Mysql InnoDB多版本並行控制MVCC
參考書籍《mysql是怎樣執行的》
一丶為什麼需要事務隔離級別
mysql是一個使用者端/伺服器端軟體,對於同一個伺服器來說,可以有多個使用者端進行連線,每一個使用者端進行連線之後就形成一個對談,每一個使用者端都可以在自己的對談中向伺服器發出請求語句,一個請求語句可能是某一個事務的一部分,伺服器可以同時處理多個事務。
如果事務時一個接著一個進行,那麼下一個事務是在上一個事務的一致性前提下進行的,就沒用一致性的問題,但是事務是並行進行且可能存取到相同的資料這時候就會出現如下問題
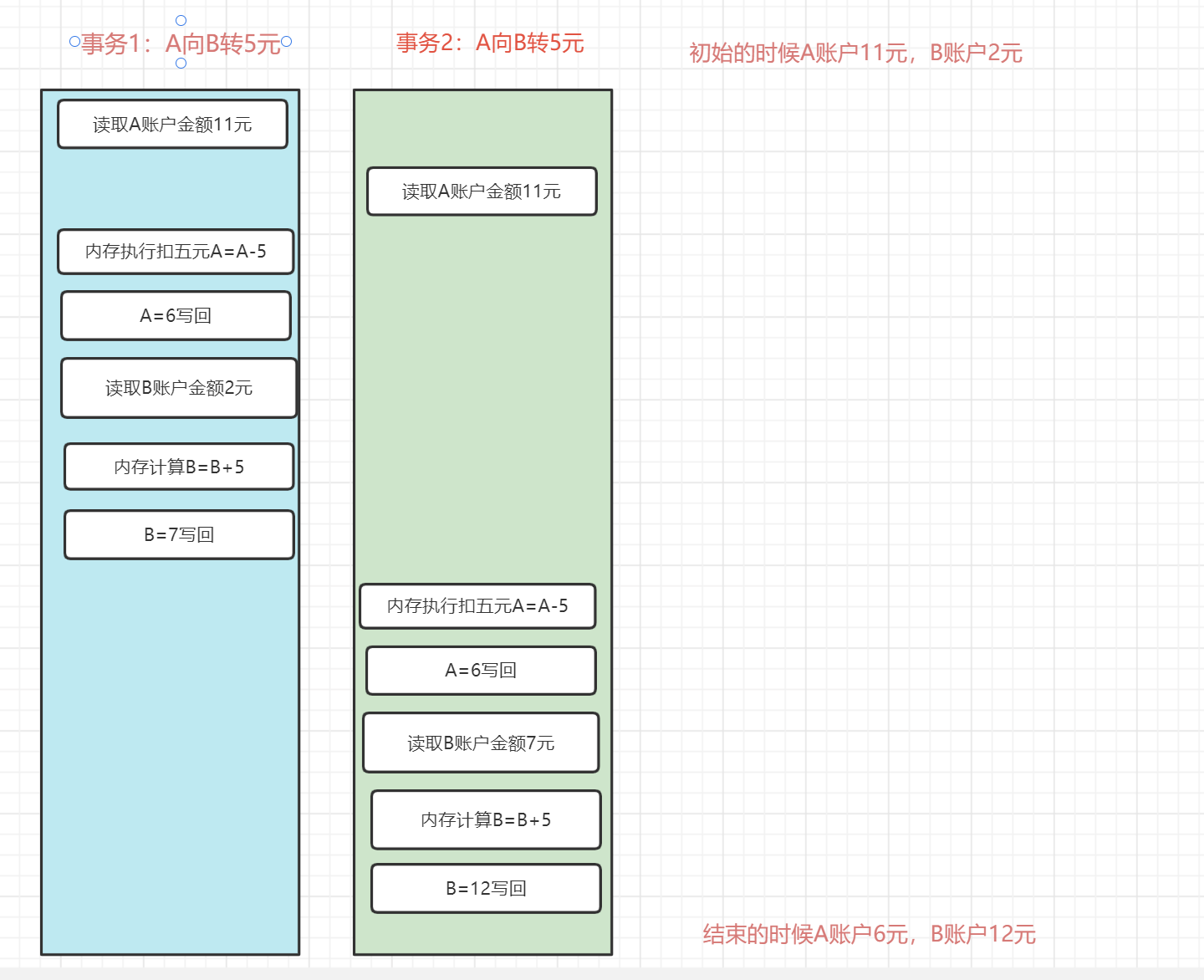
可以看到AB最開始總和13元,最後AB總和18元,銀行血虧五元,這顯然違背了一致性——錢的總量不變。這就是並行情況下兩個事務的影響,所以需要事務隔離讓事務隔離的進行,互不干涉。
1.實現事務隔離的方式:序列執行
最簡單直接的方式,同一時間只能有一個事務執行,這樣必然不會有上述不一致的情況,但是大大降低了吞吐率並增加了事務的等待時間
2.實現事務隔離的方式:可序列執行
並行事務之所以出現不一致的情況,就是由於多個事務存取相同的資料,需要實現多個事務在存取相同資料的時候進行限制,比方說上圖中事務2想存取A賬戶的值需要等待事務提交事務之後,這樣可以讓並行事務的執行如同序列執行的效果一樣。
二丶並行事務執行的問題:髒寫,髒讀,不可重複讀,幻讀
1.髒寫
一個事務修改了另外一個未提交事務修改過的資料
-
髒寫導致一致性無法保證

上圖事務A和事務B都更新紫色資料,其中事務A首先更新為A,然後事務B過來更新為B,這時候事務A回滾後更新為Null,事務 B 明明正常寫了一行資料,但是寫完之後發現值變了,有點丟失更新的意思。(比如A表示餘額,這時候在將餘額A判斷是否足以支付,判斷得到可以,事務B執行扣費寫入A-5,商家收到5元,結果這時候回滾了,A變成Null,事務A中轉錢的一方錢變為A,錢的總額變為A+5了)
-
髒寫導致原子性受到破壞
假如上述的事務B還操作了另外的資料,比如插入一條資料C,並且更改為B寫入C是在一個事務下面的,需要具備原子性,但是髒寫讓B的更改需要部分回滾為Null,這樣插入C和更改B就不具備原子性(比如A表示餘額,這時候在將餘額A判斷是否足以支付,判斷得到可以,事務B執行扣費寫入A-5,商家收到5元,結果這時候回滾了,A變成Null,這時候部分回滾,商家的5元沒用回滾,商家的庫存也沒用回滾,原子性被破壞)
2.髒讀
如果一個事務讀取到另外一個事務未提交的資料,意味著發生了髒讀

比如事務A先寫資料A,然後事務B督導資料A後在記憶體中使用A進行一系列操作(比如A表示餘額,這時候在將餘額A判斷是否足以支付,判斷得到可以)但是事務A這時候回滾了,事務B再次讀取資料發現為null,這就是髒讀。
髒讀可能引發一致性的問題:比如事務操作時修改x和y的值,並且二者總是相等的,A修改x為1,還沒來得及修改y也沒用提交事務,這時候事務B讀取x=1,y=0,二者不等,事務B讀取到了資料庫不一致的狀態,讀取到未提交事務的值
3.不可重複讀
假如一個事務修改了另外一個事務未提交的資料,意味發生了不可重複讀

比如事務A第一次讀取到值為A,接著事務B修改為B,並且提交了事務B,然後事務A再次讀取得到的資料是B,同一行資料多次讀取值並不相同,這稱作不可重複讀。它是指在同一個事務裡面查詢同一行資料,每次查到的資料都不一樣。和髒讀區別在於髒讀是由於別的事務回滾導致,而不可重複讀讀到的其實是已經提交的資料。
事務A讀到事務B提交後的資料似乎很合理,但是我們想象這樣一種場景:你有一個流水錶和使用者餘額,其中記錄使用者每天的流水,你在月初0點的時候核對流水和庫存,但是流水很多,你的程式選擇一個一個使用者的進行核對,核對使用者甲,甲沒做任何消費,但是當你核對B的時候,你將B的流水load到記憶體中,但是B這時候(0點30分,這一筆資料新的一個餘額)進行了扣除餘額的操作,導致B餘額和流水對不上了。
4.幻讀
如果一個事務A先根據沒用搜尋條件查詢到一些記錄,在該事務未提交前,另外一個事務寫入(delete,update,insert)了符合搜尋條件的記錄,這時候事務A再次讀取,發現資料條數和第一次讀取的不同,如同出現了幻覺,稱之為幻讀

事務A讀到事務B提交後的資料似乎很合理,但是我們想象這樣一種場景:你有一個需求將會公司的男性員工了女性員工查詢進行展示,你先查詢了總數為100人,然後查詢男性的總數50人,後查詢女性人數準備在頁面展示共100人,其中男50人,女50人,結果這是管理資訊的人發現有一位員工性別錯誤錄入了,將其從男修改為女,這時候你讀取事務就是女51人了,你在主頁顯示了共100人,其中男50人,女51人
三丶隔離級別
1.Read UnCommitted 讀未提交
在此隔離級別下,會發生髒讀,不可重複讀,和幻讀
2.Read Committed 讀已提交
在此隔離級別下,會發生不可重複讀,和幻讀
3.Repeatable Read 可重複讀
在此隔離級別下,可能發生幻讀
4.Serializable 可序列化
在此隔離級別下,不會發生髒讀,不可重複讀,和幻讀
其中髒寫是對一致性影響最嚴重的,無論是何種隔離級別,都不允許髒寫發生,innodb使用鎖保證不會出現髒寫現象,第一個事務更新某條記錄的時候,會給這條記錄加鎖,另外一個事務在此更新的時候,需要等待第一個事務提交釋放鎖後更新。隔離級別越高,其並行能力越低。
四丶Mysql設定隔離級別
預設隔離級別可重複讀
1.設定全域性隔離級別
SET GLOBAL TRANSACTION ISOLATION LEVEL 期望的隔離級別(可選READ UNCOMMITED,READ COMMITED,REPEATABLE READ,SERIALIZABLE),此命令只對執行語句後新產生的對談有效,對當前已經存在的對談無效
2.設定對談隔離級別
SET SESSION TRANSACTION ISOLATION LEVEL 期望的隔離級別(可選READ UNCOMMITED,READ COMMITED,REPEATABLE READ,SERIALIZABLE),對當前對談後續事務有效,該語句可以在已開啟的事務中執行,但是不會影響當前正在執行的事務,如果在事務之間執行,只會對後續的事務有效
3.設定下一個事務的隔離級別
SET TRANSACTION ISOLATION LEVEL 期望的隔離級別(可選READ UNCOMMITED,READ COMMITED,REPEATABLE READ,SERIALIZABLE) 只對當前對談的下一個即將開啟的事務有效,下一個事務執行完後,後續事務將恢復到之前的隔離級別,該語句不能再已經開啟的事務中執行,否則會報錯。
4.指定伺服器的隔離級別
在啟動的時候使用--transaction-isolation=xxx即可執行預設隔離級別
五丶MVCC原理
下面討論記錄對當前事務是否可見都是基於當前事務中執行的查詢是快照讀(普通查詢),對於當前讀(select xxx for update,select xxx lock in share mode)是不通用的
1.版本鏈
對於InnoDB儲存引擎來說,其聚簇索引記錄中包含兩個隱藏列:
trx_id:一個事務每次對聚簇索引記錄做出改動的時候,都會把該事務的事務id複製給此列roll_point:每次對某條聚簇索引記錄進行改動的時,都會把舊的版本寫入到undo 紀錄檔中,此列相當於一個指標,指向修改前的資訊
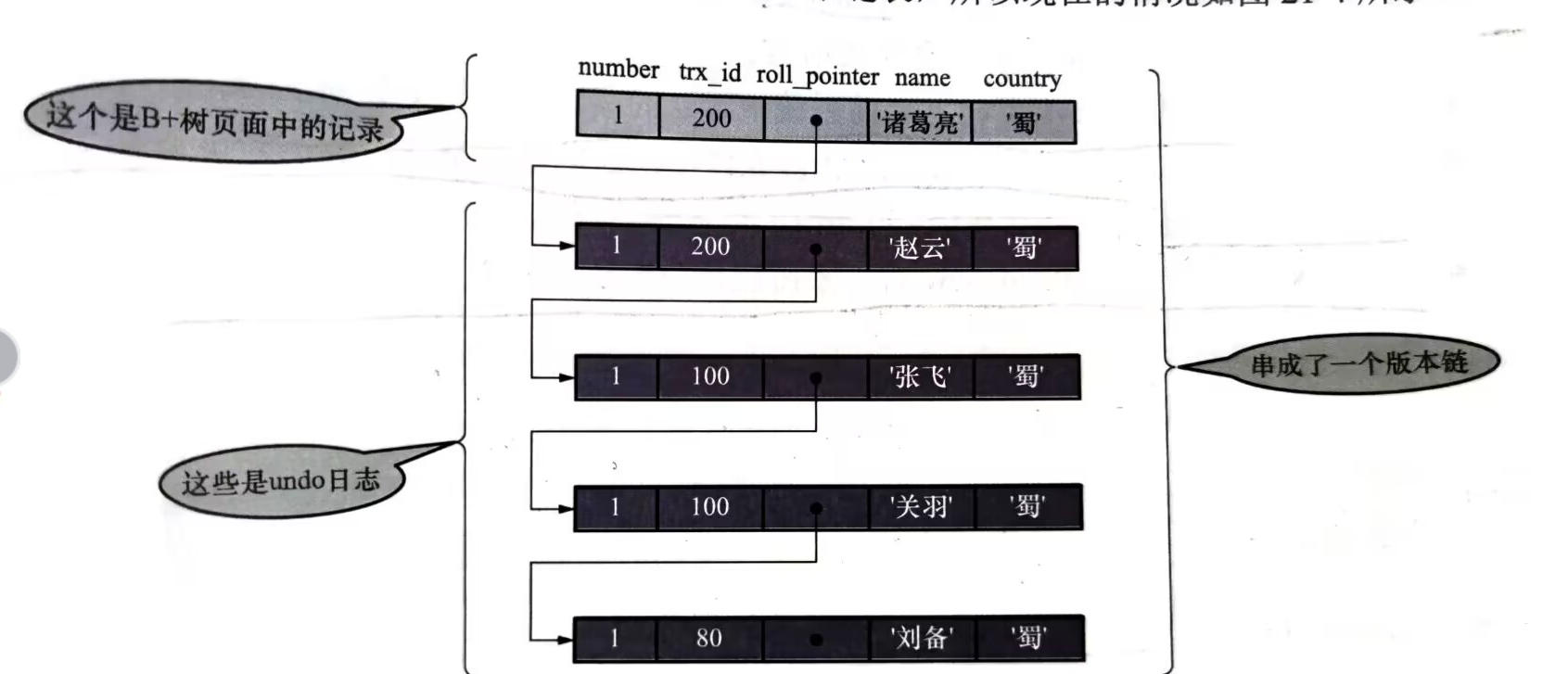
