解密負載均衡技術和負載均衡演演算法
什麼是負載均衡技術
負載均衡器是一種軟體或硬體裝置,它起到了將網路流量分散到一組伺服器的作用,可以防止任何一臺伺服器過載。負載均衡演演算法就是負載均衡器用來在伺服器之間分配網路流量的邏輯(演演算法是一組預定義的規則),有時候也叫做負載均衡的型別。負載均衡演演算法的種類非常多,包括從簡單的輪詢負載均衡演演算法到基於響應狀態資訊的自適應負載均衡演演算法。
負載均衡演演算法的選擇會影響負載分配機制的有效性,從而影響效能和業務連續性(也就是對外承諾的SLA),選擇正確的負載均衡演演算法會對應用程式效能產生重大影響。
本文將會介紹常見的負載均衡演演算法,並結合主流負載均衡軟體或硬體裝置介紹各種負載均衡演演算法的實現方式
常見負載均衡演演算法介紹
Round Robin(輪詢負載均衡演演算法)
在所有負載均衡演演算法中,輪詢負載均衡演演算法是最簡單的、最常用的負載均衡演演算法。使用者端請求以簡單的輪換方式分發到應用程式伺服器上。例如,假設有三臺應用程式伺服器:第一個使用者端請求傳送到第一臺應用程式伺服器,第二個使用者端請求傳送到第二臺應用程式伺服器,第三個使用者端請求傳送到第三臺應用程式伺服器,第四個使用者端請求重新從第一臺應用程式伺服器開始,依次往復。
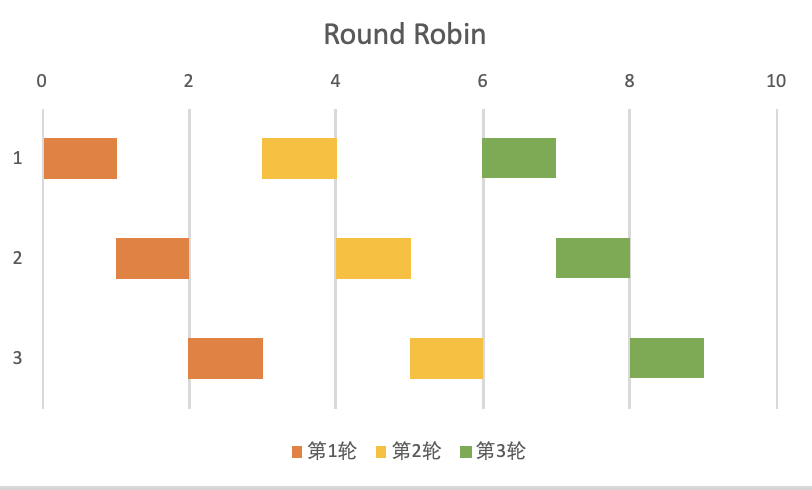
輪詢負載均衡適合所有使用者端請求都需要相同的伺服器負載,並且所有的伺服器範例都具有相同的伺服器容量和資源(比如網路頻寬和儲存)
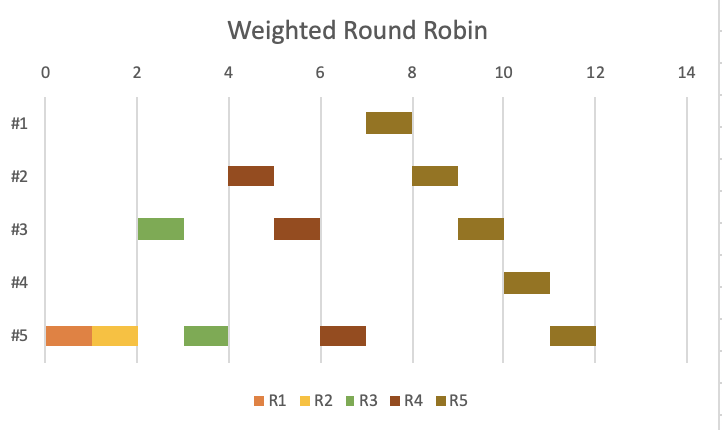
Weighted Round Robin(加權輪詢負載均衡演演算法)
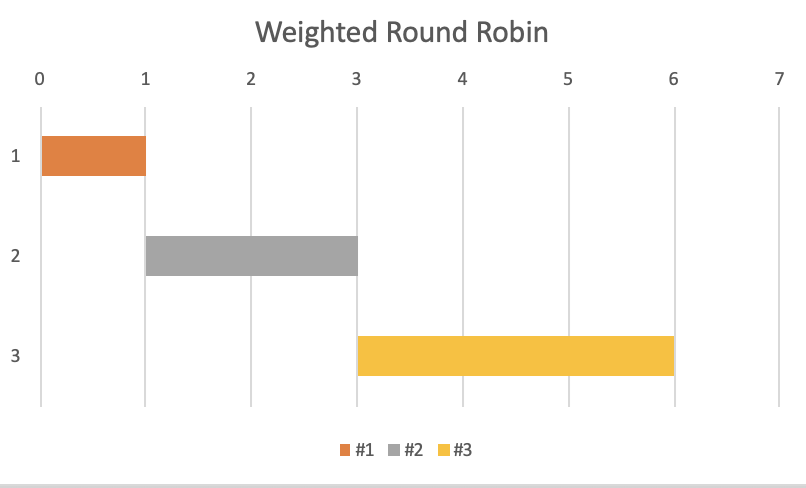
加權負載均衡演演算法與輪詢演演算法相似,增加了根據每個伺服器的相對容量來將請求分散到不同伺服器的能力。它適合將傳入的使用者端請求分散到一組具有不同功能或具有不同負載容量的伺服器上。伺服器叢集管理員根據一個標準為每個應用程式伺服器分配一個權重,這個標準表示每個伺服器對請求的相對處理能力。
例如,如果在其他資源都是無窮多的情況下,假如伺服器#1的CPU核心數是伺服器#2和伺服器#3的CPU核心數的二倍,那麼伺服器#1的權重更高,而伺服器#2和#3的權重相同(都比#1低)。如果我們有4個連續的使用者端請求,那麼有2次請求傳送到#1,另外2次請求分別傳送到#2和#3。
加權輪詢負載均衡演演算法描述的是在一段時間內負載的分佈情況,不同的加權輪詢負載均衡演演算法可能會產生不同的選擇序列,不應該對處理下一次負載的伺服器進行假設。
Least Connections(最少連線負載均衡演演算法)
最少連線負載均衡演演算法又叫做最少等待請求演演算法(Least Outstanding Request, LOR)。最少連線負載均衡是一種動態負載均衡演演算法,使用者端請求被分發到在接收到請求時活動連線數最少的應用伺服器。在應用伺服器具有類似規格的情況下,一臺伺服器可能會因為連線數過多而過載(無法接收請求也屬於過載),這個演演算法考慮了活動連線負載。這種技術適合具有不同連線時間的傳入請求(多機房)以及一組在處理能力和可用資源方面相對相似的伺服器。
Weighted Least Connections(加權最少連線負載均衡演演算法)
加權最少連線建立在最少連線負載均衡演演算法上,考慮不同的應用程式伺服器特性。與加權輪詢負載均衡演演算法相同,伺服器叢集管理員根據一個標準為每個應用程式伺服器分配一個權重,這個標準表示每個伺服器對請求的相對處理能力。負載均衡器根據活動連結和分配的伺服器權重做出負載平衡決策(例如,使用連線數乘以權重的倒數,選擇值最高的伺服器)。
Resource Based(基於資源的負載均衡演演算法)
基於資源的負載均衡演演算法又叫做自適應負載均衡演演算法。基於資源的負載均衡演演算法根據後端伺服器提供的狀態指標來做出決策。這個狀態指標可以由一個執行在伺服器上的自定義應用程式(比如agent),或從基礎設施提供方的開放介面獲取。負載均衡器定期查詢每臺伺服器的狀態指標,然後適當地調整伺服器的動態權重。
在這種方式下,負載均衡演演算法實際上是在每臺真實伺服器上執行健康檢查。這個演演算法適用於任何需要來自每臺伺服器的詳細健康檢查資訊來做出負載均衡決策的情況。
