巨量資料下一代變革之必研究資料湖技術Hudi原理實戰雙管齊下-上
@
概述
定義
Apache Hudi 官網地址 https://hudi.apache.org/
Apache Hudi 官網檔案 https://hudi.apache.org/docs/overview
Apache Hudi GitHub原始碼地址 https://github.com/apache/hudi
Apache Hudi是可以在資料庫層上使用增量資料管道構建流資料湖,滿足記錄級更新/刪除和更改流,並實現自我管理,支援流批一體並在此基礎上持續優化。最新版本為0.12.1
Apache Hudi(發音為「hoodie」)是下一代流資料湖平臺,將核心倉庫和資料庫功能引入資料湖中。Hudi提供了表、事務、高效的upsert /delete、高階索引、流攝入服務、資料叢集/壓縮優化和並行性,同時將資料保持為開原始檔格式,在分散式檔案儲存(雲端儲存,HDFS或任何Hadoop檔案系統相容的儲存)上管理大型分析資料集的儲存;不僅非常適合於流工作負載,還允許建立高效的增量處理管道;得益於其高階效能優化,使得分析工作能否較好的支援流行的查詢引擎如Spark、Flink、Presto、Trino、Hive。總體框架及周邊關係如下:

Apache Hudi是一個快速發展的多元化社群,下面為使用和貢獻Hudi的小部分公司範例:

發展歷史
- 2015 年:發表了增量處理的核心思想/原則(O'reilly 文章)。
- 2016 年:由 Uber 建立併為所有資料庫/關鍵業務提供支援。
- 2017 年:由 Uber 開源,並支撐 100PB 資料湖。
- 2018 年:吸引大量使用者,並因雲端計算普及。
- 2019 年:成為 ASF 孵化專案,並增加更多平臺元件。
- 2020 年:畢業成為 Apache 頂級專案,社群、下載量、採用率增長超過 10 倍。
- 2021 年:支援 Uber 500PB 資料湖,SQL DML、Flink 整合、索引、元伺服器、快取。
特性
- 支援可插拔、快速索引的Upserts/Delete。
- 支援增量拉取表變更以進行增量查詢、記錄級別更改流等處理。
- 支援事務提交、回滾和並行控制,具有回滾支援的原子式釋出資料。
- 支援Spark、 Flink、Presto、 Trino、Hive等引擎的SQL讀/寫。
- 自我管理小檔案,資料聚簇、壓縮(行和列資料的非同步壓縮)和清理,使用統計資訊管理檔案大小和佈局,利用聚類優化資料湖佈局。
- 流式攝入,內建CDC源和工具。
- 內建可延伸的儲存存取的時間軸後設資料跟蹤。
- 向後相容的模式實現表結構變更的支援。寫入器和查詢之間的快照隔離,用於資料恢復的儲存點。
使用場景
- 近實時寫入
- 減少碎片化工具的使用,直接使用內建工具。
- 通過CDC工具增量匯入RDBMS資料。
- 限制小檔案的大小和數量。
- 近實時分析
- 相對於秒級的儲存(Druid、時序資料庫)節省了資源。
- 提供了分鐘級別的時效性,支撐更高效的查詢。
- Hudi作為lib,非常輕量。
- 增量pipeline
- 區分arrivetime和eventtime處理延遲資料。
- 更短的排程間隔減少端到端的延遲(從小時級別到分鐘級別)的增量處理。
- 增量匯出
- 替換部分Kafka的場景,資料匯出到線上服務儲存如ES。
編譯安裝
編譯環境
-
元件版本
- Hadoop
- Hive
- Spark(Scala-2.12)
- Flink(Scala-2.12)
-
準備編譯環境Maven
編譯Hudi
- 上傳原始碼包
# 可以在github中下載
wget https://github.com/apache/hudi/archive/refs/tags/release-0.12.1.tar.gz
