MySql常用查詢優化策略詳解

程式設計師必備介面測試偵錯工具:
推薦學習:
在程式上線執行一段時間後,一旦資料量上去了,或多或少會感覺到系統出現延遲、卡頓等現象,出現這種問題,就需要程式設計師或架構師進行系統調優工作了,其中,大量的實踐經驗表明,調優的手段儘管有很多,但涉及到SQL調優的內容仍然是非常重要的一環,本文將結合範例,總結一些工作中可能涉及到的SQL優化策略;
查詢優化
可以說,對於大多數系統來說,讀多寫少一定是常態,這就表示涉及到查詢的SQL是非常高頻的操作;
前置準備,給一張測試表新增10萬條資料
使用下面的儲存過程給單表造一批資料,將表換成自己的就好了
create procedure addMyData()
begin
declare num int;
set num =1;
while num <= 100000 do
insert into XXX_table values(
replace(uuid(),'-',''),concat('測試',num),concat('cs',num),'123456'
);
set num =num +1;
end while;
end ;登入後複製然後呼叫該儲存過程
call addMyData();
登入後複製本篇準備了3張表,分別為學生(student)表,班級(class)表,賬戶(account)表,各自有50萬,1萬和10萬條資料用於測試;
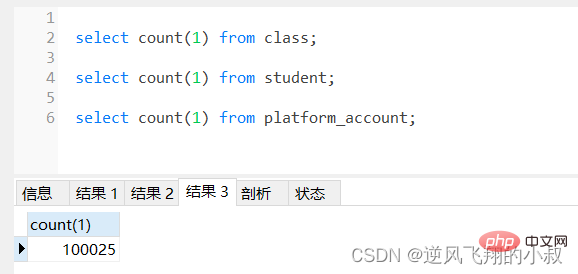
1、分頁查詢優化
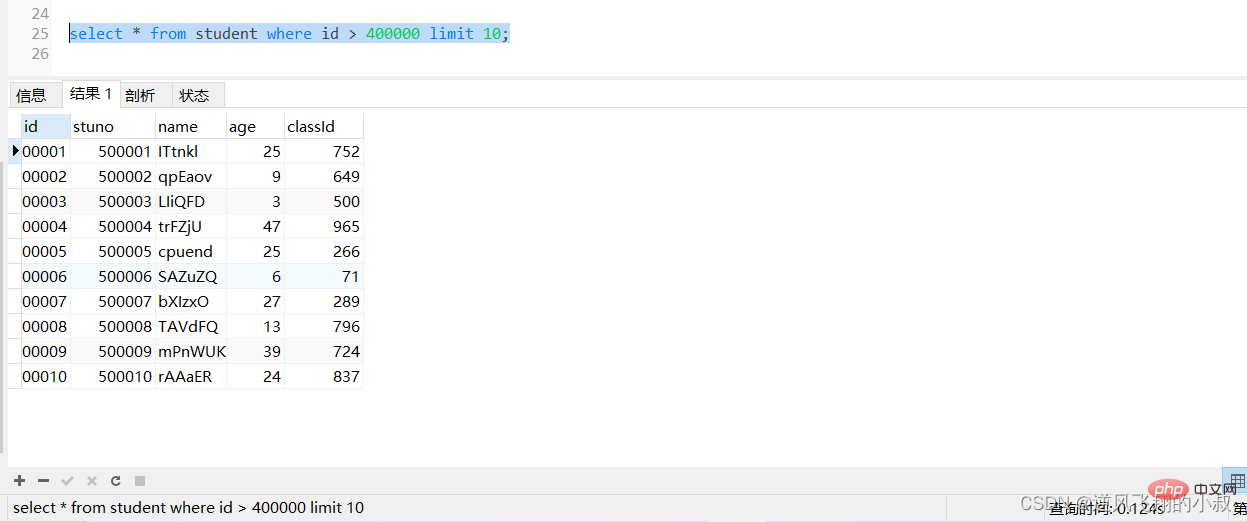
分頁查詢是開發中經常會遇到的,有一種情況是,當分頁的數量非常大的時候,查詢的時候往往非常耗時,比如查詢student表,使用下面的sql查詢,耗時達到0.2秒;
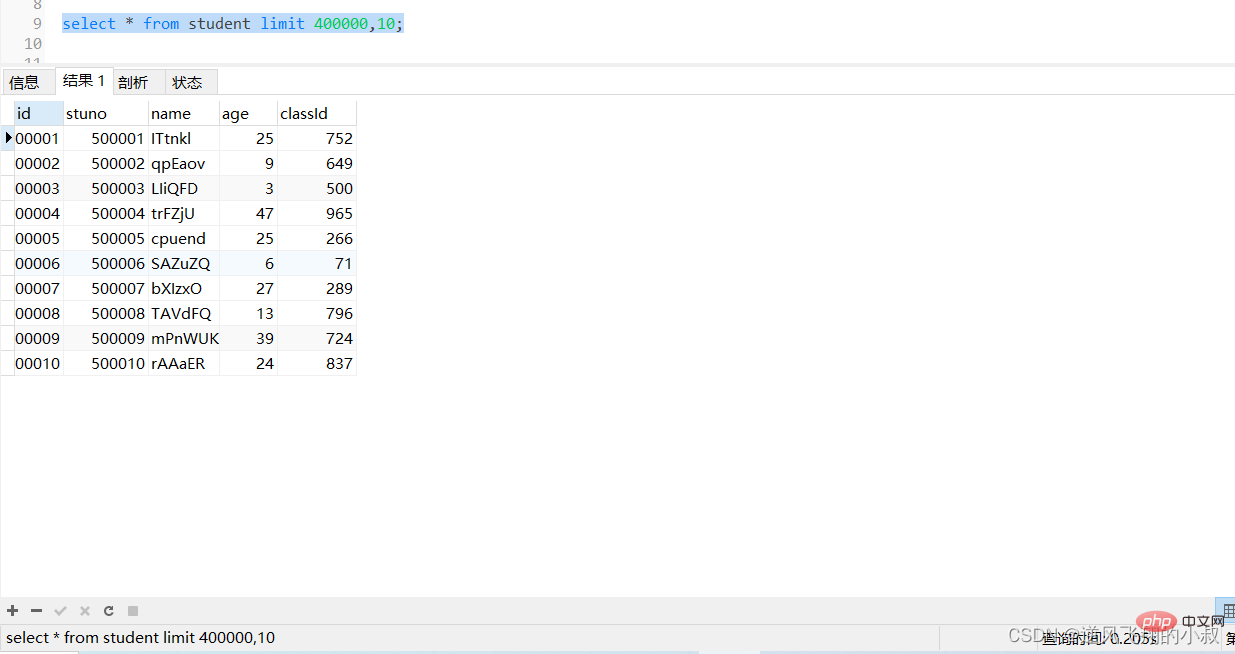