例如:此演演算法適用於工作負載多變且需要詳細的應用程式效能和狀態來評估伺服器執行狀態的任何應用程式(例如CPU密集型的最短路徑計算,或其他高效能運算場景)。
Fixed Weighting(固定權重負載均衡演演算法)
固定權重負載均衡演演算法允許伺服器叢集管理員根據他們的標準為每個應用程式伺服器分配一個權重,以表示每個伺服器的相對流量處理能力。權重最高的應用伺服器將接收所有流量。如果權重最高的應用伺服器出現故障,所有流量將會被引導到下一個權重最高的應用伺服器。此方法適用於單個伺服器能夠處理所有預期傳入請求的工作負載,如果當前活動的伺服器發生故障,一個或多個「熱備用」伺服器可以直接用於承擔負載。
Weighted Response Time(加權響應時間負載均衡演演算法)
加權響應時間負載均衡演演算法使用應用程式的響應時間來計算伺服器權重。響應速度最快的應用程式伺服器接收下一個請求。此方法適用於應用程式響應時間是最重要的問題的場景。
當應用程式提供的是對外開放服務時尤為重要,因為對外開放服務都會為合作伙伴提供服務級別協定(Service Level Argument,SLA),而SLA中承諾的主要就是服務的可用性與服務的響應時間(TP99、TP999等)。
Source IP Hash(源地址雜湊負載均衡演演算法)
源地址雜湊負載均衡演演算法使用使用者端請求的源IP與目標IP地址生成唯一的雜湊金鑰,用於將使用者端請求分配給特定的伺服器。如果傳輸層對談中斷,可以重新金鑰,因此使用者端請求將會被定向到它之前使用的統一伺服器。當用戶端對於每個連續連線始終返回到同一伺服器至關重要時,此方法最適用。
伺服器端研發經常接觸的資料庫事務就適用於此場景
Consistent Hash(一致性雜湊負載均衡演演算法)
一致性雜湊負載均衡演演算法類似於源地址雜湊,不同在於一致性雜湊負載均衡演演算法可以使用任意應用引陣列成唯一的雜湊金鑰,並且當伺服器叢集發生變化時可以儘可能少地進行資料遷移。
常見負載均衡演演算法實現
本節將會介紹各種常見負載均衡演演算法的實現方式,某些負載均衡演演算法具有多種不同的實現方式,並且每種實現方式都有各自適用的場景,這些不同的實現方式也會在本節進行介紹。同時本節中會假設所有的請求都是線性的,不會處理並行安全相關的細節。
Round Robin(輪詢負載均衡演演算法)
在所有負載均衡演演算法中,輪詢負載均衡演演算法實現起來最簡單,只需要一個變數表示當前位置並不斷增加即可。
public class RoundRobinLoadBalancer { private final List instances; private int position; public RoundRobinLoadBalancer(List instances) { this.instances = instances; this.position = ThreadLocalRandom.current().nextInt(instances.size()); } public ServiceInstance peek(HttpServletRequest request) { int peeked = (position++) & Integer.MAX_VALUE; return instances.get(peeked % instances.size()); } }
這裡有兩個需要注意的點
-
當我們初始化位置時,需要將其設定為一個隨機值,避免多個負載均衡器同時請求同一個伺服器,造成伺服器的瞬時壓力
-
在位置自增時,需要忽略符號位,因為Java沒有無符號整數,所以當位置的值超出整型最大值時會變成負值導致丟擲異常。至於為什麼不能使用絕對值,是因為整型的最小值沒有對應的絕對值,得到的依舊是負值(Spring Cloud #1074)
Weighted Round Robin(加權輪詢負載均衡演演算法)
加權輪詢負載均衡演演算法有很多主流的實現,並且各自都有各自的優點。雖然加權負載均衡產生任意符合全總分配比例分佈的選擇序列都是合適的,但在短時間視窗內是否能夠選擇儘可能多的節點提供服務仍是評價加權負載均衡實現的質量的關鍵指標。
陣列展開方式
