雲原生在各大廠的落地與分析
隨著k8s成為事實上的容器編排標準,在容器編排上很難說有嚴格意義上的競品,各大廠雲平臺也幾乎是對k8s進行外掛開發、或是其核心元件進行二次開發,而不是對k8s的架構進行更改(其本身架構已足夠優秀)。這樣既既符合社群的期望、也降低了開發人員門檻。
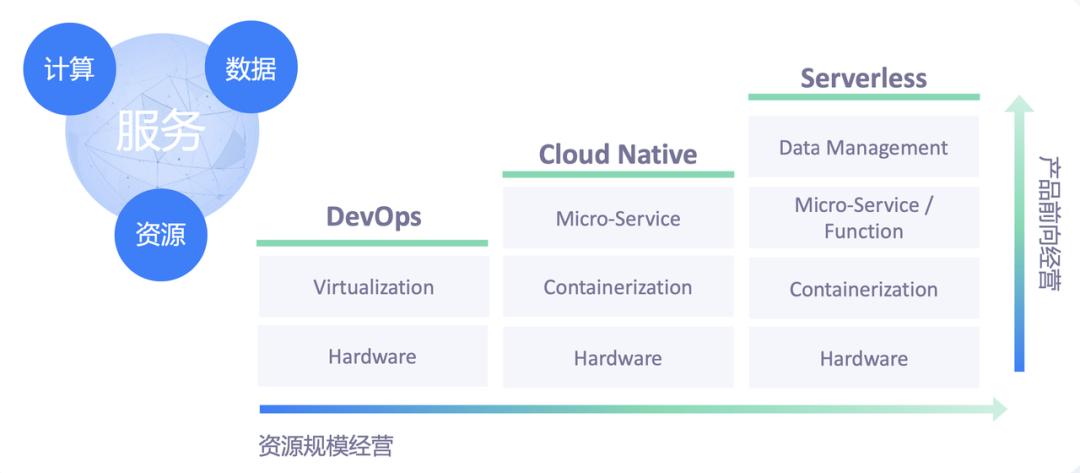
雲原生的概括(參照自位元組跳動雲原生)
雲原生相近的技術體系分成了 DevOps、Cloud Native 以及 Serverless 三代。
- DevOps:更多強調管理和運維的自動化。主流的服務開發模式是以虛擬機器器作為底層的資源抽象模型,以 Jenkins 之類的一些自動化管理平臺來部署單體應用,進而實現運維管理自動化;
- Cloud Native:以微服務模式為主。在資源方面以容器作為更小、更靈活的資源交付單元,輔以 Kubernetes 等容器編排引擎,來管理服務的部署和運維。開發者的效率得到了更大的釋放,極大增加了業務產品自身的迭代效率;
- Serverless:開發者以函數或者極度簡化的微服務程式碼來表達自身的業務邏輯,以事件作為資料模型來表達服務上下游之間的請求和響應。把容量管理、請求路由和服務治理等運維層面的需求下沉到底層的基礎設施來統一支援,服務開發者只需聚焦在自己的業務邏輯上。開發和生產的效率會進一步提升。
這三代技術總體是沿著兩個路徑在往前推進,分別是產品前向一體化,以及資源規模化。這兩種思路從兩個角度分別推動著技術體系的演進。
- 產品前向一體化:這種思路的核心是如何標準化地把業務的計算邏輯、資料管理模型、資源管理等方面的共性需求抽取出來,沉澱到基礎設施當中,使得開發者可以用更少、更簡潔的程式碼高效表達自身的需求;
- 資源規模化:這種思路更多體現在優化上,關注資源池本身的規模化優勢,通過大量的並池、資源的混用以及排程等優化手段,實現資源成本降低的目的。
從技術體系迭代來看,位元組跳動技術體系往後迭代方向可以總結為下面的主題:
- 無需管理的基礎設施
- 自動擴充套件和伸縮
- 提升開發效率
- 提升資源效率
- 按需付費,節省成本
我們希望朝這些主題方向努力,最終形成下一代的 Serverless 基礎設施。
過去各公司的迭代
位元組——16年開始的虛擬化、容器化,直接上的k8s。
美團——16年自研(驗證容器可行性)到18擁抱k8s。
攜程——2017基於Mesos上的自研排程器到18年K8s fork版本的排程器。
基礎架構部門——之前基於自研引擎Raw-Docker,22年擁抱k8s。
本部門——由於前人的積累的經驗,20年選擇了k8s作為上雲的基本元件。
同期的公司都做了什麼?
