 = filteredRDD.map(line => {/**解決傾斜第一步:加鹽操作將原本1個分割區的資料擴大到100個分割區*/
val array = line.split(",")
val target_ip = array(3)
val client_ip = array(0)
val index = client_ip.lastIndexOf(".")
val subClientIP = client_ip.substring(0, index)//為了讓後續聚合後的value資料量儘可能的少,只取ip的前段部分
if (target_ip.equals("106.38.176.185")){/**針對特定傾斜的key進行加鹽操作*/
val saltNum = 99 //將原來的1個key增加到100個key
val salt = new Random().nextInt(saltNum)
(target_ip + "-" + salt,Array(subClientIP))
}
else (target_ip,Array(subClientIP))
}).reduceByKey(_++_,103)//將Array中的元素進行合併,並確定分割區數量
val targetRDD_01 = reducedRDD_01.map(kv => {/**第二步:將各個分割區中的資料進行初步統計,減少單個分割區中value的大小*/
val map = new util.HashMap[String,Int]()
val target_ip = kv._1
val clientIPArray = kv._2
clientIPArray.foreach(clientIP => {//對clientIP進行統計
if (map.containsKey(clientIP)) {
val sum = map.get(clientIP) + 1
map.put(clientIP,sum)
}
else map.put(clientIP,1)
})
(target_ip,map)
})
val reducedRDD_02 = targetRDD_01.map(kv => {/**第3步:對傾斜的資料進行減鹽操作,將分割區數從100減到10*/
val targetIPWithSalt01 = kv._1
val clientIPMap = kv._2
if (targetIPWithSalt01.startsWith("106.38.176.185")){
val targetIP = targetIPWithSalt01.split("-")(0)
val saltNum = 9 //將原來的100個分割區減少到10個分割區
val salt = new Random().nextInt(saltNum)
(targetIP + "-" + salt,clientIPMap)
}
else kv
}).reduceByKey((map1,map2) => { /**合併2個map中的元素,key相同則value值相加*/
//將map1和map2中的結果merge到map3中,相同的key,則value相加
val map3 = new util.HashMap[String,Int](map1)
val value: util.Iterator[Entry[String, Int]] = map2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (map3.containsKey(value1.getKey)) {
val sum = map3.get(value1.getKey) + value1.getValue
map3.put(value1.getKey,sum)
} else {
map3.put(value1.getKey, value1.getValue)
}
}
map3
},13)//調整分割區數量
val reducedRDD_03 = reducedRDD_02.map(kv => {/**第4步:繼續減鹽,將原本10個分割區數的資料恢復到1個*/
val targetIPWithSalt01 = kv._1
val clientIPMap = kv._2
if (targetIPWithSalt01.startsWith("106.38.176.185")){
val targetIP = targetIPWithSalt01.split("-")(0)
(targetIP,clientIPMap)//徹底將鹽去掉
}
else kv
})
val finalRDD = reducedRDD_03.reduceByKey(new MyMapPartitioner(4), (map1,map2) => { /**合併2個map中的元素,key相同則value值相加*/
//將map1和map2中的結果merge到map3中,相同的key,則value相加
val map3 = new util.HashMap[String,Int](map1)
val value: util.Iterator[Entry[String, Int]] = map2.entrySet().iterator()
while(value.hasNext){
val value1: Entry[String, Int] = value.next()
if (map3.containsKey(value1.getKey)) {
val sum = map3.get(value1.getKey) + value1.getValue
map3.put(value1.getKey,sum)
} else {
map3.put(value1.getKey, value1.getValue)
}
}
map3
})//調整分割區數量
println("asdfsd")
finalRDD.foreach(x => println(x._1, x._2.size()))
// targetRDD1.saveAsTextFile("tmp/DataSkew01") //結果資料儲存目錄
Thread.sleep(600000)
}
/**
* ip分割區器
* @param keys
*/
class MyIpPartitioner(partitionNum: Int) extends Partitioner{
override def numPartitions: Int = partitionNum //確定總分割區數量
override def getPartition(key: Any): Int = {//確定資料進入分割區的具體策略
val keyStr = key.toString
val keyTag = keyStr.substring(keyStr.length - 1, keyStr.length)
keyTag.toInt % partitionNum
}
}
/**
* keys分割區器
* @param keys
*/
class MyMapPartitioner(keys:Array[String]) extends Partitioner{
override def numPartitions: Int = keys.length
val partitionMap = new util.HashMap[String, Int]()
var pointer = 0
keys.foreach(k =>{
partitionMap.put(k, pointer)
pointer += 1
if(pointer == keys.length){
pointer = 0
}
})
println(partitionMap)
override def getPartition(key: Any): Int = {
println(key, "-", partitionMap.get(key))
partitionMap.get(key)
}
}
/**
* mysql分割區器
* @param partitions
*/
class MyMapPartitioner(partitions:Int) extends Partitioner{
val jdbcURL = "jdbc:mysql://xxx.xxx.xxx.xxx:3306?zyk&useSSL=false"
val username = "test"
val password = "123456"
override def numPartitions: Int = partitions
override def getPartition(key: Any): Int = {
getPartitionByMysql(key)
}
/** ddl
CREATE TABLE `pointer` (
`pointer` int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO pointer VALUES (0);
CREATE TABLE `key_partition_map` (
`key_string` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`partition_index` tinyint DEFAULT NULL,
PRIMARY KEY (`key_string`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
*/
def getPartitionByMysql(key:Any):Int = {
var partition = 0
Class.forName("com.mysql.jdbc.Driver")
val conn: Connection = DriverManager.getConnection(jdbcURL, username, password)
// 開啟事務
conn.setAutoCommit(false)
val statement: Statement = conn.createStatement()
// 用mysql的寫鎖作為分散式鎖, pointer表用於當成鎖,和遞增的指標, key_partition_map表儲存 key和分割區的對映
val lock: ResultSet = statement.executeQuery("select pointer from zyk.pointer for update;")
lock.next()
partition = lock.getInt(1)
val map: ResultSet = statement.executeQuery("select partition_index from zyk.key_partition_map where key_string = '" + key + "';")
// 如果有結果則取對應對映,如果沒有結果,則插入新增對映,並將指標加1
if(map.next()){
partition = map.getInt(1)
} else {
statement.execute("insert into zyk.key_partition_map values ('" + key + "', " + partition + ");")
partition += 1
if(partition == numPartitions) partition = 0
statement.executeUpdate("update zyk.pointer set pointer = " + partition + ";")
conn.commit()
}
conn.close()
println(key, "-", partition)
// 返回最終分割區
partition
}
}
}