還在為資料庫事務一致性檢測而苦惱?讓Elle幫幫你,以TDSQL為例我們測測 | DB·洞見#7
資料庫使用者通常依賴隔離級別來確保資料一致性,但很多資料庫卻並未達到其所表明的級別。主要原因是:一方面,資料庫開發者對各個級別的理解有細微差異;另一方面,實現層面沒有達到理論上的要求。
使用者在使用或開發者在交付資料庫前,需要對隔離級別進行快速的正確性驗證,並且希望驗證是可靠的(沒有誤差)、快速的(多項式時間)、有效的(找出異常)、通用的(任意資料庫)、可解釋的(可以debug,可以復現)。
Elle 就是針對以上問題提出的一個基於 Adya 模型的黑盒一致性檢測工具。Elle 通過精心設計的讀寫操作和版本控制,可以檢驗出 Adya 提出的所有非謂詞異常,並且具有一定可解釋性和復現性。在實踐中,Elle 在所測的四個資料庫上都測出了資料不一致。
探索前沿研究,聚焦技術創新。本期由騰訊雲資料庫高階工程師陳育興為大家介紹資料庫事務一致性檢測的技術原理及相關實現,包括背景、動機、解決方案等內容。
一、背景介紹
1.1 資料異常
我們熟知的資料異常有髒讀、髒寫、丟失更新等很多種類,如果從資料異常的角度來解釋一致性,即一致性是保證不出現資料異常。

我們以一個經典案例資料異常(寫偏序(Write Skew))對此進行說明。某使用者有兩個投資賬戶,允許其中一個賬戶暫時虧損,但兩個賬戶總額不能為虧損。轉賬前兩個賬戶各有$100,兩個事務同時開啟,A事務查詢總餘額發現有$200,並在第一個賬戶取出$200,B事務查詢總餘額也是$200,並且在第二個賬戶取$200,兩個事務都提交成功。各取出$200、總共取出$400,但按正常理解,超額取錢是不允許的,這種情況就是資料異常。然而這種操作在絕大部分資料庫的預設設定中都會出現。
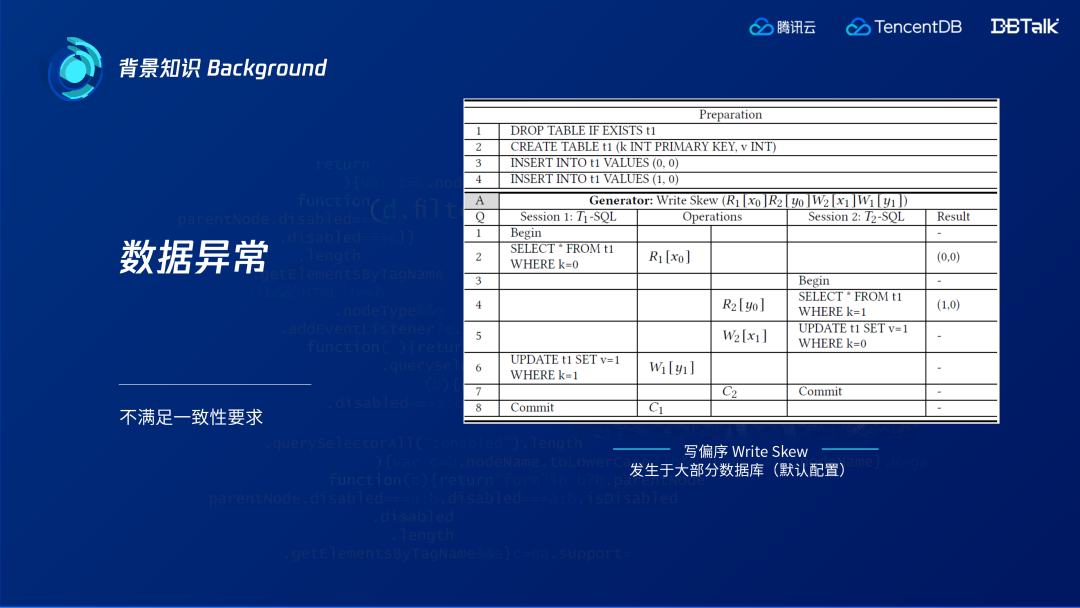
該例子的寫偏序的標準測試樣例如上圖所示:初始資料庫有兩行資料,兩個事務都各自讀一行資料,兩個事務分別更新對方讀的資料,最後兩個事務都提交成功,這就是標準的寫偏序。這在很多資料庫的預設級別和快照級別都會出現,使用者通常需要額外的約束或需要資料庫開啟可序列級別才能避免該異常。
1.2 隔離級別 VS 資料異常
一致性有強弱之分,資料庫中滿足強/弱一致性需要通過隔離級別來實現。在某些弱級別下,異常的出現被視為正常,因為有些異常在部分業務場景下是可以被接受的。那我們為何要允許資料異常的出現,而不是禁止所有異常出現從而保證正確性?因為正確性和效能之間需要權衡,正確性越高,效能越差,允許一些資料異常,效能也會有所提升。