陣列展開實現方式是一種適用空間換時間的策略,適用於較小的伺服器叢集或專用型負載均衡裝置。它的優點是速度非常快,與Round Robin實現完全一致。它的缺點也很明顯,當權重的總和很大時會帶來很大的記憶體開銷
public class WeightedLoadBalancer { private final List instances; private int position; public WeightedLoadBalancer(List instances) { this.instances = expandByWeight(instances); } public ServiceInstance peek(HttpServletRequest request) { int peeked = (position++) & Integer.MAX_VALUE; return instances.get(peeked % instances.size()); } private List expandByWeight(List instances) { List newInstances = new ArrayList<>(); for (ServiceInstance instance : instances) { int bound = instance.getWeight(); for (int w = 0; weight < bound; weight++) { newInstances.add(instance); } } Collections.shuffle(newInstances); return newInstances; } }
這裡有三個需要注意的點:
-
當範例按權重展開成陣列的時候,可能會出現範例權重都很大,但是它們的最大公約數不為1,這個時候可以使用最大公約數來減少展開後的陣列大小。因為最大公約數的諸多限制,例如任意自然數N與N+1互質,任意自然數N與1互質,所以很容易出現優化失敗的情況,因此本範例並未給出,感興趣的可以去看Spring Cloud相關PR(Spring Cloud #1140)
-
在範例按權重展開成陣列後,需要對得到的陣列進行洗牌,以保證流量儘可能均勻,避免連續請求相同範例(Java中實現的洗牌演演算法是Fisher-Yates演演算法,其他語言可以自行實現)
-
因為是在構建負載均衡器的時候按權重展開成陣列的,所以在負載均衡器構建完成後無法再改變範例的權值,對於頻繁動態變更權重的場景不適用
上界收斂選擇方式
上界收斂選擇方式提前計算出所有權重的最大值,並將初始上界設定為所有權重的最大值,接下來我們一輪一輪地去遍歷所有範例,並找到權重大於等於上界的範例。當前輪遍歷結束後,所有大於等於上界的元素都被選取到了,接下來開始嘗試權重更低的節點,直到最後上界為0時,將其重新置為最大值。目前openresty (有人在issue #44上分析了這種演演算法)
public class WeightedLoadBalancer { private final List instances; private final int max; private final int gcd; private int bound; private int position; public WeightedLoadBalancer(List instances) { this.instances = instances; this.max = calculateMaxByWeight(instances); this.gcd = calculateGcdByWeight(instances); this.position = ThreadLocalRandom.current().nextInt(instances.size()); } public ServiceInstance peek(HttpServletRequest request) { if (bound == 0) { bound = max; } while (instances.size() > 0) { for (int peeked = position; peeked < instances.size(); peeked++) { ServiceInstance instance = instances.get(peeked); if (instance.getWeight() >= bound) { position = peeked + 1; return instance; } } position = 0; bound = bound - gcd; } return null; } private static int calculateMaxByWeight(List instances) { int max = 0; for (ServiceInstance instance : instances) { if (instance.getWeight() > max) { max = instance.getWeight(); } } return max; } private static int calculateGcdByWeight(List instances) { int gcd = 0; for (ServiceInstance instance : instances) { gcd = gcd(gcd, instance.getWeight()); } return gcd; } private static int gcd(int a, int b) { if (b == 0) { return a; } return gcd(b, a % b); } }
這裡面有四個需要注意的點:
-
如果是短頻率請求,將會一直存取高權重範例,導致在短時間視窗內負載看起來並不均勻。這個可以通過改變方向,從下界向上界逼近來解決。
-
每一輪後降低上界的值可以取所有權重的最大公約數,因為如果每次下降1的話,中間這些輪會反覆請求權重最高的那些範例,導致負載不均衡。
-
雖然最大公約數可以減少下降次數,但是如果權重相差非常多,並且所有元素都是互質的(n與n+1互質,任意自然數n與1互質,在實踐中非常容易出現),那麼在上界下降的過程中將會帶來很多空轉。這個可以參考廣度優先遍歷的思想,使用先入先出的佇列來減少空轉。
-
與陣列展開方式遇到的問題相同,因為是在構建負載均衡器的時候計算最大公約數的值,所以對於頻繁動態變更權重的場景依舊會有很大的效能開銷,但是相較於陣列展開方式可以避免頻繁動態分配陣列導致的效能與記憶體碎片問題
權重輪轉實現
權重輪轉演演算法中將會儲存兩個權重的值,一個是不會變化的原始權重,一個是會隨著每次選擇變化的當前權重。權重輪轉實現中維護了一個迴圈不變數——所有節點的當前權重的和為0。每輪遍歷過程中所有範例的有效權重都會增加它的原始權重,並選擇出當前權重最高的節點。選擇出權重最高的節點後將它的當前權重減去所有範例權重的總和,以避免它再次被選擇。NGINX中加權輪詢負載均衡演演算法使用此實現(NGINX)。這種演演算法的優勢是它很平滑,低權重節點的等待時間較短,並且每輪權重輪轉的最小正週期很小,是所有伺服器範例權重的和。。
在NGINX中又叫做平滑加權負載均衡(Smooth Weighted Load Balancing,SWRR)。
public class WeightedLoadBalancer { private final List instances; public WeightedLoadBalancer(List instances) { this.instances = instances; } public ServiceInstance peek(HttpServletRequest request) { ServiceInstance best = null; int total = 0; for (ServiceInstance instance : instances) { total += instance.getWeight(); instance.setCurrentWeight(instance.getCurrentWeight() + instance.getWeight()); if (best == null || instance.getCurrentWeight() > best.getCurrentWeight()) { best = instance; } } if (best != null) { best.setCurrentWeight(best.getCurrentWeight() - total); } return best; } }
