MySQL 是怎麼加行級鎖的?為什麼一會是 next-key 鎖,一會是間隙鎖,一會又是記錄鎖?
大家好,我是小林。
是不是很多人都對 MySQL 加行級鎖的規則搞的迷迷糊糊,一會是 next-key 鎖,一會是間隙鎖,一會又是記錄鎖。
坦白說,確實還挺複雜的,但是好在我找點了點規律,也知道如何如何用命令分析加了什麼型別的行級鎖。
之前我寫過一篇關於「MySQL 是怎麼加行級鎖的?」的文章,隨著我寫 MySQL 鎖相關的文章越來越多時,後來發現當時的文章寫的不夠詳細。
為了讓大家很清楚的知道 MySQL 是怎麼加行級鎖的,以及如何用命令分析加了什麼行級鎖,所以我重寫了這篇文章。
文章內容比較長,大家可以耐心看下去,一定會有新的發現!
什麼 SQL 語句會加行級鎖?
InnoDB 引擎是支援行級鎖的,而 MyISAM 引擎並不支援行級鎖,所以後面的內容都是基於 InnoDB 引擎 的。
普通的 select 語句是不會對記錄加鎖的,因為它屬於快照讀,是通過 MVCC(多版本並行控制)實現的。
如果要在查詢時對記錄加行級鎖,可以使用下面這兩個方式,這兩種查詢會加鎖的語句稱為鎖定讀。
//對讀取的記錄加共用鎖(S型鎖)
select ... lock in share mode;
//對讀取的記錄加獨佔鎖(X型鎖)
select ... for update;
上面這兩條語句必須在一個事務中,因為當事務提交了,鎖就會被釋放,所以在使用這兩條語句的時候,要加上 begin 或者 start transaction 開啟事務的語句。
**除了上面這兩條鎖定讀語句會加行級鎖之外,update 和 delete 操作都會加行級鎖,且鎖的型別都是獨佔鎖(X型鎖)**。
//對操作的記錄加獨佔鎖(X型鎖)
updaet table .... where id = 1;
//對操作的記錄加獨佔鎖(X型鎖)
delete from table where id = 1;
共用鎖(S鎖)滿足讀讀共用,讀寫互斥。獨佔鎖(X鎖)滿足寫寫互斥、讀寫互斥。

行級鎖有哪些種類?
不同隔離級別下,行級鎖的種類是不同的。
在讀已提交隔離級別下,行級鎖的種類只有記錄鎖,也就是僅僅把一條記錄鎖上。
在可重複讀隔離級別下,行級鎖的種類除了有記錄鎖,還有間隙鎖(目的是為了避免幻讀),所以行級鎖的種類主要有三類:
- Record Lock,記錄鎖,也就是僅僅把一條記錄鎖上;
- Gap Lock,間隙鎖,鎖定一個範圍,但是不包含記錄本身;
- Next-Key Lock:Record Lock + Gap Lock 的組合,鎖定一個範圍,並且鎖定記錄本身。
接下來,分別介紹這三種行級鎖。
Record Lock
Record Lock 稱為記錄鎖,鎖住的是一條記錄。而且記錄鎖是有 S 鎖和 X 鎖之分的:
- 當一個事務對一條記錄加了 S 型記錄鎖後,其他事務也可以繼續對該記錄加 S 型記錄鎖(S 型與 S 鎖相容),但是不可以對該記錄加 X 型記錄鎖(S 型與 X 鎖不相容);
- 當一個事務對一條記錄加了 X 型記錄鎖後,其他事務既不可以對該記錄加 S 型記錄鎖(S 型與 X 鎖不相容),也不可以對該記錄加 X 型記錄鎖(X 型與 X 鎖不相容)。
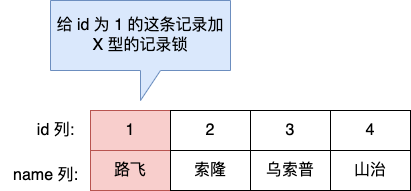
舉個例子,當一個事務執行了下面這條語句:
mysql > begin;
mysql > select * from t_test where id = 1 for update;
事務會對錶中主鍵 id = 1 的這條記錄加上 X 型的記錄鎖,這樣其他事務就無法對這條記錄進行修改和刪除了。
 img
img
當事務執行 commit 後,事務過程中生成的鎖都會被釋放。
Gap Lock
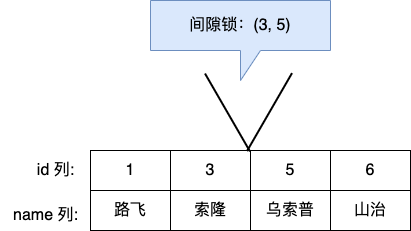
Gap Lock 稱為間隙鎖,只存在於可重複讀隔離級別,目的是為了解決可重複讀隔離級別下幻讀的現象。
假設,表中有一個範圍 id 為(3,5)間隙鎖,那麼其他事務就無法插入 id = 4 這條記錄了,這樣就有效的防止幻讀現象的發生。
 img
img
間隙鎖雖然存在 X 型間隙鎖和 S 型間隙鎖,但是並沒有什麼區別,間隙鎖之間是相容的,即兩個事務可以同時持有包含共同間隙範圍的間隙鎖,並不存在互斥關係,因為間隙鎖的目的是防止插入幻影記錄而提出的。
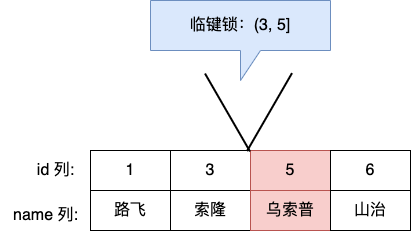
Next-Key Lock
Next-Key Lock 稱為臨鍵鎖,是 Record Lock + Gap Lock 的組合,鎖定一個範圍,並且鎖定記錄本身。
假設,表中有一個範圍 id 為(3,5] 的 next-key lock,那麼其他事務即不能插入 id = 4 記錄,也不能修改 id = 5 這條記錄。
 img
img
所以,next-key lock 即能保護該記錄,又能阻止其他事務將新記錄插入到被保護記錄前面的間隙中。
next-key lock 是包含間隙鎖+記錄鎖的,如果一個事務獲取了 X 型的 next-key lock,那麼另外一個事務在獲取相同範圍的 X 型的 next-key lock 時,是會被阻塞的。
比如,一個事務持有了範圍為 (1, 10] 的 X 型的 next-key lock,那麼另外一個事務在獲取相同範圍的 X 型的 next-key lock 時,就會被阻塞。
雖然相同範圍的間隙鎖是多個事務相互相容的,但對於記錄鎖,我們是要考慮 X 型與 S 型關係,X 型的記錄鎖與 X 型的記錄鎖是衝突的。
MySQL 是怎麼加行級鎖的?
行級鎖加鎖規則比較複雜,不同的場景,加鎖的形式是不同的。
加鎖的物件是索引,加鎖的基本單位是 next-key lock,它是由記錄鎖和間隙鎖組合而成的,next-key lock 是前開後閉區間,而間隙鎖是前開後開區間。
但是,next-key lock 在一些場景下會退化成記錄鎖或間隙鎖。
那到底是什麼場景呢?
這次會以下面這個表結構來進行實驗說明:
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(30) COLLATE utf8mb4_unicode_ci NOT NULL,
`age` int NOT NULL,
PRIMARY KEY (`id`),
KEY `index_age` (`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
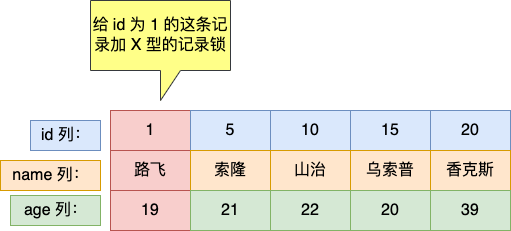
其中,id 是主鍵索引(唯一索引),age 是普通索引(非唯一索引),name 是普通的列。
表中的有這些行記錄:

這次實驗環境的 MySQL 版本是 8.0.26,隔離級別是「可重複讀」。
不同版本的加鎖規則可能是不同的,但是大體上是相同的。
唯一索引等值查詢
當我們用唯一索引進行等值查詢的時候,查詢的記錄存不存在,加鎖的規則也會不同:
- 當查詢的記錄是「存在」的,在索引樹上定位到這一條記錄後,將該記錄的索引中的 next-key lock 會退化成「記錄鎖」。
- 當查詢的記錄是「不存在」的,則會在索引樹找到第一條大於該查詢記錄的記錄,然後將該記錄的索引中的 next-key lock 會退化成「間隙鎖」。
接下里用兩個案例來說明。
1、記錄存在的情況
假設事務 A 執行了這條等值查詢語句,查詢的記錄是「存在」於表中的。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id = 1 for update;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 路飛 | 19 |
+----+--------+-----+
1 row in set (0.02 sec)
那麼,事務 A 會為 id 為 1 的這條記錄就會加上 X 型的記錄鎖。
接下來,如果有其他事務,對 id 為 1 的記錄進行更新或者刪除操作的話,這些操作都會被阻塞,因為更新或者刪除操作也會對記錄加 X 型的記錄鎖,而 X 鎖和 X 鎖之間是互斥關係。
比如,下面這個例子:
.drawiotng5u1aqy3i.png)
因為事務 A 對 id = 1的記錄加了 X 型的記錄鎖,所以事務 B 在修改 id=1 的記錄時會被阻塞,事務 C 在刪除 id=1 的記錄時也會被阻塞。
有什麼命令可以分析加了什麼鎖?