標準定義下存在四種異常,從P0到P3,逐步禁止,比如P0是髒寫,在所有級別中都不允許出現;P1是髒讀,在讀未提交允許出現,幻讀則允許在RR級別下出現;可序列級別理論上不允許任何異常出現。隔離級別越強,允許的異常就越少,且通常隔離級別為逐級疊加,即弱隔離級別不允許出現的異常,在更強的隔離級別也不允許出現。
四種標準的異常只是資料異常中的一小部分,還有更多資料異常的形式。在四種標準的級別之上也有更多的隔離級別。

上表顯示的是新的異常和新的隔離級別之間的允許/不允許關係,但並非時時刻刻都如此嚴格。一方面,各廠商的資料庫產品會因理解和實現的不同致使部分異常沒有按預期出現或禁止。另一方面,上述異常僅僅是一小部分,理論上存在的級別也還有很多。因此很多資料庫新使用者不知道哪些異常會出現或不應該出現,以及如何去理解這些級別和異常。
二、動機
2.1 非傳統隔離級別
下圖所示是部分非傳統的隔離級別。比較常見的是快照隔離級別,如圖所示的部份廠商,從名字上我們無法直接判斷這些級別的具體表現,相關檔案的描述也比較模糊,因此就會引申出一個問題,即它們應該等價於哪些級別、對比當前級別它們是強或弱。

2.2 使用者層面
從使用者角度來看,主要存在以下三方面問題:
- 如何針對自身業務選擇隔離級別,如何理解這些(新)隔離級別。比如哪些異常允許出現,哪些異常不允許出現?
- 資料庫申明的隔離級別沒有達到標準。比如Oracle申明支援可序列級別,但它只消除了四種標準的異常,沒有消除所有異常,存在寫偏序。在序列級別存在寫偏序異常,這種申明現象在很多資料庫中都會出現。
- 對隔離級別的定義標準不同,不單是可序列級別,其他弱隔離級別也是如此。比如在可重複讀級別,PostgreSQL不存在幻讀但存在寫偏序,SQL Server則不存在寫偏序異常但存在幻讀。

2.3 廠商層面
從廠商角度來看,主要存在以下兩方面問題:
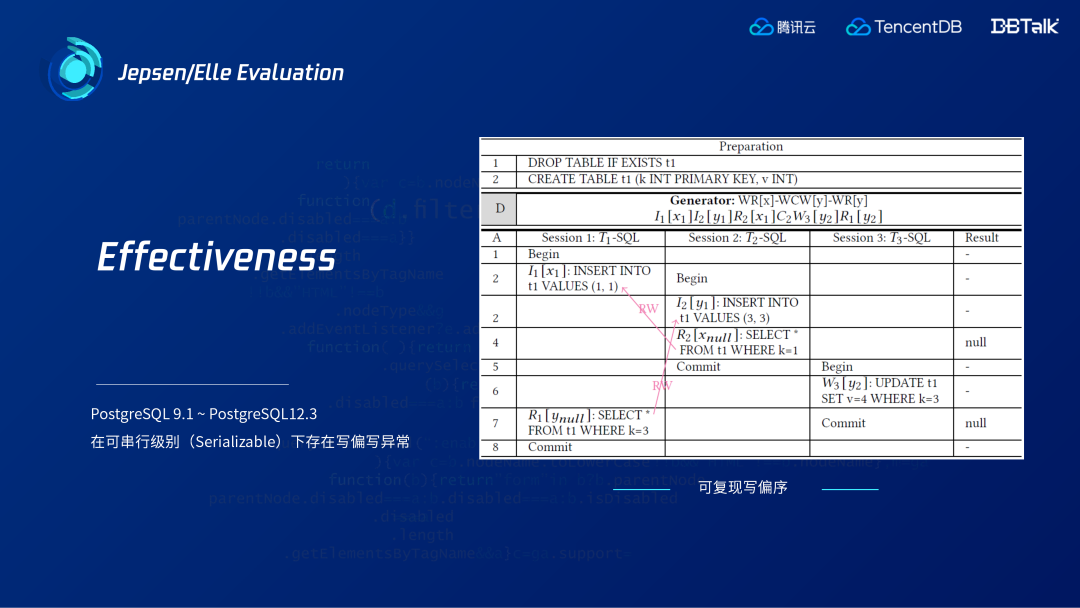
一方面,資料庫需要迭代版本,但迴歸測試樣例一般都不完整,只能在一定程度上進行驗證。比如PostgreSQL在2011年推出的9.1版本中已經實現可序列化的快照隔離(SSI),但因為某些步驟優化導致在第三方事務插入後馬上更新干擾的情況下,出現G2異常(寫偏序),正常情況下不應出現,直到2019年推出12.4版本才對此進行修復。
另一方面,廠商需要研發新型事務資料庫,需要驗證開發的正確性,確保沒有缺陷或者沒有程式上的bugs影響。