統一排程接入能力優化
攜程
演演算法集引數化設定
Pod所屬的業務型別不同,對Pod的排程演演算法選取以及權重引數等可能不同。
解決方案:
增強了排程器Policy機制,引入了PolicyCacheProvider物件。
親和性引數化設定
多維度的親和性需求使業務方會涉及過多底層實現細節,導致其心智負擔過重。
解決方案:
對NodeAffinity/PodAffinity進行了PolicyTemplate的CRD抽象,分別提煉出NodeSchedulerConfig和PodSchedulerConfig以及SchedulerConfigBinding物件。
Pod在建立時,會由sched-webhook根據繫結的Policy,更新Pod Spec。因此,業務方在使用時,不必再自己組裝Pod Spec中的細節,可以直接通過Annotation指定預設好的Pod的親和性排程規則,平臺管理員也可以通過建立Binding物件透明改變Pod的排程行為。
美團
kube-scheduler效能優化
如果有上萬臺 Node節點,預選、優選和選定判斷邏輯會浪費很多計算時間,這也是排程器效能低下的一個重要因素。
解決方案:
提出了「預選失敗中斷機制」,即一旦某個預選條件不滿足,那麼該 Node即被立即放棄,後面的預選條件不再做判斷計算,從而大大減少了計算量,排程效能也大大提升。(Kubernetes1.10版本釋出並開始作為預設的排程策略)
kubelet風險可控性改造
穩定性和風險可控性對大規模叢集管理來說非常重要。從架構上來看,Kubelet是離真實業務最近的叢集管理元件,社群版本的Kubelet對本機資源管理有著很大的自主性,試想一下,如果某個業務正在執行,但是Kubelet由於出發了驅逐策略而把這個業務的容器幹掉了會發生什麼?這在叢集中是不應該發生的,所以需要收斂和封鎖Kubelet的自決策能力,它對本機上業務容器的操作都應該從上層平臺發起。
解決方案:
容器重啟策略
Kernel升級是日常的運維操作,在通過重啟宿主機來升級Kernel版本的時候,發現宿主機重啟後,上面的容器無法自愈或者自愈後版本不對,這會引發業務的不滿,也造成了不小的運維壓力。後來為Kubelet增加了一個重啟策略(Reuse),同時保留了原生重啟策略(Rebuild),保證容器系統磁碟和資料盤的資訊都能保留,宿主機重啟後容器也能自愈。
IP狀態保持
根據美團點評的網路環境,自研了CNI外掛,並通過基於Pod唯一標識來申請和複用IP。做到了應用IP在Pod遷移和容器重啟之後也能複用,為業務上線和運維帶來了不少的收益。
限制驅逐策略
知道Kubelet擁有節點自動修復的能力,例如在發現異常容器或不合規容器後,Kubelet會對它們進行驅逐刪除操作,這對於美團來說風險太大,美團允許容器在一些次要因素方面可以不合規。例如當Kubelet發現當前宿主機上容器個數比設定的最大容器個數大時,會挑選驅逐和刪除某些容器,雖然正常情況下不會輕易發生這種問題,但是也需要對此進行控制,降低此類風險。
可延伸性
解決方案:
資源調配
在Kubelet的擴充套件性方面增強了資源的可操作性,例如為容器繫結Numa從而提升應用的穩定性;根據應用等級為容器設定CPUShare,從而調整排程權重;為容器繫結CPUSet等等。
增強容器
打通並增強了業務對容器的設定能力,支援業務給自己的容器擴充套件ulimit、io limit、pid limit、swap等引數的同時也增強容器之間的隔離能力。
應用原地升級
大家都知道,Kubernetes預設只要Pod的關鍵資訊有改動,例如映象資訊,就會出發Pod的重建和替換,這在生產環境中代價是很大的,一方面IP和HostName會發生改變,另一方面頻繁的重建也給叢集管理帶來了更多的壓力,甚至還可能導致無法排程成功。為了解決該問題,美團打通了自上而下的應用原地升級功能,即可以動態高效地修改應用的資訊,並能在原地(宿主機)進行升級。