# 解壓
tar -xvf release-0.12.1.tar.gz
# 進入根目錄
cd hudi-release-0.12.1/
- 修改根目錄下的pom檔案的元件版本和加速倉庫依賴下載,vim pom.xml
<hadoop.version>3.3.4</hadoop.version>
<hive.version>3.1.3</hive.version>
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
- 執行編譯命令
mvn clean package -DskipTests -Dspark3.3 -Dflink1.15 -Dscala-2.12 -Dhadoop.version=3.3.4 -Pflink-bundle-shade-hive3
編譯報錯
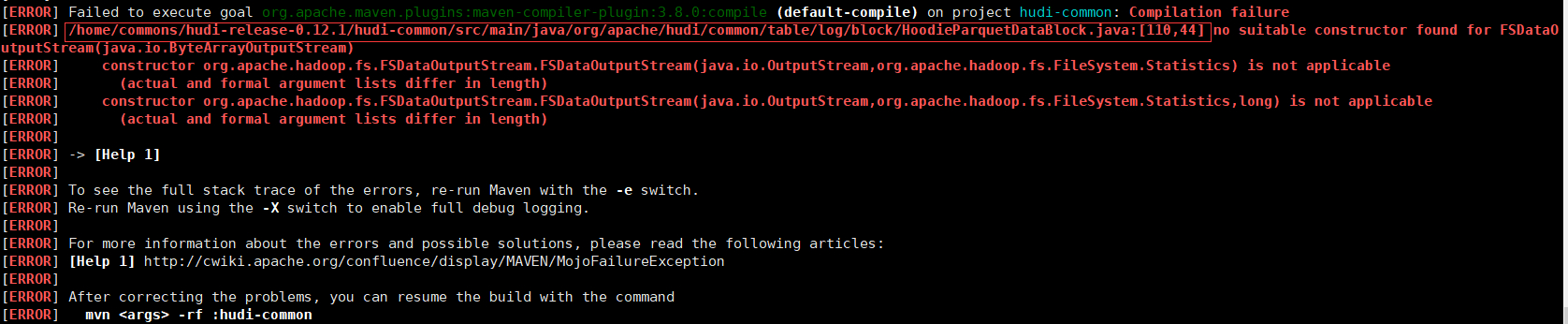
- 修改原始碼(110行位置),vim hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
try (FSDataOutputStream outputStream = new FSDataOutputStream(baos,null)) {
- 手動安裝Kafka依賴
由於kafka-schema-registry-client-5.3.4.jar、common-utils-5.3.4.jar、common-config-5.3.4.jar、kafka-avro-serializer-5.3.4.jar這四個包一直沒有安裝成功,因此我們手動下載安裝到本地maven倉庫
# 下載confluent包
wget https://packages.confluent.io/archive/5.3/confluent-5.3.4-2.12.zip
# 解壓
unzip confluent-5.3.4-2.12.zip
# 通過find命令找到儲存位置
find share/ -name kafka-schema-registry-client-5.3.4.jar
# 安裝到本地maven倉庫
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-config -Dversion=5.3.4 -Dpackaging=jar -Dfile=./share/java/confluent-common/common-config-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-utils -Dversion=5.3.4 -Dpackaging=jar -Dfile=./share/java/confluent-common/common-utils-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=5.3.4 -Dpackaging=jar -Dfile=./share/java/confluent-control-center/kafka-schema-registry-client-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-avro-serialize -Dversion=5.3.4 -Dpackaging=jar -Dfile=./share/java/confluent-control-center/kafka-avro-serializer-5.3.4.jar
-
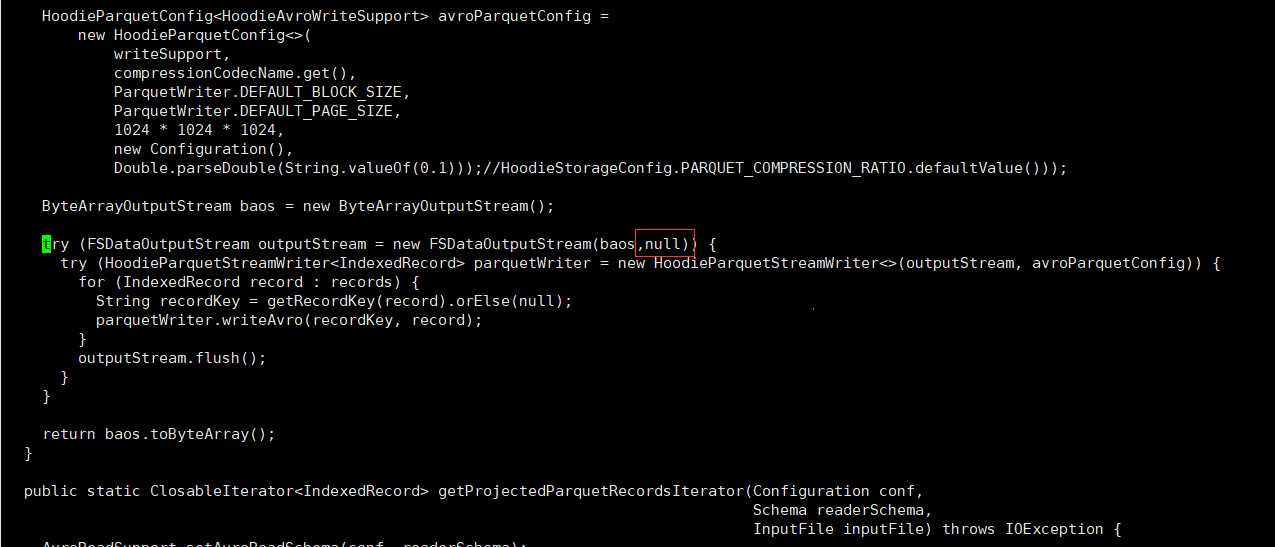
解決spark模組依賴衝突(修改了Hive版本為3.1.2,其攜帶的jetty是0.9.3,hudi本身用的0.9.4)存在依賴衝突
- 修改hudi-spark-bundle的pom檔案,排除低版本jetty,新增hudi指定版本的jetty。vim packaging/hudi-spark-bundle/pom.xml
在hive-service中376行之後增加如下內容
<exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.pentaho</groupId> <artifactId>*</artifactId> </exclusion>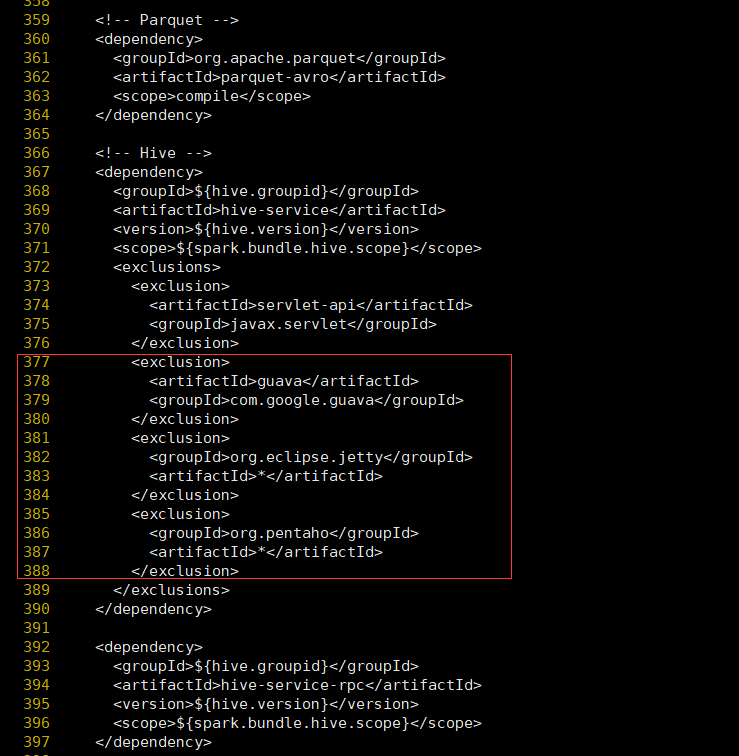
在hive-jdbc中排除下面依賴
<exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> </exclusions>在hive-metastore中排除下面依賴
<exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.datanucleus</groupId> <artifactId>datanucleus-core</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion> </exclusions>在hive-commons中排除下面依賴
<exclusions> <exclusion> <groupId>org.eclipse.jetty.orbit</groupId> <artifactId>javax.servlet</artifactId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> </exclusions>增加Hudi依賴的jetty版本
<!-- 增加hudi設定版本的jetty --> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-server</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-util</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-webapp</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-http</artifactId> <version>${jetty.version}</version> </dependency>- 修改hudi-utilities-bundle的pom檔案,排除低版本jetty,新增hudi指定版本的jetty(否則在使用DeltaStreamer工具向hudi表插入資料時,也會報Jetty的錯誤)vim ./packaging/hudi-utilities-bundle/pom.xml
在hive-service中396行之後增加如下內容
<exclusion> <artifactId>servlet-api</artifactId> <groupId>javax.servlet</groupId> </exclusion> <exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.pentaho</groupId> <artifactId>*</artifactId> </exclusion>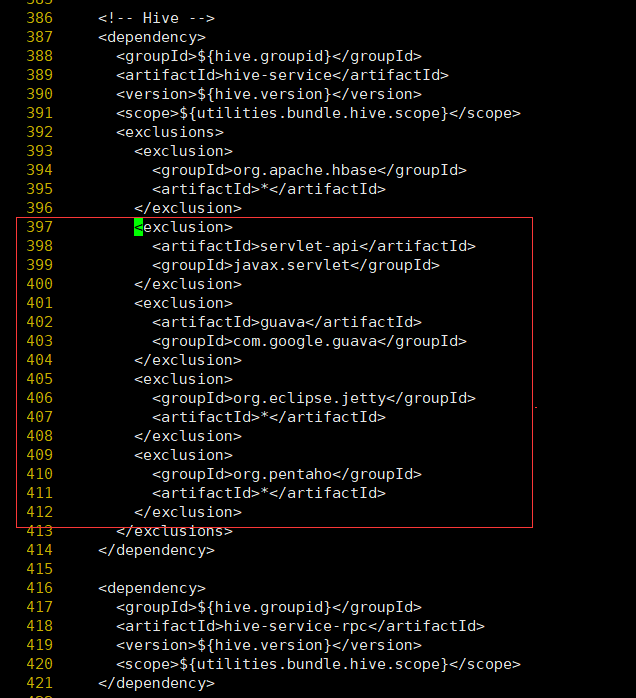
在hive-jdbc中排除下面依賴
<exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> </exclusions>在hive-metastore中排除下面依賴
<exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.datanucleus</groupId> <artifactId>datanucleus-core</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion>在hive-commons中排除下面依賴
<exclusions> <exclusion> <groupId>org.eclipse.jetty.orbit</groupId> <artifactId>javax.servlet</artifactId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> </exclusions>增加Hudi依賴的jetty版本
<!-- 增加hudi設定版本的jetty --> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-server</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-util</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-webapp</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-http</artifactId> <version>${jetty.version}</version> </dependency> -
重新執行編譯命令,等待5~10分鐘時間

- 驗證編譯:上一步編譯成功後,執行hudi-cli/hudi-cli.sh 能進入hudi-cli說明成功

- 編譯完成後,相關的包在packaging目錄的各個模組中,比如flink與hudi的包

關鍵概念
TimeLine(時間軸)
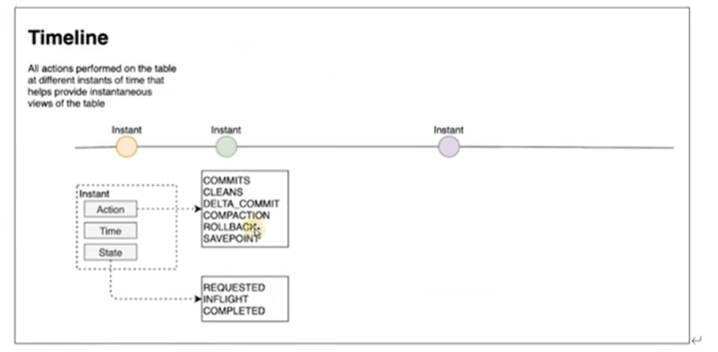
Hudi的核心是維護表上在不同時刻執行的所有操作的時間軸,這有助於提供表的瞬時檢視,同時還有效地支援按到達順序檢索資料。TimeLine是Hudi實現管理事務和其他表服務,一個Hudi瞬間由以下幾個部分組成:
- Instant action(即時動作):在表上執行的動作型別;Hudi保證在時間軸上執行的操作是原子的,並且是基於即時時間的時間軸一致的。
- COMMITS:表示將一批記錄原子地寫入表。
- CLEANS:清除表中不再需要的舊版本檔案的後臺活動。
- DELTA_COMMIT:增量提交是指將一批記錄原子地寫入MergeOnRead型別的表,其中一些/所有資料可以直接寫入增量紀錄檔。
- COMPACTION :協調Hudi中不同資料結構的後臺活動,例如:將更新從基於行的紀錄檔檔案移動到柱狀格式。在內部,壓縮表現為時間軸上的特殊提交。
- ROLLBACK:指示提交/增量提交失敗並回滾,刪除在此寫入過程中產生的所有部分檔案。
- SAVEPOINT:將某些檔案組標記為「已儲存」,以便清理器不會刪除它們。在發生災難/資料恢復場景時,它有助於將表恢復到時間軸上的某個點。
- Instant time(即時時間):即時時間通常是一個時間戳(例如:20190117010349),它按動作開始時間的順序單調增加。有兩個重要時間概念
- Arrival time:資料到達Hudi的時間。
- Event Time:資料記錄中的時間。
- State:瞬時的當前狀態。
- REQUESTED:表示一個action已經排程,但尚未執行。