這裡面有三個需要注意的點:
-
權重輪轉非常適合範例變化頻率非常高的集合,因為它不需要提前構建資料結構
-
權重輪轉實現的效率與範例數量相關,時間複雜度是O(n),當叢集伺服器數量非常大時需要限制每次參與選擇的伺服器數量(Spring Cloud #1111)
-
權重輪轉實現需要修改伺服器範例的資料結構,當服務範例是由其他機構提供時無法使用此實現
EDF(Earliest Deadline First)實現
EDF演演算法最早被用在CPU排程上,EDF是搶佔式單處理器排程的最佳排程演演算法。EDF實現與權重輪轉實現相似,引入了名為deadline的額外變數,可以認為權重越高的伺服器範例完成任務的時間越快,那麼在假設所有請求的成本相同時,所需要花費的時間是權重的倒數,所以可以很自然地選擇可以最早空閒出來提供服務的伺服器範例,並將任務分配給它。
實現EDF演演算法只需要將每個下游伺服器範例與deadline繫結,然後以deadline為優先順序維護到優先佇列中,並不斷取出隊首元素,調整它的deadline,並將它重新提交到優先佇列中。知名Service Mesh代理envoy使用了此方法實現加權負載均衡(envoy),以及螞蟻開源網路代理mosn中也實現了此方法(mosn #1920)
public class WeightedLoadBalancer { private final PriorityQueue entries; public WeightedLoadBalancer(List instances) { this.entries = instances.stream().map(EdfEntry::new).collect(Collectors.toCollection(PriorityQueue::new)); } public ServiceInstance peek(HttpServletRequest request) { EdfEntry entry = entries.poll(); if (entry == null) { return null; } ServiceInstance instance = entry.instance; entry.deadline = entry.deadline + 1.0 / instance.getWeight(); entries.add(entry); return instance; } private static class EdfEntry implements Comparable { final ServiceInstance instance; double deadline; EdfEntry(ServiceInstance instance) { this.instance = instance; this.deadline = 1.0 / instance.getWeight(); } @Override public int compareTo(EdfEntry o) { return Double.compare(deadline, o.deadline); } } }
EDF每次選擇的演演算法複雜度為O(log(n)),相較於陣列展開要慢,但相較於上界收斂選擇在最壞情況下以及權重輪轉都需要O(n)的時間複雜度來說,其效能表現的非常好,並且對於超大叢集,其效能下降不明顯。其空間複雜度為O(n),不會造成很大的記憶體開銷。
Least Connections(最少連線負載均衡演演算法)
遍歷比較方式
最簡單的實現方式,遍歷所有範例,並找出當前連線數最少的範例