我們可以通過 select * from performance_schema.data_locks\G; 這條語句,檢視事務執行 SQL 過程中加了什麼鎖。
我們以前面的事務 A 作為例子,分析下下它加了什麼鎖。
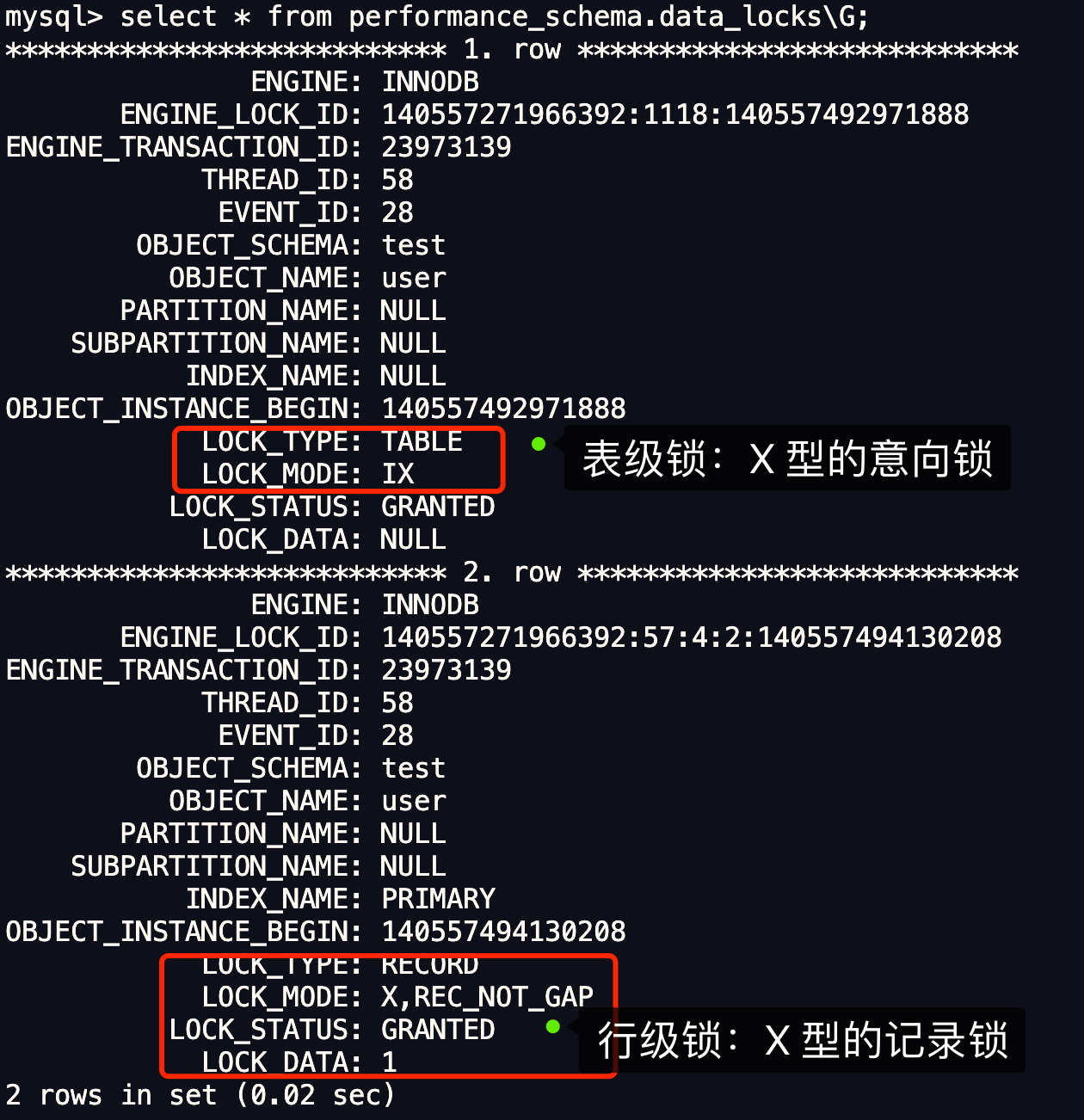
從上圖可以看到,共加了兩個鎖,分別是:
- 表鎖:X 型別的意向鎖;
- 行鎖:X 型別的記錄鎖;
這裡我們重點關注行級鎖,圖中 LOCK_TYPE 中的 RECORD 表示行級鎖,而不是記錄鎖的意思。
通過 LOCK_MODE 可以確認是 next-key 鎖,還是間隙鎖,還是記錄鎖:
- 如果 LOCK_MODE 為
X,說明是 next-key 鎖; - 如果 LOCK_MODE 為
X, REC_NOT_GAP,說明是記錄鎖; - 如果 LOCK_MODE 為
X, GAP,說明是間隙鎖;
因此,此時事務 A 在 id = 1 記錄的主鍵索引上加的是記錄鎖,鎖住的範圍是 id 為 1 的這條記錄。這樣其他事務就無法對 id 為 1 的這條記錄進行更新和刪除操作了。
從這裡我們也可以得知,加鎖的物件是針對索引,因為這裡查詢語句掃描的 B+ 樹是聚簇索引樹,即主鍵索引樹,所以是對主鍵索引加鎖。將對應記錄的主鍵索引加 記錄鎖後,就意味著其他事務無法對該記錄進行更新和刪除操作了。
2、記錄不存在的情況
假設事務 A 執行了這條等值查詢語句,查詢的記錄是「不存在」於表中的。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id = 2 for update;
Empty set (0.03 sec)
接下來,通過 select * from performance_schema.data_locks\G; 這條語句,檢視事務執行 SQL 過程中加了什麼鎖。
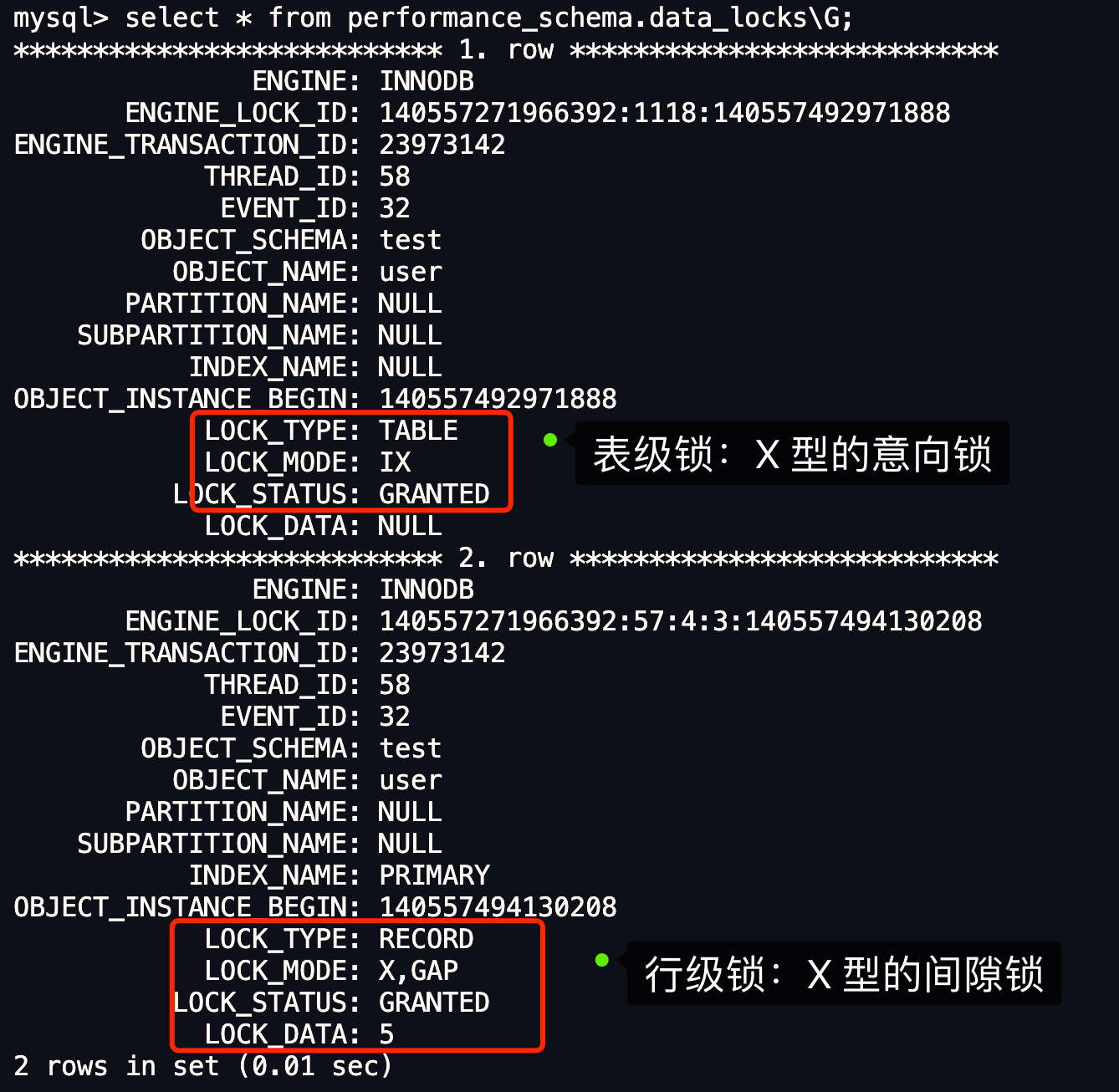
從上圖可以看到,共加了兩個鎖,分別是:
- 表鎖:X 型別的意向鎖;
- 行鎖:X 型別的間隙鎖;
因此,此時事務 A 在 id = 5 記錄的主鍵索引上加的是間隙鎖,鎖住的範圍是 (1, 5)。
接下來,如果有其他事務插入 id 值為 2、3、4 這一些記錄的話,這些插入語句都會發生阻塞。
注意,如果其他事務插入的 id = 1 或者 id = 5 的記錄話,並不會發生阻塞,而是報主鍵衝突的錯誤,因為表中已經存在 id = 1 和 id = 5 的記錄了。
比如,下面這個例子:
.drawioohztmmr1bcu.png)
因為事務 A 在 id = 5 記錄的主鍵索引上加了範圍為 (1, 5) 的 X 型間隙鎖,所以事務 B 在插入一條 id 為 3 的記錄時會被阻塞住,即無法插入 id = 3 的記錄。
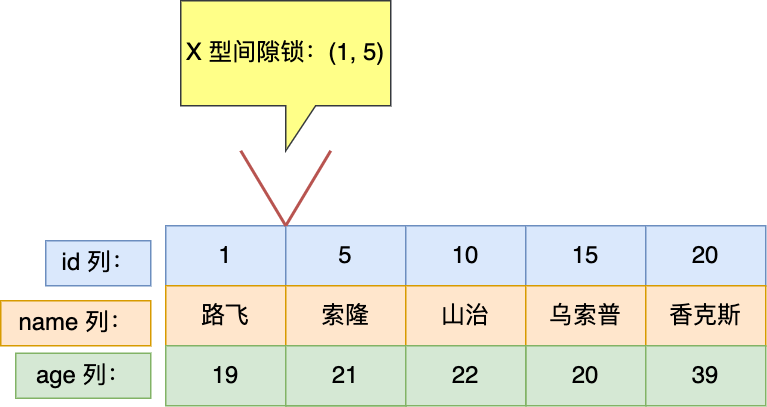
間隙鎖的範圍
(1, 5),是怎麼確定的?