- INFLIGHT:表示當前action正在執行。
- COMPLETED:表示時間軸上action已完成。
File Layouts(檔案佈局)
Apache Hudi 檔案在儲存上的總體佈局方式如下:
- Hudi將資料表組織到分散式檔案系統的基本路徑下的目錄結構中。
- 表被分成多幾個分割區,這些分割區是包含該分割區的資料檔案的資料夾,非常類似Hive表。
- 在每個分割區中,檔案被組織到檔案組中,由檔案ID唯一標識。
- 每個檔案組包含幾個檔案片(FileSlice)。
- 每個檔案片都包含在某個 commit/compaction 瞬間時間生成的一個BaseFile(MOR可能沒有),以及一組LogFile檔案(COW可能沒有),其中包含自BaseFile生成以來對BaseFile的插入/更新。Hudi將一個表對映為如下檔案結構:
- 後設資料:.hoodie目錄對應著表的後設資料資訊,包括表的版本管理(Timeline)、歸檔目錄(存放過時的instant也就是版本),一個instant記錄了一次提交的行為、時間戳和狀態;Hudi以時間軸的形式維護了在資料集上執行的所有操作的後設資料。
- 資料:和hive一樣,以分割區方式存放資料;分割區裡面存放著BaseFile(.parquet)和LogFile(.log.*)。

- Hudi採用多版本並行控制(MVCC)
- compaction 操作:合併紀錄檔和基本檔案以產生新的檔案片。
- clean 操作:清除不使用的/舊的檔案片以回收檔案系統上的空間。

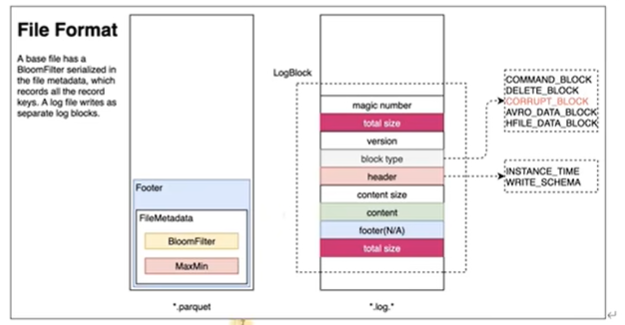
- Hudi的BaseFile在 footer 的 meta記錄了 record key 組成的 BloomFilter,用於在 file based index 實現高效率的 key contains 檢測。只有不在 BloomFilter 的 key 才需要掃描整個檔案------索引檢測key是否存在。
- Hudi 的 log 檔案通過積攢資料 buffer 以 LogBlock 為單位寫出,每個 LogBlock 包含 magic number、size、content、footer 等資訊,用於資料讀、校驗和過濾。
索引
-
原理:Hudi通過索引機制提供高效的upserts,具體是將hoodie key(record key+partition path)與檔案id(檔案組)建立唯一對映,對映的檔案組包含一組記錄的所有版本。
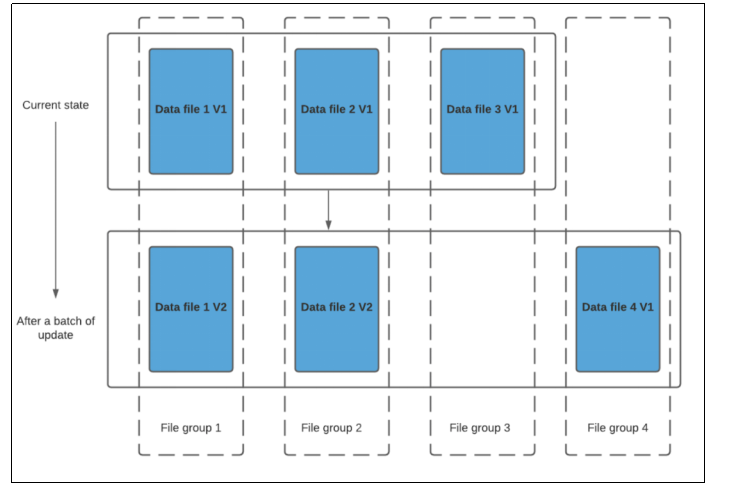
- 資料第一次寫入檔案後保持不變,一個FileGroup包含了一批record的所有版本記錄。index用於區分訊息是insert還是update;此做法的意義在於,當更新的資料到了之後可以快速定位到對應的FileGroup,避免了不必要的更新,只需要在FileGroup內做合併。
- 對於Copy-On-Write tables 可以實現快速的upsert/delete操作,避免了需要針對整個資料集進行關聯來確定要重寫哪些檔案。
- 對於 Merge-On-Read tables 這種設計允許Hudi限制需要合併的任何給定基檔案的記錄數量。具體地說,給定的基本檔案只需要針對作為該基本檔案一部分的記錄的更新進行合併。
下圖中黃色塊為更新檔案,白色塊為基本檔案

-
索引的型別
- Bloom Index(預設):使用布隆過濾器來判斷記錄存在與否,也可以選擇使用record key範圍修剪候選檔案。
- 優點:效率高,不依賴外部系統,資料和索引保持一致性。
- 缺點:因偽正率問題,還需回溯原檔案再查詢一遍。
- Simple Index:根據從儲存上的表中提取的鍵,把update/delete操作的新資料和老資料進行join。
