論文翻譯:2022_DeepFilterNet2: Towards Real-Time Speech Enhancement On Embedded Devices For Fullband Audi
部落格地址:凌逆戰
論文地址:DeepFilternet2: 面向嵌入式裝置的全波段音訊實時語音增強
論文程式碼:https://github.com/Rikorose/DeepFilterNet
參照格式:Schröter H, Rosenkranz T, Maier A. DeepFilterNet2: Towards Real-Time Speech Enhancement on Embedded Devices for Full-Band Audio[J]. arXiv preprint arXiv:2205.05474, 2022.
摘要
基於深度學習的語音增強技術已經取得了巨大的進步,最近還擴充套件到了全頻帶音訊(48 kHz)。然而,許多方法都有相當高的計算複雜度,需要大的時間緩衝來實時使用,例如由於時間折積或注意力。這兩者都使得這些方法在嵌入式裝置上不可行。這項工作進一步擴充套件了DeepFilterNet,利用語音的諧波結構實現了有效的語音增強。訓練過程、資料增強和網路結構中的幾項優化使SE效能達到了最先進的水平,同時在筆電Core-i5 CPU上將實時因子降低到0.04。這使得演演算法可以在嵌入式裝置上實時執行。DeepFilterNet框架可以在開源許可下獲取。
索引術語:DeepFilterNet,語音增強,全波段,兩級建模
1 引言
最近,基於深度學習的語音增強已經擴充套件到全頻帶(48 kHz)[1,2,3,4]。大多數SOTA方法通過對噪聲音訊訊號進行短時傅立葉變換(STFT)在頻域進行SE,並在類似於深度神經網路(DNN)的U-Net中對訊號進行增強。然而,許多方法在乘法累積操作(MAC)和記憶體頻寬方面有相對較大的計算需求。也就是說,較高的取樣率通常需要較大的FFT視窗,從而產生大量的頻率bin,這直接轉化為更多的MAC。
PercepNet[1]通過使用三角形ERB(等效矩形頻寬)濾波器組解決了這個問題。在這裡,基於STFT的頻率bin被對數壓縮到32個ERB波段。然而,這隻允許實值處理,這就是為什麼PercepNet額外應用梳狀過濾器來更好地增強語音的週期性成分。相反,FRCRN[3]將頻率bin分成3個通道,以減少頻率軸的大小。這種方法允許對複數比例掩碼(CRM)進行復數的處理和預測。類似地,DMF-Net[4]使用多波段方法,其中頻率軸被分成3個波段,由不同的網路分別處理。一般來說,與單階段方法相比,像DMF-Net這樣的多階段網路最近展示了它們的潛力。例如,GaGNet[5]在特徵提取階段之後使用兩個所謂的glance和gaze階段。glance模組在粗量級域上工作,而gaze模組在複數域上處理頻譜,允許以更精細的解析度重建頻譜。
在這項工作中,我們擴充套件了[2]的工作,[2]也分為兩個階段。DeepFilterNet利用了由一個週期分量和一個隨機分量組成的語音模型。第一階段在ERB域中工作,只增強語音包絡,而第二階段使用深度濾波[6,7]來增強週期性成分。在本文中,我們描述了在Voicebank+Demand[8]和深度噪聲抑制(DNS) 4盲測挑戰資料集[9]上實現SOTA效能的幾個優化。此外,這些優化提高了執行時效能,使得在樹莓派4上實時執行模型成為可能。
2 方法
2.1 訊號模型和DeepFilterNet框架
我們假設噪音和語音是不相關的,比如
$$公式1:x(t)=s(t)*h(t)+n(t)$$
其中$s(t)$是純淨語音訊號,$n(t)$是加性噪聲,$h(t)$是模擬混響環境的房間脈衝響應,產生噪聲混合物$x(t)$。這直接轉化為頻域
$$公式2:X(k,f)=S(k,f)*H(k,f)+N(k,f)$$
其中$X(k, f)$為時域訊號$X(t)$的STFT表示,$k, f$為時間和頻率指標。