根據我的經驗,如果 LOCK_MODE 是 next-key 鎖或者間隙鎖,那麼 LOCK_DATA 就表示鎖的範圍「右邊界」,此次的事務 A 的 LOCK_DATA 是 5。
然後鎖範圍的「左邊界」是表中 id 為 5 的上一條記錄的 id 值,即 1。
因此,間隙鎖的範圍(1, 5)。
唯一索引範圍查詢
範圍查詢和等值查詢的加鎖規則是不同的。
當唯一索引進行範圍查詢時,會對每一個掃描到的索引加 next-key 鎖,然後如果遇到下面這些情況,會退化成記錄鎖或者間隙鎖:
- 情況一:針對「大於等於」的範圍查詢,因為存在等值查詢的條件,那麼如果等值查詢的記錄是存在於表中,那麼該記錄的索引中的 next-key 鎖會退化成記錄鎖。
- 情況二:針對「小於或者小於等於」的範圍查詢,要看條件值的記錄是否存在於表中:
- 當條件值的記錄不在表中,那麼不管是「小於」還是「小於等於」條件的範圍查詢,掃描到終止範圍查詢的記錄時,該記錄的索引的 next-key 鎖會退化成間隙鎖,其他掃描到的記錄,都是在這些記錄的索引上加 next-key 鎖。
- 當條件值的記錄在表中,如果是「小於」條件的範圍查詢,掃描到終止範圍查詢的記錄時,該記錄的索引的 next-key 鎖會退化成間隙鎖,其他掃描到的記錄,都是在這些記錄的索引上加 next-key 鎖;如果「小於等於」條件的範圍查詢,掃描到終止範圍查詢的記錄時,該記錄的索引 next-key 鎖不會退化成間隙鎖。其他掃描到的記錄,都是在這些記錄的索引上加 next-key 鎖。
接下來,通過幾個實驗,才驗證我上面說的結論。
1、針對「大於或者大於等於」的範圍查詢
實驗一:針對「大於」的範圍查詢的情況。
假設事務 A 執行了這條範圍查詢語句:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id > 15 for update;
+----+-----------+-----+
| id | name | age |
+----+-----------+-----+
| 20 | 香克斯 | 39 |
+----+-----------+-----+
1 row in set (0.01 sec)
事務 A 加鎖變化過程如下:
- 最開始要找的第一行是 id = 20,由於查詢該記錄不是一個等值查詢(不是大於等於條件查詢),所以對該主鍵索引加的是範圍為 (15, 20] 的 next-key 鎖;
- 由於是範圍查詢,就會繼續往後找存在的記錄,雖然我們看見表中最後一條記錄是 id = 20 的記錄,但是實際在 Innodb 儲存引擎中,會用一個特殊的記錄來標識最後一條記錄,該特殊的記錄的名字叫 supremum pseudo-record ,所以掃描第二行的時候,也就掃描到了這個特殊記錄的時候,會對該主鍵索引加的是範圍為 (20, +∞] 的 next-key 鎖。
- 停止掃描。
可以得知,事務 A 在主鍵索引上加了兩個 X 型 的 next-key 鎖:
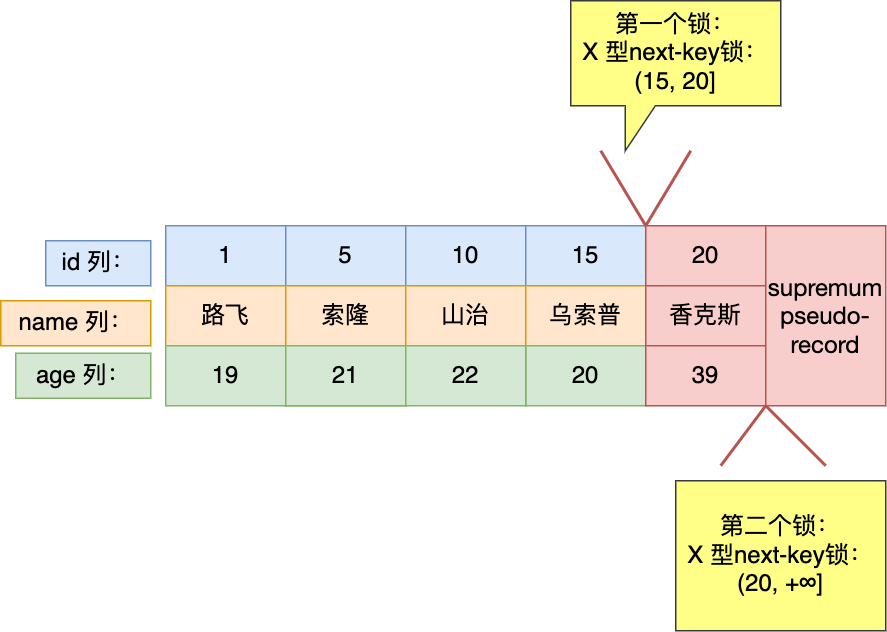
- 在 id = 20 這條記錄的主鍵索引上,加了範圍為 (15, 20] 的 next-key 鎖,意味著其他事務即無法更新或者刪除 id = 20 的記錄,同時無法插入 id 值為 16、17、18、19 的這一些新記錄。
- 在特殊記錄( supremum pseudo-record)的主鍵索引上,加了範圍為 (20, +∞] 的 next-key 鎖,意味著其他事務無法插入 id 值大於 20 的這一些新記錄。
我們也可以通過 select * from performance_schema.data_locks\G; 這條語句來看看事務 A 加了什麼鎖。
輸出結果如下,我這裡只擷取了行級鎖的內容。

從上圖中的分析中,也可以得到事務 A 在主鍵索引上加了兩個 X 型 的next-key 鎖:
- 在 id = 20 這條記錄的主鍵索引上,加了範圍為 (15, 20] 的 next-key 鎖,意味著其他事務即無法更新或者刪除 id = 20 的記錄,同時無法插入 id 值為 16、17、18、19 的這一些新記錄。
- 在特殊記錄( supremum pseudo-record)的主鍵索引上,加了範圍為 (20, +∞] 的 next-key 鎖,意味著其他事務無法插入 id 值大於 20 的這一些新記錄。
實驗二:針對「大於等於」的範圍查詢的情況。
假設事務 A 執行了這條範圍查詢語句:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id >= 15 for update;
+----+-----------+-----+
| id | name | age |
