二維條碼的祕密(生成原理)
我是風箏,公眾號「古時的風箏」,專注於 Java技術 及周邊生態。
文章會收錄在 JavaNewBee 中,更有 Java 後端知識圖譜,從小白到大牛要走的路都在裡面。
這裡所說的二維條碼預設指的就是我們經常用到的微信二維條碼這樣方形格式的,二維條碼的英文全稱是 Quick Response Code,快速響應矩陣圖碼。
我們簡直不要太熟悉了,平均每天都要掃碼好幾次,做核酸掃碼、吃飯付錢掃碼、進出辦公樓掃碼。

就像上面這樣,二維條碼就是用黑白或者明暗的格子來分別代表1和0,用黑色代表1,白色代表0,將0和1連線成二進位制串,就能幻化出各種各樣的內容,當然其中要經過各種演演算法、編碼、解碼等操作。
這是公眾號的二維條碼,裡面儲存的內容其實就是一個連結地址,也就是一段文字內容,然後用微信掃碼或者直接長按識別後,經過微信二維條碼識別程式的處理,將其中的內容讀取出來,並且經過一系列的檢測,判斷這是微信公眾號的二維條碼,於是跳轉到公眾號主頁。
那二維條碼儲存的不都是文字嗎,不管是連結還是什麼其他的東西,都是將二維條碼解析之後再做處理,是連結就跳轉、是純文字就顯示。是這樣沒錯,但是畢竟二維條碼最後是以圖片的形式展示,還是要越小越好。
所以,二維條碼在最初設計的時候就制定了幾種模式,每種模式都用最簡便的編碼方式處理,保證最後出來的二維條碼最簡單。
二維條碼的幾種模式
二維條碼說白了其實就是一種協定,和我們熟知的 IP、HTTP 協定類似,都是規定好一個標準,比如 IP 的頭部資訊,用4bit表示版本號,4bit表示首部長度等。
用4個bit標記當前二維條碼所採用的的模式,反應到二維條碼上就是4個格子。
數位編碼模式
此模式對應的場景是內容全部都是數位的情況,標記為0001。