在本研究中,我們採用了DeepFilterNet[2]的兩階段去噪過程。也就是說,第一階段在量級範圍內執行,並預測實值增益。整個第一階段在一個壓縮的ERB域內進行,目的是在模擬人耳聽覺感知時減少計算複雜性。因此,第一階段的目的是在粗頻率解析度下增強語音包絡。第二階段利用深度濾波在複數域內工作[7,6],試圖重構語音的週期性。[2]表明,深度濾波(DF)通常優於傳統的複數比掩模(CRMs),特別是在very noisy的條件下。
組合SE過程可以表述如下。編碼器$F_{enc}$將ERB和複數特徵編碼到一個embedding $\varepsilon$中。
$$公式3:\varepsilon (k)=F_{enc}(X_{erb}(k,b),X_{df}(k,f_{erb}))$$
接下來,第一階段預測實值增益$G$並增強語音包絡,從而得到短時頻譜$Y_G$。
$$公式4:\begin{aligned}
G_{erb}(k, b) &=\mathcal{F}_{erb\_dec}(\mathcal{E}(k)) \\
G(k, f) &=\operatorname{interp}(G_{{erb }}(k, b)) \\
Y_G(k, f) &=X(k, f) \cdot G(k, f)
\end{aligned}$$
最後在第二階段,$F_{df\_dec}$預測了$N$階的DF係數$C_{df}^N$,然後將其線性應用於$Y_G$。
$$公式5:\begin{aligned}
C_{\mathrm{df}}^N\left(k, i, f_{\mathrm{df}}\right) &=\mathcal{F}_{\mathrm{df} d e c}(\mathcal{E}(k)) \\
Y\left(k, f^{\prime}\right) &=\sum_{i=0}^N C\left(k, i, f^{\prime}\right) \cdot X(k-i+l, f)
\end{aligned}$$
$l$是DF look-ahead。如前所述,第二級只工作在頻頻譜的較低部分,頻率為$f_{df}$= 5 kHz。DeepFilterNet2框架如圖1所示。

圖1所示 DeepFilterNet2語音增強過程的概述
2.2 訓練流程
在DeepFilterNet[2]中,我們使用了exponential learning rate schedule和fixed weight decay。在這項工作中,我們還使用了一個學習率warmup 3個epoch,然後是cosine decay。最重要的是,我們在每次迭代時更新學習率,而不是在每個階段之後更新。類似地,我們用不斷增加的cosine schedule來安排權值衰減,從而為訓練的後期階段帶來更大的正則化。最後,為了實現更快的收斂,特別是在訓練的開始階段,我們使用batch scheduling[10],batch size從8開始,逐漸增加到96。排程方案如圖2所示。

圖2所示 用於訓練的學習率、權重衰減和batch size
2.3 多目標損失
我們採用[2]的頻譜損失$L_{spec}$。此外,使用多解析度(MR)頻譜損失,其中增強頻譜$Y(k, f)$首先轉換為時域,然後計算多個stft,視窗從5 ms到40 ms[11]。為了傳播這種損失的梯度,我們使用pytorch STFT/ISTFT,它在數值上足夠接近於Rust中實現的原始DeepFilterNet處理迴圈。
$$公式6:\mathcal{L}_{\mathrm{MR}}=\sum_i\left\|\left|Y_i^{\prime}\right|^c-\left|S_i^{\prime}\right|^c\right\|^2\left\|\left|Y_i^{\prime}\right|^c e^{j \varphi_Y}-\left|S_i^{\prime}\right|^c e^{j \varphi_S}\right\|^2$$
其中$Y_i'= STFT_i(y)$為預測TD訊號y的第$i$個視窗大小為{5,10,20,40}ms的STFT, $c = 0.3$為壓縮引數[1]。與DeepFilterNet[2]相比,我們去掉了$\alpha$損失項,因為所使用的啟發式僅是區域性語音週期性的較差近似。此外,DF可以增強非語音部分的語音,並可以通過將係數$t_0$的實部設定為1,將其餘係數設定為0來禁用其效果。多目標綜合損失為:
$$公式7:L=\lambda_{spec}L_{spec}+\lambda_{ML}L_{ML}$$
2.4 資料增強
DeepFilterNet在深度噪聲抑制(DNS) 3挑戰資料集[12]上進行訓練,而我們在DNS4[9]的英語部分上對DeepFilterNet2進行訓練,因為DNS4[9]包含更多的全波段噪聲和語音樣本。
在語音增強中,通常只減少背景噪聲,在某些情況下還會減少混響[1,11,2]。在這項工作中,我們將SE的概念進一步擴充套件到下降。因此,我們區分了動態資料預處理管道中的增強和失真。增強應用於語音和噪聲樣本,目的是進一步擴充套件網路在訓練中觀察到的資料分佈。另一方面,失真只應用於語音樣本,用於噪聲混合的建立。清晰語音目標不受失真變換的影響。因此,DNN學會重建原始的、未失真的語音訊號。目前,DeepFilterNet框架支援以下隨機增強
- 隨機二階濾波[13]
- 改變Gain
- 通過二階濾波器的均衡器
- 重取樣的速度和音高變化[13]
- 新增彩色噪聲(不用於語音樣本)
除去噪外,DeepFilterNet還將嘗試恢復以下失真:
- 混響:通過衰減房間傳遞函數,目標訊號將包含更少的混響。
- 裁剪訊雜比為[20,0]dB的偽影。
2.5 DNN
我們保留了DeepFilterNet[2]的一般折積U-Net結構,但做了以下調整。最終的架構如圖3所示。
1、Unification of the encoder。ERB和複數特徵的折積現在都在編碼器中處理,連線,並傳遞到分組線性(GLinear)層和單個GRU。
2、Simplify Grouping。以前,線性層和GRU層的分組是通過獨立的更小的層實現的,這導致了相對較高的處理開銷。在DeepFilterNet2中,只有線性層在頻率軸上分組,通過單一矩陣乘法實現。GRU hidden dim被減少到256。我們還在DF解碼器的輸出層應用分組,激勵相鄰頻率足以預測濾波器係數。這大大減少了執行時間,而只增加了少量flop的數量。
3、Reduction of temporal kernels。雖然時間折積(TCN)或時間注意已經成功地應用於SE,但它們在實時推理時需要時間緩衝。這可以通過環形緩衝區有效地實現,然而,緩衝區需要儲存在記憶體中。這種額外的記憶體存取可能會導致頻寬成為限制瓶頸,尤其對於嵌入式裝置來說可能是這種情況。因此,我們減小了折積的核大小並將折積從2*3轉置到1*3,即頻率軸上的1D。現在只有輸入層通過因果3*3折積合併了時間上下文。這大大減少了實時推理期間使用的時間緩衝區。
4、Depthwise pathway convolutions。當使用可分離折積時,大量的引數和flop位於1*1折積處。因此,在路徑折積(PConv)中新增分組可以大大減少引數,同時不會損失任何顯著的SE效能。

圖3 DeepFilterNet2架構
2.6 後處理
我們採用了Valin等人[1]首先提出的後濾波器,目的是略微過衰減有噪聲的TF bin,同時為噪聲較小的頻點增加一些增益。我們在第一階段的預測gains上執行此操作
$$公式8:\begin{aligned}
G^{\prime}(k, b) &\leftarrow G(k, b)) \cdot \sin \left(\frac{\pi}{2} G(k, b)\right) \\
G(k, b) & \leftarrow \frac{(1+\beta) \cdot G(k, b)}{1+\beta+G^{\prime}(b, k)}
\end{aligned}$$
3 實驗
3.1 實現細節
如2.4節所述,我們在DNS4資料集上訓練DeepFilterNet2,總共使用超過500小時的全波段純淨語音(大約)。150 H的噪聲以及150個真實的和60000個模擬的HRTFs。我們將資料分為訓練集、驗證集和測試集(70%、15%、15%)。Voicebank集是分離說話人獨佔,與測試集沒有重疊。我們在Voicebank+Demand測試集[8]和DNS4盲測試集[9]上評估了我們的方法。我們用AdamW對模型進行了100個epoch的訓練,並根據驗證損失選擇最佳模型。
