記錄因Sharding Jdbc批次操作引發的一次fullGC
週五晚上告警群突然收到了一條告警訊息,點開一看,應用 fullGC 了。

於是趕緊聯絡運維下載堆記憶體快照,進行分析。
記憶體分析
使用 MemoryAnalyzer 開啟堆檔案
mat 下載地址:https://archive.eclipse.org/mat/1.8/rcp/MemoryAnalyzer-1.8.0.20180604-win32.win32.x86_64.zip
下載下來後需要調大一下 MemoryAnalyzer.ini 組態檔裡的-Xmx2048m
開啟堆檔案後如圖:
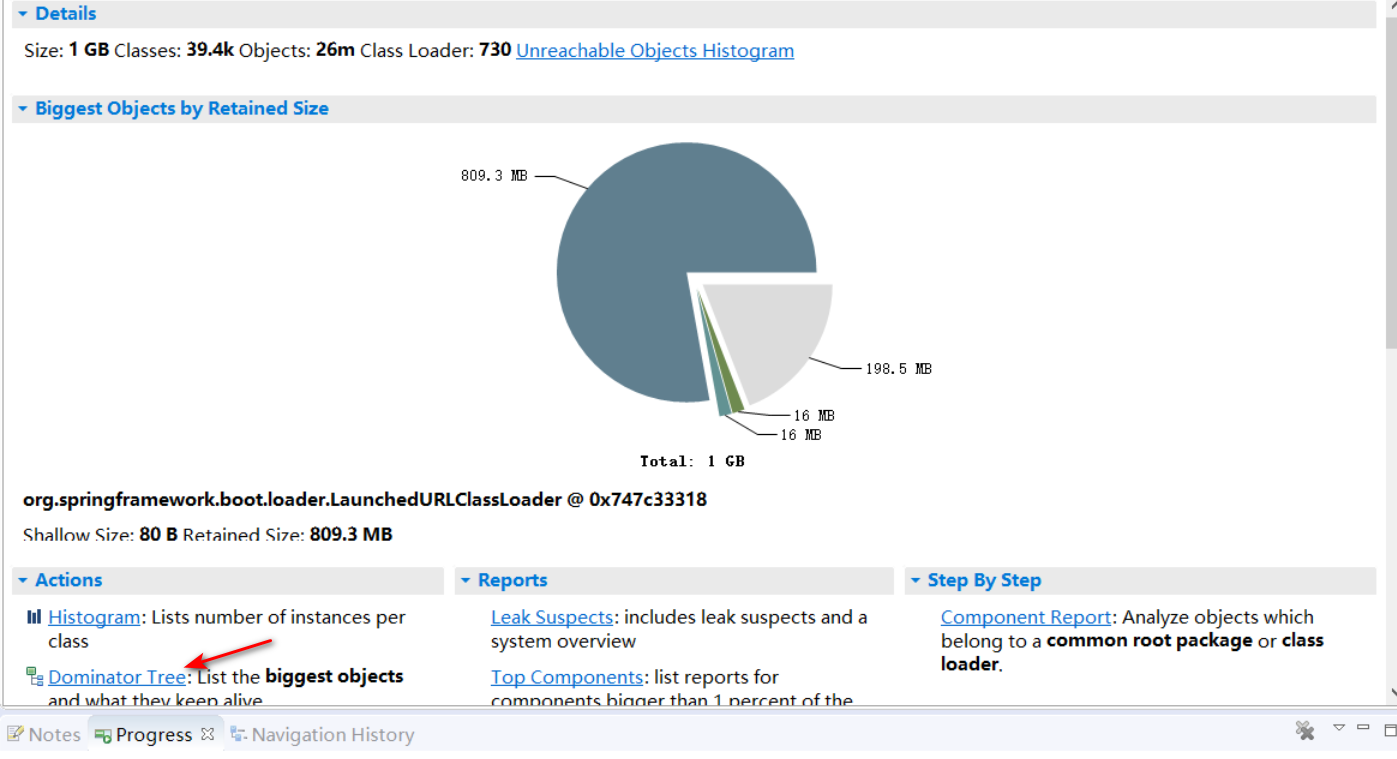
發現有 809MB 的一個佔用,應該問題就出在這塊了。然後點選 Dominator Tree,看看有什麼大的物件佔用。
