巨量資料關鍵技術:常規機器學習方法
機器學習方法簡介
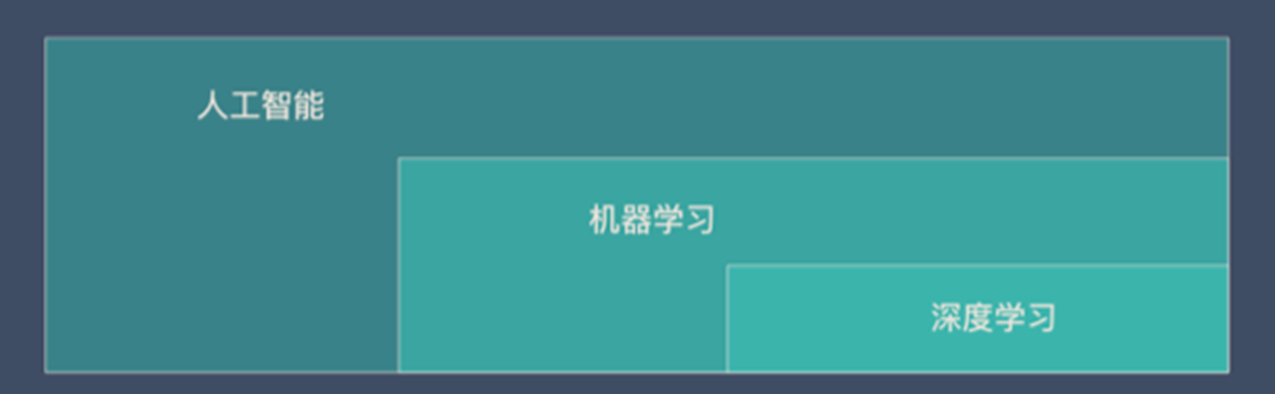
機器學習、人工智慧、深度學習是什麼關係?
機器學習研究和構建的是一種特殊演演算法(而非某一個特定的演演算法),能夠讓計算機自己在資料中學習從而進行預測。
Arthur Samuel給出的定義指出,機器學習是這樣的領域,它賦予計算機學習的能力(這種學習能力)不是通過顯著式程式設計獲得的。
不管是機器學習還是深度學習,都屬於人工智慧(AI)的範疇。所以人工智慧、機器學習、深度學習可以用下面的圖來表示:
機器學習的基本思路
1.把現實生活中的問題抽象成數學模型,並且很清楚模型中不同引數的作用
2.利用數學方法對這個數學模型進行求解,從而解決現實生活中的問題
3.評估這個數學模型,是否真正的解決了現實生活中的問題,解決的如何?
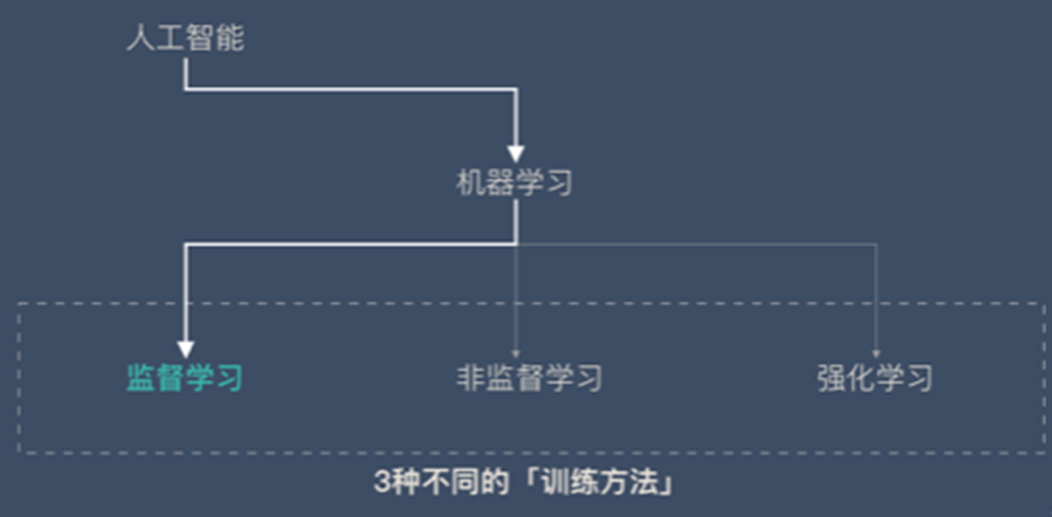
機器學習分類
監督學習
監督學習:指我們給演演算法一個資料集,並且給定正確答案。機器通過資料來學習正確答案的計算方法。
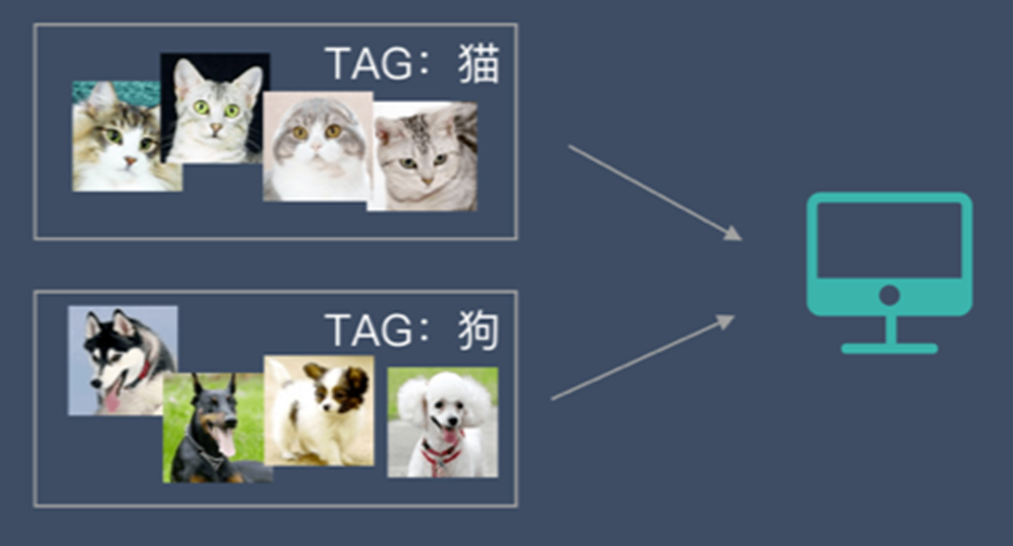
這種通過大量人工打標籤來幫助機器學習的方式就是監督學習。這種學習方式效果非常好,但是成本也非常高。

監督學習的2個任務:
1.迴歸:預測連續的、具體的數值。比如:支付寶裡的芝麻信用分數
2.分類:對各種事物分門別類,用於離散型預測

「迴歸」案例:個人信用評估方法——FICO
FICO 評分系統得出的信用分數範圍在300~850分之間,分數越高,說明信用風險越小。