在這項工作中,我們使用20毫秒的視窗,50%的重疊,以及兩個幀的look-ahead,導致總體演演算法延遲40毫秒。我們取32個ERB波段,$f_{DF}$= 5kHz,DF階數$N = 5$,look-ahead = 2幀。損失引數$\lambda_{spec}=1e3$和$\lambda_{spec}=5e2$的選擇使兩個損失的數量級相同。原始碼和一個預先訓練的DeepFilterNet2可以在https://github.com/Rikorose/DeepFilterNet獲得。
3.2 結果
我們使用Valentini語音庫+需求測試集[8]來評估DeepFilterNet2的語音增強效能。因此,我們選擇WB-PESQ [19], STOI[20]和綜合指標CSIG, CBAK, COVL[21]。表1顯示了DeepFilterNet2與其他先進(SOTA)方法的比較結果。可以發現,DeepFilterNet2實現了sota級別的結果,同時需要最小的每秒乘法累積運算(MACS)。在DeepFilterNet(第2.5節)上,引數的數量略有增加,但該網路能夠以兩倍多的速度執行,並獲得0.27的高PESQ評分。GaGNet[5]實現了類似的RTF,同時具有良好的SE效能。然而,它只在提供整個音訊時執行得很快,由於它使用了大的時間折積核,需要大的時間緩衝區。FRCRN[3]在大多數指標上都能獲得最好的結果,但具有較高的計算複雜度,這在嵌入式裝置上是不可實現的。
表1 Voicebank+Demand測試集的客觀結果。實時因子(RTF)是在筆電Core i5-8250U CPU上通過5次執行的平均值來測量的。
未報告的相關工作表示為 -
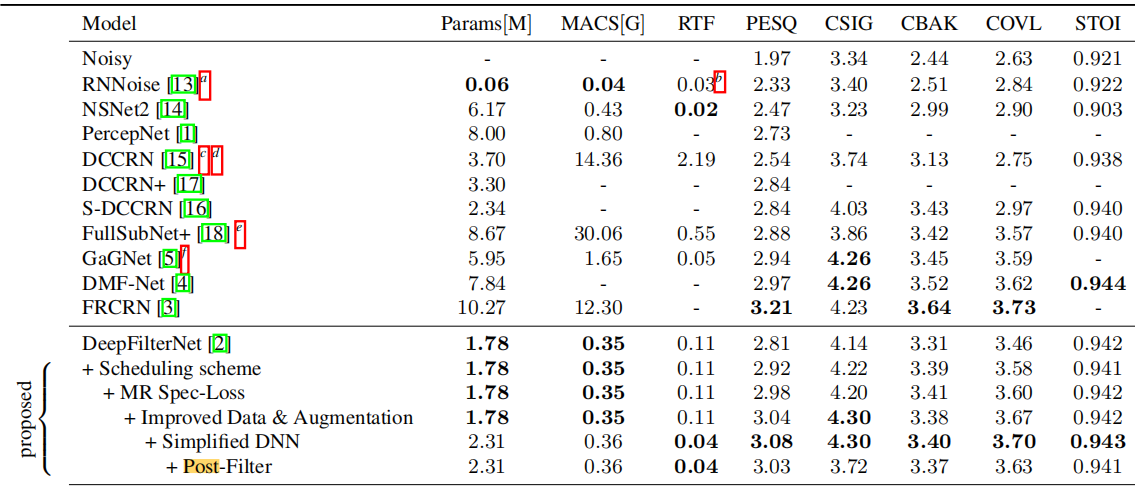
- a、度量和RTF測量的原始碼和權重提供在https://github.com/xiph/rnnoise
- b、注意,RNNoise執行單執行緒
- c、RTF測量的原始碼提供在https://github.com/huyanxin/DeepComplexCRN
- d、複合和STOI指標由相同的作者在[16]中提供
- e、度量和RTF測量的原始碼和權重提供在:https://github.com/hit-thusz-RookieCJ/FullSubNet-plus
- f、RTF測量的原始碼提供在:https://github.com/Andong-Li-speech/GaGNet
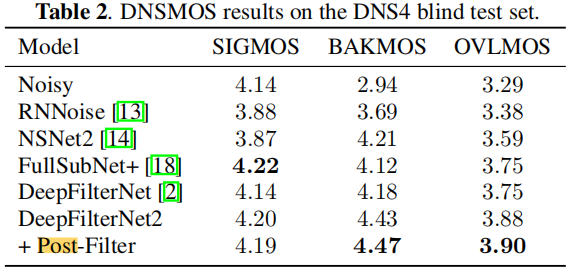
表2顯示了DNSMOS P.835[22]在DNS4盲試驗集上的結果。雖然deepfilternet[2]不能提高語音質量平均意見評分(SIGMOS),但使用DeepFilterNet2我們也獲得了良好的結果,對於背景和總體MOS值。此外,DeepFilterNet2相對接近用於選擇純淨語音樣本來訓練DNS4基線NSNet2 (SIG=4.2, BAK=4.5, OVL=4.0)[9]的最小DNSMOS值,進一步強調了其良好的SE效能。
4 結論
在這項工作中,我們提出了一個低複雜度的語音增強框架DeepFilterNet2。利用DeepFilterNet的感知方法,我們能夠進一步應用一些優化,從而提高SOTA SE的效能。由於其輕量級的架構,它可以在樹莓派4上以0.42的實時係數執行。在未來的工作中,我們計劃將語音增強的想法擴充套件到其他增強,比如糾正由於當前房間環境造成的低通特性。
5 參考
[1] Jean-Marc Valin, Umut Isik, Neerad Phansalkar, Ritwik Giri, Karim Helwani, and Arvindh Krishnaswamy, A Perceptually-Motivated Approach for Low-Complexity, Real-Time Enhancement of Fullband Speech, in INTERSPEECH 2020, 2020.