- 優點:實現最簡單,無需額外的資源。
- 缺點:效能比較差。
- HBase Index:管理外部Apache HBase表的索引對映,把index存放在HBase裡面,在插入 File Group定位階段所有task向HBase傳送 Batch Get 請求,獲取 Record Key 的 Mapping 資訊。
- 優點:對於小批次的keys,查詢效率高。
- 缺點:需要外部的系統,增加了運維壓力。
- 自帶實現:您可以擴充套件這個公共API來實現自定義索引。
- Bloom Index(預設):使用布隆過濾器來判斷記錄存在與否,也可以選擇使用record key範圍修剪候選檔案。
-
全域性索引/非全域性索引
- 全域性索引:全域性索引在全表的所有分割區範圍下強制要求鍵的唯一性,也就是確保對給定的鍵有且只有一個對應的記錄。全域性索引提供了更強的保證,但是隨著表增大,update/delete 操作損失的效能越高,因此更適用於小表。
- 非全域性索引:預設的索引實現,只能保證資料在分割區的唯一性。非全域性索引依靠寫入器為同一個記錄的update/delete提供一致的分割區路徑,同時大幅提高了效率,更適用於大表。
- HBase索引本質上是一個全域性索引,bloom和simple index都有全域性選項:
hoodie.index.type=GLOBAL_BLOOM hoodie.index.type=GLOBAL_SIMPLE -
索引的選擇策略
- 對事實表的延遲更新:許多公司在NoSQL資料庫上儲存大量交易資料,例如共用的行程資料、股票交易資料、電商的訂單資料,這些表大部分的更新會隨機發生在較新的時間記錄上,而對舊的資料有著長尾分佈型的更新。也即是隻有小部分會在舊的分割區,這種可以使用布隆索引,如果record key是有序的,那就可以通過範圍進一步篩選;如果更加高效的使用布隆過濾器進行比對,hudi快取了輸入記錄並且使用了自定義的分割區器和統計的規律來解決了資料的傾斜,如果偽正率較高,查詢會增加資料的打亂操作,也會根據資料量來調整大小從而達到設定的假陽性率。
- 對事件表的去重:事件流資料無所不在,比如從kafka或者其他訊息件發出的資料,插入和更新只存在於最新的幾個分割區中,重複事件較多,所以在入湖之前去重是一個常見的需求;雖然可以使用hbase索引進行去重,但索引儲存的消耗還是會隨著事件的增長而線性增長,所以有範圍裁剪的布隆索引才是最佳的解決方案,可以使用事件時間戳+事件id組成的鍵作為去重條件。
- 對維度表的隨機更新:使用布隆裁剪就不合適,直接使用普通簡單索引就合適,直接將所有的檔案的所需欄位連線;也可以採用HBase索引,其對這些表能提供更加優越的查詢效率;當遇到分割區內資料需要更新時,較為適合採用Merge-On-Read表。
表型別
Hudi表型別定義瞭如何在DFS上對資料進行索引和佈局,以及如何在這種組織之上實現上述原語和時間軸活動(即如何寫入資料)。反過來,查詢型別定義瞭如何向查詢公開底層資料(即如何讀取資料)。Hudi表型別分為COPY_ON_WRITE(寫時複製)和MERGE_ON_READ(讀時合併)。
-
Copy On Write
- 使用專門的列式格式儲存資料(例如parquet),通過在寫過程中執行同步合併,簡單地更新檔案的版本和重寫。
- 只有資料檔案/基本檔案(.parquet),沒有增量紀錄檔檔案(.log.*)。
- 對於每一個新批次的寫入都將建立相應資料檔案的版本(新的FileSlice),也就是第一次寫入檔案為fileslice1,第二次更新追加操作就是fileslice2。
- data_file1 和 data_file2 都將建立更新的版本,data_file1 V2 是data_file1 V1 的內容與data_file1 中傳入批次匹配記錄的記錄合併。