三、解決方案
3.1 Jepsen/Elle事務一致性測試框架
對上述問題,我們可以利用一個事務一致性檢測方案——Jepsen/Elle方案進行解決。Jepsen是一個更強大的框架,可以檢測分散式一致性、線性一致性等多種一致性級別,Elle是其中的一個事務驗證模組,Elle方案目前已經在VLDB 2020會議中發表。

整體來看,Jepsen/Elle事務一致性測試框架的作用如下:
- 測試出各種級別下存在的異常,幫助理解當前級別的表現;
- 通過理解當前級別,可以驗證當前隔離級別是否達到要求;
- 測試結果可解釋、可溯源、可復現。
3.2 定義資料異常
在解決上述問題之前,我們需要知道如何定義資料異常,以及學術界又如何看待資料庫異常。

前文提到最簡單的一致性是不存在任何資料異常,但如何判斷髮生了資料異常呢?比如正常要讀提交的值但卻讀到未提交的寫,一個事務兩次讀但卻讀到不一樣的值,這些能否歸為資料異常?其實,這些異常在一定程度上都算是資料異常,只是表述不夠正式且無法總結規律,因此我們需要用更規範的方式來定義資料異常。

在判斷有無資料異常前,我們需要把資料庫執行後的資料抽象地表示出來。Elle方案裡採用Adya表示模型,這是一個比較標準通用的表示模型,可以將資料庫操作物件以及操作方式抽象出來。比如物件通常有x、y、z, 可以對應不同key,再用R、W、C、A對應讀、寫、提交和回滾。在資料庫執行完操作後,我們把一組事務操作記錄下來成為歷史(history),排程(schedule)是歷史的字首(prefix)。兩者的區別在於,排程裡仍有未完成的事務,但歷史裡全是已完成的事務。
現階段寫偏序的執行可以描述成一個排程,其中讀寫操作的下角標表示事務,物件的下角標表示版本數。以下圖為例,寫偏序的排程為:事務1進行了讀操作,讀取了物件為x的0版本資料,事務2讀了物件為y的0版本資料,事務1改了y物件的值,事務2修改了x物件的值。

有了排程和歷史的概念後,我們可以去構建衝突圖。衝突圖是以事務為點、衝突為邊的圖模型。比如上圖右邊的寫偏序例子,事務1的讀和事務2的寫作用在同一個物件x上,從版本來看事務1的版本更小、事務2的版本更大,因此存在從事務1到事務2的RW衝突邊。同理在y物件上,存在由事務2到事務1的RW邊。我們可以看到,該圖是一個環結果,我們可以通過環的存在來判斷資料異常的存在。因為我們認為序列執行的結果是一個沒有問題的資料狀態,比如事務1先做,再做事務2,就不會有資料異常,而衝突圖有環的情況,其實就是不可序列的執行結果,它的結果不等價於任何一個序列執行的結果。因此,我們認為執行的狀態或結果為不可序列的就存在異常。

如果我們把資料庫執行轉成歷史,通過歷史去建模衝突圖,再去判斷衝突圖是否有環,就可以輕易判斷是否存在資料異常。因為歷史或排程模型裡可以確定讀寫版本,從而確定衝突依賴關係,容易做判斷。
3.3 問題與挑戰
在現實中,資料庫執行結果有時很難獲取統計,即使可以獲取統計,也很難直接轉化為確定的歷史或者排程。這主要有兩方面的問題:一方面,依賴關係有時可能性很多,很難決定;另一方面,如果並行事務較多,不確定的依賴關係就會更多,需要分析和決定的成本很高,導致驗證速度慢或可能性太多,記憶體和計算資源不足以在短時間內驗證太多可能性。

資料讀寫之間的依賴判斷存在以下難點:
- 兩個事務都對K=1更新值,從兩個事務的歷史資料無法得知誰先誰後;
- 兩個事務都對K=1更新V=5,其他事務讀到K=1、V=5時,無法得知是哪個事務的寫的資料;
- 事務讀寫後是否參與衝突依賴判斷,需要兩個事務在時間上有交叉。但很多分散式時間不可信、不對齊,時間不一定對等;
如果考慮將所有可序列的結果去匹配執行結果,本質上是NP-complete問題,是一個非多項式時間的驗證,計算成本非常高。
3.4 Jepsen/Elle解決方案