+----+-----------+-----+
| 15 | 烏索普 | 20 |
| 20 | 香克斯 | 39 |
+----+-----------+-----+
2 rows in set (0.00 sec)
事務 A 加鎖變化過程如下:
- 最開始要找的第一行是 id = 15,由於查詢該記錄是一個等值查詢(等於 15),所以該主鍵索引的 next-key 鎖會退化成記錄鎖,也就是僅鎖住 id = 15 這一行記錄。
- 由於是範圍查詢,就會繼續往後找存在的記錄,掃描到的第二行是 id = 20,於是對該主鍵索引加的是範圍為 (15, 20] 的 next-key 鎖;
- 接著掃描到第三行的時候,掃描到了特殊記錄( supremum pseudo-record),於是對該主鍵索引加的是範圍為 (20, +∞] 的 next-key 鎖。
- 停止掃描。
可以得知,事務 A 在主鍵索引上加了三個 X 型 的鎖,分別是:
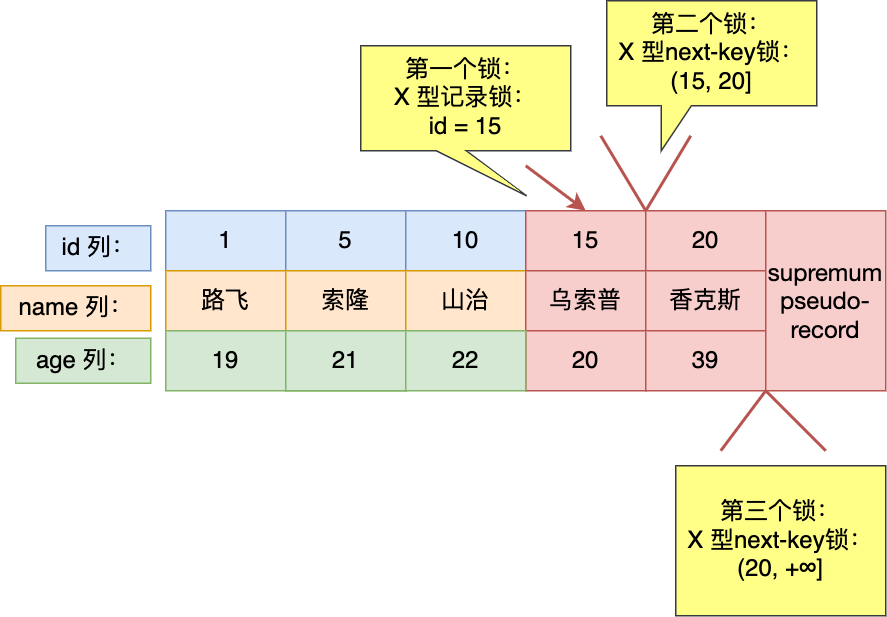
- 在 id = 15 這條記錄的主鍵索引上,加了記錄鎖,範圍是 id = 15 這一行記錄;意味著其他事務無法更新或者刪除 id = 15 的這一條記錄;
- 在 id = 20 這條記錄的主鍵索引上,加了 next-key 鎖,範圍是 (15, 20] 。意味著其他事務即無法更新或者刪除 id = 20 的記錄,同時無法插入 id 值為 16、17、18、19 的這一些新記錄。
- 在特殊記錄( supremum pseudo-record)的主鍵索引上,加了 next-key 鎖,範圍是 (20, +∞] 。意味著其他事務無法插入 id 值大於 20 的這一些新記錄。
我們也可以通過 select * from performance_schema.data_locks\G; 這條語句來看看事務 A 加了什麼鎖。
輸出結果如下,我這裡只擷取了行級鎖的內容。

通過前面這個實驗,我們證明了:
- 針對「大於等於」條件的唯一索引範圍查詢的情況下, 如果條件值的記錄存在於表中,那麼由於查詢該條件值的記錄是包含一個等值查詢的操作,所以該記錄的索引中的 next-key 鎖會退化成記錄鎖。
2、針對「小於或者小於等於」的範圍查詢
實驗一:針對「小於」的範圍查詢時,查詢條件值的記錄「不存在」表中的情況。
假設事務 A 執行了這條範圍查詢語句,注意查詢條件值的記錄(id 為 6)並不存在於表中。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id < 6 for update;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 路飛 | 19 |
| 5 | 索隆 | 21 |
+----+--------+-----+
3 rows in set (0.00 sec)
事務 A 加鎖變化過程如下:
- 最開始要找的第一行是 id = 1,於是對該主鍵索引加的是範圍為 (-∞, 1] 的 next-key 鎖;
- 由於是範圍查詢,就會繼續往後找存在的記錄,掃描到的第二行是 id = 5,所以對該主鍵索引加的是範圍為 (1, 5] 的 next-key 鎖;
- 由於掃描到的第二行記錄(id = 5),滿足 id < 6 條件,而且也沒有達到終止掃描的條件,接著會繼續掃描。
- 掃描到的第三行是 id = 10,該記錄不滿足 id < 6 條件的記錄,所以 id = 10 這一行記錄的鎖會退化成間隙鎖,於是對該主鍵索引加的是範圍為 (5, 10) 的間隙鎖。
- 由於掃描到的第三行記錄(id = 10),不滿足 id < 6 條件,達到了終止掃描的條件,於是停止掃描。
從上面的分析中,可以得知事務 A 在主鍵索引上加了三個 X 型的鎖:
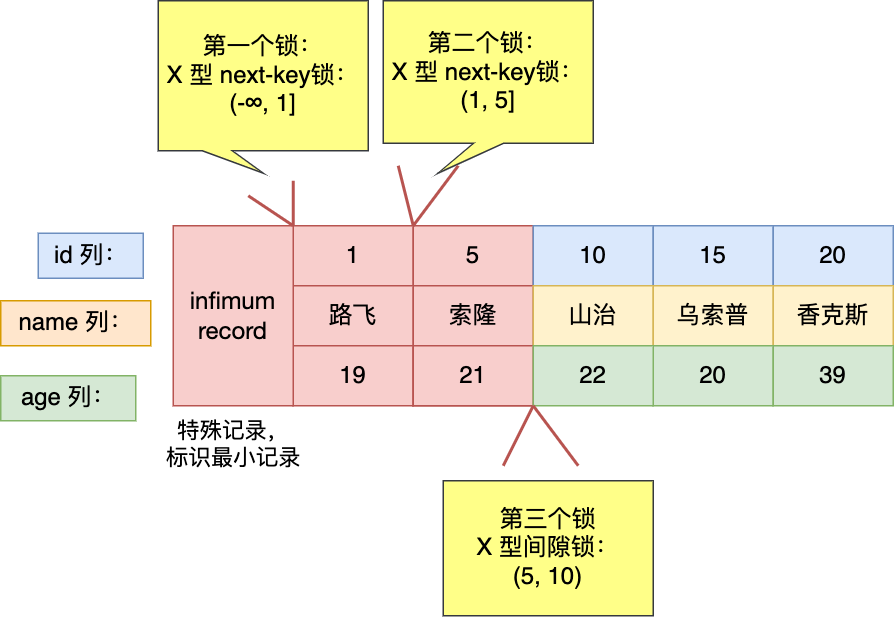
- 在 id = 1 這條記錄的主鍵索引上,加了範圍為 (-∞, 1] 的 next-key 鎖,意味著其他事務即無法更新或者刪除 id = 1 的這一條記錄,同時也無法插入 id 小於 1 的這一些新記錄。
- 在 id = 5 這條記錄的主鍵索引上,加了範圍為 (1, 5] 的 next-key 鎖,意味著其他事務即無法更新或者刪除 id = 5 的這一條記錄,同時也無法插入 id 值為 2、3、4 的這一些新記錄。
- 在 id = 10 這條記錄的主鍵索引上,加了範圍為 (5, 10) 的間隙鎖,意味著其他事務無法插入 id 值為 6、7、8、9 的這一些新記錄。
我們也可以通過 select * from performance_schema.data_locks\G; 這條語句來看看事務 A 加了什麼鎖。