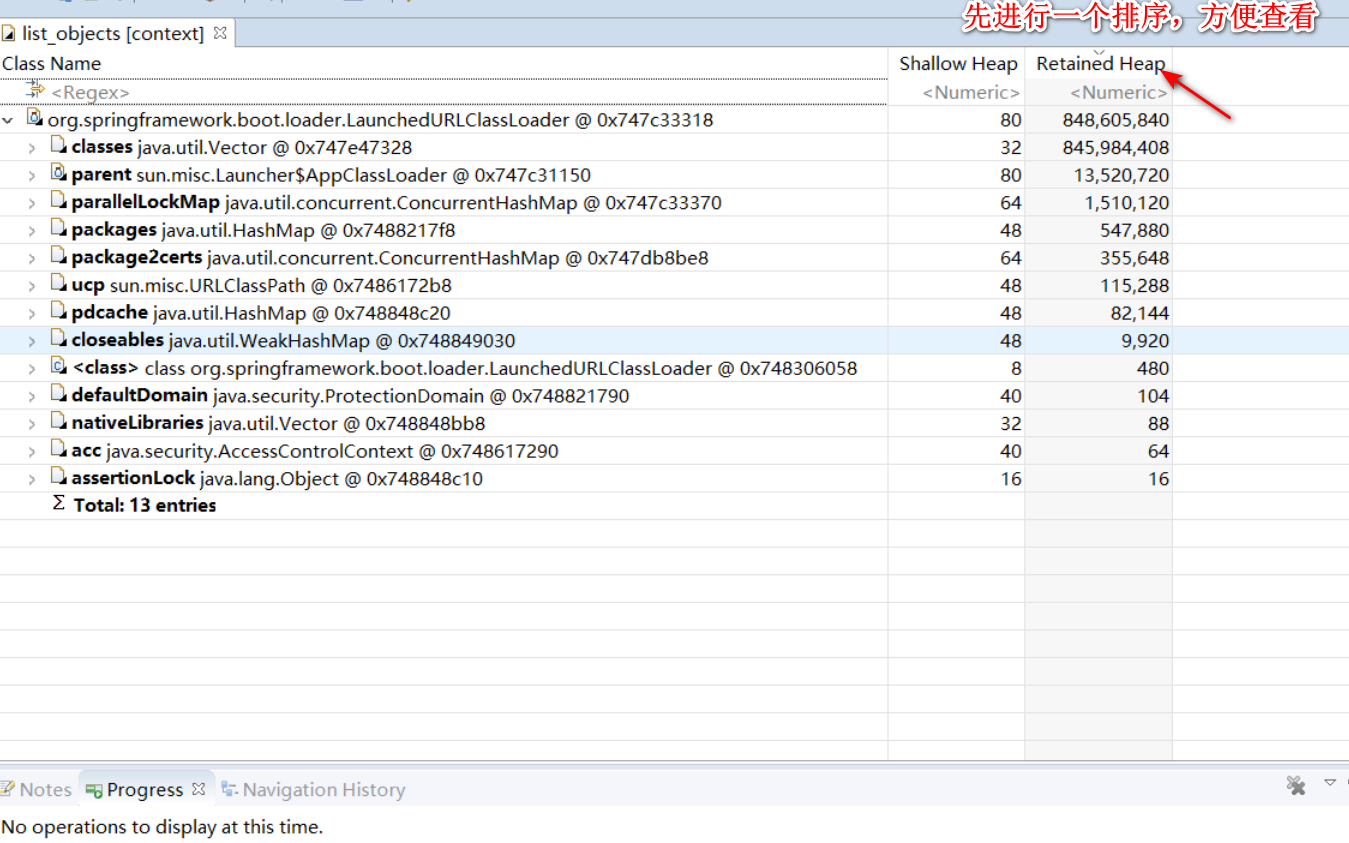
我們找大的物件,一級級往下點看看具體是誰在佔用記憶體。點到下面發現是 sharding jdbc 裡面的類,然後再繼續往下發現了一個 localCache。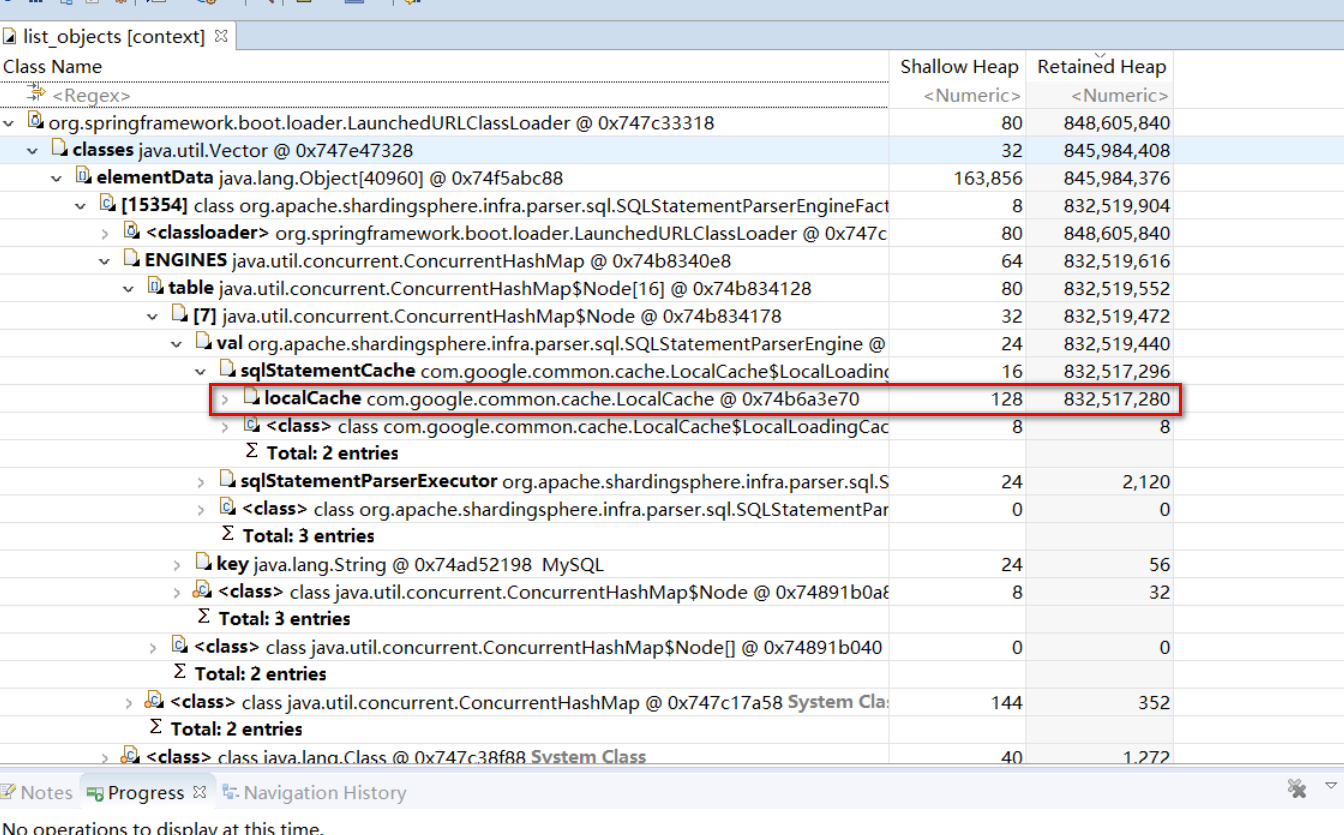
原來是一個本地快取佔了這麼大的空間
為什麼有這個 LocalCache 呢?