演演算法優化
攜程
擴充套件的資源平衡演演算法
balanced_allocation沒有考慮其它維度的資源
解決方案:
攜程擴充套件了balanced_allocation演演算法,將更多資源加入計算過程,同時賦予不同資源不同的權重
水位感知的堆疊與打散演演算法
大量宿主機剩餘一些碎片不能被分配出去,特別是一些大設定的Pod無法排程成功
解決方案:
修改了策略,引入一個叢集整體資源水位的概念,用來切換打散策略和堆疊策略。
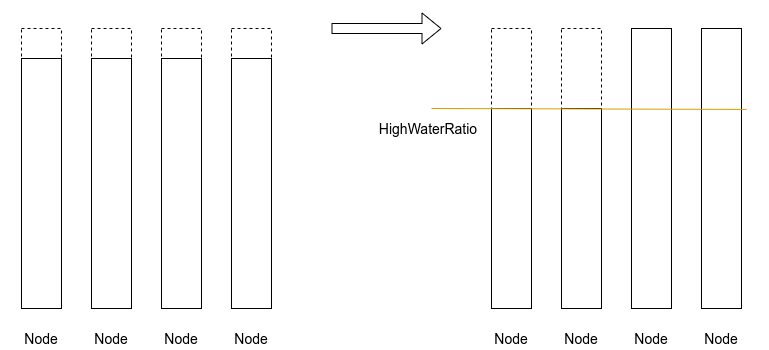
當整個叢集中已經被分配出去的資源佔總體資源的比例超過一個閾值,則切換為堆疊策略,這些「邊腳料」資源就能攢在一起,被充分利用。通過這種方式,在資源緊張的時期,美團私有云的分配率極限可以達到98%。
資源利用率的提升
位元組
線上 Web 服務和離線批式作業混合
解決方案:
在離線混合部署方案,通過單機多維度的資源隔離以及中心 + 節點兩級管控的策略,很好地支援了兩種服務進行並池嘗試。
線上算服務和離線訓練作業
解決方案:
採取了彈性並池方案,即在線上業務低峰的時段將線上資源進行縮容,騰出空閒的資源供給離線業務使用,從而實現資源的分享複用,提高資源利用效率。
美團
資源池的隔離
精細化的資源排程和運營,之所以做精細化運營主要是出於兩點考慮:業務的資源需求場景複雜,以及資源不足的情況較多。
美團依託私有云和公有云資源,部署多個Kubenretes叢集,這些叢集有些是承載通用業務,有些是為特定應用專有的叢集,在叢集維度對雲端資源進行調配,包括機房的劃分、機型的區分等。在叢集之下,又根據不同的業務需要,建設不同業務型別的專區,以便做到資源池的隔離來應對業務的需要。更細的維度,美團針對應用層面的資源需求、容災需求以及穩定性等做叢集層的資源排程,最後基於底層不同硬體以及軟體,實現CPU、MEM和磁碟等更細粒度的資源隔離和排程。
Numa感知與繫結
使用者的另一個痛點與容器效能和穩定性相關。美團不斷收到業務反饋,同樣設定的容器效能存在不小的差異,主要表現為部分容器請求延遲很高,經過測試和深入分析發現:這些容器存在跨Numa Node存取CPU,在將容器的CPU使用限制在同一個Numa Node後問題消失。所以,對於一些延遲敏感型的業務,要保證應用效能表現的一致性和穩定性,需要做到在排程側感知Numa Node的使用情況。
解決方案:
更加底層的軟硬體配合,在Node層採集了Numa Node的分配情況,在排程器層增加了對Numa Node的感知和排程,並保證資源使用的均衡性。對於一些強制需要繫結Node的敏感型應用,如果找不到合適的Node則擴容失敗;對於一些不需要繫結Numa Node的應用,則可以選擇儘量滿足的策略。
經驗心得
在容器時代,不能只看k8s本身,對於企業內的基礎設施,「向上」和「向下」的融合和相容問題也很關鍵。「向上」是面向業務場景為使用者提供對接,因為容器並不能直接服務於業務,它還涉及到如何部署應用、服務治理、排程等諸多層面。「向下」,即容器與基礎設施相結合的問題,這裡更多的是相容資源型別、更強大的隔離性、更高的資源使用效率等都是關鍵問題。
- 落地以使用者痛點為突破口,業務是比較實際的,為什麼需要進行遷移?業務會怕麻煩、不配合,所以推進要找到業務痛點,從幫助業務的角度出發,效果就會不一樣。
- 內部的叢集管理運營的價值展現也是很重要的一環,讓使用者看到價值,業務看到潛在的收益,他們會主動來找你。
目前的存在問題&&未來的建設重點
資源池暫未很好的分化、區分
- 資源池化分級
暴露太多業務方不關心的設定
- CRD(Custom Resource)客製化資源與 Operator
服務沒有優先順序。
- 任務優先順序分級
解決資源利用率與服務質量的矛盾
-
不同的層次上進行優先順序的分類
-
自定義合適的在離線混部驅逐策略策略