字元編碼模式
內容包含數位和大寫的A-Z(不包含小寫)、以及$ % * + – . / : 和空格,標記為 0010 。
位元組編碼模式
支援0x00~0xFF內所有的字元,標記為 0100。
Kanji mode
日文模式,因為二維條碼是日本的工程師發明的,雙位元組編碼,這個模式下也可以支援中文,標記為 1000 。
中文
支援中文,一箇中文佔3個位元組,標記為 1101 。
混合模式
同時支援多種編碼格式,可以包含中文、應為、數位等內容,標記為 0011 。
ECI
用於特殊字元,標記為 0111 。
FNC1
主要是給一些特殊的工業或行業用的,比如GS1條形碼之類的。
二維條碼版本的概念
二維條碼版本是從0到40,每增加一個版本,在現有基礎上橫向增加4行、縱向增加4列,計算公式為(V - 1) * 4 + 21,其中V是版本號,比如版本是1,就是橫豎各21個格子,版本號是2,就是橫豎各25個格子。
例如下圖,其中內圈白色的版本號為1,格子數為 21 x 21,外圈加上了黃色的框,版本號為2,利用公式計算,其格子數為 25 x 25,橫豎各增加了 4 個。
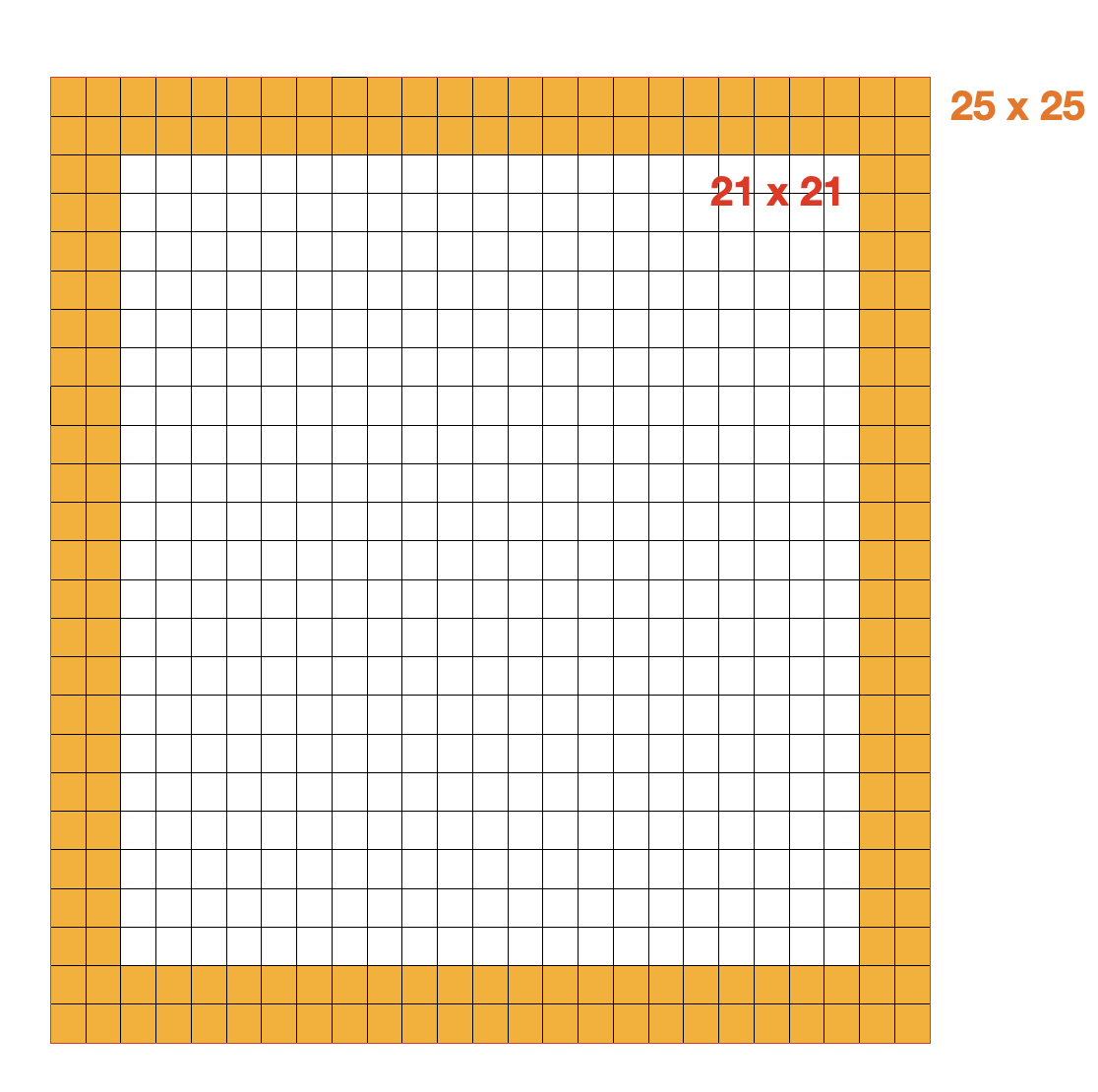
版本越大,格子數越多,包含的資訊量就越大,但同時生成和識別所需的時間也就越長,而且如果二維條碼的面積不變,那生成的格子也就越密集。
同樣都是一個英文字元 A的二維條碼,左邊版本號為1,右邊版本號為40,清晰程度一目瞭然。

容錯率
我們都知道,二維條碼在遮住其中的某些部分,或者不太清楚的情況下, 大多數時候仍然能識別出來的,這其實是和二維條碼本身設計機制中的容錯率有關的。
下面兩個二維條碼,左邊遮擋了一小部分,右邊遮擋了比較大的部分,左邊就可以正常的識別出來,而右邊的無論用什麼使用者端也識別不出來。