輸出結果如下,我這裡只擷取了行級鎖的內容。
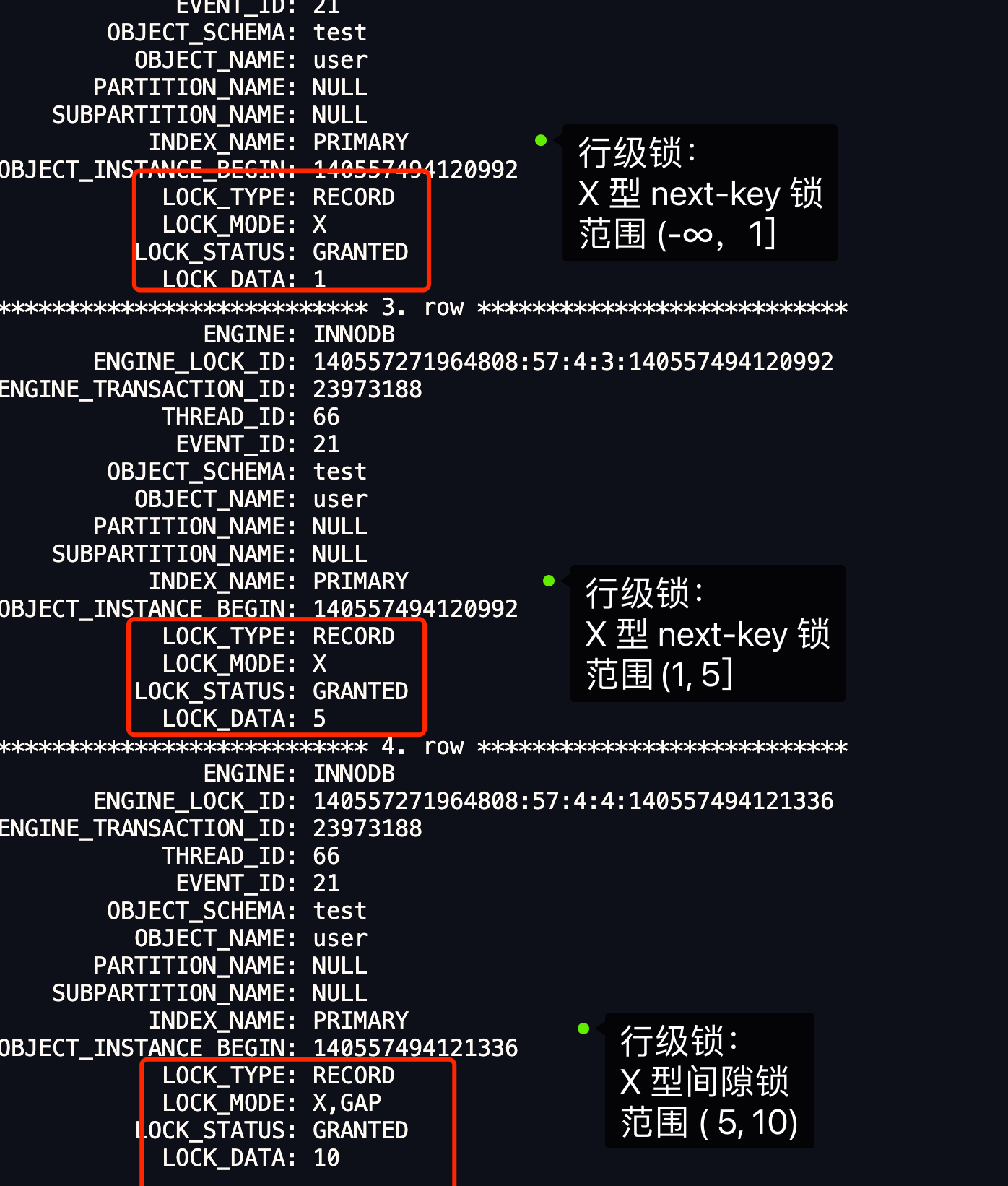
從上圖中的分析中,也可以得知事務 A 在主鍵索引加的三個鎖,就是我們前面分析出那三個鎖。
雖然這次範圍查詢的條件是「小於」,但是查詢條件值的記錄不存在於表中( id 為 6 的記錄不在表中),所以如果事務 A 的範圍查詢的條件改成 <= 6 的話,加的鎖還是和範圍查詢條件為 < 6 是一樣的。 大家自己也驗證下這個結論。
因此,針對「小於或者小於等於」的唯一索引範圍查詢,如果條件值的記錄不在表中,那麼不管是「小於」還是「小於等於」的範圍查詢,掃描到終止範圍查詢的記錄時,該記錄中索引的 next-key 鎖會退化成間隙鎖,其他掃描的記錄,則是在這些記錄的索引上加 next-key 鎖。
實驗二:針對「小於等於」的範圍查詢時,查詢條件值的記錄「存在」表中的情況。
假設事務 A 執行了這條範圍查詢語句,注意查詢條件值的記錄(id 為 5)存在於表中。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where id <= 5 for update;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 1 | 路飛 | 19 |
| 5 | 索隆 | 21 |
+----+--------+-----+
2 rows in set (0.00 sec)
事務 A 加鎖變化過程如下:
- 最開始要找的第一行是 id = 1,於是對該記錄加的是範圍為 (-∞, 1] 的 next-key 鎖;
- 由於是範圍查詢,就會繼續往後找存在的記錄,掃描到的第二行是 id = 5,於是對該記錄加的是範圍為 (1, 5] 的 next-key 鎖。
- 由於主鍵索引具有唯一性,不會存在兩個 id = 5 的記錄,所以不會再繼續掃描,於是停止掃描。
從上面的分析中,可以得到事務 A 在主鍵索引上加了 2 個 X 型的鎖:
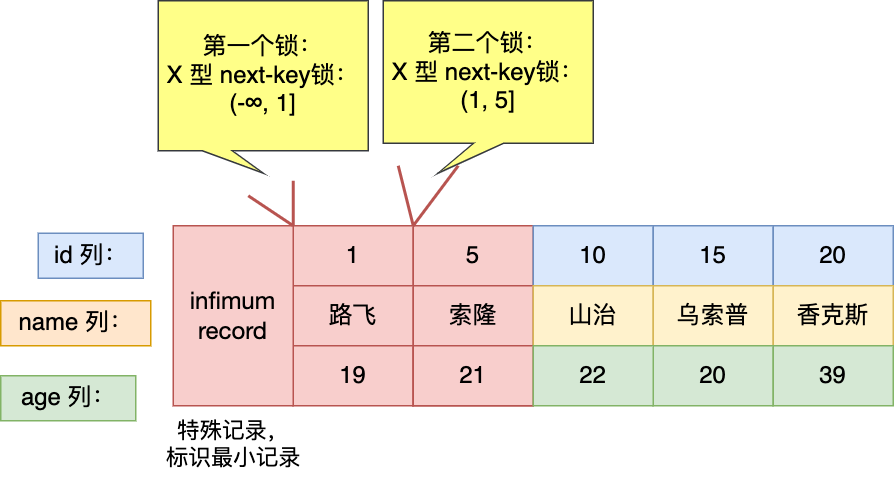
- 在 id = 1 這條記錄的主鍵索引上,加了範圍為 (-∞, 1] 的 next-key 鎖。意味著其他事務即無法更新或者刪除 id = 1 的這一條記錄,同時也無法插入 id 小於 1 的這一些新記錄。
- 在 id = 5 這條記錄的主鍵索引上,加了範圍為 (1, 5] 的 next-key 鎖。意味著其他事務即無法更新或者刪除 id = 5 的這一條記錄,同時也無法插入 id 值為 2、3、4 的這一些新記錄。
我們也可以通過 select * from performance_schema.data_locks\G; 這條語句來看看事務 A 加了什麼鎖。
輸出結果如下,我這裡只擷取了行級鎖的內容。
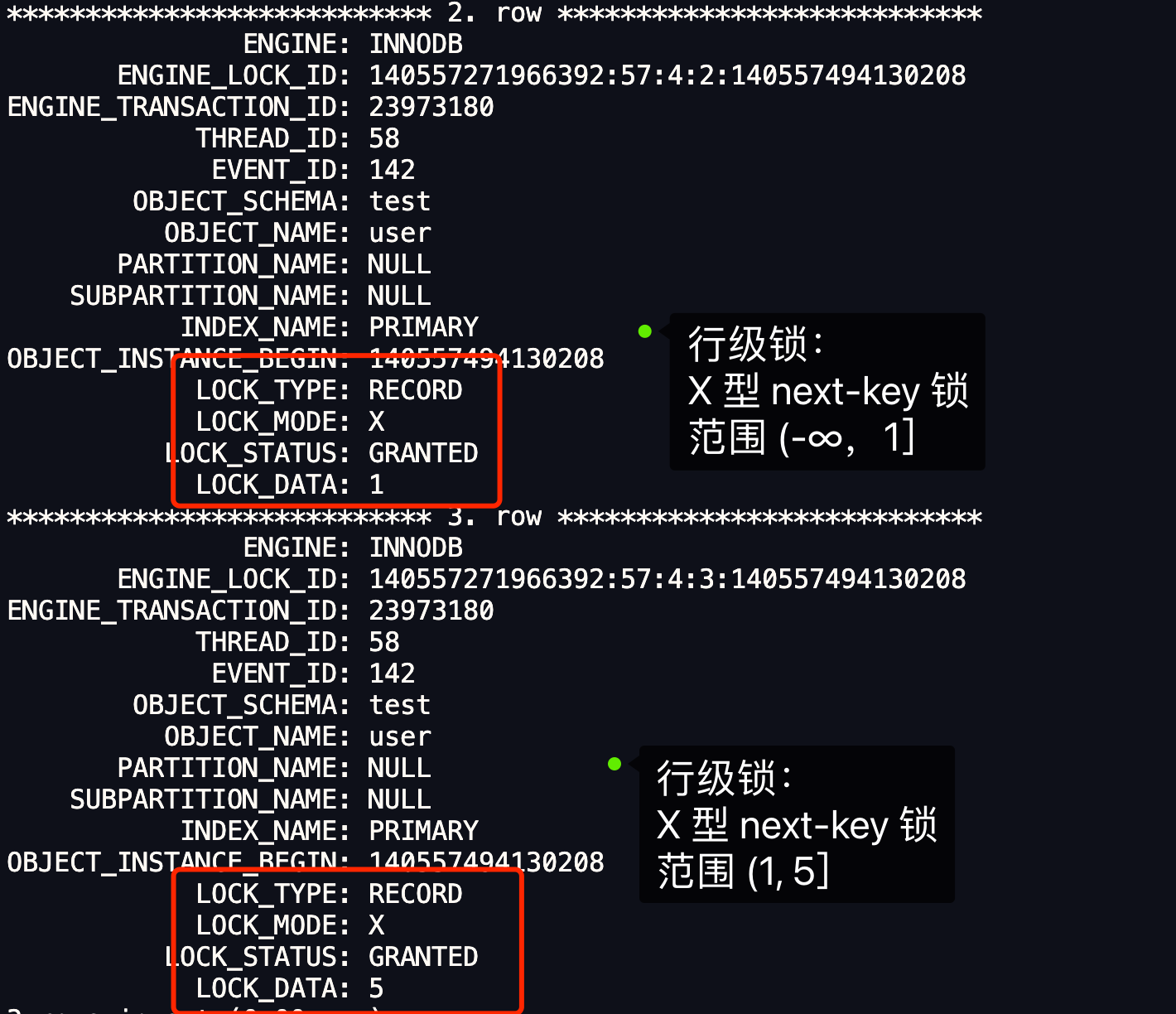
從上圖中的分析中,可以得到事務 A 在主鍵索引上加了兩個 X 型 next-key 鎖,分別是:
- 在 id = 1 這條記錄的主鍵索引上,加了範圍為 (-∞, 1] 的 next-key 鎖;
- 在 id = 5 這條記錄的主鍵索引上,加了範圍為(1, 5 ] 的 next-key 鎖。
實驗三:再來看針對「小於」的範圍查詢時,查詢條件值的記錄「存在」表中的情況。
如果事務 A 的查詢語句是小於的範圍查詢,且查詢條件值的記錄(id 為 5)存在於表中。
select * from user where id < 5 for update;
事務 A 加鎖變化過程如下:
- 最開始要找的第一行是 id = 1,於是對該記錄加的是範圍為 (-∞, 1] 的 next-key 鎖;
- 由於是範圍查詢,就會繼續往後找存在的記錄,掃描到的第二行是 id = 5,該記錄是第一條不滿足 id < 5 條件的記錄,於是**該記錄的鎖會退化為間隙鎖,鎖範圍是 (1,5)**。
- 由於找到了第一條不滿足 id < 5 條件的記錄,於是停止掃描。
可以得知,此時事務 A 在主鍵索引上加了兩種 X 型鎖:
.png)
-
在 id = 1 這條記錄的主鍵索引上,加了範圍為 (-∞, 1] 的 next-key 鎖,意味著其他事務即無法更新或者刪除 id = 1 的這一條記錄,同時也無法插入 id 小於 1 的這一些新記錄。
-
在 id = 5 這條記錄的主鍵索引上,加了範圍為 (1,5) 的間隙鎖,意味著其他事務無法插入 id 值為 2、3、4 的這一些新記錄。
我們也可以通過 select * from performance_schema.data_locks\G; 這條語句來看看事務 A 加了什麼鎖。
