ElasticSearch 常見問題
2022-11-14 21:01:00
ElasticSearch 常見問題
丈夫有淚不輕彈,只因未到傷心處。
1、說說 es 的一些調優手段。
僅索引層面調優手段:
1.1、設計階段調優
(1)根據業務增量需求,採取基於日期模板建立索引,通過 roll over API 捲動索引;
(2)使用別名進行索引管理;
(3)每天凌晨定時對索引做 force_merge 操作,以釋放空間;
(4)採取冷熱分離機制,熱資料儲存到 SSD,提高檢索效率;冷資料定期進行 shrink操作,以縮減儲存;
(5)採取 curator 進行索引的生命週期管理;
(6)僅針對需要分詞的欄位,合理的設定分詞器;
(7)Mapping 階段充分結合各個欄位的屬性,是否需要檢索、是否需要儲存等。
1.2、寫入調優
(1)寫入前副本數設定為 0;
(2)寫入前關閉 refresh_interval 設定為-1,禁用重新整理機制;
(3)寫入過程中:採取 bulk 批次寫入;
(4)寫入後恢復副本數和重新整理間隔;
(5)儘量使用自動生成的 id。
1.3、查詢調優
(1)禁用 wildcard;
(2)禁用批次 terms(成百上千的場景);
(3)充分利用倒排索引機制,能 keyword 型別儘量 keyword;
(4)資料量大時候,可以先基於時間敲定索引再檢索;
(5)設定合理的路由機制。
1.4、其他調優
部署調優,業務調優等。
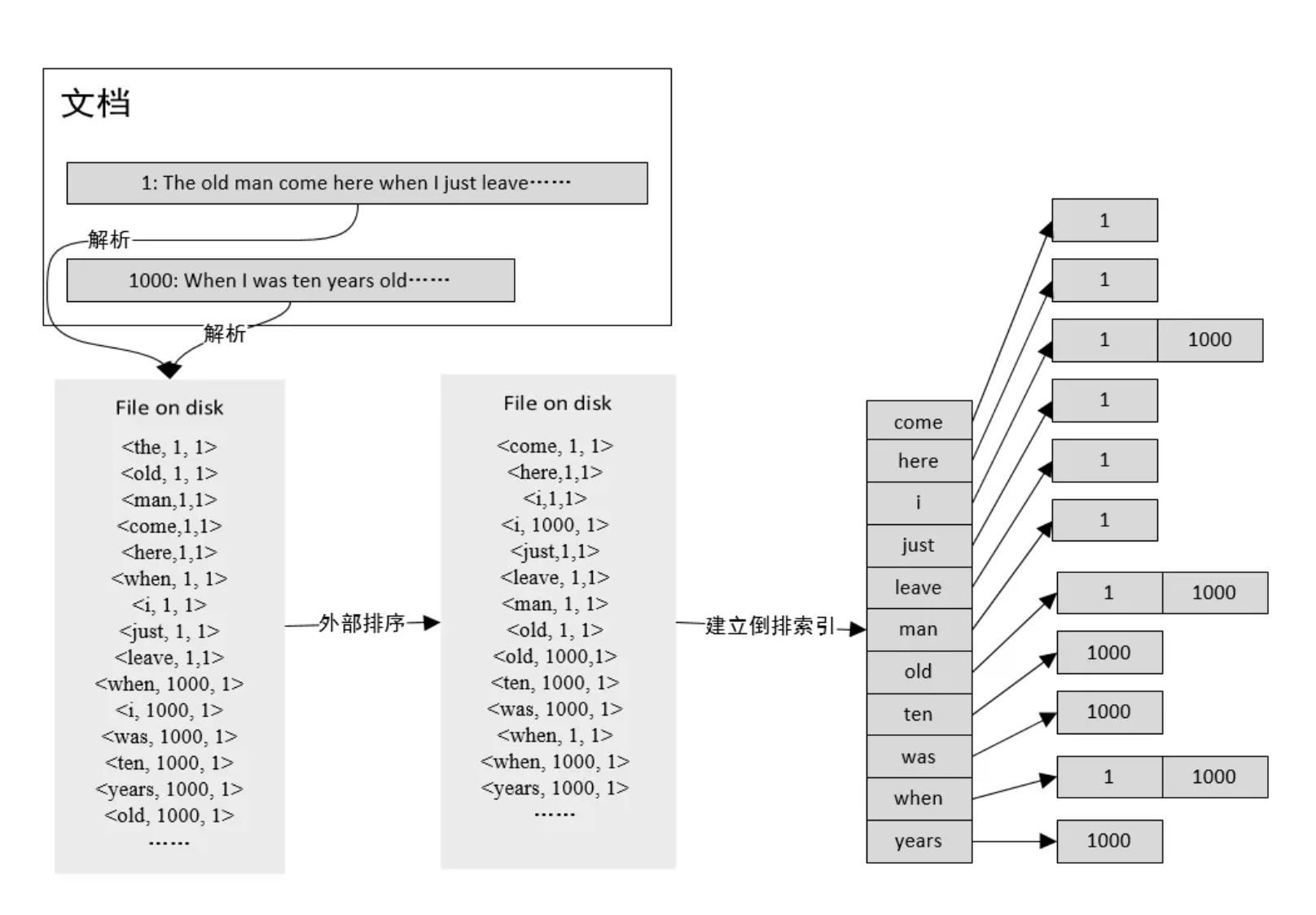
2、什麼是 ES 倒排索引?
