這次,聽人大教授講講分散式資料庫的多級一致性|TDSQL 關鍵技術突破
近年來,憑藉高可延伸、高可用等技術特性,分散式資料庫正在成為金融行業數位化轉型的重要支撐。分散式資料庫如何在不同的金融級應用場景下,在確保資料一致性的前提下,同時保障系統的高效能和高可延伸性,是分散式資料庫的一個核心技術挑戰。
針對以上分散式一致性的困境,中國人民大學-騰訊協同創新實驗室研究提出「多級一致性」的事務處理理念。該技術包含嚴格可序列化、順序可序列化、可序列化三大隔離級別,可針對不同應用場景要求,極大地平衡效能與一致性要求,滿足金融及各類企業場景的分散式事務處理需求。該項技術已應用於騰訊分散式資料庫TDSQL產品中,確保TDSQL按需提供資料一致性,並確保資料無異常。TDSQL是當前國內率先進入國有大型銀行核心系統正式投產的國產分散式資料庫,該項技術是其中的關鍵支撐。
這次,中國人民大學教授、博士生導師盧衛老師為大家全面解鎖分散式資料庫的多級一致性及構建技術!
背景
從本質上看,資料庫是長期儲存在計算機內、有組織的、可共用的資料集合。當多個使用者並行運算元據庫時,事務排程的可序列化是並行控制的正確性理論。但該觀點在當前卻受到了挑戰。Daniel J. Abadi 在2019年釋出的一篇部落格中提到,以往學界普遍認為可序列化是資料庫隔離級別的黃金標準,但經過研究,他發現實際上嚴格可序列化才是黃金標準。即在該理論中,可序列化仍存在一定的問題,只有嚴格可序列化才能做到沒有問題。

在過去,為什麼可序列化不存在問題?原因有兩方面:
一是對集中式資料庫而言,可序列化其實就是嚴格可序列化,兩者之間並沒有區別。
二是對於分佈資料庫而言,如果資料庫裡有唯一的事務排程器或協調器,這兩者之間也可等價。

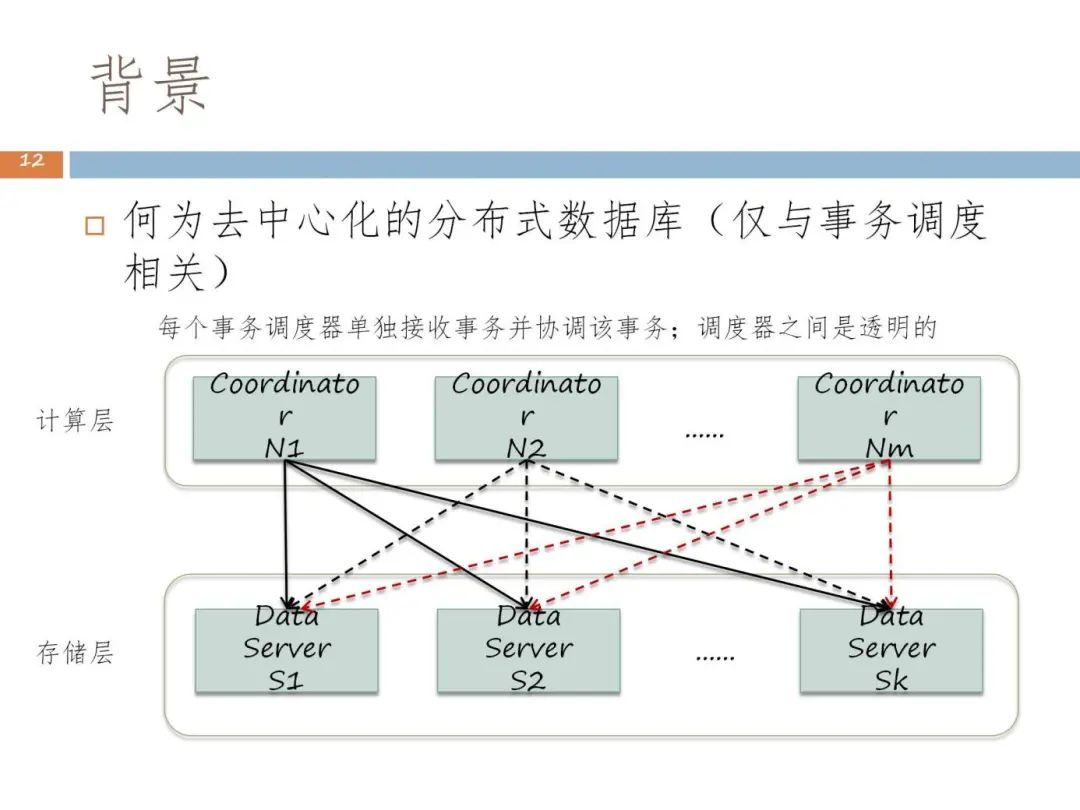
當來到去中心化的分散式資料庫時代,我們希望分散式資料庫產品可在全球部署。全球部署意味著範圍更大,如果仍然依賴集中式排程,效能和可延伸性都無法滿足應用的需求,因此需要在系統當中安排多個事務協調者進行協調。

