【人工智慧】機器學習入門之監督學習(一)有監督學習
機器學習入門之監督學習(一)有監督學習
簡介
監督學習演演算法是常見演演算法之一,主要分為有監督學習和無監督學習。本文主要記錄了有監督學習中的分類演演算法和迴歸演演算法,其中迴歸演演算法是本文最主要內容。
本筆記對應視訊:阿里雲開發者社群學習中心-人工智慧學習路線-階段1:機器學習概覽及常見演演算法
對應視訊地址:https://developer.aliyun.com/learning/course/529
監督學習
定義:利用已知類別的樣本,訓練學習得到一個最優模型,使其達到所要求效能,再利用這個訓練所得模型,將所有的輸入對映為相應的輸出,對輸出進行簡單的判斷,從而實現分類的目的,即可以對未知資料進行分類。
監督學習分為:有監督學習,無監督學習,半監督學習
本文內容主要介紹有監督學習和無監督學習相關演演算法
有監督學習
有監督學習( Supervised learning ) :利用一組已知類別的樣本來訓練模型,使其達到效能要求。
特點:為輸入資料(訓練資料)均有一個明確的標識或結果(標籤)
萌狼說1:就是給他問題和答案,讓他自己做題,然後自己對答案。
萌狼說2:就是給它一道有答案的例題讓它學習
分類演演算法
分類(Classification):就是通過已有資料集(訓練集)的學習,得到一個目標函數f (模型),把每個屬性集x對映到目標屬性y (類) ,且y必須是離散的(若y為連續的,則屬於迴歸演演算法)。通過對已知類別訓練集的分
析,從中發現分類規則,以此預測新資料的類別。
萌狼說人話:比如我手上有一堆圖片,同時每張圖片標記了圖中人物是否戴口罩。我給它看:AI你看啊,這張圖是戴了口罩了,這張圖是沒戴口罩的……(AI學習中),根據我教它的,它進行建模,然後你給它一張沒見過的圖片,它在這個時候就能根據模型預測這張圖是否戴了口罩了。
【相關閱讀】計算機視覺技術與應用:識別人物是否帶口罩
文章地址(包含程式碼):https://mp.weixin.qq.com/s/mEvL4qUpB0gxYhMm6WVqng
分類演演算法有很多種
按原理分類:
- 基於統計的:例如貝葉斯分類
- 基於規則的:例如決策樹演演算法
- 基於神經網路的:神經網路演演算法
- 基於距離的:KNN(K最近鄰)
常用評估指標
- 精確率:預測結果與實際結果的比例
- 召回率:預測結果中某類結果的正確覆蓋率
- F1-Score:統計量,綜合評估分類模型,取值0-1之間
迴歸演演算法
迴歸(Regression)
分類演演算法的帶的目標屬性y(類)是離散的,而回歸演演算法得到的y是連續的。
既然是連續的,就可以使用函數表示。
所以迴歸演演算法的實質:通過已有資料,儘可能的去擬合成一個函數
例如:我有商品在不同售價時對應賣出數量的資料集,對這些資料建模後,模型就可以根據我們輸入的價格預測會賣出的數量。實際上它是根據我們給的資料,擬合了一個函數,例如擬合線性方程Y=aX+b
這個a和b可以使用最小二乘法求出來。
比如我給你如下資料
| 價格 | 銷售量 |
|---|---|
| 1 | 1000 |
| 2 | 900 |
| 3 | 800 |
| 4 | 700 |
| 5 | 600 |
| 6 | 500 |
| 7 | 400 |
| 8 | 300 |
| 9 | 200 |
| 10 | 100 |
你一看這資料,你就知道價格和銷售量之間存在著某種關係,比如y=kx+b
計算出斜率後根據
和已經確定的斜率k,利用待定係數法求出截距b
先用數學的方式算一下,程式碼如下
import pandas as pd
def getK(data):
avgx = data["x"].values.mean() # 獲取x平均值
avgy = data["y"].values.mean() # 獲取y平均值
fenzi = 0
fenmu = 0
for i in range(len(data["x"])):
x = data["x"][i]
y = data["y"][i]
fenzi += x * y
fenmu += x * x
fenzi = fenzi -len(data["x"]) * avgx * avgy
fenmu = fenmu - len(data["x"]) * avgx *avgx
k = fenzi / fenmu
b = avgy - k *avgx
return "y="+str(k)+"x+"+str(b)
data = pd.DataFrame(data = [[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],[1000, 900, 800, 700, 600, 500, 400, 300, 200, 100]],index=["x","y"])
data = data.T # 轉置
result = getK(data)
print(result)
[輸出結果] y=-100.0x+1100.0
這個線性方程走下坡路,y後面就會變為負數。雖然說銷售量不可能為負數,但是我們這個只是一個不嚴謹的例子,資料我隨便造的,存在不合理的情況也正常
我們的目的是: tensorflow擬合的線性迴歸方程,儘可能貼近數學計算出來的線性迴歸方程
接下來使用Tensoflow來得出這個模型(擬合線性迴歸方程)
首先準備資料,光是我們上面的資料是遠遠不夠的,因此我們造一點資料出來,造資料的程式碼如下
import math
import random
import pandas as pd
def getCheck(data):
avgx = data["x"].values.mean() # 獲取x平均值
avgy = data["y"].values.mean() # 獲取y平均值
fenzi = 0
fenmu = 0
for i in range(len(data["x"])):