Jepsen/Elle解決方案首先要保證得到可靠的歷史,需要執行結果滿足兩個特性:
- 可追溯性,需要知道版本之間的順序,決定ww依賴,誰先寫、誰後寫需要確認。
- 可復原性,需要知道讀的是哪個版本、誰的寫,從而決定寫讀依賴;讀寫依賴可以根據寫寫依賴和寫讀依賴進行推導。

Jepsen/Elle的輸入設定分為三種操作:
- 讀操作,select語句。
- 插入操作,insert語句。
- 更新操作,update語句。該update語句與普通update不同,需要在更新值時附帶原有值,把原有值和更新值都保留。

具體範例如下:首先往t1表裡插入新值K=1,V=1。R1讀表裡的內容,讀到k=1、 v=1。W1更新行的內容,讓值更新為2。因為更新時我們會將原有值加進來,所以當R2再次讀時,我們讀到的是k=1,v=「1 2」。以此類推,當再次更新值為3時,我們讀到的是「1 2 3」。同一個變數上的更新使其保持唯一則不會有歧義,我們也知道更新版本順序,再通過讀資料,可以輕易推匯出這些操作的讀寫依賴關係。

上圖是論文中給出的例子。R1中間的事務,讀了K=255的值2,3,4,5;R2上面的事務,讀了K=255的值為2,3,4,5, 8;W3下面的事務在K=255上寫了值為8,我們可以得到從W3到R2的WR依賴和R1到W3的RW依賴,從最上面的事務到中間的時間依賴(real-time 依賴),可以用作嚴格一致性的判斷。

Elle檢測模型基本遵循Adya文章定義的環分類,比如G0異常為全是WW邊的環,G1c為WW或WR組合的環,加上G-single和G2,這些異常環的組合類似於四種異常現象,所以也有逐步不允許的限制。我們驗證隔離級別是否達標,就從最簡單的四種異常驗證轉化為四大類環的檢測。

Elle檢測可以保證正確性,只要測出異常,則該異常一定存在。只要出現異常,理論上可以復現,也說明資料庫在該模型下不一致。另一方面,Elle不能保證完整性,Elle檢測後不代表系統完全滿足一致性,因為有些異常不能用環表示,比如髒讀、髒寫、中間讀以及有些需要狀態確認的異常,Elle也不能檢測謂詞異常。

Elle通過初期寫的特殊處理,所有的依賴關係都是確定性的,通過事務執行結果來判斷依賴關係的複雜度,基本上都是線性。我們可以看到,隨著並行增大,粉色線的時間基本是平穩線性增長,而傳統做法需要比對任意事務之間的順序,複雜度是階乘於事務個數,隨著並行增大,驗證時間為指數增長。

上圖是用Elle工具在PostgreSQL老版本上測出的異常,在可序列級別下存在寫偏序異常。右邊的可復現的例子中, 共有三個事務,兩個事務新插入資料,且相互沒有讀到新插入的資料,從而形成一個寫偏序的環。出現該異常的原因是,第三個事務對某個插入進行更新導致後面的讀依賴沒有作用在插入值上。
3.5 Test on TDSQL

我們在TDSQL上進行測試。結果顯示,可序列級別不存在任何異常,RR級別的表現屬於快照隔離級別水平。
四、總結
綜上所述,Elle事務一致性檢測框架主要解決兩個問題:
- 通過寫版本疊加,在更新時保留舊值,從而確定版本順序以及把執行結果變為歷史排程。
- 通過沖突圖的環檢測,從歷史排程判斷有無資料異常。此外,Elle也可通過疊加時間要求來檢測嚴格一致性,比如T2是T1 commit之後才開始的,那麼序列執行時必須為T1->T2,不允許出現T2->T1。
上述情況只涉及部分級別,我們還可以根據實際情況細分出更多的級別和一致性模型,用Elle進行更多的驗證。

最後,我們還可以從以下四方面對Jepsen/Elle事務一致性測試框架進行優化:
- 框架本身並不簡單,需要很多引數調節才能達到效果。比如有些情況壓測不充分,小概率異常難於發現,有時不易復現。
- 不支援Delete,不支援謂詞範圍查詢。無法檢驗幻讀(Phantom),無法判別Repeatable Read和Serializable之間的區別。
- 採用新資料格式,而非傳統迴歸測試的SQL語句,分析和debug都比較困難。
- Jepsen有額外錯誤注入功能,但作者在Elle文章中並沒有細說。比如很多異常是因為某些節點重啟斷聯導致的,正常情況下允許並無異常。
參考文獻
[1] Atul Adya, Barbara Liskov, Patrick E. O'Neil: Generalized Isolation Level Definitions. ICDE 2000: 67-78
[2] Peter Alvaro, Kyle Kingsbury: Elle: Inferring Isolation Anomalies from Experimental Observations. Proc. VLDB Endow. 14(3): 268-280 (2020)