Oracle收集統計資訊的一些思考
一、問題
- Oracle在收集統計資訊時預設的取樣比例是DBMS_STATS.AUTO_SAMPLE_SIZE,那麼AUTO_SAMPLE_SIZE的值具體是多少?
- 假設取樣比例為10%,那麼在計算單個列的distinct時與實際的差別大嗎?
- 有哪些取樣演演算法?
二、實驗
準備三張實驗表,t1/t2/t3,這三張表的資料內容完全一致,我們分別使用100%、10%、AUTO_SAMPLE_SIZE的比例去收集他們的統計資訊。
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T1',
5 estimate_percent => 100
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T2',
5 estimate_percent => 10
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname => 'BAO',
4 tabname => 'T3',
5 estimate_percent => dbms_stats.auto_sample_size
6 );
7 end;
8 /
PL/SQL procedure successfully completed.
檢視這三張表的統計資訊,可以看到採用100%和AUTO_SAMPLE_SIZE這兩種方式收集的統計資訊的SAMPLE_SIZE相同,都是全量收集。
SQL> select table_name, num_rows, sample_size from user_tables where table_name in ('T1', 'T2', 'T3');
TABLE_NAME NUM_ROWS SAMPLE_SIZE
-------------- ---------- -----------
T1 145334 145334
T2 146190 14619
T3 145334 145334
官方檔案並沒有說明AUTO_SAMPLE_SIZE具體的值是多少,但是從實驗結果來看,這個值就是100。這就回答了文章的第一個問題。
Oracle為什麼會預設採用100%的方式來收集統計資訊呢,在ASKTOM有同行就提出過這個問題「DBMS_STATS.AUTO_SAMPLE_SIZE seems to always generate 100%」,他們的回覆是為了得到精確的distinct列值。接下來我們就來看下全量採集和部分採集列的distinct區別。
SQL> select a.column_name, a.num_distinct "t1.num_distinct", b.num_distinct "t2.num_distinct",
2 round((a.num_distinct - b.num_distinct) * 100 / a.num_distinct, 1) "diff",
3 a.sample_size "t1.sample_size", b.sample_size "t2.sample_size"
4 from (select table_name, column_name, num_distinct, sample_size from user_tab_col_statistics where table_name in ('T1')) a,
5 (select table_name, column_name, num_distinct, sample_size from user_tab_col_statistics where table_name in ('T2')) b
6 where a.column_name = b.column_name and a.num_distinct > 0 order by "diff" desc;
COLUMN_NAME t1.num_distinct t2.num_distinct diff t1.sample_size t2.sample_size
------------------------------ --------------- --------------- ---------- -------------- --------------
OBJECT_NAME 64552 10300 84 145334 14619
SUBOBJECT_NAME 1015 385 62.1 68251 6856
TIMESTAMP 2585 1240 52 145212 14610
LAST_DDL_TIME 2490 1257 49.5 145212 14610
CREATED 2312 1209 47.7 145334 14619
NAMESPACE 21 15 28.6 145212 14610
OBJECT_TYPE 45 39 13.3 145334 14619
OWNER 80 71 11.3 145334 14619
TEMPORARY 2 2 0 145334 14619
DUPLICATED 1 1 0 145334 14619
STATUS 2 2 0 145334 14619
SHARDED 1 1 0 145334 14619
GENERATED 2 2 0 145334 14619
SECONDARY 1 1 0 145334 14619
SHARING 4 4 0 145334 14619
EDITIONABLE 2 2 0 25433 2531
ORACLE_MAINTAINED 2 2 0 145334 14619
APPLICATION 1 1 0 145334 14619
DEFAULT_COLLATION 1 1 0 16886 1705
DATA_OBJECT_ID 77785 78100 -.4 77822 7813
OBJECT_ID 145212 146100 -.6 145212 14610
T1表是全量收集,T2表是按10%的比例收集,從上面的結果可以看到,對於大部分欄位通過部分取樣的方式都能估算得很準確。但對於OBJECT_NAME這個列,估算出來的值和全量統計的差別很大,我們來看一下是什麼原因導致的。
SQL> select count(*), object_name from t1 group by object_name order by count(*) desc;
COUNT(*) OBJECT_NAME
---------- -----------------
690 S_AAA_CCD
690 S_ABA_CED
690 S_ACA_CCD
690 S_ADA_CCD
690 PK_AEA_CED
...