x = data["x"][i]
y = data["y"][i]
fenzi += x * y
fenmu += x * x
fenzi = fenzi - len(data["x"]) * avgx * avgy
fenmu = fenmu - len(data["x"]) * avgx * avgx
k = fenzi / fenmu
b = avgy - k * avgx
testX=[]
testY=[]
# return k,b
for i in range(1000):
x = random.uniform(0, 10)
y = k * x + b
testX.append(x)
testY.append(math.floor(y)) # 向下取整
print(testX)
print(testY)
d = pd.DataFrame(data = [testX,testY])
d = d.T
d.to_csv("train_data.csv")
# d.to_csv("test_data.csv")
if __name__ == '__main__':
data = pd.DataFrame(data=[[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], [1000, 900, 800, 700, 600, 500, 400, 300, 200, 100]],
index=["x", "y"])
data = data.T # 轉置
getCheck(data)
執行上面的程式碼(注意第33行和第34行,分別是生成訓練集和測試集的),生成資料集
【相關閱讀】
讀取資料集
# 讀取資料集
train_data = pd.read_csv('./train_data.csv')
test_data = pd.read_csv('./test_data.csv')
構建模型
首先要明確我們要做的事情,我們是在做預測,使用線性迴歸演演算法方式預測。
# 構建模型
model = tf.keras.Sequential([
# 全連線層 tf.keras.layers.Dense() 全連線層在整個網路折積神經網路中起到「特徵提取器」的作用
# --- 輸出維度
# --- 啟用函數activation:relu 關於啟用函數。可以查閱https://www.cnblogs.com/mllt/p/sjwlyh.html
tf.keras.layers.Dense(128, activation='relu', input_shape=(1,)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1)
])
# 設定優化器optimizer 相關連結:https://www.cnblogs.com/mllt/p/sjwlbg.html
# https://www.cnblogs.com/mllt/p/sjwlyh.html#%E4%BC%98%E5%8C%96%E5%99%A8
optimizer = tf.keras.optimizers.Adam(lr = 0.002)
"""
lr 學習率。lr決定了學習程序的快慢(也可以看作步幅的大小)。
如果學習率過大,很可能會越過最優值;
如果學習率過小,優化的效率可能很低,導致過長的運算時間
優化器keras.optimizers.Adam()是解決這個問題的一個方案。
其大概的思想是開始的學習率設定為一個較大的值,然後根據次數的增多,動態的減小學習率,以實現效率和效果的兼得
"""
訓練模型
model.compile(loss="mse", optimizer=optimizer, metrics=['mse']) # 預測評價指標:https://blog.csdn.net/guolindonggld/article/details/87856780
# 均方誤差(MSE)是最常用的迴歸損失函數,計算方法是求預測值與真實值之間距離的平方和
# 相關連結:https://www.cnblogs.com/mllt/p/sjwlbg.html
# 神經網路模型
print(model)
# 神經網路模型結構
print(model.summary())
# 對神經網路進行訓練
模型訓練情況視覺化
# 訓練情況視覺化
hist = pd.DataFrame(history.history)
print(hist)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.plot(hist['epoch'], hist['loss'],label="訓練集損失值")
plt.plot(hist['epoch'], hist['val_loss'],label='測試集損失值')
"""
最佳情況:loss 和 val_loss 都不斷下降
過擬合:loss不斷下降,val_loss趨近於不變 解決辦法:減少學習率或者減少批次數目
資料集異常:loss趨近於不變,val_loss不斷下降
學習瓶頸:loss、val_loss都趨近於不變 解決辦法:減少學習率或者減少批次數目
神經網路設計的有問題:loss、val_loss都不斷上升 解決辦法:重置模型結構 重置資料集
"""
plt.legend()
plt.show()
plt.figure()
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.plot(hist['epoch'], hist['mse'],label="訓練集準確率")
plt.plot(hist['epoch'], hist['val_mse'],label="測試集準確率")
plt.legend()
plt.show()
預測情況視覺化