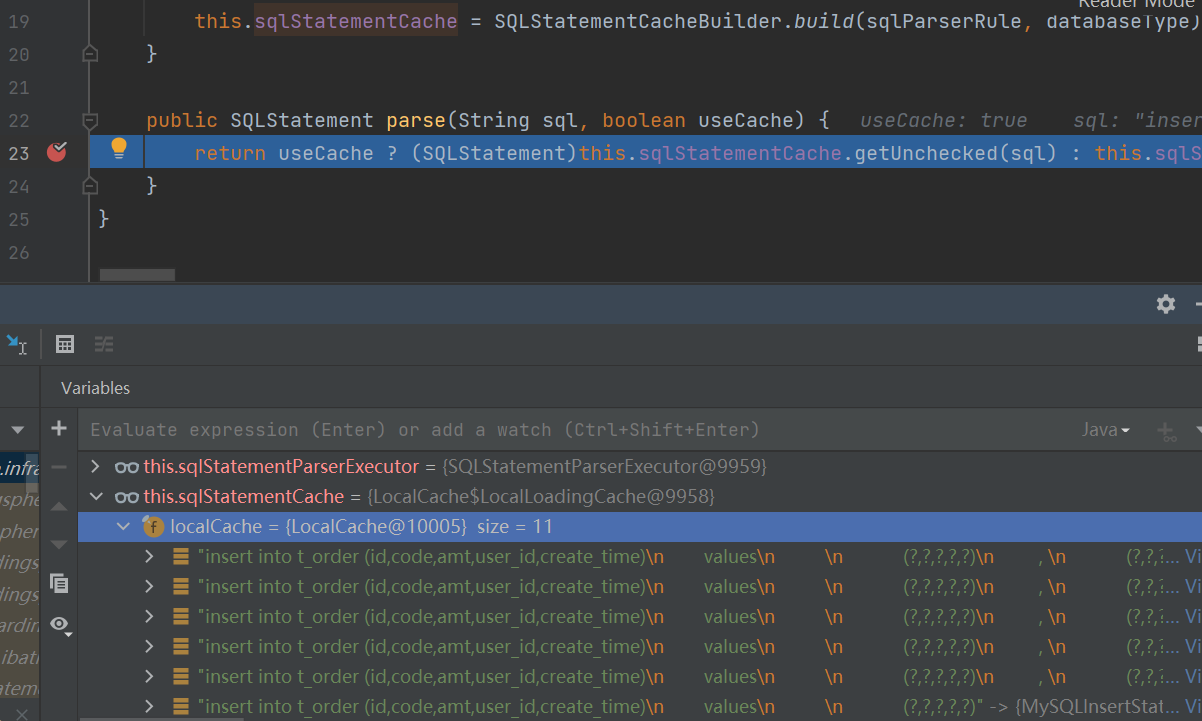
帶著這個疑惑我們去程式碼裡看看它是怎麼使用的,根據堆記憶體分析上的提示,我直接開啟了 SQLStatementParserEngine 類。
public final class SQLStatementParserEngine {
private final SQLStatementParserExecutor sqlStatementParserExecutor;
private final LoadingCache<String, SQLStatement> sqlStatementCache;
public SQLStatementParserEngine(String databaseType, SQLParserRule sqlParserRule) {
this.sqlStatementParserExecutor = new SQLStatementParserExecutor(databaseType, sqlParserRule);
this.sqlStatementCache = SQLStatementCacheBuilder.build(sqlParserRule, databaseType);
}
public SQLStatement parse(String sql, boolean useCache) {
return useCache ? (SQLStatement)this.sqlStatementCache.getUnchecked(sql) : this.sqlStatementParserExecutor.parse(sql);
}
}
他這個裡面有個 LoadingCache 型別的 sqlStatementCache 物件,這個就是我們要找的快取物件。
從 parse 方法可以看出,它這裡是想用本地快取做一個優化,優化通過 sql 解析 SQLStatement 的速度。
在普通的場景使用應該是沒問題的,但是如果是進行批次操作場景的話就會有問題。
就像下面這個語句:
@Mapper
public interface OrderMapper {
Integer batchInsertOrder(List<Order> orders);
}
<insert id="batchInsertOrder" parameterType="com.mmc.sharding.bean.Order" >
insert into t_order (id,code,amt,user_id,create_time)
values
<foreach collection="list" item="item" separator=",">
(#{item.id},#{item.code},#{item.amt},#{item.userId},#{item.createTime})