[2] Hendrik Schr oter, Alberto N Escalante-B, Tobias Rosenkranz, and Andreas Maier, DeepFilterNet: A low complexity speech enhancement framework for fullband audio based on deep filtering, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022.
[3] Shengkui Zhao, Bin Ma, Karn N Watcharasupat, and Woon-Seng Gan, FRCRN: Boosting feature representation using frequency recurrence for monaural speech enhancement, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022.
[4] Guochen Yu, Yuansheng Guan, Weixin Meng, Chengshi Zheng, and Hui Wang, DMF-Net: A decoupling-style multi-band fusion model for real-time full-band speech enhancement, arXiv preprint arXiv:2203.00472, 2022.
[5] Andong Li, Chengshi Zheng, Lu Zhang, and Xiaodong Li, Glance and gaze: A collaborative learning framework for single-channel speech enhancement, Applied Acoustics, vol. 187, 2022.
[6] Hendrik Schr oter, Tobias Rosenkranz, Alberto Escalante Banuelos, Marc Aubreville, and Andreas Maier, CLCNet: Deep learning-based noise reduction for hearing aids using complex linear coding, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020.
[7] Wolfgang Mack and Emanu el AP Habets, Deep Filtering: Signal Extraction and Reconstruction Using Complex Time-Frequency Filters, IEEE Signal Processing Letters, vol. 27, 2020.
[8] Cassia Valentini-Botinhao, Xin Wang, Shinji Takaki, and Junichi Yamagishi, Investigating RNN-based speech enhancement methods for noise-robust Text-toSpeech, in SSW, 2016.
[9] Harishchandra Dubey, Vishak Gopal, Ross Cutler, Ashkan Aazami, Sergiy Matusevych, Sebastian Braun, Sefik Emre Eskimez, Manthan Thakker, Takuya Yoshioka, Hannes Gamper, et al., ICASSP 2022 deep noise suppression challenge, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022.
[10] Samuel L Smith, Pieter-Jan Kindermans, Chris Ying, and Quoc V Le, Don t decay the learning rate, increase the batch size, arXiv preprint arXiv:1711.00489, 2017.
[11] Hyeong-Seok Choi, Sungjin Park, Jie Hwan Lee, Hoon Heo, Dongsuk Jeon, and Kyogu Lee, Real-time denoising and dereverberation wtih tiny recurrent u-net, in International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
[12] Chandan KA Reddy, Harishchandra Dubey, Kazuhito Koishida, Arun Nair, Vishak Gopal, Ross Cutler, Sebastian Braun, Hannes Gamper, Robert Aichner, and Sriram Srinivasan, Interspeech 2021 deep noise suppression challenge, in INTERSPEECH, 2021.
[13] Jean-Marc Valin, A hybrid dsp/deep learning approach to real-time full-band speech enhancement, in 2018 IEEE 20th international workshop on multimedia signal processing (MMSP). IEEE, 2018.
[14] Sebastian Braun, Hannes Gamper, Chandan KA Reddy, and Ivan Tashev, Towards efficient models for realtime deep noise suppression, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021.
[15] Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie, DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement, in INTERSPEECH, 2020.
[16] Shubo Lv, Yihui Fu, Mengtao Xing, Jiayao Sun, Lei Xie, Jun Huang, Yannan Wang, and Tao Yu, SDCCRN: Super wide band dccrn with learnable complex feature for speech enhancement, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022.
[17] Shubo Lv, Yanxin Hu, Shimin Zhang, and Lei Xie, DCCRN+: Channel-wise Subband DCCRN with SNR Estimation for Speech Enhancement, in INTERSPEECH, 2021.
[18] Jun Chen, Zilin Wang, Deyi Tuo, Zhiyong Wu, Shiyin Kang, and Helen Meng, FullSubNet+: Channel attention fullsubnet with complex spectrograms for speech enhancement, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022.
[19] ITU, Wideband extension to Recommendation P.862 for the assessment of wideband telephone networks and speech codecs, ITU-T Recommendation P.862.2, 2007.
[20] Cees H Taal, Richard C Hendriks, Richard Heusdens, and Jesper Jensen, An algorithm for intelligibility prediction of time frequency weighted noisy speech, IEEE Transactions on Audio, Speech, and Language Processing, 2011.
[21] Yi Hu and Philipos C Loizou, Evaluation of objective quality measures for speech enhancement, IEEE Transactions on audio, speech, and language processing, 2007.
[22] Chandan KA Reddy, Vishak Gopal, and Ross Cutler, Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022.