回顧發展歷程,20年前的資料庫的標註設定為業務系統+主庫+備庫。業務系統存取主庫,主庫通過同步協定使資料在主庫和備庫之間保持一致性。在這一階段,集中式的IBM小型機、Oracle資料庫、EMC儲存(IOE)在處理小規模的資料場景時較為合適。但這種架構模式的問題在於,當資料量比較大或者業務場景比較密集時,集中式主庫就會成為整個系統的負擔。

到了第二階段,典型的做法是分庫分表,將業務按照主庫進行拆分,因為業務系統建立在主庫之上,因此實現了業務的隔離,TDSQL的早期版本也採用了這種做法。這種做法的前提假設是資料/業務能夠很好地進行切分,從而解決前一階段業務不可延伸的問題。但當業務系統進行跨庫存取時,就會帶來新的問題。

為了解決上述問題,我們來到了第三階段,即去中心化的分散式資料庫階段。在該階段,資料庫中設定了更多的事務排程器,由排程器來對每個節點資料上的子事務進行事務提交,每個事務排程器都可以獨立地去處理事務。但這也會產生新的問題,即不同協調者之間如何協調。
問題與挑戰
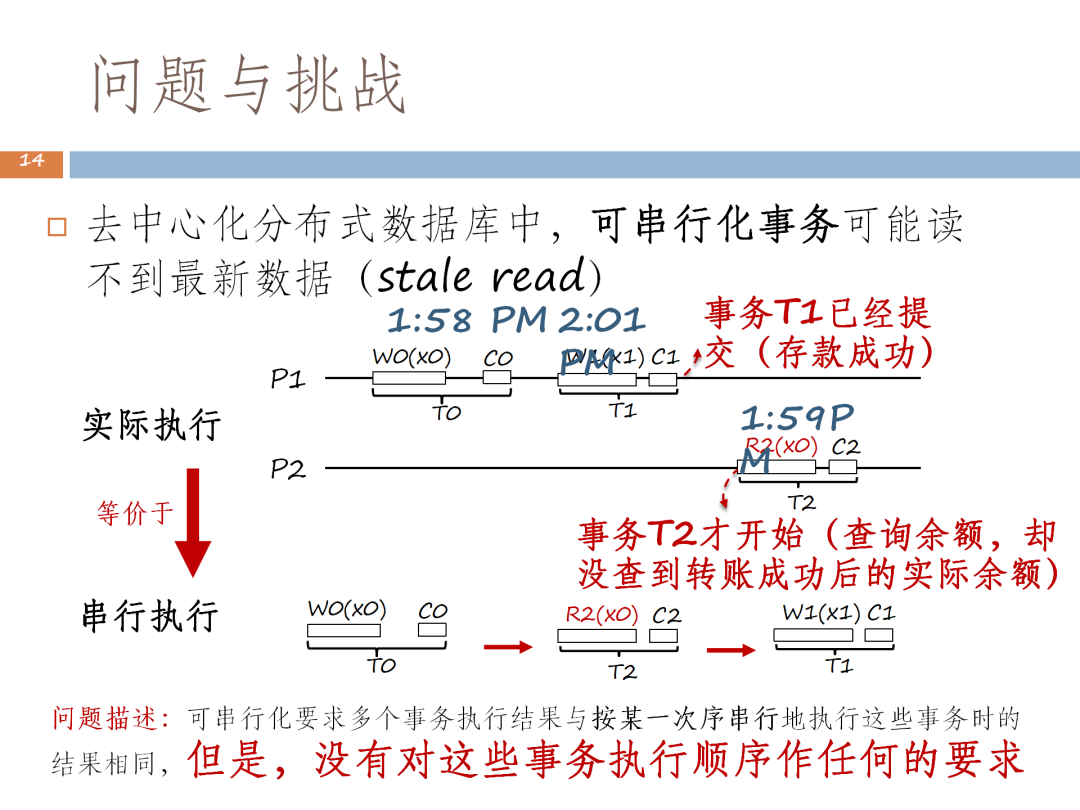
我們以下圖中的例子來說明分散式資料庫中不同協調者之間如何協調的問題。假設有一個家庭賬戶,丈夫和妻子共用,都可以進行讀和寫。丈夫在 ATM機上存了 100 塊,存完後通知妻子,但妻子有可能看不到丈夫存的這筆錢。因為這是一個多協調器的架構,裝置1交由協調者1來進行協調,妻子發起的這個事務可能由另外一個協調者去發起,這就會出現協調者之間AMG時鐘不統一的問題。