</foreach>
</insert>
1)我傳入的 orders 的個數不一樣,會拼出很多不同的 sql,生成不同的 SQLStatement,都會被放入到快取中
2)因為批次操作的拼接,sql 本身長度也很大。如果我傳入的 orders 的 size 是 1000,那麼這個 sql 就很長,也比普通的 sql 更佔用記憶體。
綜上,就會導致大量的記憶體消耗,如果是請求速度很快的話,就就有可能導致頻繁的 FullGC。
解決方案
因為是引數個數不同而導致的拼成 Sql 的不一致,所以我們解決引數個數就行了。
我們可以將傳入的引數按我們指定的集合大小來拆分,即不管傳入多大的集合,都拆為{300, 200, 100, 50, 25, 10, 5, 2, 1}這裡面的個數的集合大小。如傳入 220 大小的集合,就拆為[{200},{10},{10}],這樣分三次去執行 sql,那麼生成的 SQL 快取數也就只有我們指定的固定數位的個數那麼多了,基本不超過 10 個。
接下來我們實驗一下,改造前和改造後的 gc 情況。
測試程式碼如下:
@RequestMapping("/batchInsert")
public String batchInsert(){
for (int j = 0; j < 1000; j++) {
List<Order> orderList = new ArrayList<>();
int i1 = new Random().nextInt(1000) + 500;
for (int i = 0; i < i1; i++) {
Order order=new Order();
order.setCode("abc"+i);
order.setAmt(new BigDecimal(i));
order.setUserId(i);
order.setCreateTime(new Date());
orderList.add(order);
}
orderMapper.batchInsertOrder(orderList);
System.out.println(j);
}
return "success";
}
GC 情況如圖所示:
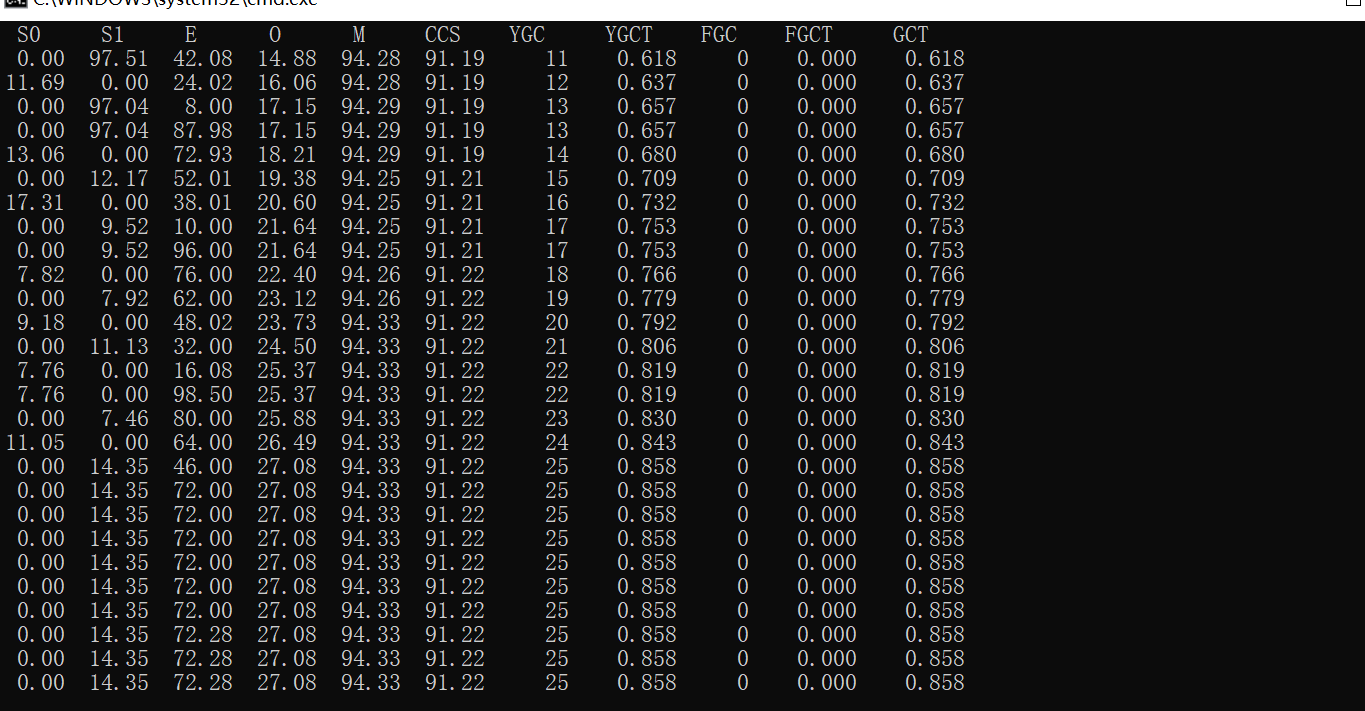
cache 裡面存有元素:

修改程式碼後:
@RequestMapping("/batchInsert")
public String batchInsert(){
for (int j = 0; j < 1; j++) {
List<Order> orderList = new ArrayList<>();
int i1 = new Random().nextInt(1000) + 500;
for (int i = 0; i < i1; i++) {
Order order=new Order();
order.setCode("abc"+i);