我們平時生活中也能碰到這種情況,比如之前騎共用單車的時候,有的二維條碼被颳了一點,但是還是可以掃出來的,但是有的二維條碼被刮花了很大不一部分,無論掃多長時間也於事無補。
容錯率有4個等級,容錯等級越高可修復的面積就越大,最高的修復率達到30%,也就是二維條碼有將近 1/3的面積被覆蓋了,仍然能識別出來,當然不包括一些關鍵的區域,接下來會提到。
L 級
約 7 %的字碼可被修復
M 級
約 15%的字碼可以被修復
Q 級
約 25%的字碼可以被修復
H 級
約 30%的字碼可以被修復
一般場景下,容錯率都在15%左右,因為容錯等級越高,代價就越大,為了修復被遮蓋的部分,只能加入更多的冗餘資訊。
字碼是二維條碼中定義的一個概念,其實就是 8個bit,一個位元組的單位。
最大容量
決定二維條碼的最大容量的因素有兩個,一個是版本,一個是容錯率。
版本越大,其格子數越多,所以可以編碼的二進位制位就越多,最終所能儲存的資料量也就越多。
容錯率越低,其中所冗餘的用於糾錯的資訊就越少,所以最終真正的資料內容也就越大,因為總容量是固定的。
下面表格是版本號40(最大版本號)、容錯率為L(最低容錯)的情況下,不同的內容型別所能承載的最大容量,數位最多是7089個,而採用 UTF-8 編碼的中文最多就984個。
| 內容型別 | (對於版本40) |
|---|---|
| 數位 | 最多7,089字元 |
| 字母 | 最多4,296字元 |
| 二進位制數(8 bit) | 最多2,953 位元組 |
| 日文漢字 | 最多1,817字元(採用Shift JIS) |
| 中文漢字 | 最多984字元(採用UTF-8) |
現實情況中,一般也不會用二維條碼做大量的儲存,我們可以看一下包含大量內容的二維條碼最後的生成效果。已經給出提示了,手機和掃碼槍不易掃碼。

生成步驟
用最簡單的版本為1的二維條碼舉例。
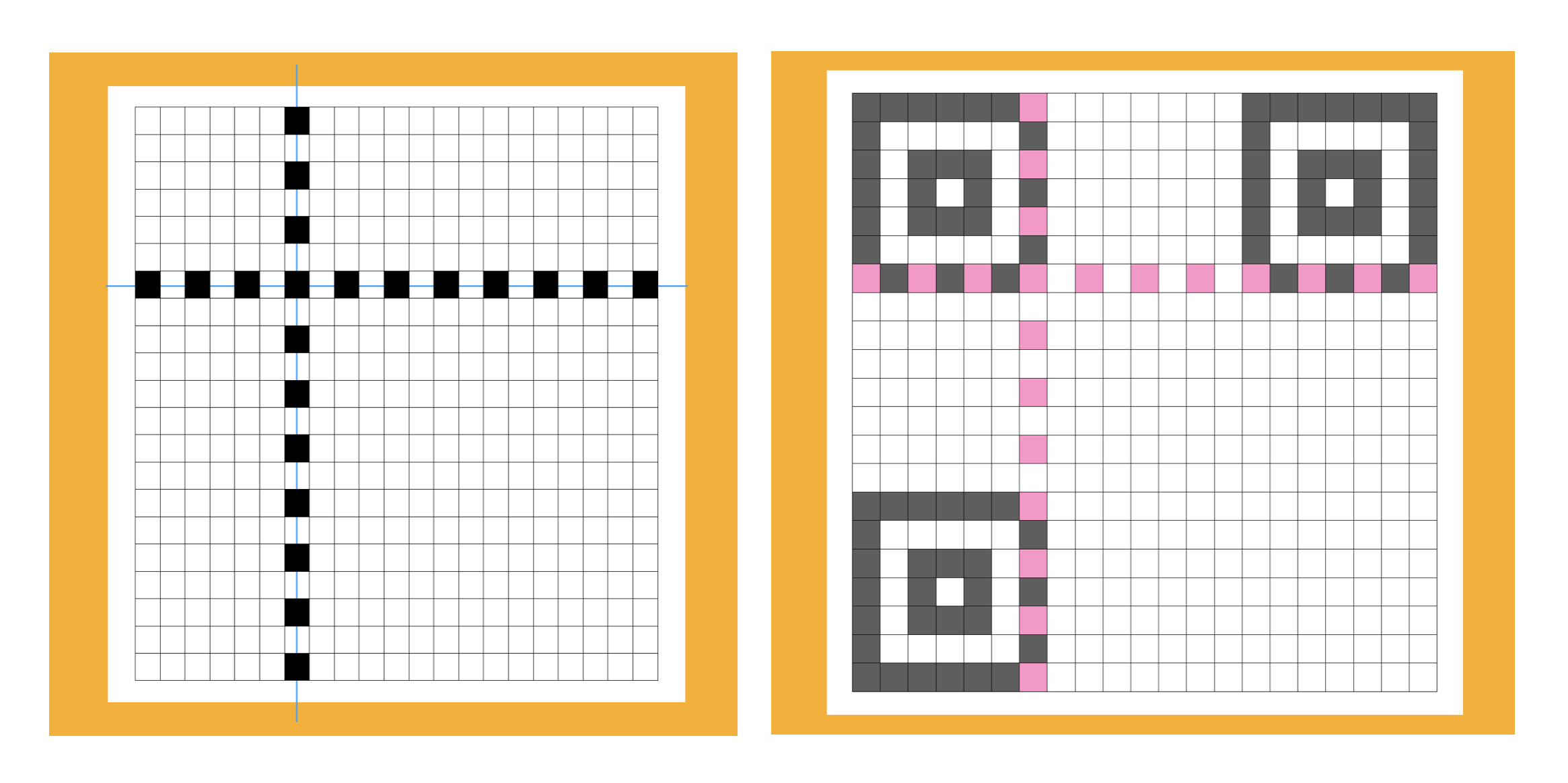
三個回型定位區域
這三個回型的區域可以幫助掃碼器(例如微信或掃碼槍)定位二維條碼的,與三個回型定位區域緊挨的格子要留白,也就是下圖藍色線所在的格子。
並且最後在二維條碼的周圍要有一定的留白空間,這樣可以幫助掃碼器快速的定位二維條碼的整個區域。