public class LeastConnectionLoadBalancer { private final List instances; public LeastConnectionLoadBalancer(List instances) { this.instances = instances; } public ServiceInstance peek(HttpServletRequest request) { ServiceInstance best = null; for (ServiceInstance instance : instances) { if (best == null || instance.getConnections() < best.getConnections()) { best = instance; } } if (best != null) { best.setConnections(best.getConnections() + 1); } return best; } }
堆維護方式
所有動態有序集合都可以通過優先佇列來實現,與EDF演演算法相同,取出隊首的元素,修改它的優先順序,並放回佇列中
public class LeastConnectionLoadBalancer { private final PriorityQueue instances; public LeastConnectionLoadBalancer(List instances) { this.instances = instances.stream().collect(toCollection( () -> new PriorityQueue<>(comparingInt(ServiceInstance::getConnections)))); } public ServiceInstance peek(HttpServletRequest request) { ServiceInstance best = instances.poll(); if (best == null) { return null; } best.setConnections(best.getConnections() + 1); return best; } }
Weighted Least Connections(加權最少連線負載均衡演演算法)
加權最少連線負載均衡演演算法的實現方式與最少連線負載均衡演演算法相同,只是在計算時增加了權重相關的引數
遍歷比較方式
public class LeastConnectionLoadBalancer { private final List instances; public LeastConnectionLoadBalancer(List instances) { this.instances = instances; } public ServiceInstance peek(HttpServletRequest request) { ServiceInstance best = null; for (ServiceInstance instance : instances) { if (best == null || instance.getConnections() * best.getWeight() < best.getConnections() * instance.getWeight()) { best = instance; } } if (best != null) { best.setConnections(best.getConnections() + 1); } return best; } }
Tips,在不等式中 a/b < c/d 與 ad < bc等價,並且可以避免除法帶來的效能與精度問題
堆維護方式
public class LeastConnectionLoadBalancer { private final PriorityQueue instances; public LeastConnectionLoadBalancer(List instances) { this.instances = instances.stream().collect(toCollection( () -> new PriorityQueue<>(comparingDouble(ServiceInstance::getWeightedConnections)))); } public ServiceInstance peek(HttpServletRequest request) { ServiceInstance best = instances.poll(); if (best == null) { return null; } best.setConnections(best.getConnections() + 1); best.setWeightedConnections(1.0 * best.getConnections() / best.getWeight()); return best; } }