每次修改都會形成Undo 紀錄檔,所有版本的資料會通過roll_point串聯成一個連結串列,稱之為版本鏈,頭節點是當前記錄的最新值。利用版本鏈控制多個並行事務存取相同記錄時的行為稱為MVCC多版本並行控制。
其實在undo紀錄檔中,只記錄被更新列的資訊,而不是記錄全部的資訊,對於沒有記錄的列,會通過版本鏈找少一個版本中的對應列的資訊,直到找到聚簇索引葉子節點中的內容
2.Read View
對於使用Read Uncommitted隔離級別的事務,可以讀取到沒提交的資料,那麼直接讀取最新的版本即可。對於Serializable隔離級別,innodb直接通過加鎖來存取記錄。對於read committed 和 repeatable read隔離級別的事務,都必須保證督導的資料是已經提交事務修改過的記錄,那麼如何判斷版本鏈中的哪個版本的資料是當前事務可見的暱?
innodb 使用的Read View
2.1 read view 的結構
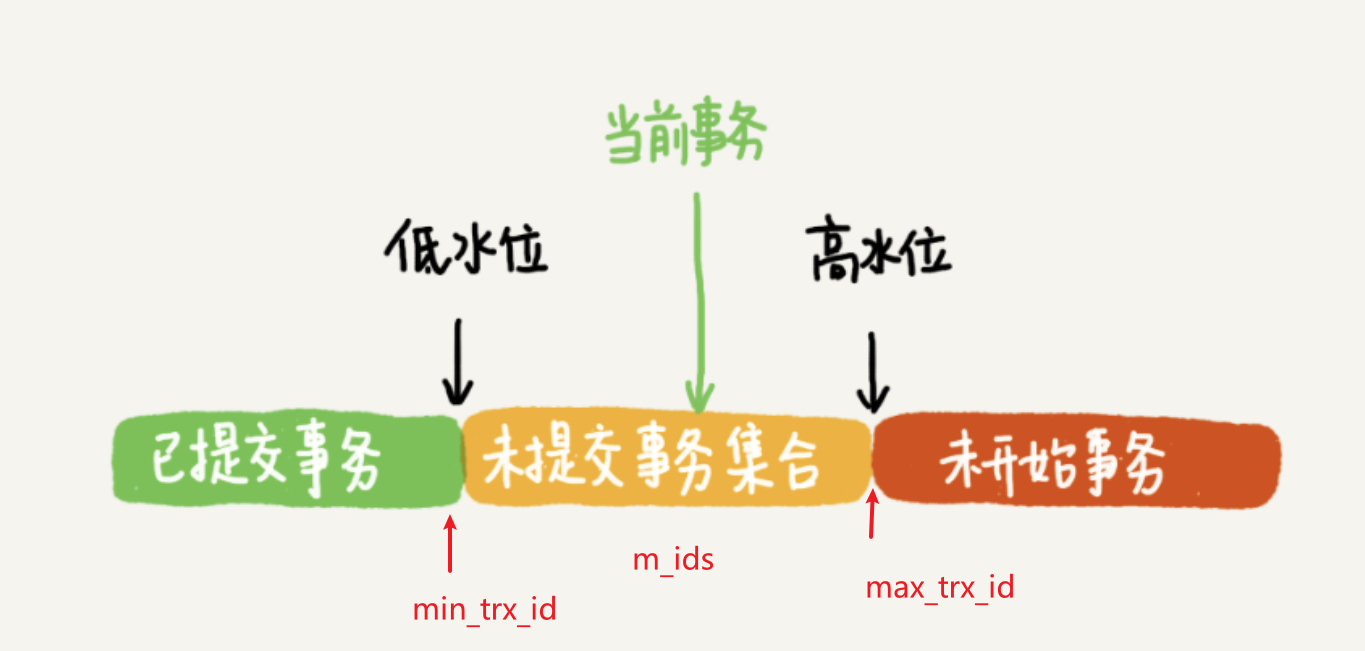
- m_ids:在生成read view時,當前系統中活躍的讀寫事務id列表
- min_trx_id:生成read view時,當前系統中活躍的讀寫事務中最西澳的事務id,也就是m_ids中的最小值
- max_trx_id:生成read view時,系統應該分配給下一個事務的事務id值
- creator_trx_id:生成該read view的事務的事務id
2.2 read view 判斷某個版本當前事務釋放可見的步驟
- 如果被存取版本的
trx_id和creator_trx_id相同,意味著當前事務在存取自己修改的記錄,自然可見 - 如果存取版本的
trx_id屬性值小於read view中的min_trx_id表明此版本是生成read view之前已經提交的事務,那麼自然可見 - 如果存取版本的
trx_id,大於等於read view中的max_trx_id說明,當前版本資料是生成read view後開啟事務產生的,那麼自然不可見 - 如果存取版本的
trx_id介於min_trx_id和max_trx_id之間,需要判斷trx_id是否位於m_ids列表中,如果在說明建立read view時生成該版本的事務還是活躍的,那麼該版本,不可被存取,如果不在說明建立read view 時生成該版本的事務已經提交,可以被存取到
如果某個版本資料對當前事務不可見那麼需要一直順著版本鏈找上一個版本的資料,並通過上述步驟判斷是否可見,直到找到可見的版本,如果一直找不到說明該條記錄對當前事務不可見,查詢結果將不包含該記錄。
2.3 Read Committed和 Repeatable Read的不同
-
Read Committed——每次讀取資料前都生成一個Read View
這樣可以保證生成Read view 中的m_ids是實時活躍事務id集合,也許第一次讀取的時候事務A沒提交,其id位於m_ids中,但是第二次讀取的時候事務A提交了,事務A將不位於m_ids中,這樣在第二次讀取的時候,通過m_ids判斷事務A是否提交的時候,可以得到事務A已經提交了,然後讓事務A版本產生的資料可見(見2.2.4中的內容)。
-
Repeatable Read——如果使用begin開啟事務那麼在第一次查詢的時候生成Read view,如果使用
start transaction with consistent snapshot那麼執行的時候就會生成read view這樣可以保證當前事務從頭到尾都是read view中記錄的內容是一致的,第一次讀取的時候事務A沒有提交,那麼不可見,但是第二次讀取的時候事務A提交了,但是read view的
m_ids和max_trx_id可以判斷事務A不可見,比如事務A事務id小於max_trx_id意味著生成read view是事務A啟動但是沒提交,即使第二次讀事務A提交了,但是m_ids中還是包含事務A,那麼不可見。如果事務A事務id大於max_trx_id,那麼自然第二次還是大於max_trx_id,也是不可見的,從而實現了可重複讀。
2.4 二級索引與MVCC
上面我們提到,innodb聚簇索引組織的記錄才具備trx_id和roll_point,那麼我們使用二級索引進行查詢的時候,如何判斷資料是否可見暱?
- 二級索引頁面的page header中存在page_max_trx_id屬性,每當有事務對其中的記錄進行增刪改查操作的時候,如果事務的事務id,大於page_max_trx_id,那麼會更新page_max_trx_id屬性值為其事務id,這意味著page_max_trx_id記錄了修改該二級索引頁面最大的事務id是多少。當select通過二級索引首先看下對於read view的min_trx_id是否大於該頁面的page_max_trx_id,如果大於那麼頁面中所有記錄都對該read view可見,否則就進行下面的第二步
- 利用二級索引中的主鍵值,進行回標,得到對應的聚簇索引記錄然後進行回表,然後通過2.2中步驟拿到第一個可見版本的資料,然後比對此紀錄和通過二級索引查詢得到記錄的值是否相同,如果相同那麼傳送給使用者端,否則跳過該記錄。