order.setAmt(new BigDecimal(i));
order.setUserId(i);
order.setCreateTime(new Date());
orderList.add(order);
}
List<List<Order>> shard = ShardingUtils.shard(orderList);
shard.stream().forEach(
orders->{
orderMapper.batchInsertOrder(orders);
}
);
System.out.println(j);
}
return "success";
}
GC 情況如下:
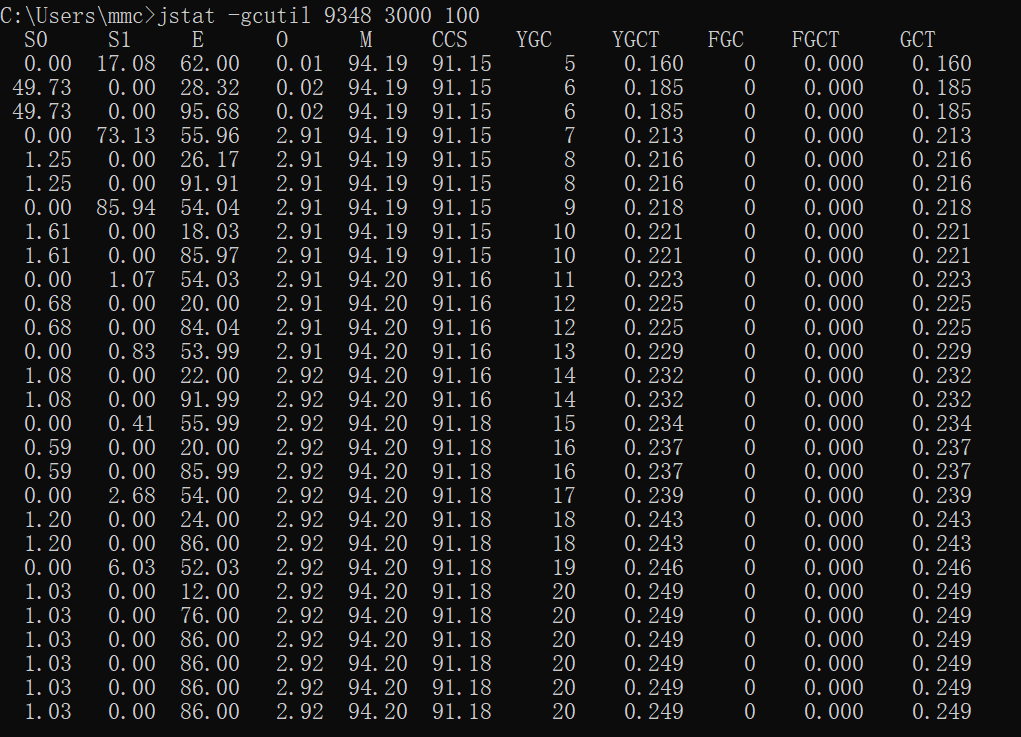
cache 裡面存有元素:
可以看出 GC 次數有減少,本地快取的條數由 600 多減到了 11 個,如果匯出堆記憶體還能看出至少降低了幾百 M 的本地記憶體佔用。
另外,這個 cache 是有大小限制的,如果因為一個 sql 佔了 600 多個位置,那麼其他的 sql 的快取就會被清理,導致其他 SQL 效能會受到影響,甚至如果機器本身記憶體不高,還會因為這個 cache 過大而導致頻繁的 Full GC
大家以後在使用 Sharding JDBC 進行批次操作的時候就需要多注意了
另附上拆分為固定大小的陣列的工具方法如下:
public class ShardingUtils {
private static Integer[] nums = new Integer[]{800,500,300, 200, 100, 50, 25, 10, 5, 2, 1};
public static <T> List<List<T>> shard(final List<T> originData) {
return shard(originData, new ArrayList<>());
}
private static <T> List<List<T>> shard(final List<T> originData, List<List<T>> result) {
if (originData.isEmpty()) {
return result;
}
for (int i = 0; i < nums.length; i++) {
if (originData.size() >= nums[i]) {
List<T> ts = originData.subList(0, nums[i]);
result.add(ts);
List<T> ts2 = originData.subList(nums[i], originData.size());
if (ts2.isEmpty()) {
return result;
} else {
return shard(ts2, result);
}
}
}
return result;
}
}