同事吐槽我的介面效能差,原理它是真凶!
前言
最近我在公司優化過幾個慢查詢介面的效能,總結了一些心得體會拿出來跟大家一起分享一下,希望對你會有所幫助。
我們使用的資料庫是Mysql8,使用的儲存引擎是Innodb。這次優化除了優化索引之外,更多的是在優化count(*)。
通常情況下,分頁介面一般會查詢兩次資料庫,第一次是獲取具體資料,第二次是獲取總的記錄行數,然後把結果整合之後,再返回。
查詢具體資料的sql,比如是這樣的:`
select id,name from user limit 20;
它沒有效能問題。
但另外一條使用count(*)查詢總記錄行數的sql,例如:
select count(*) from user;
卻存在效能差的問題。
為什麼會出現這種情況呢?
1 count(*)為什麼效能差?
在Mysql中,count(*)的作用是統計表中記錄的總行數。
而count(*)的效能跟儲存引擎有直接關係,並非所有的儲存引擎,count(*)的效能都很差。
在Mysql中使用最多的儲存引擎是:innodb和myisam。
在myisam中會把總行數儲存到磁碟上,使用count(*)時,只需要返回那個資料即可,無需額外的計算,所以執行效率很高。
而innodb則不同,由於它支援事務,有MVCC(即多版本並行控制)的存在,在同一個時間點的不同事務中,同一條查詢sql,返回的記錄行數可能是不確定的。
在innodb使用count(*)時,需要從儲存引擎中一行行的讀出資料,然後累加起來,所以執行效率很低。
如果表中資料量小還好,一旦表中資料量很大,innodb儲存引擎使用count(*)統計資料時,效能就會很差。
2 如何優化count(*)效能?
從上面得知,既然count(*)存在效能問題,那麼我們該如何優化呢?
我們可以從以下幾個方面著手。
2.1 增加redis快取
對於簡單的count(*),比如:統計瀏覽總次數或者瀏覽總人數,我們可以直接將介面使用redis快取起來,沒必要實時統計。
當用戶開啟指定頁面時,在快取中每次都設定成count = count+1即可。
使用者第一次存取頁面時,redis中的count值設定成1。使用者以後每存取一次頁面,都讓count加1,最後重新設定到redis中。
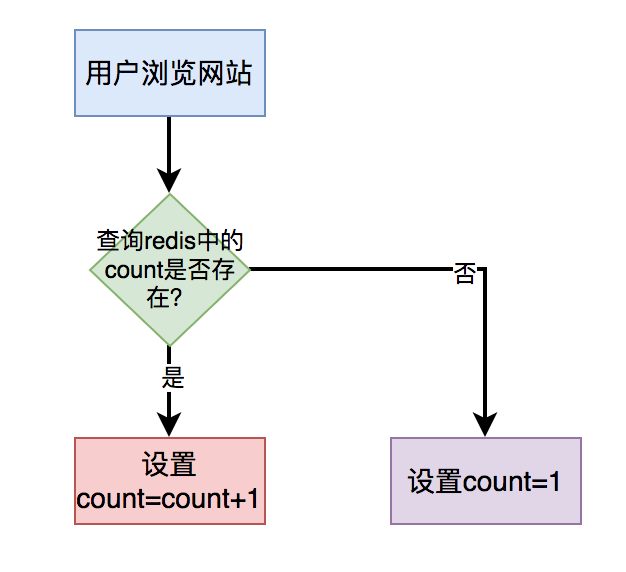
這樣在需要展示數量的地方,從redis中查出count值返回即可。
該場景無需從資料埋點表中使用count(*)實時統計資料,效能將會得到極大的提升。
不過在高並行的情況下,可能會存在快取和資料庫的資料不一致的問題。
但對於統計瀏覽總次數或者瀏覽總人數這種業務場景,對資料的準確性要求並不高,容忍資料不一致的情況存在。
2.2 加二級快取
對於有些業務場景,新增資料很少,大部分是統計數量操作,而且查詢條件很多。這時候使用傳統的count(*)實時統計資料,效能肯定不會好。
假如在頁面中可以通過id、name、狀態、時間、來源等,一個或多個條件,統計品牌數量。
這種情況下使用者的組合條件比較多,增加聯合索引也沒用,使用者可以選擇其中一個或者多個查詢條件,有時候聯合索引也會失效,只能儘量滿足使用者使用頻率最高的條件增加索引。
也就是有些組合條件可以走索引,有些組合條件沒法走索引,這些沒法走索引的場景,該如何優化呢?
