通過硬體計數器,將效能提升3倍之旅
通過硬體計數器,將效能提升3倍之旅
翻譯自:Seeing through hardware counters: a journey to threefold performance increase
本文通過對CPU層面的程式碼挖掘,發現JVM存在的問題,並通過對JVM打修補程式的方式解決了大範例下效能不足的問題。
在前面的文章中,我們概述了可觀測性的三大領域:整體範圍,微服務和範例。我們描述了洞察每個領域所使用的工具和技術。然而,還有一類問題需要深入到CPU微體系架構中。本文我們將描述一個此類問題,並使用工具來解決該問題。
問題概述
問題起始於一個常規遷移。在Netflix,我們會定期對負載進行重新評估來優化可用容量的利用率。我們計劃將一個Java微服務(暫且稱之為GS2)遷移到一個更大的AWS範例上,規格從m5.4xl(16 vCPU)變為m5.12xl(48 vCPU)。GS2是計算密集型的,因此CPU就成為了受限資源。雖然我們知道,隨著vCPU數量的增長,吞吐量幾乎不可能實現線性增長,但可以近線性增長。在大型範例上進行整合可以分攤後臺任務產生的開銷,為請求留出更多的資源,並可以抵消亞線性縮放。由於12xl範例的vCPU數是4xl範例的3倍,因此我們預期每個範例的吞吐量能夠提升3倍。在快速進行了一次金絲雀測試後發現沒有發現錯誤,並展示了更低的延遲,該結果符合預期,在我們的標準金絲雀設定中,會將流量平均路由到執行在4xl上的基準以及執行在12xl上的金絲雀上。