該事務發起的時間雖然在 2:01 PM後,但因為協調的時間偏慢,所以此時1:59 PM的這個時鐘去讀 2:01 PM的時間戳提交的這個資料,就會出現讀不到的情況。
形象地說,即有兩個協調器,其中一個協調器執行了事務 T0 、T1,T1 事務已經提交成功。這時協調者 2 發起了事務T2,當T2 查詢餘額時,我們發現時鐘比 T1 提交的時鐘來得小,所以讀不到T1。但實際上,是先執行 T0 再執行 T2 再執行T1,屬於可序列化。但這又會跟前述提到的執行相違背,因為既然T1已經提交, T2理應可以讀到,但結果沒有讀到。因此Daniel J. Abadi 的可序列化存在一定的問題,讀不到最新資料。
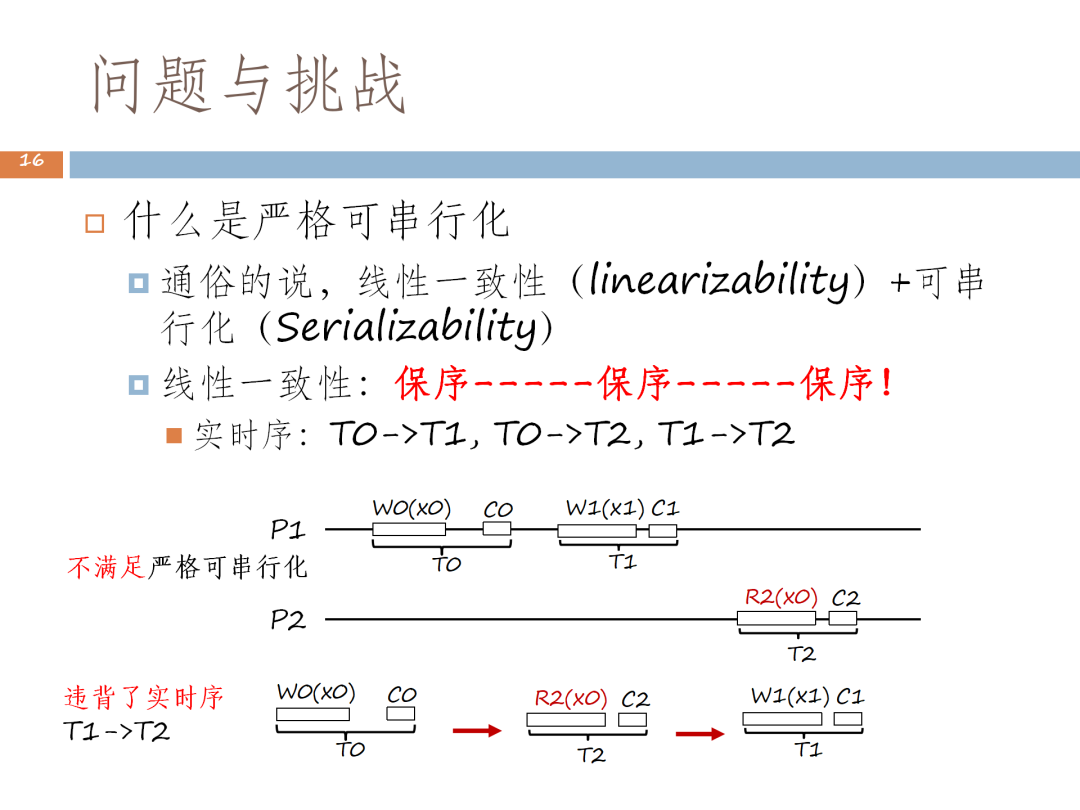
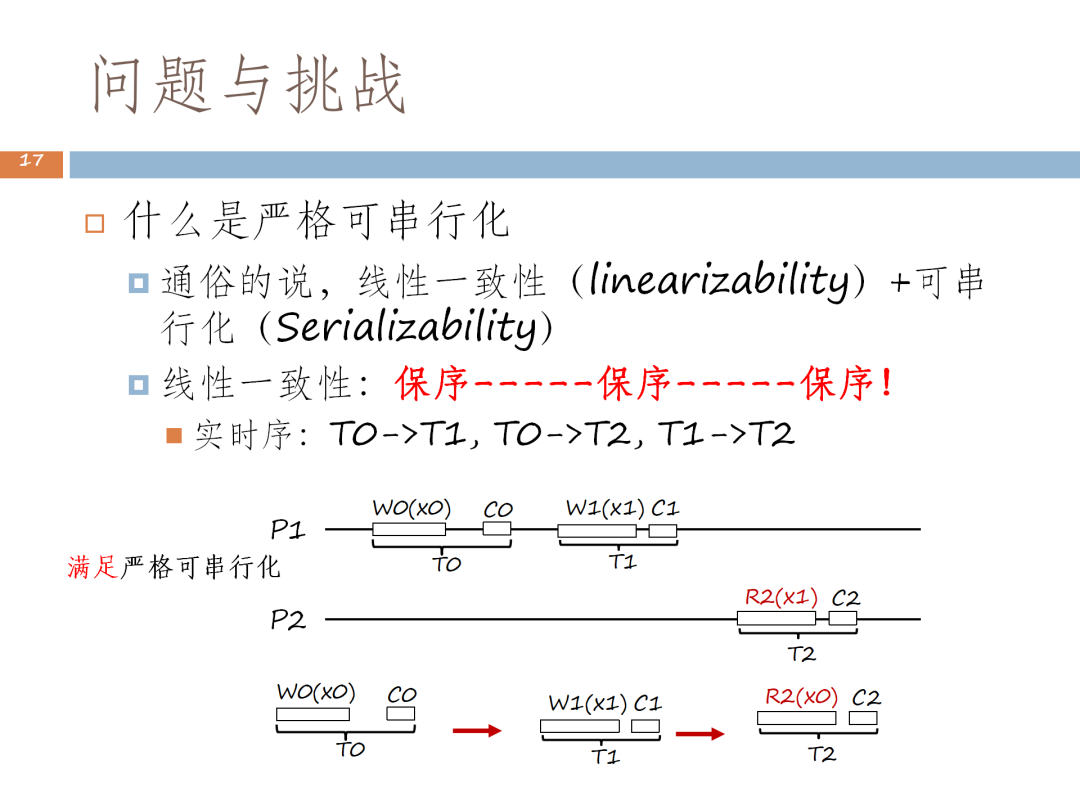
這個問題的本質是保序,而嚴格可串化的本質是線性一致性加上可序列化。從事務角度來看,根據線性一致性要求,如果T0事務已經結束,T1才開始,則T1要讀到T0的寫;同理,T1已經完成了T2才開始,T2要讀到T1的寫。雖然這裡的 T0、T2、T1 是可序列化,但違背線性一致性的要求,只有T0→ T1→ T2時才是正確的,這就是保序。
因此,這裡的實時序就是T0 結束後開始T1事務,T0 排在T1的前面;T0 完成後T2才開始,T0 排在T2的前面;T1結束後T2才開始,T1排在T2的前面。因此核心理念就是保序,即在原來可序列化全序的基礎上,對可序列化的序做約束,這個約束是線性一致性所造成的。
嚴格序列化雖然能保證資料的準確性,但也帶來了較多的問題。以Google Spanner為例,Google Spanner支援嚴格可序列化,但是嚴格可序列化要求有一個原子鐘,或者有一箇中心授時器(本質上是因為協調器和協調器之間缺少一個協調),因而導致效能較低,難以被廣泛應用於實際業務場景中。