答:使用二級快取。
二級快取其實就是記憶體快取。
我們可以使用caffine或者guava實現二級快取的功能。
目前SpringBoot已經整合了caffine,使用起來非常方便。
只需在需要增加二級快取的查詢方法中,使用@Cacheable註解即可。
@Cacheable(value = "brand", , keyGenerator = "cacheKeyGenerator")
public BrandModel getBrand(Condition condition) {
return getBrandByCondition(condition);
}
然後自定義cacheKeyGenerator,用於指定快取的key。
public class CacheKeyGenerator implements KeyGenerator {
@Override
public Object generate(Object target, Method method, Object... params) {
return target.getClass().getSimpleName() + UNDERLINE
+ method.getName() + ","
+ StringUtils.arrayToDelimitedString(params, ",");
}
}
這個key是由各個條件組合而成。
這樣通過某個條件組合查詢出品牌的資料之後,會把結果快取到記憶體中,設定過期時間為5分鐘。
後面使用者在5分鐘內,使用相同的條件,重新查詢資料時,可以直接從二級快取中查出資料,直接返回了。
這樣能夠極大的提示count(*)的查詢效率。
但是如果使用二級快取,可能存在不同的伺服器上,資料不一樣的情況。我們需要根據實際業務場景來選擇,沒法適用於所有業務場景。
2.3 多執行緒執行
不知道你有沒有做過這樣的需求:統計有效訂單有多少,無效訂單有多少。
這種情況一般需要寫兩條sql,統計有效訂單的sql如下:
select count(*) from order where status=1;
統計無效訂單的sql如下:
select count(*) from order where status=0;
但如果在一個介面中,同步執行這兩條sql效率會非常低。
這時候,可以改成成一條sql:
select count(*),status from order
group by status;
使用group by關鍵字分組統計相同status的數量,只會產生兩條記錄,一條記錄是有效訂單數量,另外一條記錄是無效訂單數量。
但有個問題:status欄位只有1和0兩個值,重複度很高,區分度非常低,不能走索引,會全表掃描,效率也不高。
還有其他的解決方案不?
答:使用多執行緒處理。
我們可以使用CompleteFuture使用兩個執行緒非同步呼叫統計有效訂單的sql和統計無效訂單的sql,最後彙總資料,這樣能夠提升查詢介面的效能。
2.4 減少join的表
大部分的情況下,使用count(*)是為了實時統計總數量的。
但如果表本身的資料量不多,但join的表太多,也可能會影響count(*)的效率。
比如在查詢商品資訊時,需要根據商品名稱、單位、品牌、分類等資訊查詢資料。
這時候寫一條sql可以查出想要的資料,比如下面這樣的:
select count(*)
from product p
inner join unit u on p.unit_id = u.id
inner join brand b on p.brand_id = b.id
inner join category c on p.category_id = c.id
where p.name='測試商品' and u.id=123 and b.id=124 and c.id=125;
使用product表去join了unit、brand和category這三張表。
其實這些查詢條件,在product表中都能查詢出資料,沒必要join額外的表。
我們可以把sql改成這樣:
select count(*)
from product
where name='測試商品' and unit_id=123 and brand_id=124 and category_id=125;
在count(*)時只查product單表即可,去掉多餘的表join,讓查詢效率可以提升不少。
2.5 改成ClickHouse
有些時候,join的表實在太多,沒法去掉多餘的join,該怎麼辦呢?
比如上面的例子中,查詢商品資訊時,需要根據商品名稱、單位名稱、品牌名稱、分類名稱等資訊查詢資料。
這時候根據product單表是沒法查詢出資料的,必須要去join:unit、brand和category這三張表,這時候該如何優化呢?
答:可以將資料儲存到ClickHouse。
ClickHouse是基於列儲存的資料庫,不支援事務,查詢效能非常高,號稱查詢十幾億的資料,能夠秒級返回。
為了避免對業務程式碼的嵌入性,可以使用Canal監聽Mysql的binlog紀錄檔。當product表有資料新增時,需要同時查詢出單位、品牌和分類的資料,生成一個新的結果集,儲存到ClickHouse當中。
查詢資料時,從ClickHouse當中查詢,這樣使用count(*)的查詢效率能夠提升N倍。
需要特別提醒一下:使用ClickHouse時,新增資料不要太頻繁,儘量批次插入資料。
其實如果查詢條件非常多,使用ClickHouse也不是特別合適,這時候可以改成ElasticSearch,不過它跟Mysql一樣,存在深分頁問題。
3 count的各種用法效能對比
既然說到count(*),就不能不說一下count家族的其他成員,比如:count(1)、count(id)、count(普通索引列)、count(未加索引列)。
那麼它們有什麼區別呢?
- count(*) :它會獲取所有行的資料,不做任何處理,行數加1。
- count(1):它會獲取所有行的資料,每行固定值1,也是行數加1。
- count(id):id代表主鍵,它需要從所有行的資料中解析出id欄位,其中id肯定都不為NULL,行數加1。
- count(普通索引列):它需要從所有行的資料中解析出普通索引列,然後判斷是否為NULL,如果不是NULL,則行數+1。
- count(未加索引列):它會全表掃描獲取所有資料,解析中未加索引列,然後判斷是否為NULL,如果不是NULL,則行數+1。
由此,最後count的效能從高到低是:
count(*) ≈ count(1) > count(id) > count(普通索引列) > count(未加索引列)
所以,其實count(*)是最快的。
意不意外,驚不驚喜?
千萬別跟select * 搞混了。
最後說一句(求關注,別白嫖我)
如果這篇文章對您有所幫助,或者有所啟發的話,幫忙掃描下發二維條碼關注一下,您的支援是我堅持寫作最大的動力。
求一鍵三連:點贊、轉發、在看。
關注公眾號:【蘇三說技術】,在公眾號中回覆:面試、程式碼神器、開發手冊、時間管理有超讚的粉絲福利,另外回覆:加群,可以跟很多BAT大廠的前輩交流和學習。