- cow是在寫入期間進行合併,因此會產生一些延時,但是它最大的特點在於簡單性,不需要其他表的服務,也相對容易偵錯。
當資料寫入寫入即寫複製表並在其上執行兩個查詢時

- Merge On Read
- 使用列式儲存(如parquet) +基於行(如avro)的檔案格式組合儲存資料,更新被記錄到增量檔案,然後壓縮以同步或非同步生成新版本的列式檔案。
- 可能包含列存的基本檔案(.parquet)和行存的增量紀錄檔檔案(基於行的avro格式,.log檔案)。
- 所以對於初始的檔案也是追加的avro檔案,後續修改追加的檔案是avro檔案,而且只有在讀的時候或者compaction才會合併成列檔案。
- compaction可以選擇內聯或者非同步方式,比如可以將壓縮的最大增量紀錄檔設定為 4。這意味著在進行 4 次增量寫入後,將對資料檔案進行壓縮並建立更新版本的資料檔案。
- 不同索引寫檔案會有差異,布隆索引插入還是寫入parquet檔案,只有更新才會寫入avro檔案,因為當parquet檔案記錄了要更新訊息的FileGroupID;而對於Flink索引可以直接寫入avro檔案。
在讀表上合併的目的是支援直接在DFS上進行接近實時的處理,而不是將資料複製到可能無法處理資料量的專門系統。這個表還有一些次要的好處,比如通過避免資料的同步合併減少了寫量的增加,即在批次處理中每1個位元組的資料寫入的資料量。下面為兩種型別的查詢—快照查詢和讀取優化查詢的圖說明

- COW適合批次處理,MOR適合批流一體但更適合流式計算,COW與MOR的對比如下
| CopyOnWrite | MergeOnRead | |
|---|---|---|
| 資料延遲 | 高 | 低 |
| 查詢延遲 | 低 | 高 |
| 更新 (I/O)成本 | 高(重寫整個 parquet檔案) | 低 (追加到增量紀錄檔) |
| Parquet 檔案大小 | 小 | 較大 |
| 寫擴大 | 高 | 低(依賴合併或壓縮策略) |
查詢型別
-
查詢型別:支援快照查詢、增量查詢、讀優化查詢三種查詢型別。
-
快照查詢:提供對實時資料的快照查詢,使用基於列和基於行的儲存的組合(例如Parquet + Avro)。針對全量最新資料COW表直接查最新的parquet檔案,而MOR表需要做一個合併(最新全量資料)。
-
增量查詢:提供一個更改流,其中包含在某個時間點之後插入或更新的記錄。可以查詢給定commit/delta commit即時操作以來新寫入的資料。有效的提供變更流來啟用增量資料管道(最新增量資料)。
-
讀優化查詢:通過純列儲存(例如Parquet)提供出色的快照查詢效能。可檢視給定的commit/compact即時操作的表的最新快照。僅將最新檔案片的基本/列檔案暴露給查詢,並保證與非Hudi表相同的列查詢效能(並不是全量最新),只是合併時檔案。
-
不同表支援查詢型別
| Table Type | Supported Query types |
|---|---|
| Copy On Write | Snapshot Queries + Incremental Queries |
| Merge On Read | Snapshot Queries + Incremental Queries + Read Optimized Queries |
不同查詢型別之間的權衡
| 快照 | 讀優化 | |
|---|---|---|
| 資料延遲 | 低 | 高 |
| 查詢延遲 | 高 (合併基本檔案/列式檔案 + 基於行的 delta 紀錄檔檔案) | 低(行原始 / 列式檔案效能) |
**本人部落格網站 **IT小神 www.itxiaoshen.com