實踐經驗告訴我們,越往後,分頁查詢效率越低,這就是分頁查詢的問題所在, 因為,當在進行分頁查詢時,如果執行 limit 400000,10 ,此時需要 MySQL 排序前4000 10 記 錄,僅僅返回400000 - 4 00010 的記錄,其他記錄丟棄,查詢排序的代價非常大
優化思路:
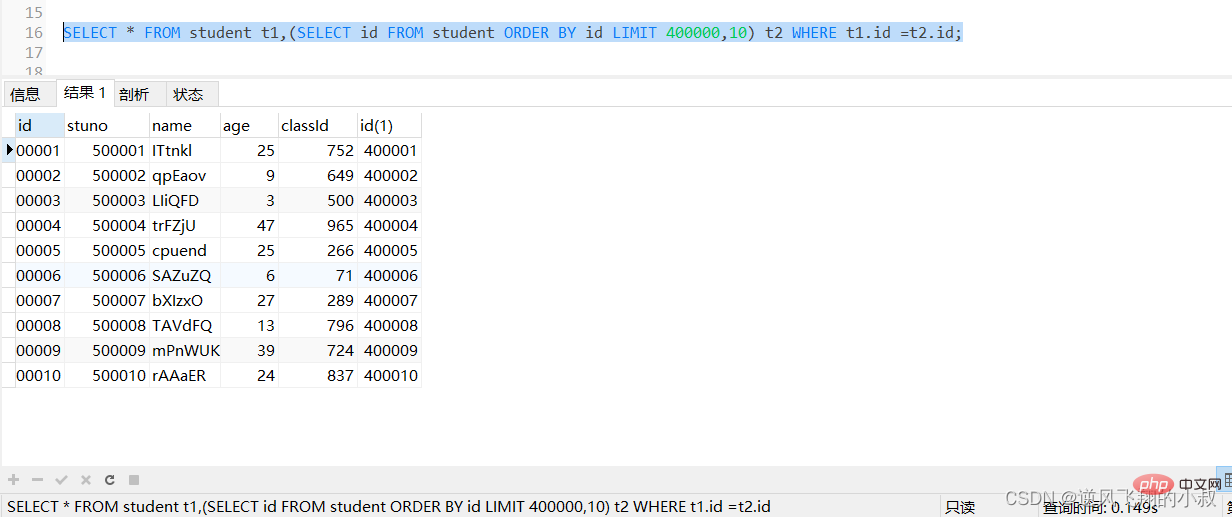
一般分頁查詢時,通過建立 覆蓋索引 能夠比較好地提高效能,可以通過覆蓋索引加子查詢形式進行優化;
SELECT * FROM student t1,(SELECT id FROM student ORDER BY id LIMIT 400000,10) t2 WHERE t1.id =t2.id;
執行上面的sql,可以看到響應時間有一定的提升;
2)對於主鍵自增的表,可以把Limit 查詢轉換成某個位置的查詢
select * from student where id > 400000 limit 10;
執行上面的sql,可以看到響應時間有一定的提升;
2、關聯查詢優化
在實際的業務開發過程中,關聯查詢可以說隨處可見,關聯查詢的優化核心思路是,最好為關聯查詢的欄位新增索引,這是關鍵,具體到不同的場景,還需要具體分析,這個跟mysql的引擎在執行優化策略的方案選擇時有一定關係;
2.1 左連線或右連線
下面是一個使用left join 的查詢,可以預想到這條sql查詢的結果集非常大
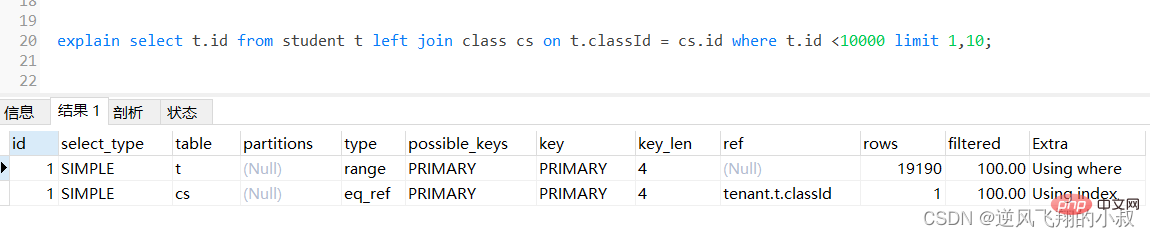
select t.* from student t left join class cs on t.classId = cs.id;
登入後複製為了檢查下sql的執行效率,使用explain做一下分析,可以看到,第一張表即left join左邊的表student走了全表掃描,而class表走了主鍵索引,儘管結果集較大,還是走了索引;

針對這種場景的查詢,思路如下:
- 讓查詢的欄位儘量包含在主鍵索引或者覆蓋索引中;
- 查詢的時候儘量使用分頁查詢;
關於左連線(右連線)的explain結果補充說明
- 左連線左邊的表一般為驅動表,右邊的表為被驅動表;
- 儘可能讓資料集小的表作為驅動表,減少mysql內部迴圈的次數;
- 兩表關聯時,explain結果展示中,第一欄一般為驅動表;
2.2 關聯查詢關聯的欄位建立索引
看下面的這條sql,其關聯欄位非表的主鍵,而是普通的欄位;
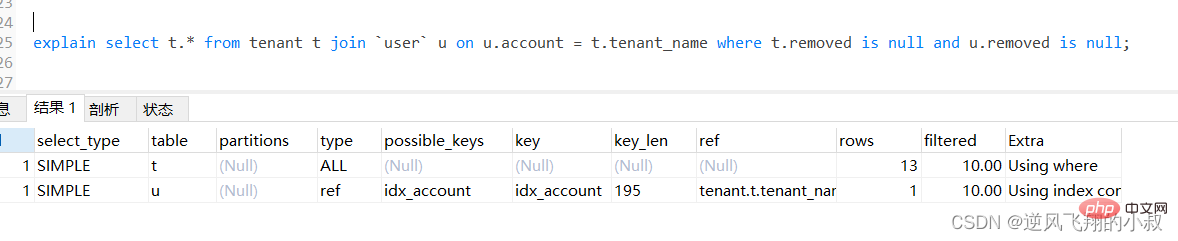
explain select u.* from tenant t left join `user` u on u.account = t.tenant_name where t.removed is null and u.removed is null;
登入後複製
通過explain分析可以發現,左邊的表走了全表掃描,可以考慮給左邊的表的tenant_name和user表的account 各自建立索引;
create index idx_name on tenant(tenant_name);
create index idx_account on `user`(account);
再次使用explain分析結果如下

可以看到第二行type變為ref,rows的數量優化比較明顯。這是由左連線特性決定的,LEFT JOIN條件用於確定如何從右表搜尋行,左邊一定都有,所以右邊是我們的關鍵點,一定需要建立索引 。
2.3 內連線關聯的欄位建立索引
我們知道,左連線和右連線查詢的資料分別是完全包含左表資料,完全包含右表資料,而內連線(inner join 或join) 則是取交集(共有的部分),在這種情況下,驅動表的選擇是由mysql優化器自動選擇的;
在上面的基礎上,首先移除兩張表的索引
ALTER TABLE `user` DROP INDEX idx_account;
ALTER TABLE `tenant` DROP INDEX idx_name;
使用explain語句進行分析

然後給user表的account欄位新增索引,再次執行explain我們發現,user表竟然被當作是被驅動表了;
此時,如果我們給tenant表的tenant_name加索引,並移除user表的account索引,得出的結果竟然都沒有走索引,再次說明,使用內連線的情況下,查詢優化器將會根據自己的判斷進行選擇;

3、子查詢優化
子查詢在日常編寫業務的SQL時也是使用非常頻繁的做法,不是說子查詢不能用,而是當資料量超出一定的範圍之後,子查詢的效能下降是很明顯的,關於這一點,本人在日常工作中深有體會;
比如下面這條sql,由於student表資料量較大,執行起來耗時非常長,可以看到耗費了將近3秒;
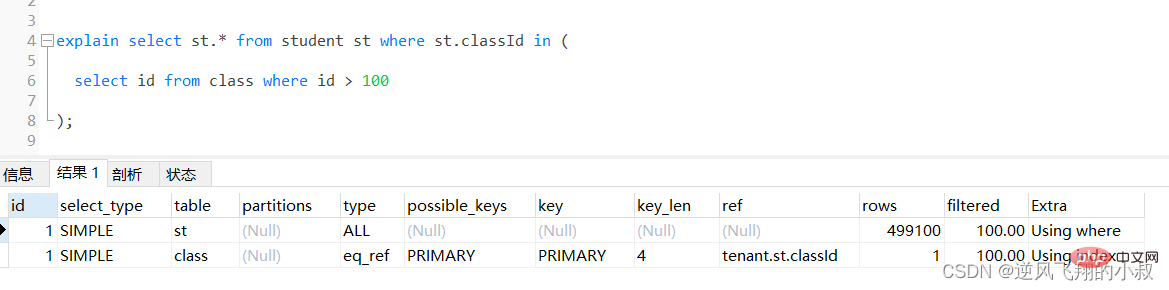
select st.* from student st where st.classId in (
select id from class where id > 100
);
登入後複製
通過執行explain進行分析得知,內層查詢 id > 100的子查詢儘管用上了主鍵索引,但是由於結果集太大,帶入到外層查詢,即作為in的條件時,查詢優化器還是走了全表掃描;
針對上面的情況,可以考慮下面的優化方式
select st.id from student st join class cl on st.classId = cl.id where cl.id > 100;
子查詢效能低效的原因
- 子查詢時,MySQL需要為內層查詢語句的查詢結果建立一個臨時表 ,然後外層查詢語句從臨時表中查詢記錄,查詢完畢後,再復原這些臨時表 。這樣會消耗過多的CPU和IO資源,產生大量的慢查詢;
- 子查詢結果集儲存的臨時表,不論是記憶體臨時表還是磁碟臨時表都不能走索引 ,所以查詢效能會受到一定的影響;
- 對於返回結果集比較大的子查詢,其對查詢效能的影響也就越大;
使用mysql查詢時,可以使用連線(JOIN)查詢來替代子查詢。連線查詢不需要建立臨時表 ,其速度比子查詢要快 ,如果查詢中使用索引的話,效能就會更好,儘量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代;
一個真實的案例
在下面的這段sql中,優化前使用的是子查詢,在一次生產問題的效能分析中,發現某個tenant_id下的資料達到了35萬多,這樣直接導致某個列表頁面的介面查詢耗時達到了5秒左右;
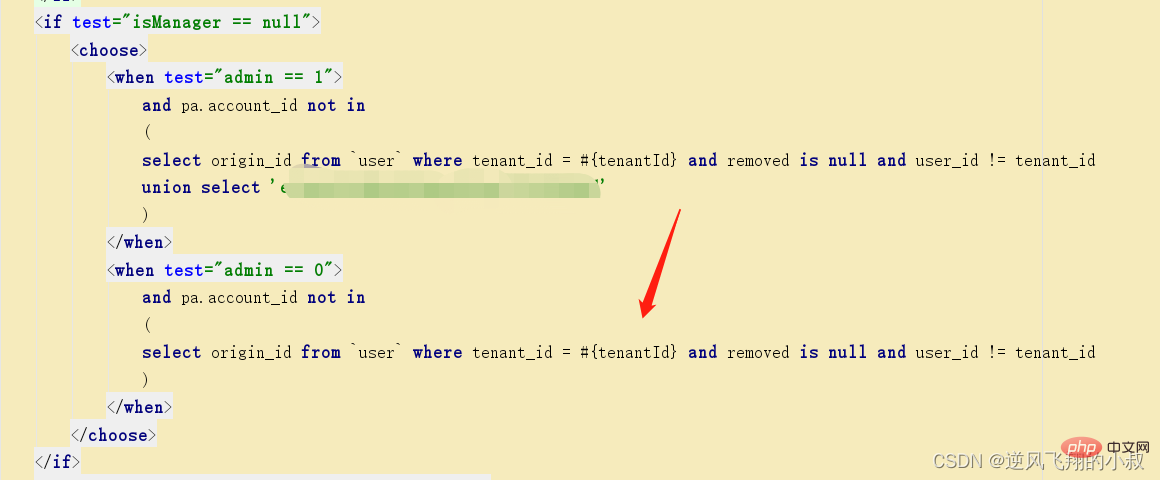
找到了問題的根源後,嘗試使用上面的優化思路進行解決即可,優化後的sql大概如下,
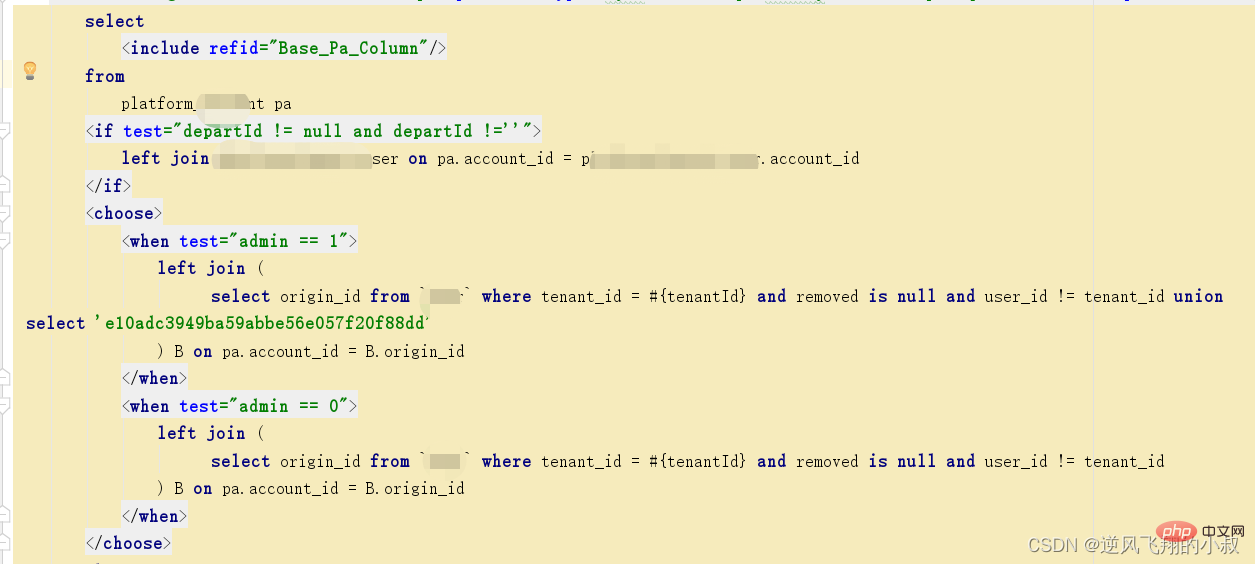
4、排序(order by)優化
在mysql,排序主要有兩種方式
- Using filesort : 通過表索引或全表掃描,讀取滿足條件的資料行,然後在排序緩衝區sort
buffer中完成排序操作,所有不是通過索引直接返回排序結果的排序都叫 FileSort 排序; - Using index : 通過有序的索引順序掃描直接返回有序資料,這種情況即為 using index,不需要額外排序,操作效率高;
對於以上兩種排序方式,Using index的效能高,而Using filesort的效能低,我們在優化排序操作時,儘量要優化為 Using index
4.1 使用age欄位進行排序
由於age欄位未加索引,查詢結果按照age排序的時候發現使用了filesort,排序效能較低;

給age欄位新增索引,再次使用order by時就走了索引;

4.2 使用多欄位進行排序
通常在實際業務中,參與排序的欄位往往不只一個,這時候,就可以對參與排序的多個欄位建立聯合索引;
如下根據stuno和age排序

給stuno和age新增聯合索引
create index idx_stuno_age on `student`(stuno,age);
再次分析時結果如下,此時排序走了索引

關於多欄位排序時的注意事項
1)排序時,需要滿足最左字首法則,否則也會出現 filesort;
在上面我們建立的聯合索引順序是stuno和age,即stuno在前面,而age在後,如果查詢的時候調換排序順序會怎樣呢?通過分析結果發現,走了filesort;

2)排序時,排序的型別保持一致
在保持欄位排序順序不變時,預設情況下,如果都按照升序或者降序時,order by可以使用index,如果一個是升序,另一個是降序會如何呢?分析發現,這種情況下也會走filesort;

5、分組(group by)優化
group by 的優化策略和order by 的優化策略非常像,主要列舉如下幾個要點:
- group by 即使沒有過濾條件用到索引,也可以直接使用索引;
- group by 先排序再分組,遵照索引建的最佳左字首法則;
- 當無法使用索引列時,增大 max_length_for_sort_data 和 sort_buffer_size 引數的設定;
- where效率高於having,能寫在where限定的條件就不要寫在having中了;
- 減少使用order by,能不排序就不排序,或將排序放到程式去做。Order by、groupby、distinct這些語句較為耗費CPU,資料庫的CPU資源是極其寶貴的;
- 如果sql包含了order by、group by、distinct這些查詢的語句,where條件過濾出來的結果集請保持在1000行以內,否則SQL會很慢;
5.1 給group by的欄位新增索引
如果欄位未加索引,分析結果如下,這種結果效能顯然很低效

給stuno新增索引之後

給stuno和age新增聯合索引

如果不遵循最佳左字首,group by 效能將會比較低效

遵循最佳左字首的情況如下

6、count 優化
count() 是一個聚合函數,對於返回的結果集,一行行判斷,如果 count 函數的引數不是NULL,累計值就加 1,否則不加,最後返回累計值;
用法:count(*)、count(主鍵)、count(欄位)、count(數位)
如下列舉了count的幾種寫法的詳細說明
| 用法 | 說明 |
| count(主鍵) | InnoDB 會遍歷整張表,把每一行的主鍵id值都取出來,返回給服務層,服務層拿到主鍵後,直接按行進行累加(主鍵不可能為null); |
| count(*) | InnoDB不會把全部欄位取出來,而是專門做了優化,不取值,服務層直接按行進行累加; |
| count(欄位) | 沒有not null 約束 : InnoDB 引擎會遍歷整張表把每一行的欄位值都取出來,返回給服務層,服務層判斷是否為null,不為null,計數累加,有not null 約束:InnoDB 引擎會遍歷整張表把每一行的欄位值都取出來,返回給服務層,直接按行進行累加; |
| count(數位) | InnoDB 引擎遍歷整張表,但不取值。服務層對於返回的每一行,放一個數位「1」進去,直接按行進行累加; |
經驗值總結
按照效率排序來看,count(欄位) < count(主鍵 id) < count(1) ≈ count(*),所以儘量使用 count(*)
推薦學習:
以上就是MySql常用查詢優化策略詳解的詳細內容,更多請關注TW511.COM其它相關文章!
