重新整理 .net core 實踐篇 ———— dotnet-dump [外篇]
前言
本文的上一篇為: https://www.cnblogs.com/aoximin/p/16861797.html
該文為dotnet-dump 和 procdump 的實戰介紹一下。
正文
現在很多情況下去抓取dotnet 執行的資訊一般都是適用 procdump 或者 直接使用dotnet-dump
這個procdump 有什麼用呢?
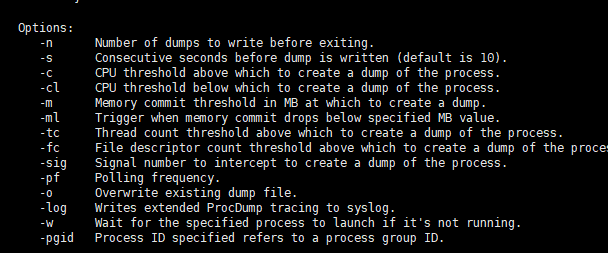
根據 ProcDump 幫助,下面是必須使用的開關:
-M:當記憶體提交超過或等於指定值時觸發核心轉儲檔案生成 (MB)
-n:退出前要寫入的核心轉儲檔案數 (預設值為 1)
-s:連續幾秒鐘寫入轉儲檔案 (預設值為 10)
-d:將診斷紀錄檔寫入 Syslog
-p:程序的 PID
這個的好處就是有時候突然間記憶體升高,其實就是多了一個監控的作用。
我記得以前每次用dotnet-dump的時候,我讓運維寫了一個指令碼,當記憶體到達多少或者cpu到達多少的時候執行一些dotnet-dump 這個命令。
我們知道一般抓取需要連續抓取,那麼我們用上一篇的例子抓一下。
procdump -pgid 108232 -n 2 -c 50 -s 3
上面就是說cpu到達50%並持續時間3秒,那麼就執行抓取操作,一共抓取兩次,相隔10秒。
這個procdump 抓取的內容在workdirection下面,也就是自己的工作目錄下面。
那麼抓取一次。
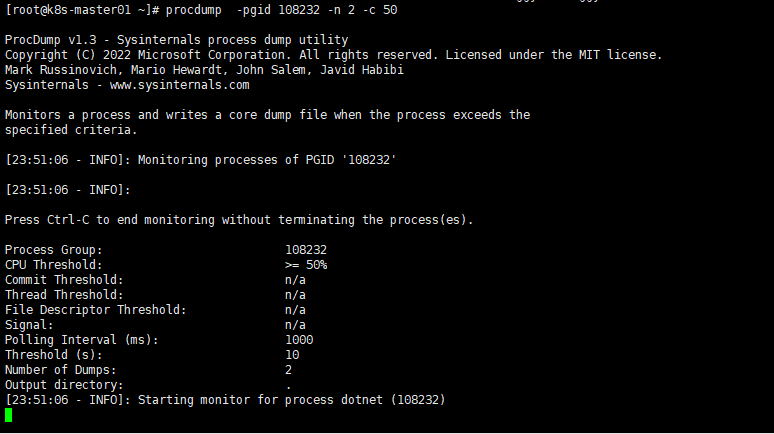
執行的時候一直在monitor,看到了吧。
然後執行慢查詢:
這樣就ok了。
然後用dotnet-dump 去解析就好了。
如果使用dotnet-dump 的話:
這個是安裝:
dotnet tool install -g dotnet-dump
然後你也可以這麼收集:
檢視正在執行的dotnet core:
dotnet-dump ps

然後:
dotnet-dump collect -p xxx
根據程序號收集就好了。 但是這樣只能手動,procdump 可以做到監聽。
如果是偶發性的用procdump 比較好,比如不是,那麼用dotnet-dump就好了。
然後dotnet-dump 分析的話,舉個例子:
dotnet-dump analyze /tmp/coredump.manual.1.108232
然後其實和lldb 沒有什麼區別,其實lldb 更為強大而已,帶偵錯功能和檢視非託管的功能,而dotnet-dump 檢視託管問題。
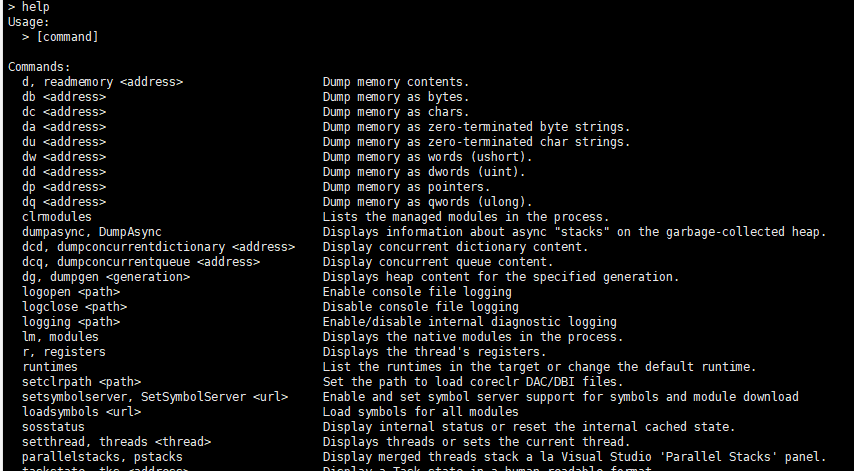
可以看到命令差不多。
把上篇文章的上半段記憶體問題給演示下:
dumpheap -stat
統計一下:
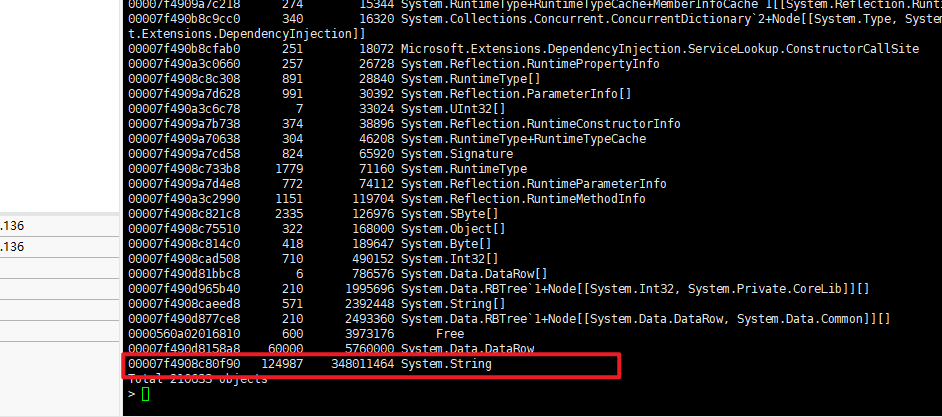
這個 string 很大,然後檢視大物件:
dumpheap -stat -min 85000
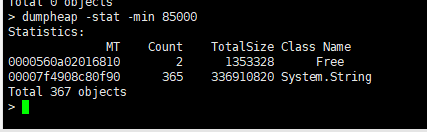
大於8.5m string 有 365個。
檢視一下物件堆,並且活躍的,可以理解為沒有被GC標記的吧:
dumpheap -mt 00007f4908c80f90 -min 85000 -live
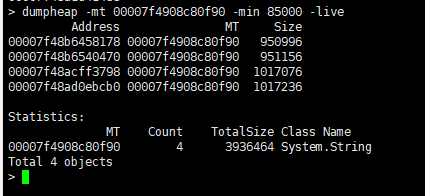
這裡就有4個了。
那麼檢視其中一個就好。
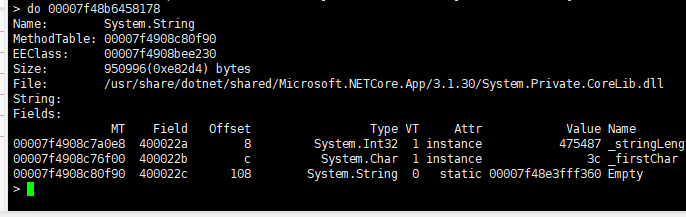
95m差不吧。
然後看下其位置:gcroot -all 00007f48b6458178
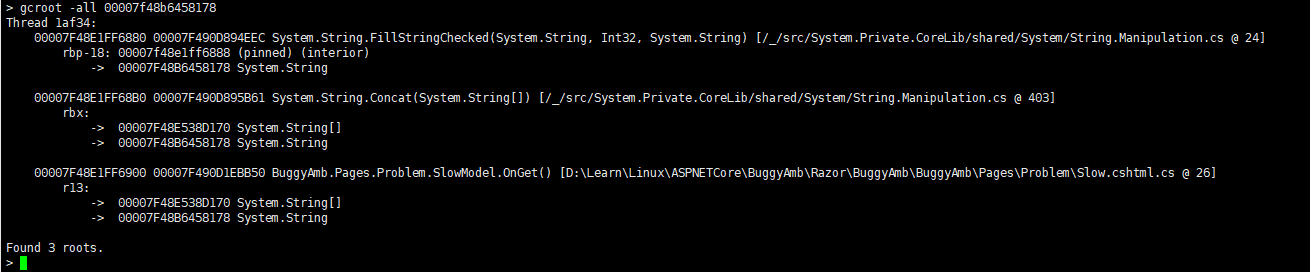
這樣就找到了程式碼的位置。
結
該系列逐步補充,補的是一些排查技巧和一些原理,為什麼這樣抓取,為什麼能抓到之類的,怎麼排查更快之流。
持續更新。。。。。。。