一些關於位元組序處理的一些經驗
特別是接觸下位機 或者socket資料流處理,總少不了涉及所謂位元組序問題。今天又拿這個出來說事了。有點囉嗦哈
偶然翻到微量氧專案的ModbusRTU 暫存器說明 ,有這麼一段說明:
從站地址預設為0x01
位元組序:每個暫存器均一個2位元組資料 ,下位機發時遵循 先發高位 再發低位。
比如下位機發 0xff00 那麼上位機收到的 byte[] readDatas; 為 readDatas={0xff,0x00}
想著先發高位對方收到的ff 00 對的哈 ,仔細一想 我擦 越想越不對 ,在未傳送前 0xff00 按照little位元組序 ff可是高位噢。對應65280, 你一傳送後 變成了{ff,00} 低位元組對應低位 別人用little位元組序一轉換變成 255了 這不扯淡麼。但是 但是 但是 這不是我自己寫的麼 ,當時我就怎麼寫出這段話來的呢,鬼使神差?不得不說這玩意兒確實個繞 絞人的東西 ,現在這社會 人浮躁的甚至到了都不能靜下心來認真理解一段話的程度了。為了刨根問底兒追這些細節我們來調測一下:
首先是位元組序說明和測試:
little位元組序,即小端位元組序 高位元組資料在地址或者陣列的高位 ,低位元組資料在地址或者陣列的低位。這也是符合我們正常人思維理解概念的一種位元組序 ,且也是大多數程式設計環境支援的一種預設處理方式。
另一種與之相反是big位元組序 我們這裡不做說明。
c#中預設是intel架構 的little位元組序 所有的位元組資料處理也是遵循的。好的我們 首先編寫一段簡單的不能再簡單的程式碼
1 UInt16 testNum = 0xff00;//65280 2 byte[] btstest = BitConverter.GetBytes(testNum); 3 4 //byte[] btstest2 = { 0xff, 0x00 }; 5 UInt16 testNum2 = BitConverter.ToUInt16(btstest, 0); 6 Console.WriteLine(testNum2.ToString());
都知道"hello" 陣列末尾以\0結尾 陣列的高索引代表高位 ,那麼上面應該是{00,ff}這種看似簡單的東西容易把人絞昏。為什麼推進little位元組序。你想想這邊的環境 傳送到對方那 對方也接收到一個陣列裡 ,先發低地址也就是ff 對方越收到越往陣列的後面 排 {ff,00}->{ff,00} 這邊環境的東西跟對方環境的東西完全一樣,這樣才符合人慣性思維的預期 是不是這樣。
那我們看下到底是不是高位就在高地址
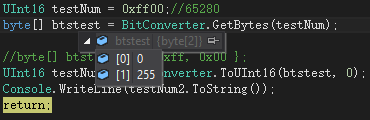
嗯 確實是的對吧。輸出65280完全沒問題。
另外一種處理方式的來由
但是看到下面一段程式碼 ,反向了?
1 float oxMeasure = float.Parse(textBox1.Text); 2 //0,0,127,67 3 //0x43 7f 00 00 4 //{0x00,0x00 ,0x7f,0x43} 5 byte[] oxmeasureData = BitConverter.GetBytes(oxMeasure); 6 7 byte[] uploadData = { 0xEE, 0xB5, 0x02, 0x01, 0x04, 0x01, 0x01, 0x01, 0x01, 0xFF, 0xFC, 0xFF, 0xFF }; 8 //高低位反向 9 uploadData[5] = oxmeasureData[3]; 10 uploadData[6] = oxmeasureData[2]; 11 uploadData[7] = oxmeasureData[1]; 12 uploadData[8] = oxmeasureData[0]; 13 //ComDevice.Write(uploadData, 0, uploadData.Length);
如上程式碼所描述 反向了,先發高位,那麼下位機收到的應該是{0x43,0x7f,0x00,0x00}
為什麼要這樣寫呢。
我們程式碼這裡應該是oxmeasureData = {0x00,0x00 ,0x7f,0x43} ,反著發下位機收到 {0x43,0x7f,0x00,0x00 } ,下位機每收到一個位元組都加到字串然後輸出偵錯。
1 function measureProcess(parid, parData) 2 local measureHexStr = ""; 3 local measureval = 0.0; 4 for i = 1, #parData, 1 do 5 measureHexStr = measureHexStr .. string.format('%02X', parData[i]); 6 end 7 --print(measureHexStr.."------"); 8 measureval = hexToFloat(measureHexStr); 9 if parid == 1 then --通道1 10 globalvar_ch1_measure = measureval; 11 elseif parid == 2 then --通道2 12 globalvar_ch2_measure = measureval; 13 elseif parid == 3 then 14 globalvar_ch3_measure = measureval; 15 elseif parid == 4 then 16 globalvar_ch4_measure = measureval; 17 end 18 19 end
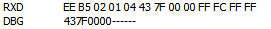
那麼 問題來了,看到輸出的字串沒有 ,轉過來了,學過c語言都知道, 0x43是字串陣列中的低位,但是這裡是當作全字串來處理的 就像我們平常書寫程式碼一樣//"0x43 7f 00 00",卻恰巧可以正確轉換,也正是由於這點小小的貓膩 經常導致我們的混亂。
另外曬一下網上抄的一段支援標誌ANSI c 也就是所謂,IEEE754的 轉換程式碼 也即標準的c語言float在記憶體中怎麼形式存在的 就怎麼形式轉換。
1 function hexToFloat( hexString ) 2 if hexString == nil then 3 return 0 4 end 5 local t = type( hexString ) 6 if t == "string" then 7 hexString = tonumber(hexString , 16) 8 end 9 10 local hexNums = hexString 11 12 local sign = math.modf(hexNums/(2^31)) 13 14 local exponent = hexNums % (2^31) 15 exponent = math.modf(exponent/(2^23)) -127 16 17 local mantissa = hexNums % (2^23) 18 19 for i=1,23 do 20 mantissa = mantissa / 2 21 end 22 mantissa = 1+mantissa 23 -- print(mantissa) 24 local result = (-1)^sign * mantissa * 2^exponent 25 --保留一位小數 26 result = math.floor(result * 10+ 0.5) / 10; 27 return result 28 end
事情往就是在這樣絞來絞去的過程中 不知不覺就被帶偏了 ,然後就囫圇吞棗的過。