Weighted Response Time(加權響應時間負載均衡演演算法)
加權響應時間負載均衡演演算法使用統計學的方法,通過歷史的響應時間來得到預測值,使用這個預測值來選擇相對更優的伺服器範例。得到預測值的方法有很多,包括時間視窗內的平均值、時間視窗內的TP99、歷史所有響應時間的指數移動加權平均數(EWMA)等等。其中Linkerd與APISIX使用了EWMA演演算法(Linkerd和APISIX)。
通過歷史的響應時間來得到預測值這個操作通常是CPU開銷很大的,實際使用時可以不用遍歷所有元素,而是使用K-臨近元素或直接隨機選擇兩個元素進行比較即可,這種啟發式方法辦法無法保證全域性最優但是可以保證不至於全域性最差。
Source IP Hash(源地址雜湊負載均衡演演算法)
源地址雜湊負載均衡以任意演演算法將請求地址對映成整型數,並將這個整型數對映到範例列表的下標
public class IpHashLoadBalancer { private final List instances; public IpHashLoadBalancer(List instances) { this.instances = instances; } public ServiceInstance peek(HttpServletRequest request) { int h = hashCode(request); return instances.get(h % instances.size()); } private int hashCode(HttpServletRequest request) { String xForwardedFor = request.getHeader("X-Forwarded-For"); if (xForwardedFor != null) { return xForwardedFor.hashCode(); } else { return request.getRemoteAddr().hashCode(); } } }
這裡有一個需要注意的點:
-
面向公網提供服務的負載均衡器前面可能會經過任意多層反向代理伺服器,為了獲取到真實的源地址,需要先獲取X-Forwarded-For頭部,如果該頭部不存在再去獲取TCP連線的源地址
負載均衡技術擴充套件
服務登入檔與發現(Service Registry and Service Discovery)
在維護大型伺服器叢集時,伺服器範例隨時都有可能被建立或移除,當伺服器被建立或移除時,叢集管理員需要到各個負載均衡裝置上去更新伺服器範例列表。
服務登入檔會在內部維護服務對應的伺服器範例列表。在伺服器範例被建立併成功執行服務後,伺服器範例會去服務登入檔中註冊自身,包括網路地址(IPv4/IPv6)、伺服器埠號、服務協定(TCP/TLS/HTTP/HTTPS)以及自身提供的服務名稱等等,有的服務登入檔本身也會提供主動健康檢查的能力(如Eureka與Consul)。在伺服器範例正常退出時會在服務登入檔執行反註冊邏輯,這個時候服務登入檔就會將這個伺服器範例從伺服器範例列表中移除。即使伺服器範例異常退出導致無法執行反註冊邏輯,服務登入檔也會通過主動健康檢查機制將這個異常的伺服器範例從伺服器範例列表中移除。
在擁有服務登入檔後,負載均衡裝置不需要再手動維護伺服器範例列表,而是當請求到來時從服務登入檔中拉取對應的伺服器範例列表,並在這個伺服器範例列表中進行負載均衡。為了提高服務的可用性,負載均衡裝置會在本地(記憶體或本地檔案登入檔)快取這些伺服器範例列表,以避免由於負載均衡裝置與服務登入檔無法連線而導致服務不可用。