1 GV_$CON_SYSSTAT
1 GV_$DATAFILE
1 GV_$TABLESPACE
1 GV_$ROLLSTAT
1 GV_$PARAMETER
可以看到OBJECT_NAME這個列的資料分佈極不均勻。因此對於分佈不均勻的列,通過部分取樣方式得到的distinct值與實際的distinct值差別就會比較大。這就回答了文章的第二個問題。
三、取樣演演算法
以下是個人的一些娛樂性思考
-
等比放大,即(取樣得到distinct值 / 取樣行數) x 總行數。
舉個例子,假設表有1000行資料,只取樣100行,A列有95個不同的值,即count(distinct A) / count(A) = 95%,那麼等比放大很容易推匯出1000行資料,有950個A的不同值。但是如果這100行中B列只有2個不同的值,即count(distinct B) / count(B) = 2%,那麼對於1000行的表來講,B的不同值是不是等於2% * 1000呢?很有可能不是,說不定全表就這兩個不同值,例如性別。所以通過等比放大得到的distinct值就不準。這種演演算法有明顯的缺陷。 -
按增長率估算,即將取樣得到的前5%作為一個基數,取樣得到的後5%作為一個增長率。(假設取樣比例是10%)
還是舉個例子,假設表有1000行資料,只取樣100行,取樣的前50行,C列有40個不同值。取樣的後50行,C列又多了30個不同值,即總共有70個不同值。那麼後面的90%都會保持這個增長速度。則總體的C列不同值為40 + 30 * ((100-5)/5) = 610。再來看一種情況,假設取樣的前50行,D列有2個不同值。取樣的後50行,D列多了0個不同值,即不同值總數保持不變。那麼後面的90%都會保持這個增長速度。則總體的D列不同值仍為2。這種方式似乎比等比取樣更加合乎實際情況一點。接下來就用python去實現這個演演算法,看看與oracle的估算差別有多大。以下為python程式碼。
import random
import cx_Oracle
def func(ins):
SAMPLE_PERCENT = 10 # 取樣比例%
sample_size = int(len(ins) * SAMPLE_PERCENT / 100)
# 對資料進行取樣
sample = random.sample(ins, sample_size)
head_half_sample = sample[0:int(len(sample)/2)] # 取樣資料的前一半
head_half_sample_distinct = len(set(head_half_sample)) # 取樣資料的前一半的distinct值
full_sample_distinct = len(set(sample)) # 取樣資料的全量distinct值
tail_half_inc = full_sample_distinct - head_half_sample_distinct # 取樣資料的distinct增量
estimate_distinct = round(head_half_sample_distinct + tail_half_inc * (100 - SAMPLE_PERCENT/2) / (SAMPLE_PERCENT/2))
return estimate_distinct
def test(colname):
DATABASE_URL = 'xxxxx'
conn = cx_Oracle.connect(DATABASE_URL)
curs = conn.cursor()
sql = 'select {} from t1'.format(colname)
curs.execute(sql)
tmpdata = []
for i in curs.fetchall():
tmpdata.append(i[0])
res = func(tmpdata)
curs.close()
conn.close()
return res
for i in ['OBJECT_NAME', 'SUBOBJECT_NAME', 'TIMESTAMP', 'LAST_DDL_TIME', 'CREATED', 'NAMESPACE', 'OBJECT_TYPE',
'OWNER', 'TEMPORARY', 'DUPLICATED', 'STATUS', 'SHARDED', 'GENERATED', 'SECONDARY', 'SHARING', 'EDITIONABLE',
'ORACLE_MAINTAINED', 'APPLICATION', 'DEFAULT_COLLATION', 'DATA_OBJECT_ID', 'OBJECT_ID']:
print(i, '估算的distinct->', test(i))
執行結果
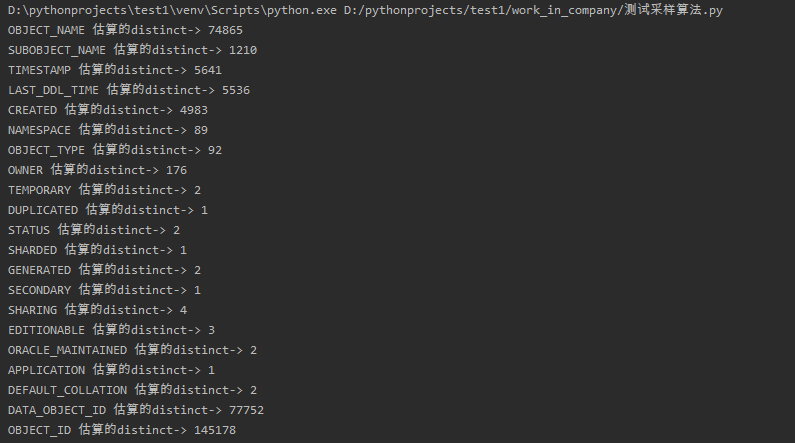
再來跟之前的一個表格進行對比,按增長率的方式估算的distinct值看上去也能接受。
COLUMN_NAME 實際的distinct 資料庫估算的distinct python估算的distinct
------------------------------ --------------- -------------------- --------------------
OBJECT_NAME 64552 10300 74865
SUBOBJECT_NAME 1015 385 1210
TIMESTAMP 2585 1240 5641
LAST_DDL_TIME 2490 1257 5536
CREATED 2312 1209 4983
NAMESPACE 21 15 89
OBJECT_TYPE 45 39 92
OWNER 80 71 176
TEMPORARY 2 2 2
DUPLICATED 1 1 1
STATUS 2 2 2
SHARDED 1 1 1
GENERATED 2 2 2
SECONDARY 1 1 1
SHARING 4 4 4
EDITIONABLE 2 2 3
ORACLE_MAINTAINED 2 2 2
APPLICATION 1 1 1
DEFAULT_COLLATION 1 1 2
DATA_OBJECT_ID 77785 78100 77752
OBJECT_ID 145212 146100 145178
限於時間,測試到此結束。後面有時間再學點統計相關的知識。