在版本大於1的時候,還有一個小的定位塊,在靠右下的藍色框位置。

定位線
兩條用來定位的定位線,一般用在版本比較高的二維條碼上。
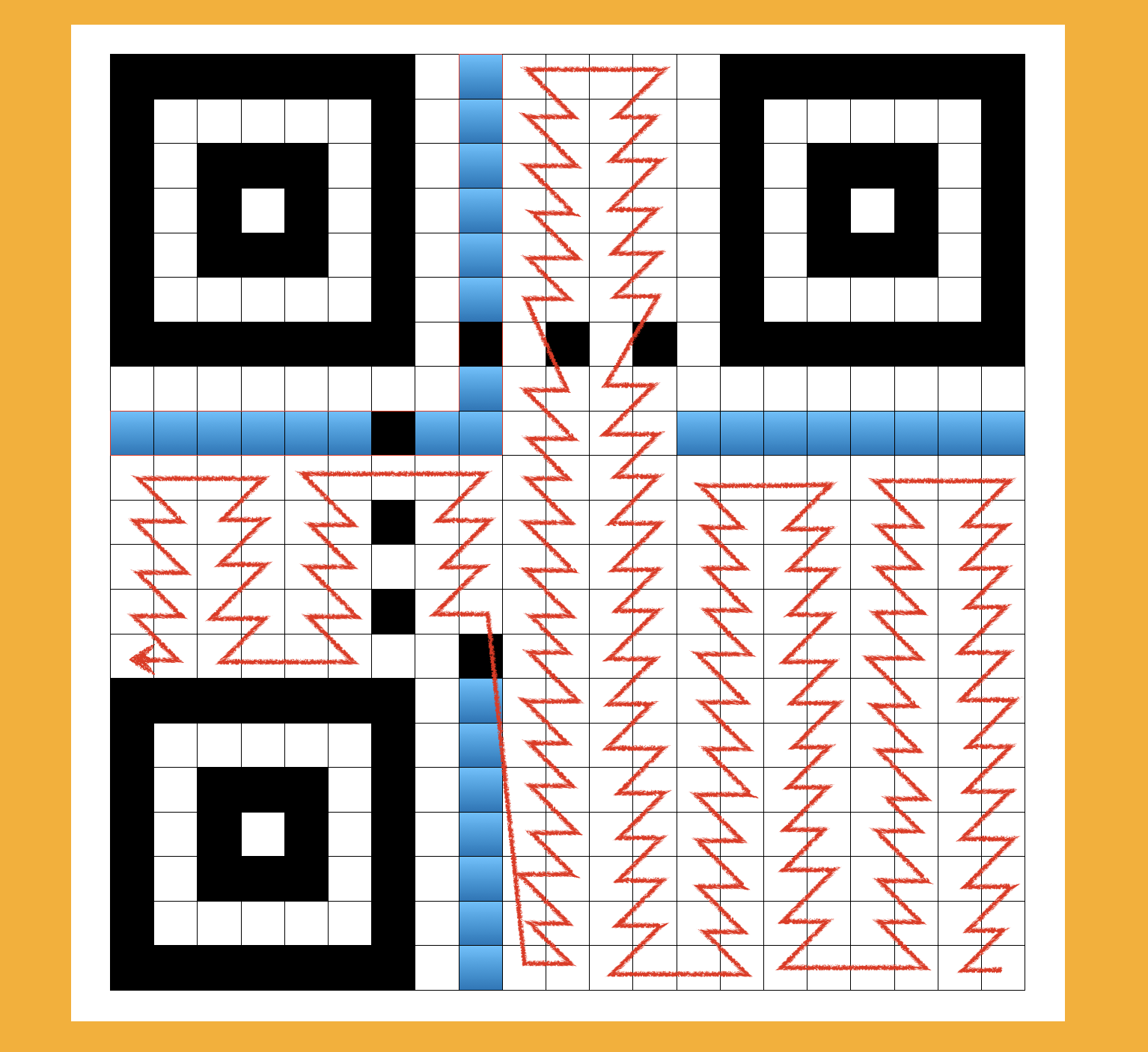
填充格式資料
有一些固定的格子是用來儲存當前二維條碼的格式資訊的,比如版本號、容錯級別、編碼模式。下圖中的藍色格子,分別有兩組15bit的區域,這兩部分就用來儲存當前二維條碼的格式資訊,以二進位制串的形式出現,不同的容錯級別以及其他設定不同,從而計算出來的二進位制串也不同。這部分計算有專門的演演算法,也可以通過查表的方式獲取,因為總共的組合方式是固定的,也就是幾十種。
這部分的資料因為有容錯率的設計,所以其實也是有冗餘的,不光只有內容資料容錯,格式資料如果有部分遮擋的情況,也應該能識別出來。