非監督學習
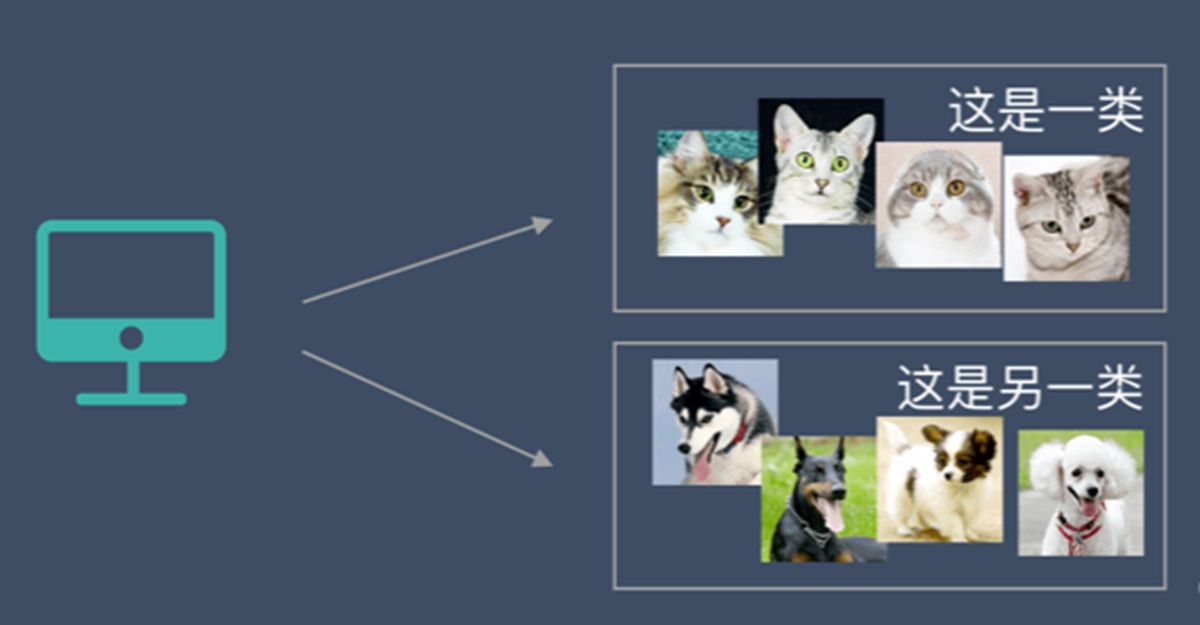
非監督學習中,給定的資料集沒有「正確答案」,所有的資料都是一樣的。無監督學習的任務是從給定的資料集中,挖掘出潛在的結構。
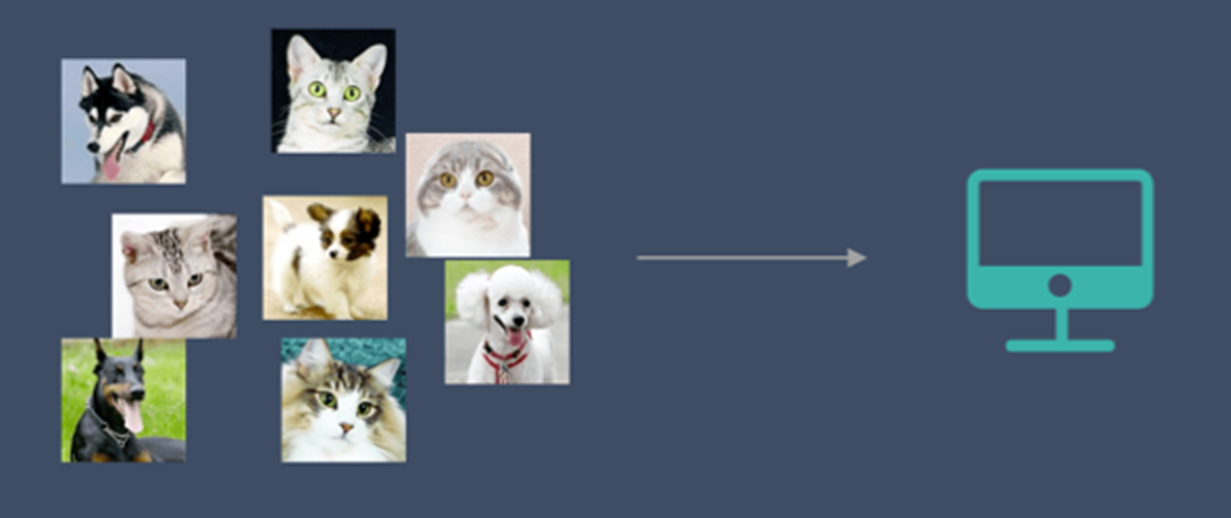
通過學習,機器會把這些照片分為2類,一類都是貓的照片,一類都是狗的照片。雖然跟上面的監督學習看上去結果差不多,但是有著本質的差別:
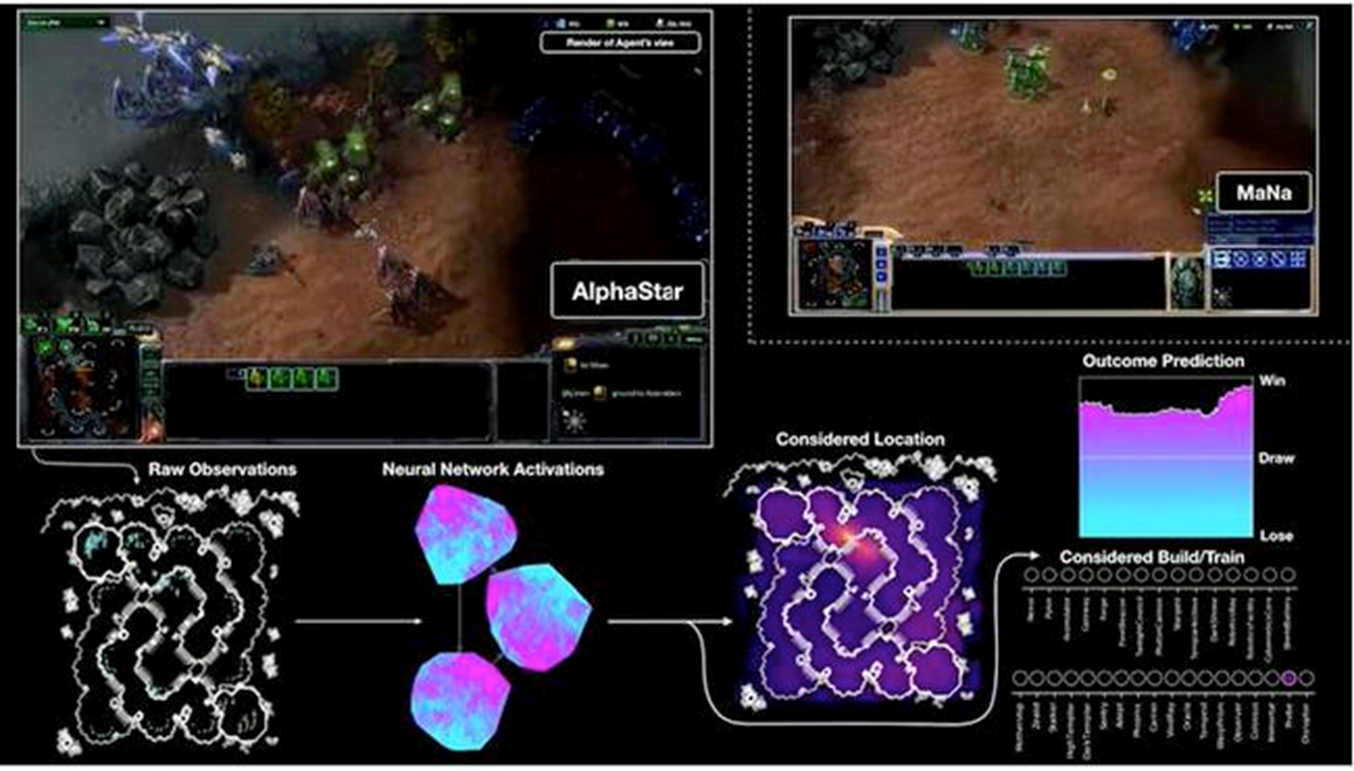
強化學習
在一個有特定規則的場景下,尤其是遊戲。
機器學習實操的步驟
機器學習在實際操作層面一共分為7步:
- 收集資料
- 資料準備
- 選擇一個模型
- 訓練
- 評估
- 引數調整
- 預測(開始使用)

15種經典機器學習演演算法
| 演演算法 | 訓練方式 |
|---|---|
| 線性迴歸 | 監督學習 |
| 邏輯迴歸 | 監督學習 |
| 線性判別分析 | 監督學習 |
| 決策樹 | 監督學習 |
| 樸素貝葉斯 | 監督學習 |
| K鄰近 | 監督學習 |
| 學習向量量化 | 監督學習 |
| 支援向量機 | 監督學習 |
| 隨機森林 | 監督學習 |
| AdaBoost | 監督學習 |
| 高斯混合模型 | 非監督學習 |
| 限制波爾茲曼機 | 非監督學習 |
| K-means 聚類 | 非監督學習 |
| 最大期望演演算法 | 非監督學習 |
主流的監督學習演演算法