由於GS2依賴 AWS EC2 Auto Scaling來達到目標CPU利用率,一開始我們認為只要將服務重新部署到大型範例上,然後等待 ASG (Auto Scaling Group)達到目標CPU即可,但不幸的是,一開始的結果與我們的預期相差甚遠:
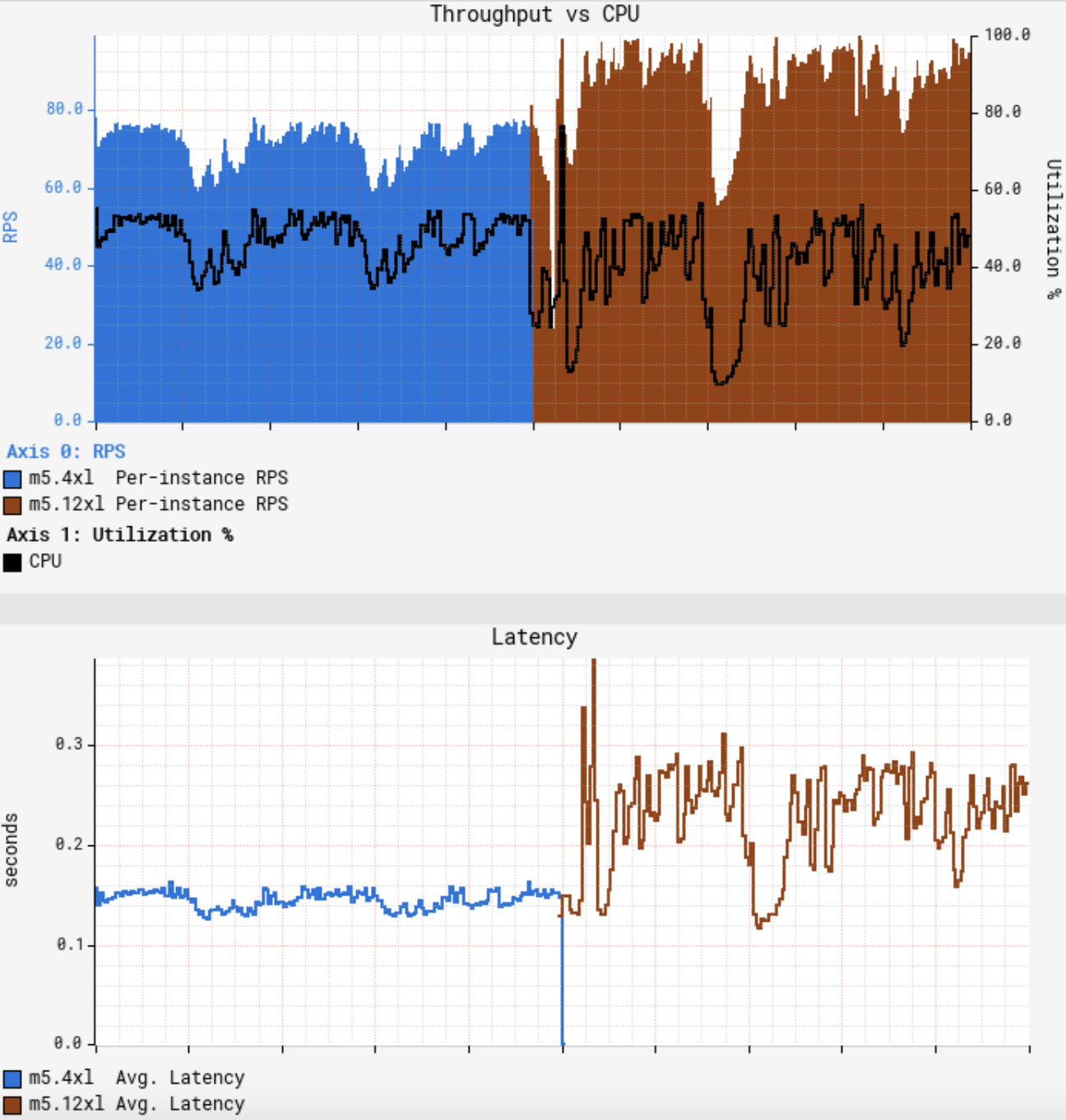
此時CPU和延遲展示了相似的曲線,慢波段節點消失不見。
True Sharing
隨著自動擴容達到CPU目標,但我們注意到單個節點仍然無法處理超過150RPS,而我們的目標是250RPS。針對修補程式版本的JDK進行的又一輪vTune效能取樣,發現圍繞二級父類別的快取查詢出現了瓶頸。在經過修補程式之後又出現了相同的問題,一開始讓人感到困惑,但在仔細研究後發現,現在我們使用的是true sharing,與false sharing不同,兩個獨立的變數共用了一個cache line,true sharing指相同的變數會被多執行緒/core讀寫。這種情況下,CPU強制記憶體排序是導致速度減慢的原因。我們推斷,消除false sharing並提高了總吞吐量會導致增加相同JVM父類別快取程式碼路徑的執行次數。本質上,我們有更高的執行並行性,但由於CPU強制記憶體排序協定,導致父類別快取壓力過大。通常的解決方式是避免一起寫入相同的共用變數,這樣就可以有效地繞過JVM的輔助父類別快取。由於此變更改變了JDK的行為,因此我們使用了命令列標誌,完整的修補程式如下:
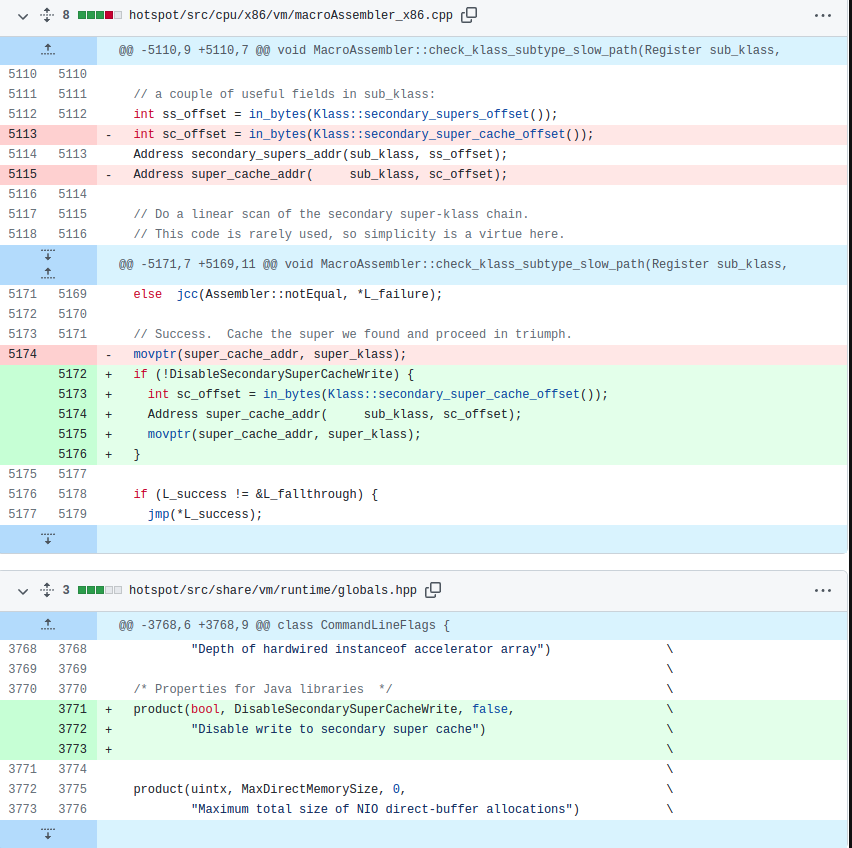
在禁用父類別快取寫操作之後的結果如下:
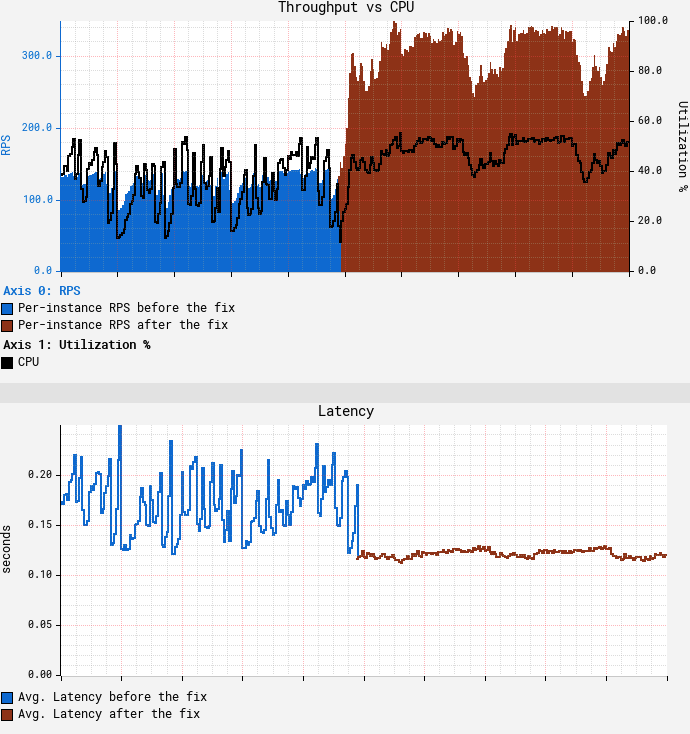
可以看到在CPU達到目標55%的情況下,吞吐量達到了350 RPS,是我們一開始使用m5.12xl的吞吐量的3.5倍,同時降低了平均和尾部延遲。
後續工作
在我們的場景下,禁用寫入二級父類別快取工作良好,雖然這並不一定適用於所有場景,但過程中使用到的方法,工具集可能會對遇到類似現象的人有所幫助。在處理該問題時,我們碰到了 JDK-8180450,這是一個5年前的bug,它所描述的問題和我們遇到的一模一樣。諷刺的是,在真正找到答案之前,我們並不能確定是這個bug。
總結
我們傾向於認為現在的JVM是一個高度優化的環境,在很多場景中展示出了類似C+++的效能。雖然對於大多數負載來說是正確的,但需要提醒的是,JVM中執行的特定負載可能不僅僅受應用程式碼的設計和實現的影響,還會受到JVM自身的影響,本文中我們描述瞭如何利用PMC來發現JVM原生程式碼的瓶頸,對其打修補程式,並且隨後使負載的吞吐量提升了3倍以上。當遇到這類效能問題時,唯一的解決方案是在CPU微體系結構層面進行挖掘。intel vTune使用PMC提供了有價值的資訊(如通過m5.12xl範例型別暴露出來的資訊)。在雲環境中跨所有範例型別和大小公開一組更全面的PMC和PEBS可以為更深入的效能分析鋪平道路,並可能獲得更大的效能收益。
本文來自部落格園,作者:charlieroro,轉載請註明原文連結:https://www.cnblogs.com/charlieroro/p/16880090.html