快取及重新獲取伺服器列表的策略根據不同業務場景有不同的實現,在Spring Cloud Loadbalancer中是通過快取過期而觸發重新獲取的邏輯(Spring Cloud),當服務登入檔不可用時,因為負載均衡裝置中無可用的伺服器備份而導致服務完全不可用;在大部分的負載均衡裝置中將快取獲取與更新邏輯改為定時器主動重新整理的機制,這樣當服務登入檔不可用時可以主動決定是否將舊資料標記為過期。儘管本地快取可以提高服務的可用性,但是要注意負載均衡裝置在使用的仍舊是舊的服務提供方列表,當長時間無法獲取到新的服務提供方列表時,負載均衡裝置應當捨棄舊的服務提供方列表,並將服務不可用的問題暴露出來,通過基礎設施提供的監控與告警能力通知叢集管理員來進行處理。
健康檢查(Health Check)
健康檢查本質是一個預定規則,它向負載均衡器背後的伺服器叢集中的所有成員傳送相同的請求,以確定每個成員伺服器是否可以接受使用者端請求。
對於某些型別的健康檢查,通過評估來自伺服器的響應以及收到伺服器響應所需的時間以確定每個成員伺服器的執行狀態。通常情況下,當成員伺服器的狀態變為不健康時,負載均衡器應該快速地將其從伺服器範例列表中移除,並在成員伺服器狀態恢復正常時將其重新新增回伺服器範例列表中。
-
對於網路層負載均衡器(也叫做NLB或L4LB),通過建立TCP連線,根據是否能夠成功建立連線以及建立連線所需要的時間來確定成員伺服器的狀態。
-
對於應用層負載均衡器(也叫做ALB或L7LB),通過傳送應用層協定(不只是HTTP協定)定義的用於健康檢查的請求報文,並根據響應報文內容以及整個請求從建立連線到完整收到所有響應所花費的時間來確定成員伺服器的狀態。
應用負載均衡器沒有固定的模式。例如,對於提供HTTP協定服務的應用,可以提供用於健康檢查的URL,設定通過健康檢查的HTTP狀態碼(或狀態碼集),並驗證響應報文中用於表示伺服器狀態的欄位(通過JSONPath或XMLPath等提取)是否是預期值等方式來確認成員伺服器狀態;對於RPC協定,可以提供專門的ping-pong服務,負載均衡器根據RPC協定組裝請求報文,並行送ping請求到成員伺服器上,並根據成員伺服器返回的內容是否為pong響應來確認成員伺服器的狀態,具體設計可以參考websocket的ping-pong機制(RFC 6455)。
慢啟動(Slow Start)
負載均衡器中的慢啟動思想來自於TCP的擁塞控制理論,其核心也是為了避免大量請求湧入剛剛啟動完成的應用程式,導致大量請求阻塞、超時或異常的情況。 眾所周知,Java是半編譯半直譯語言,包括Java語言在內,現代直譯語言的直譯器都帶有即時編譯器(Just In Time,JIT),JIT編譯器會跟蹤每個方法的執行點,對那些熱點路徑(Hotspot)進行更高效的優化,這也是Hotspot JVM名字的由來。而JIT對熱點路徑的優化全都來自於自應用程式啟動以來的所有方法呼叫,也就是說應用程式的系統承載能力是隨著程式的執行而不斷得到強化的,經過JIT優化的Java程式碼甚至可以得到近似GCC中O3(最高階別)優化的效能。跟多關於JIT編譯器的細節可以看Oracle的Java開發者指南(Java Developer Guide)。
同時,現代應用程式都不可避免的會使用本地快取,當應用程式剛剛啟動時記憶體中的快取是空的,隨著應用程式的執行,不斷地存取外部系統獲取資料並將資料寫入到記憶體快取中,應用程式與外部系統的互動會不斷減少,應用程式的系統承載能力也會逐漸達到峰值。
上面是應用程式在啟動後效能不斷提升的因素中最常見的,初次之外還有很多的因素。所以為了避免大量請求湧入剛剛啟動完成的應用程式的現象發生,負載均衡器會通過慢啟動的方式,隨著伺服器執行不斷增加這些伺服器範例的權重,最終達到伺服器的實際權重,從而達到動態調整分配給這些伺服器範例的流量的效果。
伺服器權重變化演演算法有很多,包括隨時間線性增長、隨時間對數增長、隨時間指數增長、隨時間變冪增長、與隨時間按Logistic增長等。目前京東服務架構(JSF)實現的是隨時間線性增長;envoy實現了隨時間變冪增長,並引入了漸進因子來調整變化速率(envoy slow start)。

總結
負載均衡技術是網路代理與閘道器元件最核心的組成部分,本文簡單介紹了什麼是負載均衡技術、常見的負載均衡演演算法以及常見負載均衡演演算法的實現,並給出了負載均衡技術的擴充套件,為將來更深入學習網路代理相關技術打下基礎。
因本人才學疏淺經驗能力有限,文中難免會有疏忽和遺漏,以及不連貫的地方,歡迎大家與我溝通交流給出建議。