多級可序列化建模
基於上述情況,我們希望可以找到一箇中間環節,在一致性上比可序列化級別高、比嚴格序列化級別低;在效能上接近可序列化、優於嚴格可序列化。針對這個需求,我們提出了多級可序列化建模,本質是在可序列化的基礎上加了序。
線性一致性是並行系統中一致性最強的,比它弱一點的有順序一致性、因果一致性、寫讀一致性、最終一致性等。我們嘗試將可序列化與它們進行結合,最終發現只有可序列化和線性一致性以及可序列化和順序一致性可以實現結合。因為可序列化要求全序,但因果一致性不要求全序,因此無法結合。

我們的做法是將可序列化+線性一致性,從而得到嚴格可序列化;可序列化+順序一致性,從而得到順序可序列化。所以我們提出了嚴格可序列化、順序可序列化、可序列化這三個隔離級別。

多級可序列化實現的核心理念就是保序。我們定義了五個序:
- 實時序,即原來的線性一致性要求。
- 程式序,比如程式碼中的session order,session 連線後,事務之間就變成了T0,T0 提交後才能提交T1,這就是程式序。

- 寫讀序,即如果T2讀取了T1的寫,T1必定排在T2 之前。
- 因果序,指寫讀序和程式序之間形成的閉包。
- 寫合法,假設有一個x資料項,T1寫了資料項x1,T3 寫了資料項x2,但如果T2 讀了一個x ,就必須要求T2 要緊跟T1,因為它不能緊跟在T3 後;如果它排在T3 後,則它讀的應該是 x2 ,因此這時T1和T3形成了一個序,要求T2要排在T3 前。

有了序後,我們重新定義了事務的可序列化理論,即可序列化等於寫讀序的傳遞閉包+寫合法;可序列化+順序一致性,即寫讀序+程式序的傳遞閉包,再加寫合法;嚴格可序列化就是寫讀序+實時序的傳遞閉包,加寫合法。因此可以理解為所有的一致性模型就是保序。

該理論成果已經應用於騰訊分散式資料庫TDSQL產品當中,使得TDSQL成為全球範圍內首個能夠具備嚴格可序列化、順序可序列化、可序列化三大隔離級別的國產分散式資料庫,還可針對不同應用場景要求,極大地平衡效能與一致性要求,滿足金融及各類企業場景的分散式事務處理需求。
並行控制演演算法
並行控制演演算法-雙向動態時間戳調整的實現如下圖所示。圖中有兩個協調者P1和P2,協調者P1有兩個事務T1和T3,協調者P2有T2 和T4 。我們先定義順序,T1和T3之間有一個session order或program order,T2和T4也存在一個program order,我們將它preserve 出來。

其中還存在寫讀序,像T1和T4之間,T1寫了x1,T4讀了x1,此時就存在一個寫讀序,所以要把T1和T4的order preserve出來。同時還存在寫合法,因為T3 讀了y 資料項,然後 T2 寫了y資料項, 但是基於可序列化理論,R3讀取的是y0,沒有讀取到y2,如果讀到y2,這時T3就必須排在T2後。因為此時讀不到y2 ,要排在T2前面,因此T3和 T2之間存在寫合法。在整個執行過程中,我們要保證必須存在保序。
主要思想是每次事務提交時,都需要判斷能否違背事務的先後順序。比如T1開始提交,因為T1只包含自身,我們將它放到佇列中時不需要回滾。T2 提交時,T2和T1之間沒有序,但T1和T3之間以及T2和T3之間都分別存在一個序,因為此時存在y資料項,所以只有T1、T3、T2 這樣的序才能保證可序列化,否則T必須進行回滾。