如果版本大於6的話,會另外在右上和左下的回型區域的旁邊開闢兩塊3 x 6 的區域,用來儲存更多的格式資訊。如下圖的紅色格子。

填充內容資料
填充完格式資料後,剩下的就是真正的內容資料了,不同的模式有不同的計算方式。
例如字元模式。
1、拆成字元對:HE, LL, O (空格), WO, RL, D
2、參考字母數位表,轉換成對應的數位,然後用第一個字元數位*45+第二個字元數位,再轉換成二進位制,一個字元補滿6位,兩個字元補滿11位。例如:HE=(45*17)+14=779,再轉換成二進位制 779 → 01100001011。為什麼要乘以45呢,就是這麼約定的。
確定了模式和容錯級別,就能確定二維條碼所能容納的最大值,如果資料量較少,沒有達到最大值,就要在內容二進位制串後面加上四個0bit位 0000,用來標示真正內容的結束。
如果仍然不夠最大長度,則在後面連續加入 236和17的二進位制串 11101100 00010001,至於為什麼是這兩個數位,沒有為什麼,就這麼約定的。
最後將計算出來的二進位制串從右下角開始依次填充,每次跨兩列。跳過回型定位區、定位線,以及個數資料區域。遇到1就填充成黑色或者深色,遇到0就填充上白色或者淺色。
掩碼美化
其實上一步生成好的二維條碼就已經可以用了,但是資料都非常集中,所以最後的出來的二維條碼黑色塊和白色塊分配嚴重不均,最後的效果就不太好。比如下面這樣的

為了顏值,所以基本上在生成最終二維條碼之前都會加上掩模這一步。其實就是和8種固定的圖案(被稱作掩碼圖案)中的一種做互斥或計算,最終就可以得到一個分佈均勻且比較美觀的最終形態。下面是這8種掩碼圖案。

最後的效果就是我們經常看到的那些二維條碼。
還可以到一些線上的平臺對生成的二維條碼進行美化,最後的呈現的效果可能像下面這樣,不過美化的太過,識別起來就比較慢了,不信你可以識別下面的二維條碼感受一下。

參考檔案:https://www.nayuki.io/page/creating-a-qr-code-step-by-step
公眾號「古時的風箏」,Java 開發者,全棧工程師,bug 殺手,擅長解決問題。
一個兼具深度與廣度的程式設計師鼓勵師,本打算寫詩卻寫起了程式碼的田園碼農!堅持原創乾貨輸出,你可選擇現在就關注我,或者看看歷史文章再關注也不遲。長按二維條碼關注,跟我一起變優秀!