通俗解釋:
傳統的我們的檢索是通過文章,逐個遍歷找到對應關鍵詞的位置。
而倒排索引,是通過分詞策略,形成了詞和文章的對映關係表,這種詞典+對映表即為倒排索引。有了倒排索引,就能實現 O(1)時間複雜度的效率檢索文章了,極大的提高了檢索效率。
學術解釋:
倒排索引,相反於一篇文章包含了哪些詞,它從詞出發,記載了這個詞在哪些檔案中出現過,由兩部分組成——詞典和倒排表。
倒排索引的底層實現是基於:FST(Finite State Transducer)資料結構。lucene 從 4+版本後開始大量使用的資料結構是 FST。FST 有兩個優點:
(1)空間佔用小。通過對詞典中單詞字首和字尾的重複利用,壓縮了儲存空間;
(2)查詢速度快。O(len(str))的查詢時間複雜度。 
3、ES 索引資料多了怎麼辦?如何調優、部署?
索引資料的規劃,應在前期做好規劃,正所謂「設計先行,編碼在後」,這樣才能有效的避免突如其來的資料激增導致叢集處理能力不足引發的線上客戶檢索或者其他業務受到影響。
如何調優,正如問題 1 所說。
3.1 動態索引層面
基於模板+時間+rollover api 捲動建立索引。
舉例:設計階段定義:blog 索引的模板格式為:blog_index_時間戳的形式,每天遞增資料。這樣做的好處:不至於資料量激增導致單個索引資料量非常大,接近於上線 2 的32 次冪-1,索引儲存達到了 TB+甚至更大。
一旦單個索引很大,儲存等各種風險也隨之而來,所以要提前考慮+及早避免。
3.2 儲存層面
冷熱資料分離儲存,熱資料(比如最近 3 天或者一週的資料),其餘為冷資料。
對於冷資料不會再寫入新資料,可以考慮定期 force_merge 加 shrink 壓縮操作,節省儲存空間和檢索效率。
3.3 部署層面
一旦之前沒有規劃,這裡就屬於應急策略。
結合 ES 自身的支援動態擴充套件的特點,動態新增機器的方式可以緩解叢集壓力,注意:如果之前主節點等規劃合理,不需要重啟叢集也能完成動態新增的。
4、elasticsearch 是如何實現 master 選舉的?
前置前提:
(1)只有候選主節點(master:true)的節點才能成為主節點。
(2)最小主節點數(min_master_nodes)的目的是防止腦裂。
核對了一下程式碼,核心入口為 findMaster,選擇主節點成功返回對應 Master,否則返回 null。選舉流程大致描述如下:
第一步:確認候選主節點數達標,elasticsearch.yml 設定的值 discovery.zen.minimum_master_nodes;
第二步:比較,先判定是否具備 master 資格,具備候選主節點資格的優先返回;若兩節點都為候選主節點,則 id 小的值會主節點。注意這裡的 id 為 string 型別。
1 GET /_cat/nodes?v&h=ip,port,heapPercent,heapMax,id,name
2 ip port heapPercent heapMax id name
5、描述一下 Elasticsearch 索引檔案的過程
這裡的索引檔案應該理解為檔案寫入 ES,建立索引的過程。
檔案寫入包含:單檔案寫入和批次 bulk 寫入,這裡只解釋一下:單檔案寫入流程。
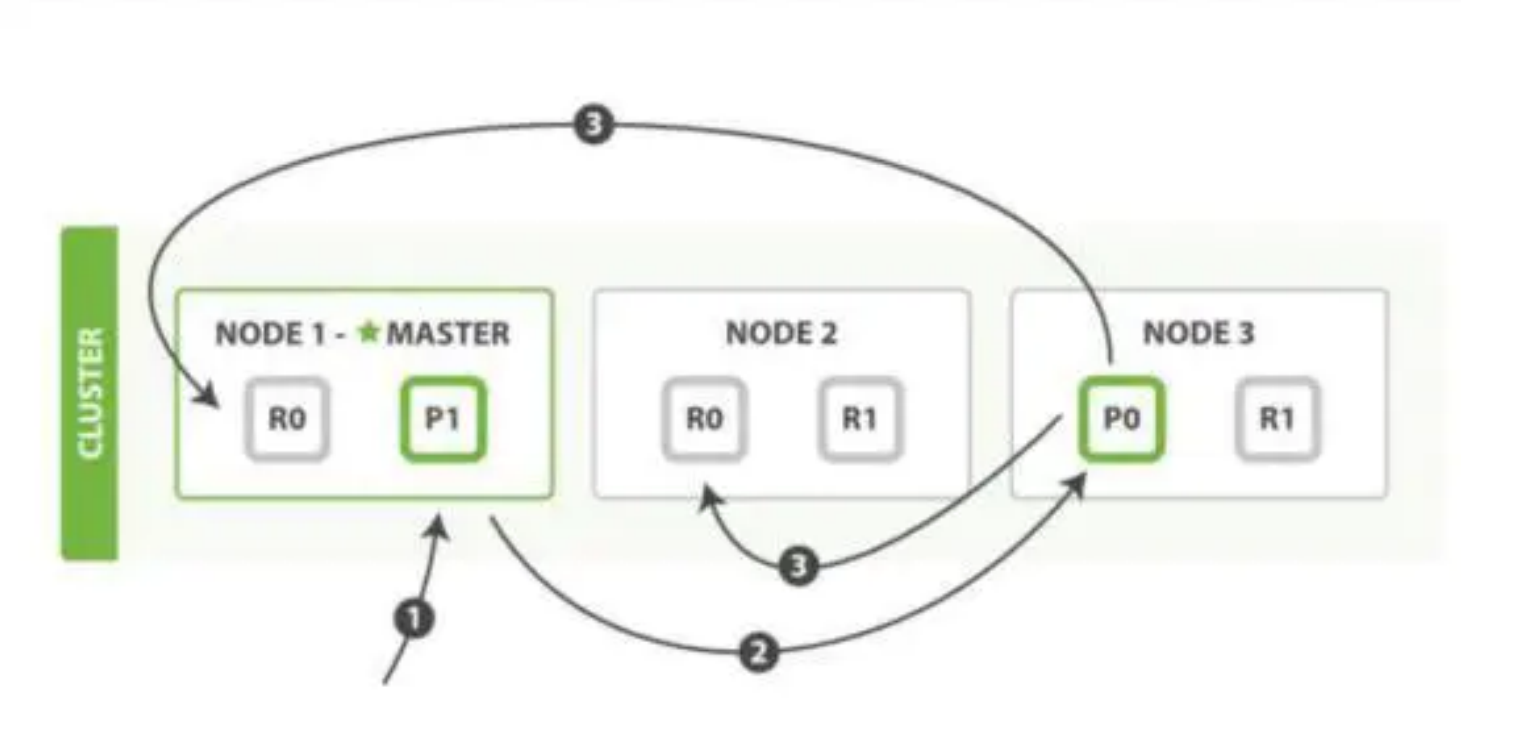
第一步:客戶向叢集某節點寫入資料,傳送請求。(如果沒有指定路由/協調節點,請求的節點扮演路由節點的角色。)
第二步:節點 1 接受到請求後,使用檔案_id 來確定檔案屬於分片 0。請求會被轉到另外的節點,假定節點 3。因此分片 0 的主分片分配到節點 3 上。
第三步:節點 3 在主分片上執行寫操作,如果成功,則將請求並行轉發到節點 1和節點 2 的副本分片上,等待結果返回。所有的副本分片都報告成功,節點 3 將向協調節點(節點 1)報告成功,節點 1 向請求使用者端報告寫入成功。
如果面試官再問:第二步中的檔案獲取分片的過程?
回答:藉助路由演演算法獲取,路由演演算法就是根據路由和檔案 id 計算目標的分片 id 的過程。
6、描述一下 Elasticsearch 搜尋的過程?
搜尋拆解為「query then fetch」 兩個階段。
query 階段的目的:定位到位置,但不取資料。步驟拆解如下:
(1)假設一個索引資料有 5 主+1 副本 共 10 分片,一次請求會命中(主或者副本分片中)的一個。
(2)每個分片在本地進行查詢,結果返回到本地有序的優先佇列中。
(3)第 2)步驟的結果傳送到協調節點,協調節點產生一個全域性的排序列表。
fetch 階段的目的:取資料。路由節點獲取所有檔案,返回給使用者端。
7、ES 在部署時,對 Linux 的設定有哪些優化方法?
(1)關閉快取 swap;
(2)堆記憶體設定為:Min(節點記憶體/2, 32GB);
(3)設定最大檔案控制程式碼數;
(4)執行緒池+佇列大小根據業務需要做調整;
(5)磁碟儲存 raid 方式——儲存有條件使用 RAID10,增加單節點效能以及避免單節點儲存故障。
8、lucence 內部結構是什麼?
Lucene 是有索引和搜尋的兩個過程。
- 索引建立:將現實世界中所有的結構化和非結構化資料提取資訊,建立索引的過程。
- 搜尋索引:就是得到使用者的查詢請求,搜尋建立的索引,然後返回結果的過程。
9、ES 是如何實現 Master 選舉的?
(1)Elasticsearch 的選主是 ZenDiscovery 模組負責的,主要包含 Ping(節點之間通過這個 RPC 來發現彼此)和 Unicast(單播模組包含一個主機列表以控制哪些節點需要 ping 通)這兩部分;
(2)對所有可以成為 master 的節點(node.master: true)根據 nodeId 字典排序,每次選舉每個節點都把自己所知道節點排一次序,然後選出第一個(第 0 位)節點,暫且認為它是 master 節點。
(3)如果對某個節點的投票數達到一定的值(可以成為 master 節點數 n/2+1)並且該節點自己也選舉自己,那這個節點就是 master。否則重新選舉一直到滿足上述件。
(4)補充:master 節點的職責主要包括叢集、節點和索引的管理,不負責檔案級別的管理;data 節點可以關閉 http 功能*。
10、描述一下 Elasticsearch 索引檔案的過程。
協調節點預設使用檔案 ID 參與計算(也支援通過 routing),以便為路由提供合適的分片。
shard = hash(document_id) % (num_of_primary_shards)
(1)當分片所在的節點接收到來自協調節點的請求後,會將請求寫入到 MemoryBuffffer,然後定時(預設是每隔 1 秒)寫入到 Filesystem Cache,這個從 MomeryBuffffer 到 Filesystem Cache 的過程就叫做 refresh;
(2)當然在某些情況下,存在 Momery Buffffer 和 Filesystem Cache 的資料可能會丟失,ES 是通過translog 的機制來保證資料的可靠性的。其實現機制是接收到請求後,同時也會寫入到 translog 中 ,當 Filesystem cache 中的資料寫入到磁碟中時,才會清除掉,這個過程叫做 flush;
(3)在 flush 過程中,記憶體中的緩衝將被清除,內容被寫入一個新段,段的 fsync將建立一個新的提交點,並將內容重新整理到磁碟,舊的 translog 將被刪除並開始一個新的 translog。
(4)flush 觸發的時機是定時觸發(預設 30 分鐘)或者 translog 變得太大(預設為 512M)時;
補充:關於 Lucene 的 Segement:
(1)Lucene 索引是由多個段組成,段本身是一個功能齊全的倒排索引。
(2)段是不可變的,允許 Lucene 將新的檔案增量地新增到索引中,而不用從頭重建索引。
(3)對於每一個搜尋請求而言,索引中的所有段都會被搜尋,並且每個段會消耗CPU 的時鐘周、檔案控制程式碼和記憶體。這意味著段的數量越多,搜尋效能會越低。
(4)為了解決這個問題,Elasticsearch 會合並小段到一個較大的段,提交新的合併段到磁碟,並刪除那些舊的小段。
12、描述一下 Elasticsearch 更新和刪除檔案的過程。
(1)刪除和更新也都是寫操作,但是 Elasticsearch 中的檔案是不可變的,因此不能被刪除或者改動以展示其變更;
(2)磁碟上的每個段都有一個相應的.del 檔案。當刪除請求傳送後,檔案並沒有真的被刪除,而是在.del 檔案中被標記為刪除。該檔案依然能匹配查詢,但是會在結果中被過濾掉。當段合併時,在.del檔案中被標記為刪除的檔案將不會被寫入新段。
(3)在新的檔案被建立時,Elasticsearch 會為該檔案指定一個版本號,當執行更新時,舊版本的檔案在.del 檔案中被標記為刪除,新版本的檔案被索引到一個新段。舊版本的檔案依然能匹配查詢,但是會在結果中被過濾掉。
13、描述一下 ES 搜尋的過程。
(1)搜尋被執行成一個兩階段過程,我們稱之為 Query Then Fetch;
(2)在初始查詢階段時,查詢會廣播到索引中每一個分片拷貝(主分片或者副本分片)。 每個分片在本地執行搜尋並構建一個匹配檔案的大小為 from + size 的優先佇列。
PS:在搜尋的時候是會查詢 Filesystem Cache 的,但是有部分資料還在 MemoryBuffffer,所以搜尋是近實時的。
(3)每個分片返回各自優先佇列中 所有檔案的 ID 和排序值 給協調節點,它合併這些值到自己的優先佇列中來產生一個全域性排序後的結果列表。
(4)接下來就是 取回階段,協調節點辨別出哪些檔案需要被取回並向相關的分片提交多個 GET 請求。每個分片載入並 豐 富 檔案,如果有需要的話,接著返回檔案給協調節點。一旦所有的檔案都被取回了,協調節點返回結果給使用者端。
(5)補充:Query Then Fetch 的搜尋型別在檔案相關性打分的時候參考的是本分片的資料,這樣在檔案數量較少的時候可能不夠準確,DFS Query Then Fetch 增加了一個預查詢的處理,詢問 Term 和Document frequency,這個評分更準確,但是效能會變差。
14、在 ES 中,是怎麼根據一個詞找到對應的倒排索引的?
(1)Lucene的索引過程,就是按照全文檢索的基本過程,將倒排表寫成此檔案格式的過程。
(2)Lucene的搜尋過程,就是按照此檔案格式將索引進去的資訊讀出來,然後計算每篇檔案打分(score)的過程。
15、對於 GC 方面,在使用 Elasticsearch 時要注意什麼?
(1)倒排詞典的索引需要常駐記憶體,無法 GC,需要監控 data node 上 segmentmemory 增長趨勢。
(2)各類快取,field cache, filter cache, indexing cache, bulk queue 等等,要設定合理的大小,並且要應該根據最壞的情況來看 heap 是否夠用,也就是各類快取全部佔滿的時候,還有 heap 空間可以分配給其他任務嗎?避免採用 clear cache等「自欺欺人」的方式來釋放記憶體。
(3)避免返回大量結果集的搜尋與聚合。確實需要大量拉取資料的場景,可以採用scan & scroll api來實現。
(4)cluster stats 駐留記憶體並無法水平擴充套件,超大規模叢集可以考慮分拆成多個叢集通過 tribe node連線。
(5)想知道 heap 夠不夠,必須結合實際應用場景,並對叢集的 heap 使用情況做持續的監控。
(6)根據監控資料理解記憶體需求,合理設定各類circuit breaker,將記憶體溢位風險降低到最低。
16、ES 對於巨量資料量(上億量級)的聚合如何實現?
Elasticsearch 提供的首個近似聚合是 cardinality 度量。它提供一個欄位的基數,即該欄位的 distinct或者 unique 值的數目。它是基於 HLL 演演算法的。HLL 會先對我們的輸入作雜湊運算,然後根據雜湊運算的結果中的 bits 做概率估算從而得到基數。其特點是:可設定的精度,用來控制記憶體的使用(更精確= 更多記憶體);小的資料集精度是非常高的;我們可以通過設定引數,來設定去重需要的固定記憶體使用量。無論數千還是數十億的唯一值,記憶體使用量只與你設定的精確度相關。
17、並行情況下,Elasticsearch 如果保證讀寫一致?
(1)可以通過版本號使用樂觀並行控制,以確保新版本不會被舊版本覆蓋,由應用層來處理具體的衝突;
(2)另外對於寫操作,一致性級別支援 quorum/one/all,預設為 quorum,即只有當大多數分片可用時才允許寫操作。但即使大多數可用,也可能存在因為網路等原因導致寫入副本失敗,這樣該副本被認為故障,分片將會在一個不同的節點上重建。
(3)對於讀操作,可以設定 replication 為 sync(預設),這使得操作在主分片和副本分片都完成後才會返回;如果設定 replication 為 async 時,也可以通過設定搜尋請求引數_preference 為 primary 來查詢主分片,確保檔案是最新版本。
18、如何監控 Elasticsearch 叢集狀態?
Marvel 讓你可以很簡單的通過 Kibana 監控 Elasticsearch。你可以實時檢視你的叢集健康狀態和效能,也可以分析過去的叢集、索引和節點指標。
19、是否瞭解字典樹?
Trie 的核心思想是空間換時間,利用字串的公共字首來降低查詢時間的開銷以達到提高效率的目的。
它有 3 個基本性質:
1)根節點不包含字元,除根節點外每一個節點都只包含一個字元。
2)從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串。
3)每個節點的所有子節點包含的字元都不相同。
丈夫有淚不輕彈
只因未到傷心處