| 演演算法 | 型別 | 簡介 |
|---|---|---|
| 樸素貝葉斯 | 分類 | 貝葉斯分類法是基於貝葉斯定定理的統計學分類方法。它通過預測一個給定的元組屬於一個特定類的概率,來進行分類。樸素貝葉斯分類法假定一個屬性值在給定類的影響獨立於其他屬性的 —— 類條件獨立性。 |
| 決策樹 | 分類 | 決策樹是一種簡單但廣泛使用的分類器,它通過訓練資料構建決策樹,對未知的資料進行分類。 |
| SVM | 分類 | 支援向量機把分類問題轉化為尋找分類平面的問題,並通過最大化分類邊界點距離分類平面的距離來實現分類。 |
| 邏輯迴歸 | 分類 | 邏輯迴歸是用於處理因變數為分類變數的迴歸問題,常見的是二分類或二項分佈問題,也可以處理多分類問題,它實際上是屬於一種分類方法。 |
| 線性迴歸 | 迴歸 | 線性迴歸是處理迴歸任務最常用的演演算法之一。該演演算法的形式十分簡單,它期望使用一個超平面擬合資料集(只有兩個變數的時候就是一條直線)。 |
| 迴歸樹 | 迴歸 | 迴歸樹(決策樹的一種)通過將資料集重複分割為不同的分支而實現分層學習,分割的標準是最大化每一次分離的資訊增益。這種分支結構讓迴歸樹很自然地學習到非線性關係。 |
| K鄰近 | 分類+迴歸 | 通過搜尋K個最相似的範例(鄰居)的整個訓練集並總結那些K個範例的輸出變數,對新資料點進行預測。 |
| Adaboosting | 分類+迴歸 | Adaboost目的就是從訓練資料中學習一系列的弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。 |
| 神經網路 | 分類+迴歸 | 它從資訊處理角度對人腦神經元網路進行抽象, 建立某種簡單模型,按不同的連線方式組成不同的網路。 |
模型評估與引數優化——SVM
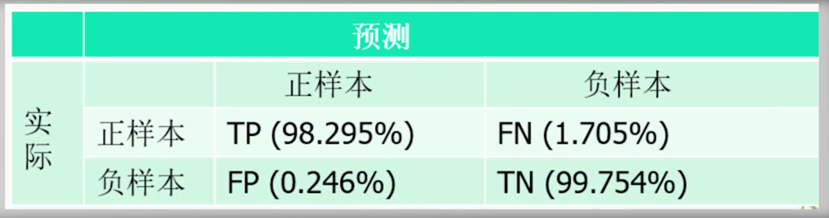
混淆矩陣

TP+FN=所有正樣本的數量
FP+TN=所有負樣本的數量
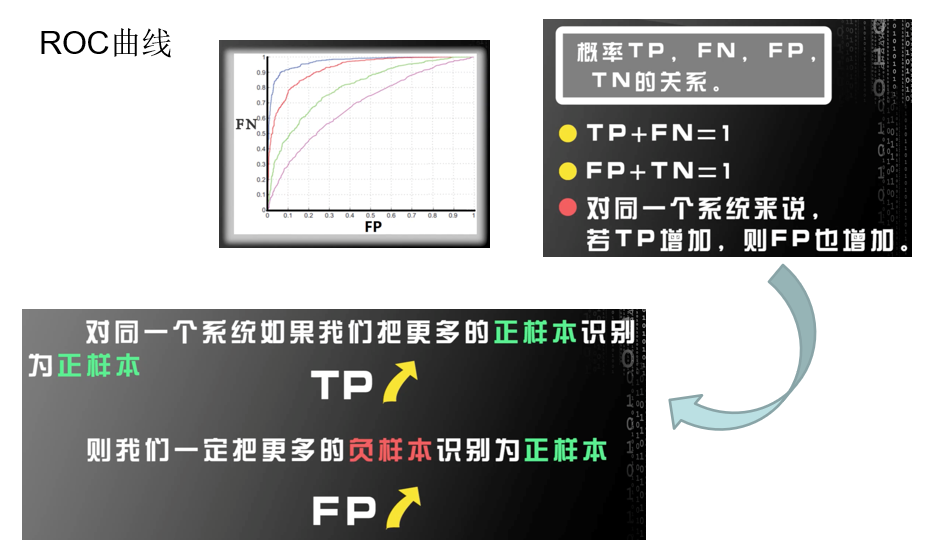
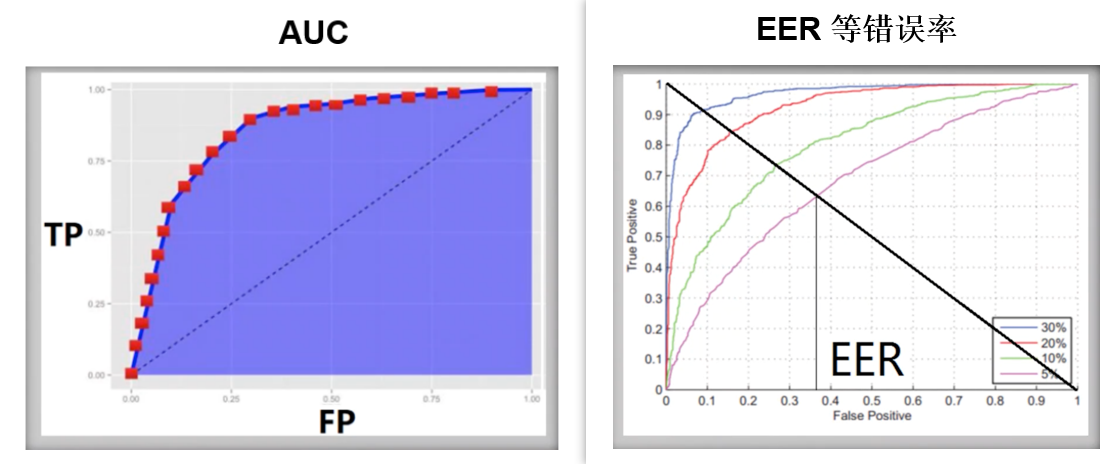
ROC曲線
AUC Score
SVM引數調優
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split,cross_val_score,GridSearchCv
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
#pandas處理資料集
#sklearn.model selection實現資料集分割,自動調參
#sklearn,svm線性支援向量分類
#讀取資料
data = pd.read csv('krkopt.data',header=None)
data.dropna(inplace=True)#不建立新的物件,直接對原始物件進行修改
資料預處理忽略,詳見ppt
SVM引數
SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
SVC引數解釋
- C: 目標函數的懲罰係數C,用來平衡分類間隔margin和錯分樣本的,default C = 1.0;