輸出結果如下,我這裡只擷取了行級鎖的內容。

從上圖中的分析中,可以得到事務 A 在主鍵索引上加了 X 型的範圍為 (-∞, 1] 的 next-key 鎖,和 X 型的範圍為 (1, 5) 的間隙鎖。
因此,通過前面這三個實驗,可以得知。
在針對「小於或者小於等於」的唯一索引(主鍵索引)範圍查詢時,存在這兩種情況會將索引的 next-key 鎖會退化成間隙鎖的:
- 當條件值的記錄「不在」表中時,那麼不管是「小於」還是「小於等於」條件的範圍查詢,掃描到終止範圍查詢的記錄時,該記錄的主鍵索引中的 next-key 鎖會退化成間隙鎖,其他掃描到的記錄,都是在這些記錄的主鍵索引上加 next-key 鎖。
- 當條件值的記錄「在」表中時:
- 如果是「小於」條件的範圍查詢,掃描到終止範圍查詢的記錄時,該記錄的主鍵索引中的 next-key 鎖會退化成間隙鎖,其他掃描到的記錄,都是在這些記錄的主鍵索引上,加 next-key 鎖。
- 如果是「小於等於」條件的範圍查詢,掃描到終止範圍查詢的記錄時,該記錄的主鍵索引中的 next-key 鎖「不會」退化成間隙鎖,其他掃描到的記錄,都是在這些記錄的主鍵索引上加 next-key 鎖。
非唯一索引等值查詢
當我們用非唯一索引進行等值查詢的時候,因為存在兩個索引,一個是主鍵索引,一個是非唯一索引(二級索引),所以在加鎖時,同時會對這兩個索引都加鎖,但是對主鍵索引加鎖的時候,只有滿足查詢條件的記錄才會對它們的主鍵索引加鎖。
針對非唯一索引等值查詢時,查詢的記錄存不存在,加鎖的規則也會不同:
- 當查詢的記錄「存在」時,由於不是唯一索引,所以肯定存在索引值相同的記錄,於是非唯一索引等值查詢的過程是一個掃描的過程,直到掃描到第一個不符合條件的二級索引記錄就停止掃描,然後在掃描的過程中,對掃描到的二級索引記錄加的是 next-key 鎖,而對於第一個不符合條件的二級索引記錄,該二級索引的 next-key 鎖會退化成間隙鎖。同時,在符合查詢條件的記錄的主鍵索引上加記錄鎖。
- 當查詢的記錄「不存在」時,掃描到第一條不符合條件的二級索引記錄,該二級索引的 next-key 鎖會退化成間隙鎖。因為不存在滿足查詢條件的記錄,所以不會對主鍵索引加鎖。
接下里用兩個實驗來說明。
1、記錄不存在的情況
實驗一:針對非唯一索引等值查詢時,查詢的值不存在的情況。
先來說說非唯一索引等值查詢時,查詢的記錄不存在的情況,因為這個比較簡單。
假設事務 A 對非唯一索引(age)進行了等值查詢,且表中不存在 age = 25 的記錄。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where age = 25 for update;
Empty set (0.00 sec)
事務 A 加鎖變化過程如下:
- 定位到第一條不符合查詢條件的二級索引記錄,即掃描到 age = 39,於是該二級索引的 next-key 鎖會退化成間隙鎖,範圍是 (22, 39)。
- 停止查詢
事務 A 在 age = 39 記錄的二級索引上,加了 X 型的間隙鎖,範圍是 (22, 39)。意味著其他事務無法插入 age 值為 23、24、25、26、....、38 這些新記錄。不過對於插入 age = 22 和 age = 39 記錄的語句,在一些情況是可以成功插入的,而一些情況則無法成功插入,具體哪些情況,會在後面說。

我們也可以通過 select * from performance_schema.data_locks\G; 這條語句來看看事務 A 加了什麼鎖。
輸出結果如下,我這裡只擷取了行級鎖的內容。
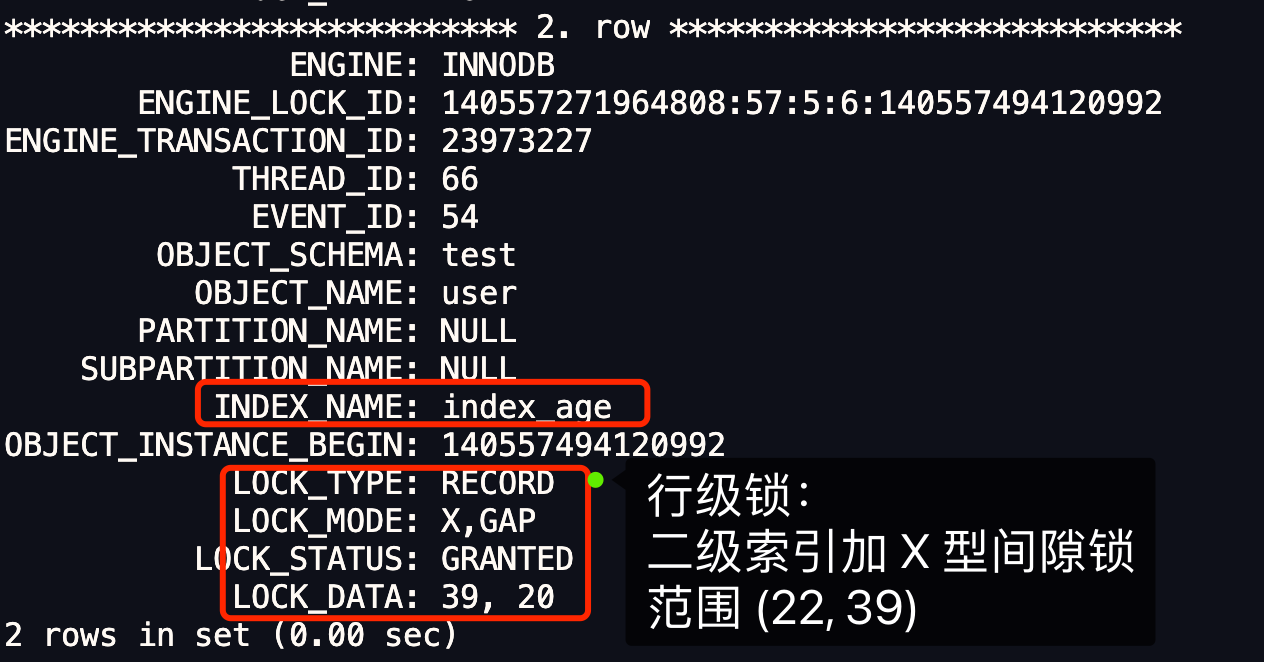
從上圖的分析,可以看到,事務 A 在 age = 39 記錄的二級索引上(INDEX_NAME: index_age ),加了範圍為 (22, 39) 的 X 型間隙鎖。
此時,如果有其他事務插入了 age 值為 23、24、25、26、....、38 這些新記錄,那麼這些插入語句都會發生阻塞。不過對於插入 age = 39 記錄的語句,在一些情況是可以成功插入的,而一些情況則無法成功插入,具體哪些情況,接下來我們就說!
當有一個事務持有二級索引的間隙鎖 (22, 39) 時,什麼情況下,可以讓其他事務的插入 age = 22 或者 age = 39 記錄的語句成功?又是什麼情況下,插入 age = 22 或者 age = 39 記錄時的語句會被阻塞?
我們先要清楚,什麼情況下插入語句會發生阻塞。
插入語句在插入一條記錄之前,需要先定位到該記錄在 B+樹 的位置,如果插入的位置的下一條記錄的索引上有間隙鎖,才會發生阻塞。
在分析二級索引的間隙鎖是否可以成功插入記錄時,我們要先要知道二級索引樹是如何存放記錄的?