# 預測情況視覺化
plt.figure()
y = model.predict(test_data["0"])
plt.plot(test_data["0"],y,label="模型預測值")
plt.plot(test_data['0'],test_data['1'],label="真實值")
plt.legend()
plt.show()
預測
print(model.predict([5.5]))
結果
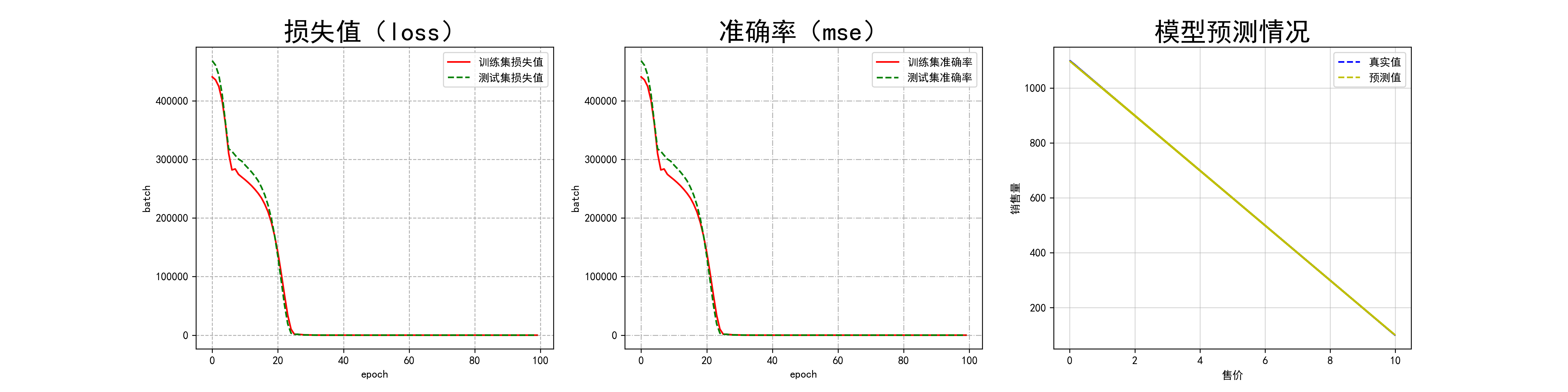
MSE:均方誤差(Mean Square Error)
範圍[0,+∞],當預測值與真實值完全吻合時等於0,即完美模型;誤差越大,該值越大,模型效能越差。
完整程式碼
這個完整程式碼,是上面程式碼刪除註釋後,影象規範化後的完整程式碼。
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus']=False # 正常顯示負號
train_data = pd.read_csv('./train_data.csv')
test_data = pd.read_csv('./test_data.csv')
# 構建模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(1,)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1)
])
optimizer = tf.keras.optimizers.Adam(lr = 0.002)
model.compile(loss="mse", optimizer=optimizer, metrics=['mse'])
history = model.fit(train_data["0"], train_data["1"], batch_size=100, epochs=100, validation_split=0.3, verbose=0)
# 訓練情況視覺化
hist = pd.DataFrame(history.history)
print(hist)
hist['epoch'] = history.epoch
y = model.predict(test_data["0"])
# plt.figure(figsize=(10,5),dpi=300)# 建立畫布
fig,axes = plt.subplots(nrows=1,ncols=3,figsize=(20,5),dpi=300)
# 新增描述
axes[0].set_title("損失值(loss)",fontsize=24)
axes[1].set_title("準確率(mse)",fontsize=24)
axes[2].set_title("模型預測情況",fontsize=24)
# 設定標籤
axes[0].set_ylabel("batch")
axes[1].set_ylabel("batch")
axes[2].set_ylabel("銷售量")
axes[0].set_xlabel("epoch")
axes[1].set_xlabel("epoch")
axes[2].set_xlabel("售價")
axes[0].plot(hist['epoch'], hist['mse'],label="訓練集損失值",color="r",linestyle="-")
axes[0].plot(hist['epoch'],hist['val_mse'],label="測試集損失值",color="g",linestyle="--")
axes[1].plot(hist['epoch'], hist['loss'],label="訓練集準確率",color="r",linestyle="-")
axes[1].plot(hist['epoch'],hist['val_loss'],label="測試集準確率",color="g",linestyle="--")
axes[2].plot(test_data['0'],test_data['1'],label="真實值",color="b",linestyle="--")
axes[2].plot(test_data['0'],y,label="預測值",color="y",linestyle="--")
axes[0].legend(loc="upper right")# 顯示圖例必須在繪製時設定好
axes[1].legend(loc="upper right")# 顯示圖例必須在繪製時設定好
axes[2].legend(loc="upper right")# 顯示圖例必須在繪製時設定好
# 新增網格
# plt.grid(True,linestyle="--",alpha=0.5) # 新增網格
axes[0].grid(True,linestyle="--",alpha=1)
axes[1].grid(True,linestyle="-.",alpha=1)
axes[2].grid(True,linestyle="-",alpha=0.5)
plt.show()
print(model.predict([5.5]))
其他有監督學習演演算法
分類演演算法:
-
KNN ( K最近鄰,K-Nearest Neighbour)
-
NB (樸素貝葉斯 ,Naive Bayes )
-
DT (決策樹, Decision Tree ) : C45、CART
-
SVM (支援向量機, Support Vector Machine )
迴歸預測:
-
線性迴歸( Linear Regression )
-
邏輯迴歸( Logistic Regression )
-
嶺迴歸( Ridge Regression )
-
拉索迴歸( LASSO Regression )