最後為保證協調器間能進行協調,我們還需要引入混合邏輯時鐘,來保證因果序。
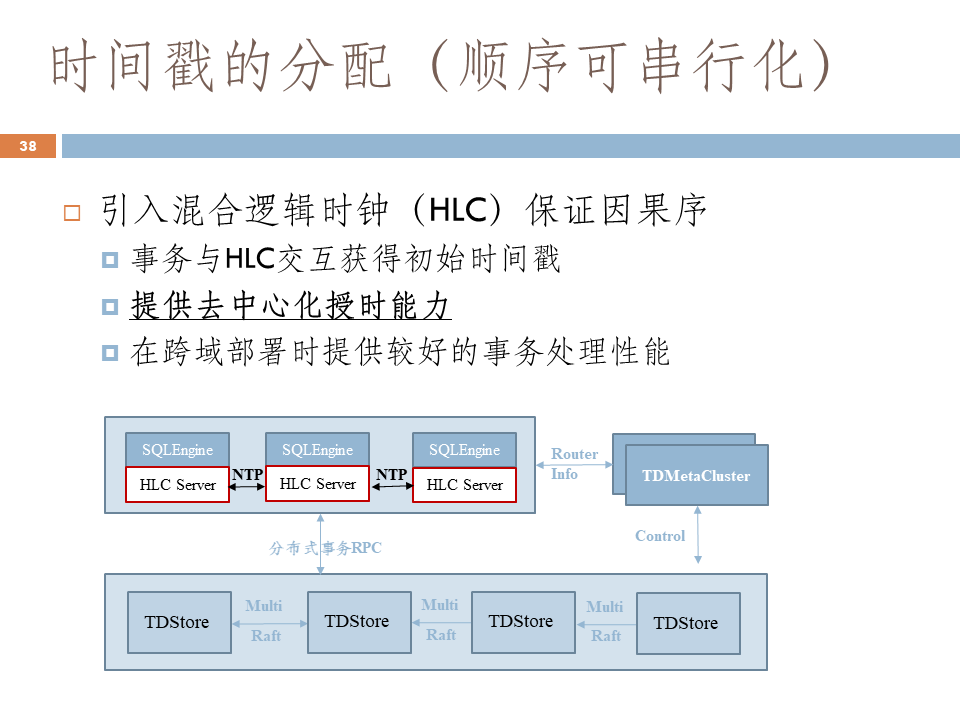
實驗評價
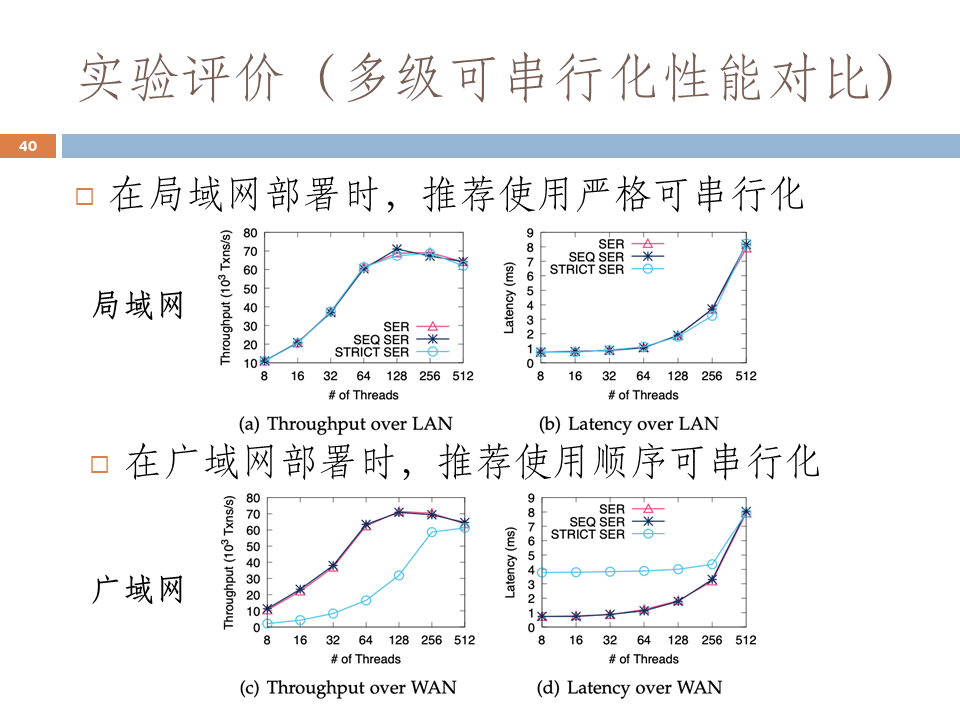
我們以下圖中的實驗為例,來說明可序列化、嚴格可序列化和順序可序列化之間的關係。如果在區域網情況下,在正確性方面,嚴格可序列化跟可序列化效能基本一致。但在廣域網情況下,嚴格可序列化、順序可序列化和可序列化之間的效能差異較大,所以導致在廣域網上很難實現嚴格可序列化。
如圖所示,BDTA演演算法比現有的演演算法如MAT、SUNDIAL等快了將近 1.8 倍,主要原因是BDTA中保序,但如果用前面的方法實現並行控制,就會造成大量事務的回滾。

總結與討論
本文提出了提出了面向分散式資料庫的多級可序列化模型,將並行系統中的一致性要求結合到可序列化中,實現了多級可序列化原型系統,保證了去中心化的事務處理機制,並設計了雙向動態時間戳調整演演算法(BDTA),可以在統一系統架構下支援多個可序列化級別。
該技術已應用於騰訊雲資料庫TDSQL中,確保TDSQL無任何資料異常,且具備高效能的可延伸性,解決了分散式資料庫在金融級場景應用的最核心技術挑戰,使得國產分散式資料庫實現在金融核心系統場景的可用。基於此,TDSQL是當前國內唯一進入國有大型銀行核心系統正式投產的國產分散式資料庫。