二級索引樹是按照二級索引值(age列)按順序存放的,在相同的二級索引值情況下, 再按主鍵 id 的順序存放。知道了這個前提,我們才能知道執行插入語句的時候,插入的位置的下一條記錄是誰。
基於前面的實驗,事務 A 是在 age = 39 記錄的二級索引上,加了 X 型的間隙鎖,範圍是 (22, 39)。
插入 age = 22 記錄的成功和失敗的情況分別如下:
- 當其他事務插入一條 age = 22,id = 3 的記錄的時候,在二級索引樹上定位到插入的位置,而該位置的下一條是 id = 10、age = 22 的記錄,該記錄的二級索引上沒有間隙鎖,所以這條插入語句可以執行成功。
- 當其他事務插入一條 age = 22,id = 12 的記錄的時候,在二級索引樹上定位到插入的位置,而該位置的下一條是 id = 20、age = 39 的記錄,正好該記錄的二級索引上有間隙鎖,所以這條插入語句會被阻塞,無法插入成功。
插入 age = 39 記錄的成功和失敗的情況分別如下:
-
當其他事務插入一條 age = 39,id = 3 的記錄的時候,在二級索引樹上定位到插入的位置,而該位置的下一條是 id = 20、age = 39 的記錄,正好該記錄的二級索引上有間隙鎖,所以這條插入語句會被阻塞,無法插入成功。
-
當其他事務插入一條 age = 39,id = 21 的記錄的時候,在二級索引樹上定位到插入的位置,而該位置的下一條記錄不存在,也就沒有間隙鎖了,所以這條插入語句可以插入成功。
所以,當有一個事務持有二級索引的間隙鎖 (22, 39) 時,插入 age = 22 或者 age = 39 記錄的語句是否可以執行成功,關鍵還要考慮插入記錄的主鍵值,因為「二級索引值(age列)+主鍵值(id列)」才可以確定插入的位置,確定了插入位置後,就要看插入的位置的下一條記錄是否有間隙鎖,如果有間隙鎖,就會發生阻塞,如果沒有間隙鎖,則可以插入成功。
知道了這個結論之後,我們再回過頭看,非唯一索引等值查詢時,查詢的記錄不存在時,執行select * from performance_schema.data_locks\G; 輸出的結果。

在前面分析輸出結果的時候,我說的結論是:「事務 A 在 age = 39 記錄的二級索引上(INDEX_NAME: index_age ),加了範圍為 (22, 39) 的 X 型間隙鎖」。這個結論其實還不夠準確,因為只考慮了 LOCK_DATA 第一個數值(39),沒有考慮 LOCK_DATA 第二個數值(20)。
那 LOCK_DATA:39,20 是什麼意思?
- LOCK_DATA 第一個數值,也就是 39, 它代表的是 age 值。從前面我們也知道了,LOCK_DATA 第一個數值是 next-key 鎖和間隙鎖鎖住的範圍的右邊界值。
- LOCK_DATA 第二個數值,也就是 20, 它代表的是 id 值。
之所以 LOCK_DATA 要多顯示一個數值(ID值),是因為針對「當某個事務持有非唯一索引的 (22, 39) 間隙鎖的時候,其他事務是否可以插入 age = 39 新記錄」的問題,還需要考慮插入記錄的 id 值。而 LOCK_DATA 的第二個數值,就是說明在插入 age = 39 新記錄時,哪些範圍的 id 值是不可以插入的。
因此, LOCK_DATA:39,20 + LOCK_MODE : X, GAP 的意思是,事務 A 在 age = 39 記錄的二級索引上(INDEX_NAME: index_age ),加了 age 值範圍為 (22, 39) 的 X 型間隙鎖,**同時針對其他事務插入 age 值為 39 的新記錄時,不允許插入的新記錄的 id 值小於 20 **。如果插入的新記錄的 id 值大於 20,則可以插入成功。
但是我們無法從select * from performance_schema.data_locks\G; 輸出的結果分析出「在插入 age =22 新記錄時,哪些範圍的 id 值是可以插入成功的」,這時候就得自己畫出二級索引的 B+ 樹的結構,然後確定插入位置後,看下該位置的下一條記錄是否存在間隙鎖,如果存在間隙鎖,則無法插入成功,如果不存在間隙鎖,則可以插入成功。
2、記錄存在的情況
實驗二:針對非唯一索引等值查詢時,查詢的值存在的情況。
假設事務 A 對非唯一索引(age)進行了等值查詢,且表中存在 age = 22 的記錄。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where age = 22 for update;
+----+--------+-----+
| id | name | age |
+----+--------+-----+
| 10 | 山治 | 22 |
+----+--------+-----+
1 row in set (0.00 sec)
事務 A 加鎖變化過程如下:
- 由於不是唯一索引,所以肯定存在值相同的記錄,於是非唯一索引等值查詢的過程是一個掃描的過程,最開始要找的第一行是 age = 22,於是對該二級索引記錄加上範圍為 (21, 22] 的 next-key 鎖。同時,因為 age = 22 符合查詢條件,於是對 age = 22 的記錄的主鍵索引加上記錄鎖,即對 id = 10 這一行加記錄鎖。
- 接著繼續掃描,掃描到的第二行是 age = 39,該記錄是第一個不符合條件的二級索引記錄,所以該二級索引的 next-key 鎖會退化成間隙鎖,範圍是 (22, 39)。
- 停止查詢。
可以看到,事務 A 對主鍵索引和二級索引都加了 X 型的鎖:
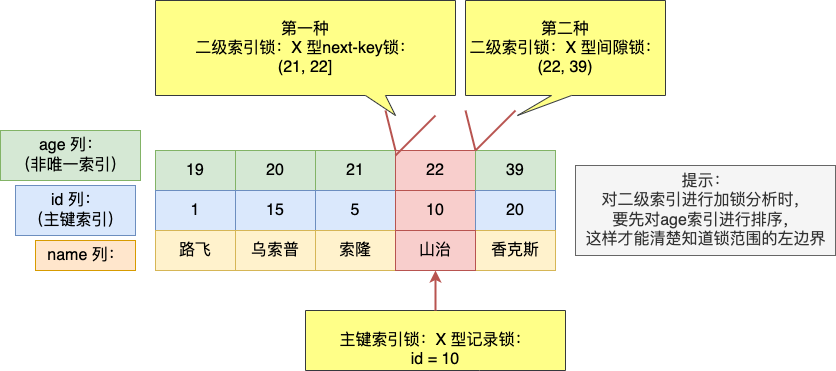
- 主鍵索引:
- 在 id = 10 這條記錄的主鍵索引上,加了記錄鎖,意味著其他事務無法更新或者刪除 id = 10 的這一行記錄。
- 二級索引(非唯一索引):
- 在 age = 22 這條記錄的二級索引上,加了範圍為 (21, 22] 的 next-key 鎖,意味著其他事務無法更新或者刪除 age = 22 的這一些新記錄,不過對於插入 age = 20 和 age = 21 新記錄的語句,在一些情況是可以成功插入的,而一些情況則無法成功插入,具體哪些情況,會在後面說。
- 在 age = 39 這條記錄的二級索引上,加了範圍 (22, 39) 的間隙鎖。意味著其他事務無法插入 age 值為 23、24、..... 、38 的這一些新記錄。不過對於插入 age = 22 和 age = 39 記錄的語句,在一些情況是可以成功插入的,而一些情況則無法成功插入,具體哪些情況,會在後面說。
我們也可以通過 select * from performance_schema.data_locks\G; 這條語句來看看事務 A 加了什麼鎖。
輸出結果如下,我這裡只擷取了行級鎖的內容。
p4dc4pq1lzf.png)
從上圖的分析,可以看到,事務 A 對二級索引(INDEX_NAME: index_age )加了兩個 X 型鎖,分別是:
- 在 age = 22 這條記錄的二級索引上,加了範圍為 (21, 22] 的 next-key 鎖,意味著其他事務無法更新或者刪除 age = 22 的這一些新記錄,針對是否可以插入 age = 21 和 age = 22 的新記錄,分析如下:
- 是否可以插入 age = 21 的新記錄,還要看插入的新記錄的 id 值,如果插入 age = 21 新記錄的 id 值小於 5,那麼就可以插入成功,因為此時插入的位置的下一條記錄是 id = 5,age = 21 的記錄,該記錄的二級索引上沒有間隙鎖。如果插入 age = 21 新記錄的 id 值大於 5,那麼就無法插入成功,因為此時插入的位置的下一條記錄是 id = 20,age = 39 的記錄,該記錄的二級索引上有間隙鎖。
- 是否可以插入 age = 22 的新記錄,還要看插入的新記錄的 id 值,從
LOCK_DATA : 22, 10可以得知,其他事務插入 age 值為 22 的新記錄時,如果插入的新記錄的 id 值小於 10,那麼插入語句會發生阻塞;如果插入的新記錄的 id 大於 10,還要看該新記錄插入的位置的下一條記錄是否有間隙鎖,如果沒有間隙鎖則可以插入成功,如果有間隙鎖,則無法插入成功。
- 在 age = 39 這條記錄的二級索引上,加了範圍 (22, 39) 的間隙鎖。意味著其他事務無法插入 age 值為 23、24、..... 、38 的這一些新記錄,針對是否可以插入 age = 22 和 age = 39 的新記錄,分析如下:
- 是否可以插入 age = 22 的新記錄,還要看插入的新記錄的 id 值,如果插入 age = 22 新記錄的 id 值小於 10,那麼插入語句會被阻塞,無法插入,因為此時插入的位置的下一條記錄是 id = 10,age = 21 的記錄,該記錄的二級索引上有間隙鎖( age = 22 這條記錄的二級索引上有 next-key 鎖)。如果插入 age = 21 新記錄的 id 值大於 10,也無法插入,因為此時插入的位置的下一條記錄是 id = 20,age = 39 的記錄,該記錄的二級索引上有間隙鎖。
- 是否可以插入 age = 39 的新記錄,還要看插入的新記錄的 id 值,從
LOCK_DATA : 39, 20可以得知,其他事務插入 age 值為 39 的新記錄時,如果插入的新記錄的 id 值小於 20,那麼插入語句會發生阻塞,如果插入的新記錄的 id 大於 20,則可以插入成功。
同時,事務 A 還對主鍵索引(INDEX_NAME: PRIMARY )加了X 型的記錄鎖:
- 在 id = 10 這條記錄的主鍵索引上,加了記錄鎖,意味著其他事務無法更新或者刪除 id = 10 的這一行記錄。
為什麼這個實驗案例中,需要在二級索引索引上加範圍 (22, 39) 的間隙鎖?