- kernel:引數選擇有RBF, Linear, Poly, Sigmoid, 預設的是"RBF";
- degree:degree決定了多項式的最高次冪;
- gamma:核函數的係數('Poly', 'RBF' and 'Sigmoid'), 預設是gamma = 1 / n_features;
- coef0:核函數中的獨立項,'RBF' and 'Poly'有效;
- probablity: 可能性估計是否使用(true or false);
- shrinking:是否進行啟發式;
- tol(default = 1e - 3): svm結束標準的精度;
- cache_size: 制定訓練所需要的記憶體(以MB為單位);
- class_weight: 每個類所佔據的權重,不同的類設定不同的懲罰引數C, 預設的話自適應;
- verbose: 跟多執行緒有關;
- max_iter: 最大迭代次數,default = 1, if max_iter = -1, no limited;
- decision_function_shape : ‘ovo’ 一對一, ‘ovr’ 多對多 or None 無, default=None
- random_state :用於概率估計的資料重排時的偽亂數生成器的種子。
ps:7,8,9一般不考慮。
def svm_c(x train,x test,y_train,y_test):
#xbf核函數,設定資料權重
svc = SVC(kernel='rbf',class weight='balanced',)
c_range = np.logspace(-5,15,11,base=2)
gamma range = np.logspace(-9,3,13,base=2)
#網格搜尋交叉驗證的引數範圍,cV=3,3折交叉
param_grid =[{'kernel':['rbf']'C':c_range,'gamma':gamma_range}]
grid = GridSearchCV(svc,param_grid,cv=3,n jobs=-1)
產訓練模型
clf = grid.fit(x train,y_train)
#計算測試集精度
score = grid.score(x test,y test)
print('精度為8s' % score)
網格搜尋(GridSearchCV)
GridSearchCV的名字其實可以拆分為兩部分,GridSearch和CV,即網格搜尋和交叉驗證。
網格搜尋,搜尋的是引數,即在指定的引數範圍內,按步長依次調整引數,利用調整的引數訓練學習器,從所有的引數中找到在驗證集上精度最高的引數,這其實是一個訓練和比較的過程。
交叉驗證分為三種:簡單交叉驗證、S折交叉驗證、留一交叉驗證
GridSearchCV可以保證在指定的引數範圍內找到精度最高的引數,但是這也是網格搜尋的缺陷所在,他要求遍歷所有可能引數的組合,在面對巨量資料集和多引數的情況下,非常耗時。
grid = GridSearchCV(svc, param_grid, cv=3, n_jobs=-1)
#n_jobs=-1,表示使用該計算機的全部cpu