12 張圖看懂 CPU 快取一致性與 MESI 協定,真的一致嗎?
本文已收錄到 GitHub · AndroidFamily,有 Android 進階知識體系,歡迎 Star。技術和職場問題,請關注公眾號 [彭旭銳] 進 Android 面試交流群。
前言
大家好,我是小彭。
在上一篇文章裡,我們聊到了 CPU 的三級快取結構,提到 CPU 快取就一定會聊到 CPU 的快取一致性問題。那麼,什麼是快取一致性問題,CPU Cache 的讀取和寫入過程是如何執行的,MESI 快取一致性協定又是什麼?今天我們將圍繞這些問題展開。
學習路線圖:
1. 回顧 CPU 三級快取結構
由於 CPU 和記憶體的速度差距太大,為了拉平兩者的速度差,現代計算機會在兩者之間插入一塊速度比記憶體更快的快取記憶體,CPU 快取是分級的,有 L1 / L2 / L3 三級快取。
由於單核 CPU 的效能遇到瓶頸(主頻與功耗的矛盾),晶片廠商開始在 CPU 晶片裡整合多個 CPU 核心,每個核心有各自的 L1 / L2 快取。 其中 L1 / L2 快取是核心獨佔的,而 L3 快取是多核心共用的。
基於區域性性原理的應用,CPU Cache 在讀取記憶體資料時,每次不會唯讀一個字或一個位元組,而是一塊塊地讀取,每一小塊資料也叫 CPU 快取行(CPU Cache Line)。 為了標識 Cache 塊中的資料是否已經從記憶體中讀取,需要在 Cache 塊上增加一個 有效位(Valid bit)。
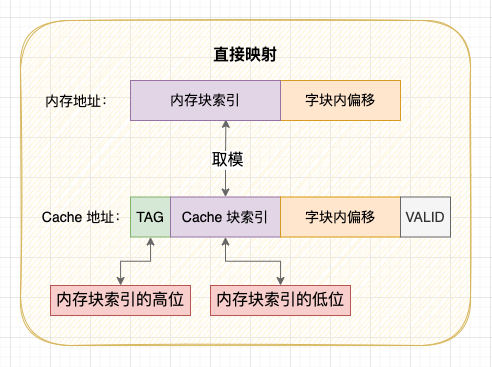
無論對 Cache 資料檢查、讀取還是寫入,CPU 都需要知道存取的記憶體資料對映在 Cache 上的哪個位置,這就是 Cache - 記憶體地址對映問題,對映方案有直接對映、全相聯對映和組相聯對映 3 種方案。當快取塊滿或者記憶體塊對映的快取塊位置被佔用時,就需要使用 替換策略 將舊的 Cache 塊換出騰出空閒位置。
Cache - 記憶體的直接對映方案
基於以上結構,就會存在快取一致性問題。
2. 什麼是 CPU 快取一致性問題?
CPU 快取一致性(Cache Coherence)問題指 CPU Cache 與記憶體的不一致性問題。事實上, 在分析快取一致性問題時,考慮 L1 / L2 / L3 的多級快取沒有意義, 所以我們提出快取一致性抽象模型,只考慮核心獨佔的快取。
CPU 三級快取與抽象模型
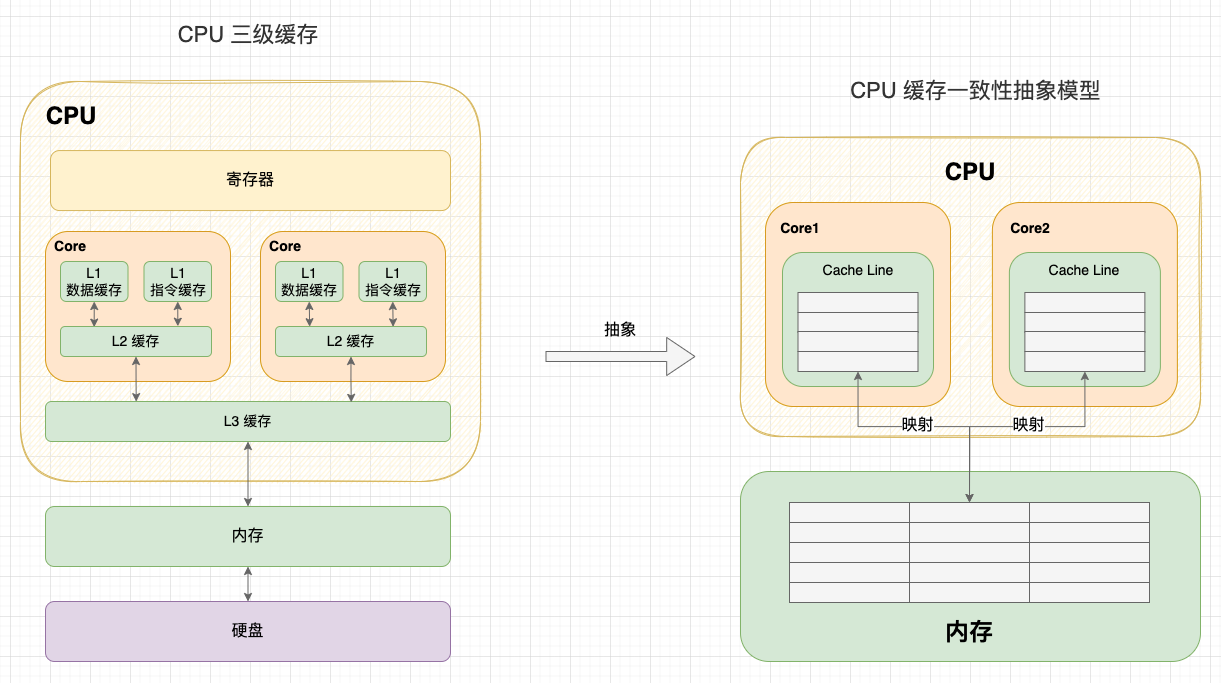
在單核 CPU 中,只需要考慮 Cache 與記憶體的一致性。但是在多核 CPU 中,由於每個核心都有一份獨佔的 Cache,就會存在一個核心修改資料後,兩個核心 Cache 資料不一致的問題。因此,我認為 CPU 的快取一致性問題應該從 2 個維度理解:
- 縱向:Cache 與記憶體的一致性問題: 在修改 Cache 資料後,如何同步回記憶體?
- 橫向:多核心 Cache 的一致性問題: 在一個核心修改 Cache 資料後,如何同步給其他核心 Cache?
接下來,我們將圍繞這兩個問題展開。
3. 縱向:Cache 與記憶體的一致性問題
3.1 CPU Cache 的讀取過程
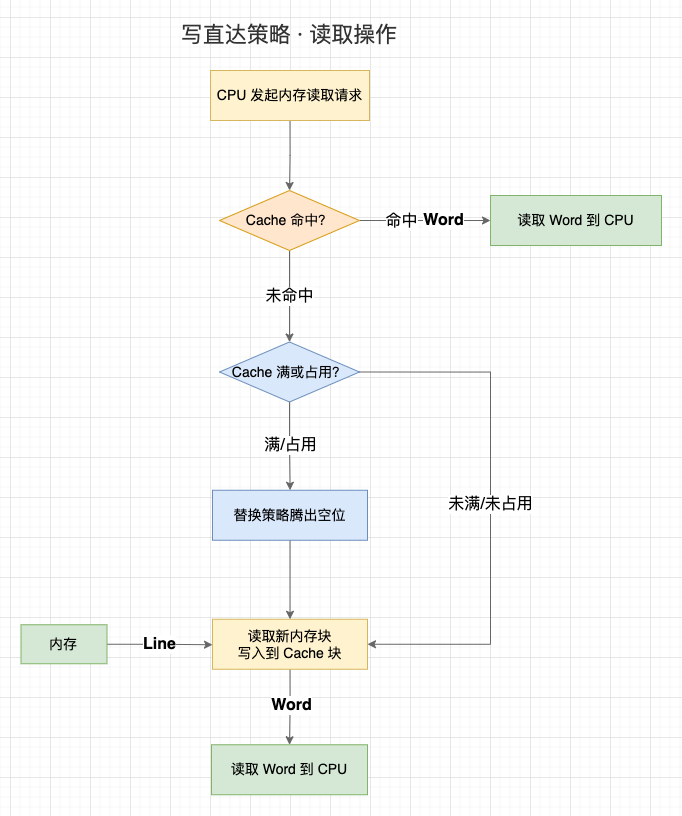
這一節,我們先來討論 Cache 的讀取過程。事實上,Cache 的讀取過程會受到 Cache 的寫入策略影響,我們暫且用相對簡單的 「寫直達策略」 的讀取過程:
-
1、CPU 在存取記憶體地址時,會先檢查該地址的資料是否已經載入到 Cache 中(Valid bit 是否為 1);
-
2、如果資料在 Cache 中,則直接讀取 Cache 塊上的字到 CPU 中;
-
3、如果資料不在 Cache 中:
- 3.1 如果 Cache 已裝滿或者 Cache 塊被佔用,先執行替換策略,騰出空閒位置;
- 3.2 存取記憶體地址,並將記憶體地址所處的整個記憶體塊寫入到對映的 Cache 塊中;
- 3.3 讀取 Cache 塊上的字到 CPU 中。
讀取過程(以寫直達策略)
但是,CPU 不僅會讀取 Cache 資料,還會修改 Cache 資料,這就是第 1 個一致性問題 —— 在修改 Cache 資料後,如何同步回記憶體?有 2 種寫入策略:
3.2 寫直達策略(Write-Through)
寫直達策略是解決 Cache 與記憶體一致性最簡單直接的方式: 在每次寫入操作中,同時修改 Cache 資料和記憶體資料,始終保持 Cache 資料和記憶體資料一致:
- 1、如果資料不在 Cache 中,則直接將資料寫入記憶體;
- 2、如果資料已經載入到 Cache 中,則不僅要將資料寫入 Cache,還要將資料寫入記憶體。
寫直達的優點和缺點都很明顯:
- 優點: 每次讀取操作就是純粹的讀取,不涉及對記憶體的寫入操作,讀取速度更快;
- 缺點: 每次寫入操作都需要同時寫入 Cache 和寫入記憶體,在寫入操作上失去了 CPU 快取記憶體的價值,需要花費更多時間。
寫直達策略

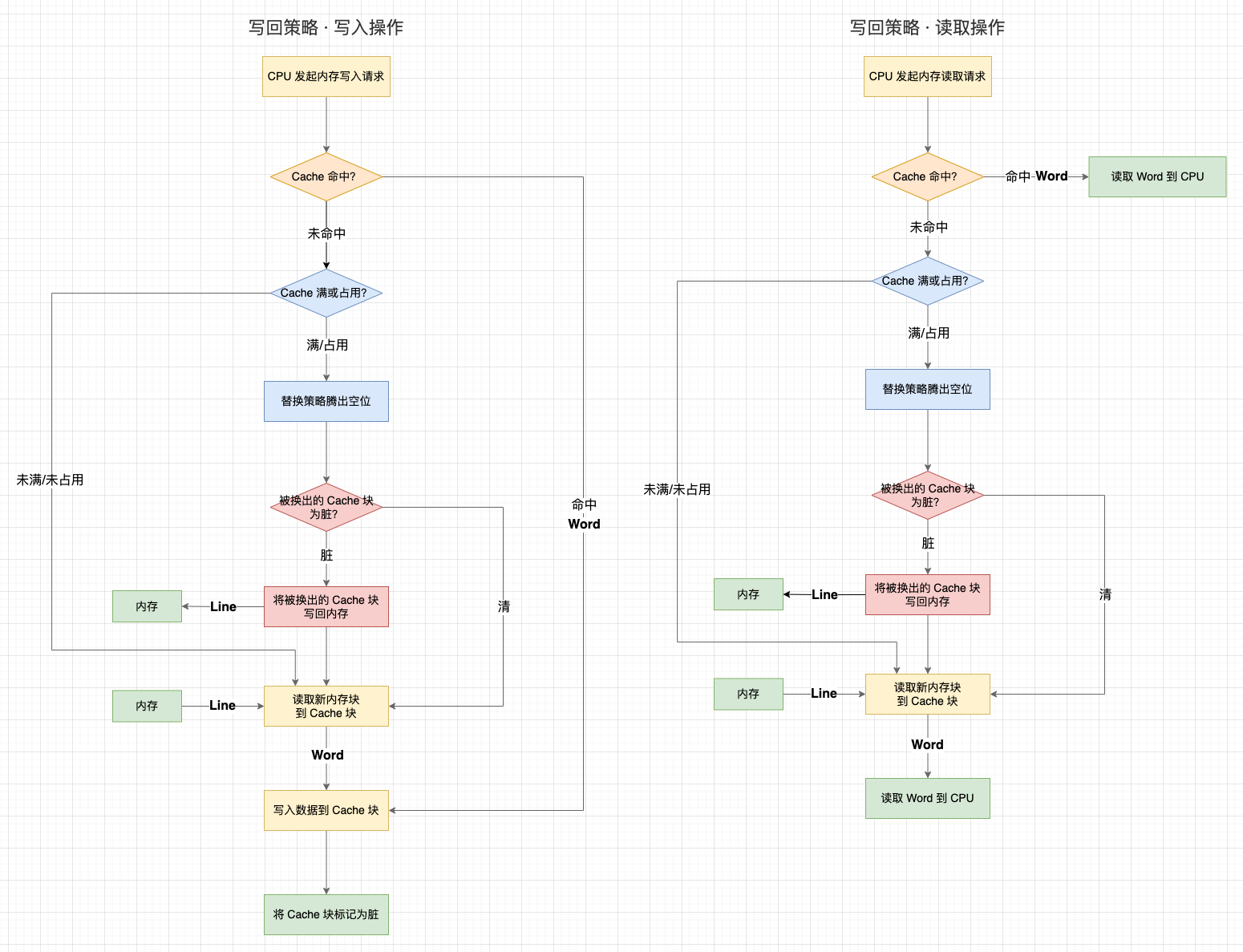
3.3 寫回策略(Write-Back)
既然寫直達策略在每次寫入操作都會寫記憶體,那麼有沒有什麼辦法可以減少寫回記憶體的次數呢?這就是寫回策略:
-
1、寫回策略會在每個 Cache 塊上增加一個 「髒(Dirty)」 標記位 ,當一個 Cache 被標記為髒時,說明它的資料與記憶體資料是不一致的;
-
2、在寫入操作時,我們只需要修改 Cache 塊並將其標記為髒,而不需要寫入記憶體;
-
3、那麼,什麼時候才將髒資料寫回記憶體呢?—— 就發生在 Cache 塊被替換出去的時候:
- 3.1 在寫入操作中,如果目標記憶體塊不在 Cache 中,需要先將記憶體塊資料讀取到 Cache 中。如果替換策略換出的舊 Cache 塊是髒的,就會觸發一次寫回記憶體操作;
- 3.2 在讀取操作中,如果目標記憶體塊不在 Cache 中,且替換策略換出的舊 Cache 塊是髒的,就會觸發一次寫回記憶體操作;
可以看到,寫回策略只有當一個 Cache 資料將被替換出去時判斷資料的狀態,「清(未修改過,資料與記憶體一致)」 的 Cache 塊不需要寫回記憶體,「髒」 的 Cache 塊才需要寫回記憶體。這個策略能夠減少寫回記憶體的次數,效能會比寫直達更高。當然,寫回策略在讀取的時候,有可能不是純粹的讀取了,因為還可能會觸發一次髒 Cache 塊的寫入。
這裡還有一個設計: 在目標記憶體塊不在 Cache 中時,寫直達策略會直接寫入記憶體。而寫回策略會先把資料讀取到 Cache 中再修改 Cache 資料,這似乎有點多餘?其實還是為了減少寫回記憶體的次數。雖然在未命中時會增加一次讀取操作,但後續重複的寫入都能命中快取。否則,只要一直不讀取資料,寫回策略的每次寫入操作還是需要寫入記憶體。
寫回策略
通過寫直達或寫回策略,我們已經能夠解決 「在修改 Cache 資料後,如何同步回記憶體」 的問題。接下來,我們來討論第 2 個快取一致性問題 —— 在一個核心修改 Cache 資料後,如何同步給其他核心 Cache?
4. 橫向:多核心 Cache 的一致性問題
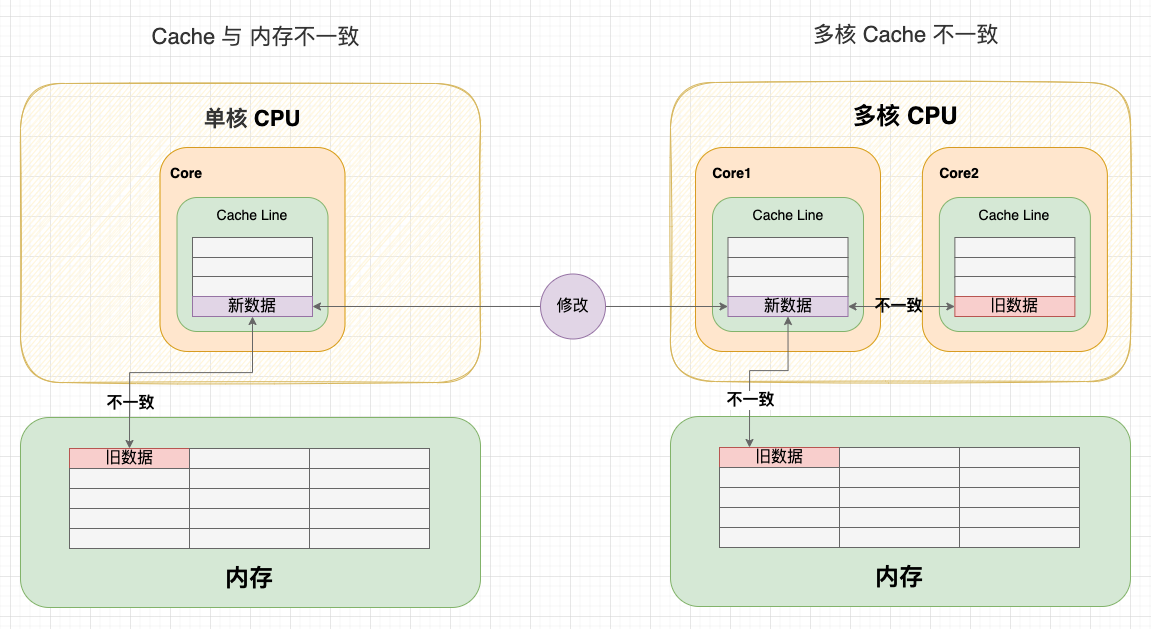
在單核 CPU 中,我們通過寫直達策略或寫回策略保持了Cache 與記憶體的一致性。但是在多核 CPU 中,由於每個核心都有一份獨佔的 Cache,就會存在一個核心修改資料後,兩個核心 Cache 不一致的問題。
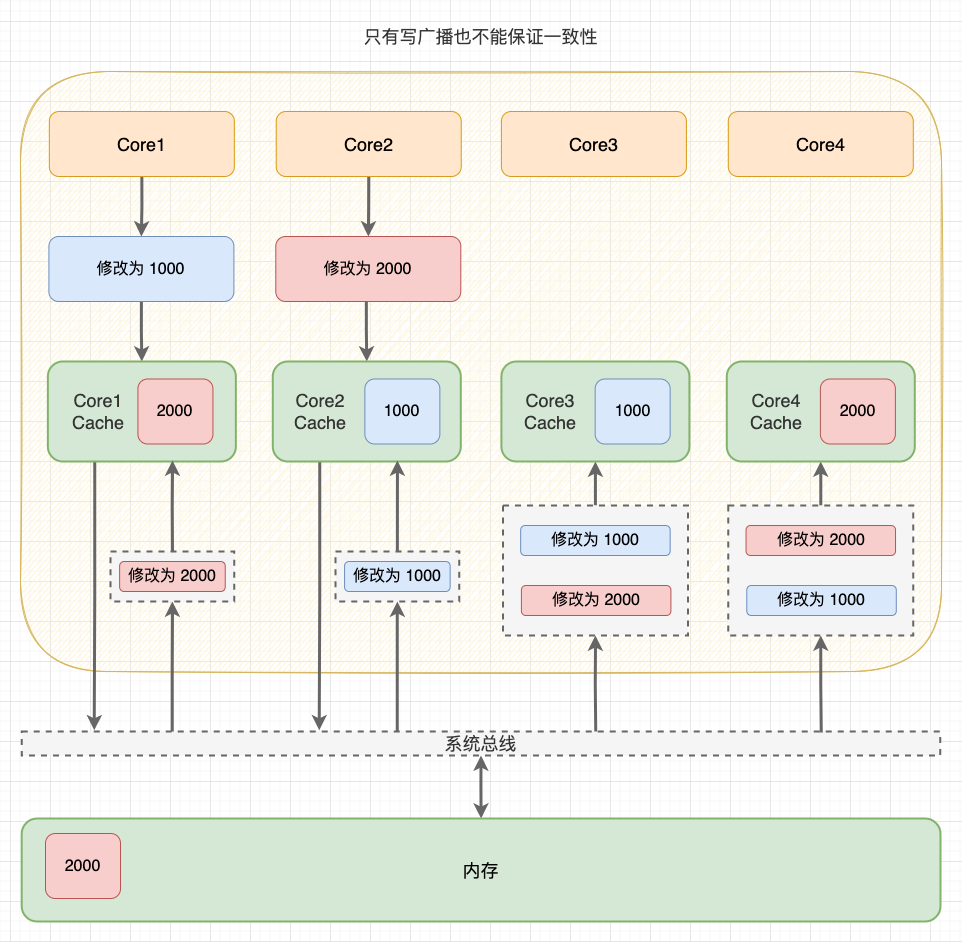
舉個例子:
-
1、Core 1 和 Core 2 讀取了同一個記憶體塊的資料,在兩個 Core 都快取了一份記憶體塊的副本。此時,Cache 和記憶體塊是一致的;
-
2、Core 1 執行記憶體寫入操作:
-
2.1 在寫直達策略中,新資料會直接寫回記憶體,此時,Cache 和記憶體塊一致。但由於之前 Core 2 已經讀過這塊資料,所以 Core 2 快取的資料還是舊的。此時,Core 1 和 Core 2 不一致;
-
2.2 在寫回策略中,新資料會延遲寫回記憶體,此時 Cache 和記憶體塊不一致。不管 Core 2 之前有沒有讀過這塊資料,Core 2 的資料都是舊的。此時,Core 1 和 Core 2 不一致。
-
-
3、由於 Core 2 無法感知到 Core 1 的寫入操作,如果繼續使用過時的資料,就會出現邏輯問題。
多核 Cache 不一致

可以看到:由於兩個核心的工作是獨立的,在一個核心上的修改行為不會被其它核心感知到,所以不管 CPU 使用寫直達策略還是寫回策略,都會出現快取不一致問題。 所以,我們需要一種機制,將多個核心的工作聯合起來,共同保證多個核心下的 Cache 一致性,這就是快取一致性機制。
4.1 寫傳播 & 事務序列化
快取一致性機制需要解決的問題就是 2 點:
-
特性 1 - 寫傳播(Write Propagation): 每個 CPU 核心的寫入操作,需要傳播到其他 CPU 核心;
-
特性 2 - 事務序列化(Transaction Serialization): 各個 CPU 核心所有寫入操作的順序,在所有 CPU 核心看起來是一致。
第 1 個特性解決了 「感知」 問題,如果一個核心修改了資料,就需要同步給其它核心,很好理解。但只做到同步還不夠,如果各個核心收到的同步訊號順序不一致,那最終的同步結果也會不一致。
舉個例子:假如 CPU 有 4 個核心,Core 1 將共用資料修改為 1000,隨後 Core 2 將共用資料修改為 2000。在寫傳播下,「修改為 1000」 和 「修改為 2000」 兩個事務會同步到 Core 3 和 Core 4。但是,如果沒有事務序列化,不同核心收到的事務順序可能是不同的,最終資料還是不一致。
非事務序列化
4.2 匯流排嗅探 & 匯流排仲裁
寫傳播和事務序列化在 CPU 中是如何實現的呢?—— 此處隆重請出計算機匯流排系統。
-
寫傳播 - 匯流排嗅探: 匯流排除了能在一個主模組和一個從模組之間傳輸資料,還支援一個主模組對多個從模組寫入資料,這種操作就是廣播。要實現寫傳播,其實就是將所有的讀寫操作廣播到所有 CPU 核心,而其它 CPU 核心時刻監聽匯流排上的廣播,再修改原生的資料;
-
事務序列化 - 匯流排仲裁: 匯流排的獨佔性要求同一時刻最多隻有一個主模組佔用匯流排,天然地會將所有核心對記憶體的讀寫操作序列化。如果多個核心同時發起匯流排事務,此時匯流排仲裁單元會對競爭做出仲裁,未獲勝的事務只能等待獲勝的事務處理完成後才能執行。
提示: 寫傳播還有 「基於目錄(Directory-base)」 的實現方案。
基於匯流排嗅探和匯流排仲裁,現代 CPU 逐漸形成了各種快取一致性協定,例如 MESI 協定。
4.3 MESI 協定
MESI 協定其實是 CPU Cache 的有限狀態機,一共有 4 個狀態(MESI 就是狀態的首字母):
- M(Modified,已修改): 表明 Cache 塊被修改過,但未同步回記憶體;
- E(Exclusive,獨佔): 表明 Cache 塊被當前核心獨佔,而其它核心的同一個 Cache 塊會失效;
- S(Shared,共用): 表明 Cache 塊被多個核心持有且都是有效的;
- I(Invalidated,已失效): 表明 Cache 塊的資料是過時的。
在 「獨佔」 和 「共用」 狀態下,Cache 塊的資料是 「清」 的,任何讀取操作可以直接使用 Cache 資料;
在 「已失效」 和 「已修改」 狀態下,Cache 塊的資料是 「髒」 的,它們和記憶體的資料都可能不一致。在讀取或寫入 「已失效」 資料時,需要先將其它核心 「已修改」 的資料寫回記憶體,再從記憶體讀取;
在 「共用」 和 「已失效」 狀態,核心沒有獲得 Cache 塊的獨佔權(鎖)。在修改資料時不能直接修改,而是要先向所有核心廣播 RFO(Request For Ownership)請求 ,將其它核心的 Cache 置為 「已失效」,等到獲得迴應 ACK 後才算獲得 Cache 塊的獨佔權。這個獨佔權這有點類似於開發語言層面的鎖概念,在修改資源之前,需要先獲取資源的鎖;
在 「已修改」 和 「獨佔」 狀態下,核心已經獲得了 Cache 塊的獨佔權(鎖)。在修改資料時不需要向匯流排傳送廣播,能夠減輕匯流排的通訊壓力。
事實上,完整的 MESI 協定更復雜,但我們沒必要記得這麼細。我們只需要記住最關鍵的 2 點:
-
關鍵 1 - 阻止同時有多個核心修改的共用資料: 當一個 CPU 核心要求修改資料時,會先廣播 RFO 請求獲得 Cache 塊的所有權,並將其它 CPU 核心中對應的 Cache 塊置為已失效狀態;
-
關鍵 2 - 延遲迴寫: 只有在需要的時候才將資料寫回記憶體,當一個 CPU 核心要求存取已失效狀態的 Cache 塊時,會先要求其它核心先將資料寫回記憶體,再從記憶體讀取。
提示: MESI 協定在 MSI 的基礎上增加了 E(獨佔)狀態,以減少只有一份快取的寫操作造成的匯流排通訊。
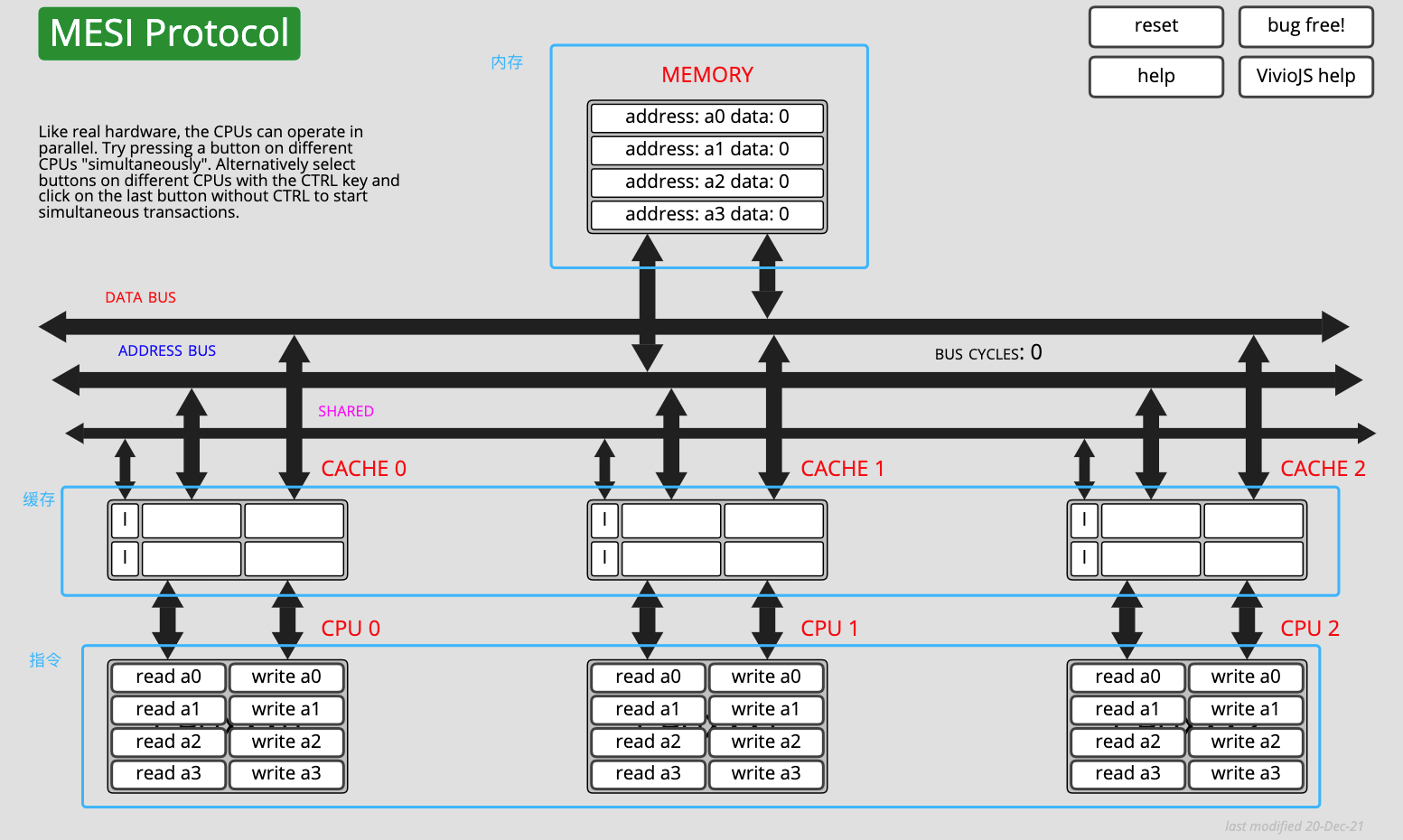
MESI 協定有一個非常 nice 的線上體驗網站,你可以對照文章內容,在網站上操作指令區,並觀察記憶體和快取的資料和狀態變化。網站地址:https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESI.htm
MESI 協定線上模擬
4.4 寫緩衝區 & 失效佇列
MESI 協定保證了 Cache 的一致性,但完全地遵循協定會影響效能。 因此,現代的 CPU 會在增加寫緩衝區和失效佇列將 MESI 協定的請求非同步化,以提高並行度:
- 寫緩衝區(Store Buffer)
由於在寫入操作之前,CPU 核心 1 需要先廣播 RFO 請求獲得獨佔權,在其它核心迴應 ACK 之前,當前核心只能空等待,這對 CPU 資源是一種浪費。因此,現代 CPU 會採用 「寫緩衝區」 機制:寫入指令放到寫緩衝區後並行送 RFO 請求後,CPU 就可以去執行其它任務,等收到 ACK 後再將寫入操作寫到 Cache 上。
- 失效佇列(Invalidation Queue)
由於其他核心在收到 RFO 請求時,需要及時迴應 ACK。但如果核心很忙不能及時回覆,就會造成傳送 RFO 請求的核心在等待 ACK。因此,現代 CPU 會採用 「失效佇列」 機制:先把其它核心發過來的 RFO 請求放到失效佇列,然後直接返回 ACK,等當前核心處理完任務後再去處理失效佇列中的失效請求。
寫緩衝區 & 失效佇列

事實上,寫緩衝區和失效佇列破壞了 Cache 的一致性。 舉個例子:初始狀態變數 a 和變數 b 都是 0,現在 Core1 和 Core2 分別執行這兩段指令,最終 x 和 y 的結果是什麼?
Core1 指令
a = 1; // A1
x = b; // A2
Core2 指令
b = 2; // B1
y = a; // B2
我們知道在未同步的情況下,這段程式可能會有多種執行順序。不管怎麼執行,只要 2 號指令是在 1 號指令後執行的,至少 x 或 y 至少一個有值。但是在寫緩衝區和失效佇列的影響下,程式還有以意料之外的方式執行:
| 執行順序(先不考慮 CPU 超前流水線控制) | 結果 |
|---|---|
| A1 → A2 → B1 → B2 | x = 0, y = 1 |
| A1 → B1 → A1 → B2 | x = 2, y = 1 |
| B1 → B2 → A1 → A2 | x = 1, y = 0 |
| B1 → A1 → B2 → A2 | x = 2, y = 1 |
| A2 → B1 → B2 → A1(A1 與 A2 重排) | x = 0, y = 0 |
| Core2 也會出現相同的情況,不再贅述 | x = 0, y = 0 |

上圖。
寫緩衝區造成指令重排
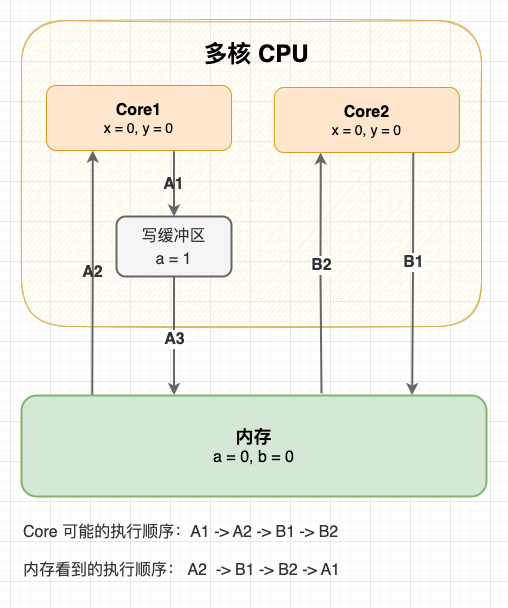
可以看到:從記憶體的視角看,直到 Core1 執行 A3 來重新整理寫緩衝區,寫操作 A1 才算真正執行了。雖然 Core 的執行順序是 A1 → A2 → B1 → B2,但記憶體看到的順序卻是 A2 → B1 → B2 → A1,變數 a 寫入沒有同步給對變數 a 的讀取,Cache 的一致性被破壞了。
5. 總結
-
1、在 CPU Cache 的三級快取中,會存在 2 個快取一致性問題:
- 縱向 - Cache 與記憶體的一致性問題: 在修改 Cache 資料後,如何同步回記憶體?
- 橫向 - 多核心 Cache 的一致性問題: 在一個核心修改 Cache 資料後,如何同步給其他核心 Cache?
-
2、Cache 與記憶體的一致性問題有 2 個策略:
- 寫直達策略: 始終保持 Cache 資料和記憶體資料一致,在每次寫入操作中都會寫入記憶體;
- 寫回策略: 只有在髒 Cache 塊被替換出去的時候寫回記憶體,減少寫回記憶體的次數;
-
3、多核心 Cache 一致性問題需要滿足 2 點特性:
- 寫傳播(匯流排嗅探): 每個 CPU 核心的寫入操作,需要傳播到其他 CPU 核心;
- 事務序列化(匯流排仲裁): 各個 CPU 核心所有寫入操作的順序,在所有 CPU 核心看起來是一致。
-
4、MESI 協定能夠滿足以上 2 點特性,通過 「已修改、獨佔、共用、已失效」 4 個狀態實現了 CPU Cache 的一致性;
-
5、現代 CPU 為了提高並行度,會在增加 寫緩衝區 & 失效佇列 將 MESI 協定的請求非同步化, 從記憶體的視角看就是指令重排,破壞了 CPU Cache 的一致性。
今天,我們主要討論了 CPU 的快取一致性問題與對應的快取一致性協定。這裡有一個問題:既然 CPU 已經實現了 MESI 協定,已經在硬體層面實現了寫傳播和事務序列化,為什麼 Java 語言層面還需要定義 volatile 關鍵字呢?豈不是多此一舉?
你可能會說因為寫緩衝區和失效佇列破壞了 Cache 一致性。好,那不考慮這個因素的話,還需要定義 volatile 關鍵字嗎?這個問題我們在 下一篇文章 展開討論,請關注。
參考資料
- 深入淺出計算機組成原理(第 37、38、39 講) —— 徐文浩 著,極客時間 出品
- 深入理解 Java 虛擬機器器(第 5 部分) —— 周志明 著
- Java 並行程式設計的藝術(第 1、2、3 章) —— 方騰飛 魏鵬 程曉明 著
- 計算機組成原理教學(第 7 章) —— 尹豔輝 王海文 邢軍 著
- 10 張圖開啟 CPU 快取一致性的大門 —— 小林 Coding 著
- CPU有快取一致性協定(MESI),為何還需要 volatile —— 一角錢技術 著
- Cache Miss – What It Is and How to Reduce It —— Linda D. 著
- CPU cache —— Wikipedia
- CPU caches —— LWN.net
- Cache coherence —— Wikipedia
- Directory-based cache coherence —— Wikipedia
- MESI protocol —— Wikipedia