要找到這個問題的答案,我們要明白 MySQL 在可重複讀的隔離級別場景下,為什麼要引入間隙鎖?其實是為了避免幻讀現象的發生。
如果這個實驗案例中:
select * from user where age = 22 for update;
如果事務 A 不在二級索引索引上加範圍 (22, 39) 的間隙鎖,只在二級索引索引上加範圍為 (21, 22] 的 next-key 鎖的話,那麼就會有幻讀的問題。
前面我也說過,針對範圍為 (21, 22] 的 next-key 鎖,是無法完全鎖住 age = 22 新記錄的插入,因為對於是否可以插入 age = 22 的新記錄,還要看插入的新記錄的 id 值,從 LOCK_DATA : 22, 10 可以得知,其他事務插入 age 值為 22 的新記錄時,如果插入的新記錄的 id 值小於 10,那麼插入語句會發生阻塞,如果插入的新記錄的 id 值大於 10,則可以插入成功。
也就是說,只在二級索引索引上加範圍為 (21, 22] 的 next-key 鎖,其他事務是有可能插入 age 值為 22 的新記錄的(比如插入一個 age = 22,id = 12 的新記錄),那麼如果事務 A 再一次查詢 age = 22 的記錄的時候,前後兩次查詢 age = 22 的結果集就不一樣了,這時就發生了幻讀的現象。
那麼當在 age = 39 這條記錄的二級索引索引上加了範圍為 (22, 39) 的間隙鎖後,其他事務是無法插入一個 age = 22,id = 12 的新記錄,因為當其他事務插入一條 age = 22,id = 12 的新記錄的時候,在二級索引樹上定位到插入的位置,而該位置的下一條是 id = 20、age = 39 的記錄,正好該記錄的二級索引上有間隙鎖,所以這條插入語句會被阻塞,無法插入成功,這樣就避免幻讀現象的發生。
所以,為了避免幻讀現象的發生,就需要在二級索引索引上加範圍 (22, 39) 的間隙鎖。
非唯一索引範圍查詢
非唯一索引和主鍵索引的範圍查詢的加鎖也有所不同,不同之處在於非唯一索引範圍查詢,索引的 next-key lock 不會有退化為間隙鎖和記錄鎖的情況,也就是非唯一索引進行範圍查詢時,對二級索引記錄加鎖都是加 next-key 鎖。
就帶大家簡單分析一下,事務 A 的這條範圍查詢語句:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user where age >= 22 for update;
+----+-----------+-----+
| id | name | age |
+----+-----------+-----+
| 10 | 山治 | 22 |
| 20 | 香克斯 | 39 |
+----+-----------+-----+
2 rows in set (0.01 sec)
事務 A 的加鎖變化:
- 最開始要找的第一行是 age = 22,雖然範圍查詢語句包含等值查詢,但是這裡不是唯一索引範圍查詢,所以是不會發生退化鎖的現象,因此對該二級索引記錄加 next-key 鎖,範圍是 (21, 22]。同時,對 age = 22 這條記錄的主鍵索引加記錄鎖,即對 id = 10 這一行記錄的主鍵索引加記錄鎖。
- 由於是範圍查詢,接著繼續掃描已經存在的二級索引記錄。掃面的第二行是 age = 39 的二級索引記錄,於是對該二級索引記錄加 next-key 鎖,範圍是 (22, 39],同時,對 age = 39 這條記錄的主鍵索引加記錄鎖,即對 id = 20 這一行記錄的主鍵索引加記錄鎖。
- 雖然我們看見表中最後一條二級索引記錄是 age = 39 的記錄,但是實際在 Innodb 儲存引擎中,會用一個特殊的記錄來標識最後一條記錄,該特殊的記錄的名字叫 supremum pseudo-record ,所以掃描第二行的時候,也就掃描到了這個特殊記錄的時候,會對該二級索引記錄加的是範圍為 (39, +∞] 的 next-key 鎖。
- 停止查詢
可以看到,事務 A 對主鍵索引和二級索引都加了 X 型的鎖:

- 主鍵索引(id 列):
- 在 id = 10 這條記錄的主鍵索引上,加了記錄鎖,意味著其他事務無法更新或者刪除 id = 10 的這一行記錄。
- 在 id = 20 這條記錄的主鍵索引上,加了記錄鎖,意味著其他事務無法更新或者刪除 id = 20 的這一行記錄。
- 二級索引(age 列):
- 在 age = 22 這條記錄的二級索引上,加了範圍為 (21, 22] 的 next-key 鎖,意味著其他事務無法更新或者刪除 age = 22 的這一些新記錄,不過對於是否可以插入 age = 21 和 age = 22 的新記錄,還需要看新記錄的 id 值,有些情況是可以成功插入的,而一些情況則無法插入,具體哪些情況,我們前面也講了。
- 在 age = 39 這條記錄的二級索引上,加了範圍為 (22, 39] 的 next-key 鎖,意味著其他事務無法更新或者刪除 age = 39 的這一些記錄,也無法插入 age 值為 23、24、25、...、38 的這一些新記錄。不過對於是否可以插入 age = 22 和 age = 39 的新記錄,還需要看新記錄的 id 值,有些情況是可以成功插入的,而一些情況則無法插入,具體哪些情況,我們前面也講了。
- 在特殊的記錄(supremum pseudo-record)的二級索引上,加了範圍為 (39, +∞] 的 next-key 鎖,意味著其他事務無法插入 age 值大於 39 的這些新記錄。
沒有加索引的查詢
前面的案例,我們的查詢語句都有使用索引查詢,也就是查詢記錄的時候,是通過索引掃描的方式查詢的,然後對掃描出來的記錄進行加鎖。
如果鎖定讀查詢語句,沒有使用索引列作為查詢條件,或者查詢語句沒有走索引查詢,導致掃描是全表掃描。那麼,每一條記錄的索引上都會加 next-key 鎖,這樣就相當於鎖住的全表,這時如果其他事務對該表進行增、刪、改操作的時候,都會被阻塞。
不只是鎖定讀查詢語句不加索引才會導致這種情況,update 和 delete 語句如果查詢條件不加索引,那麼由於掃描的方式是全表掃描,於是就會對每一條記錄的索引上都會加 next-key 鎖,這樣就相當於鎖住的全表。
因此,線上上在執行 update、delete、select ... for update 等具有加鎖性質的語句,一定要檢查語句是否走了索引,如果是全表掃描的話,會對每一個索引加 next-key 鎖,相當於把整個表鎖住了,這是挺嚴重的問題。
總結
這次我以 MySQL 8.0.26 版本,在可重複讀隔離級別之下,做了幾個實驗,讓大家瞭解了唯一索引和非唯一索引的行級鎖的加鎖規則。
我這裡總結下, MySQL 行級鎖的加鎖規則。
唯一索引等值查詢:
- 當查詢的記錄是「存在」的,在索引樹上定位到這一條記錄後,將該記錄的索引中的 next-key lock 會退化成「記錄鎖」。
- 當查詢的記錄是「不存在」的,則會在索引樹找到第一條大於該查詢記錄的記錄,然後將該記錄的索引中的 next-key lock 會退化成「間隙鎖」。
非唯一索引等值查詢:
- 當查詢的記錄「存在」時,由於不是唯一索引,所以肯定存在索引值相同的記錄,於是非唯一索引等值查詢的過程是一個掃描的過程,直到掃描到第一個不符合條件的二級索引記錄就停止掃描,然後在掃描的過程中,對掃描到的二級索引記錄加的是 next-key 鎖,而對於第一個不符合條件的二級索引記錄,該二級索引的 next-key 鎖會退化成間隙鎖。同時,在符合查詢條件的記錄的主鍵索引上加記錄鎖。
- 當查詢的記錄「不存在」時,掃描到第一條不符合條件的二級索引記錄,該二級索引的 next-key 鎖會退化成間隙鎖。因為不存在滿足查詢條件的記錄,所以不會對主鍵索引加鎖。
非唯一索引和主鍵索引的範圍查詢的加鎖規則不同之處在於:
- 唯一索引在滿足一些條件的時候,索引的 next-key lock 退化為間隙鎖或者記錄鎖。
- 非唯一索引範圍查詢,索引的 next-key lock 不會退化為間隙鎖和記錄鎖。
還有一件很重要的事情,線上上在執行 update、delete、select ... for update 等具有加鎖性質的語句,一定要檢查語句是否走了索引,如果是全表掃描的話,會對每一個索引加 next-key 鎖,相當於把整個表鎖住了,這是挺嚴重的問題。
就說到這啦, 我們下次見啦!
推薦閱讀
介紹
基礎篇:
索引篇:
- 索引常見面試題
- 從資料頁的角度看 B+ 樹
- 為什麼 MySQL 採用 B+ 樹作為索引?
- MySQL 單表不要超過 2000W 行,靠譜嗎?
- 索引失效有哪些?
- MySQL 使用 like 「%x「,索引一定會失效嗎?
- count(*) 和 count(1) 有什麼區別?哪個效能最好?
事務篇:
鎖篇:
紀錄檔篇:
記憶體篇: