.NET效能優化-是時候換個序列化協定了
計算機單機效能一直受到摩爾定律的約束,隨著行動網際網路的興趣,單機效能不足的瓶頸越來越明顯,制約著整個行業的發展。不過我們雖然不能無止境的縱向擴容系統,但是我們可以分散式、橫向的擴容系統,這聽起來非常的美好,不過也帶來了今天要說明的問題,分散式的節點越多,通訊產生的成本就越大。
- 網路傳輸頻寬變得越來越緊缺,我們伺服器的標配上了10Gbps的網路卡
- HTTPx.x 時代TCP/IP協定通訊低效,我們即將用上QUIC HTTP 3.0
- 同機器走Socket協定棧太慢,我們用起了eBPF
- ....
現在我們的應用程式花在網路通訊上的時間太多了,其中花在序列化上的時間也非常的多。我們和大家一樣,在內部微服務通訊序列化協定中,絕大的部分都是用JSON。JSON的好處很多,首先就是它對人非常友好,我們能直接讀懂它的含義,但是它也有著致命的缺點,那就是它序列化太慢、序列化以後的字串太大了。
之前筆者做一個專案時,就遇到了一個選型的問題,我們有數億行資料需要快取到Redis中,每行資料有數百個欄位,如果用Json序列化儲存的話它的記憶體消耗是數TB級別的(部署個叢集再做個主從、多中心 需要成倍的記憶體、太貴了,用不起)。於是我們就在找有沒有除了JSON其它更好的序列化方式?
看看都有哪些
目前市面上序列化協定有很多比如XML、JSON、Thrift、Kryo等等,我們選取了在.NET平臺上比較常用的序列化協定來做比較:
- JSON:JSON是一種輕量級的資料交換格式。採用完全獨立於程式語言的文字格式來儲存和表示資料。簡潔和清晰的層次結構使得 JSON 成為理想的資料交換語言。
- Protobuf:Protocol Buffers 是一種語言無關、平臺無關、可延伸的序列化結構資料的方法,它可用於(資料)通訊協定、資料儲存等,它類似XML,但比它更小、更快、更簡單。
- MessagePack:是一種高效的二進位制序列化格式。它可以讓你像JSON一樣在多種語言之間交換資料。但它更快、更小。小的整數被編碼成一個位元組,典型的短字串除了字串本身之外,只需要一個額外的位元組。
- MemoryPack:是Yoshifumi Kawai大佬專為C#設計的一個高效的二進位制序列化格式,它有著.NET平臺很多新的特性,並且它是Code First開箱即用,非常簡單;同時它還有著非常好的效能。
我們選擇的都是.NET平臺上比較常用的,特別是後面的三種都宣稱自己是非常小,非常快的,那麼我們就來看看到底是誰最快,誰序列化後的結果最小。
準備工作
我們準備了一個DemoClass類,裡面簡單的設定了幾個不同型別的屬性,然後依賴了一個子類陣列。暫時忽略上面的一些頭標記。
[MemoryPackable]
[MessagePackObject]
[ProtoContract]
public partial class DemoClass
{
[Key(0)] [ProtoMember(1)] public int P1 { get; set; }
[Key(1)] [ProtoMember(2)] public bool P2 { get; set; }
[Key(2)] [ProtoMember(3)] public string P3 { get; set; } = null!;
[Key(3)] [ProtoMember(4)] public double P4 { get; set; }
[Key(4)] [ProtoMember(5)] public long P5 { get; set; }
[Key(5)] [ProtoMember(6)] public DemoSubClass[] Subs { get; set; } = null!;
}
[MemoryPackable]
[MessagePackObject]
[ProtoContract]
public partial class DemoSubClass
{
[Key(0)] [ProtoMember(1)] public int P1 { get; set; }
[Key(1)] [ProtoMember(2)] public bool P2 { get; set; }
[Key(2)] [ProtoMember(3)] public string P3 { get; set; } = null!;
[Key(3)] [ProtoMember(4)] public double P4 { get; set; }
[Key(4)] [ProtoMember(5)] public long P5 { get; set; }
}
System.Text.Json
選用它的原因很簡單,這應該是.NET目前最快的JSON序列化框架之一了,它的使用非常簡單,已經內建在.NET BCL中,只需要參照System.Text.Json名稱空間,存取它的靜態方法即可完成序列化和反序列化。
using System.Text.Json;
var obj = ....;
// Serialize
var json = JsonSerializer.Serialize(obj);
// Deserialize
var newObj = JsonSerializer.Deserialize<T>(json)
Google Protobuf
.NET上最常用的一個Protobuf序列化框架,它其實是一個工具包,通過工具包+*.proto檔案可以生成GRPC Service或者對應實體的序列化程式碼,不過它使用起來有點麻煩。
使用它我們需要兩個Nuget包,如下所示:
<!--Google.Protobuf 序列化和反序列化幫助類-->
<PackageReference Include="Google.Protobuf" Version="3.21.9" />
<!--Grpc.Tools 用於生成protobuf的序列化反序列化類 和 GRPC服務-->
<PackageReference Include="Grpc.Tools" Version="2.50.0">
<PrivateAssets>all</PrivateAssets>
<IncludeAssets>runtime; build; native; contentfiles; analyzers; buildtransitive</IncludeAssets>
</PackageReference>
由於它不能直接使用C#物件,所以我們還需要建立一個*.proto檔案,佈局和上面的C#類一致,加入了一個DemoClassArrayProto方便後面測試:
syntax="proto3";
option csharp_namespace="DemoClassProto";
package DemoClassProto;
message DemoClassArrayProto
{
repeated DemoClassProto DemoClass = 1;
}
message DemoClassProto
{
int32 P1=1;
bool P2=2;
string P3=3;
double P4=4;
int64 P5=5;
repeated DemoSubClassProto Subs=6;
}
message DemoSubClassProto
{
int32 P1=1;
bool P2=2;
string P3=3;
double P4=4;
int64 P5=5;
}
做完這一些後,還需要在專案檔案中加入如下的設定,讓Grpc.Tools在編譯時生成對應的C#類:
<ItemGroup>
<Protobuf Include="*.proto" GrpcServices="Server" />
</ItemGroup>
然後Build當前專案的話就會在obj目錄生成C#類:
最後我們可以用下面的方法來實現序列化和反序列化,泛型型別T是需要繼承IMessage<T>從*.proto生成的實體(用起來還是挺麻煩的):
using Google.Protobuf;
// Serialize
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static byte[] GoogleProtobufSerialize<T>(T origin) where T : IMessage<T>
{
return origin.ToByteArray();
}
// Deserialize
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public DemoClassArrayProto GoogleProtobufDeserialize(byte[] bytes)
{
return DemoClassArrayProto.Parser.ParseFrom(bytes);
}
Protobuf.Net
那麼在.NET平臺protobuf有沒有更簡單的使用方式呢?答案當然是有的,我們只需要依賴下面的Nuget包:
<PackageReference Include="protobuf-net" Version="3.1.22" />
然後給我們需要進行序列化的C#類打上ProtoContract特性,另外將所需要序列化的屬性打上ProtoMember特性,如下所示:
[ProtoContract]
public class DemoClass
{
[ProtoMember(1)] public int P1 { get; set; }
[ProtoMember(2)] public bool P2 { get; set; }
[ProtoMember(3)] public string P3 { get; set; } = null!;
[ProtoMember(4)] public double P4 { get; set; }
[ProtoMember(5)] public long P5 { get; set; }
}
然後就可以直接使用框架提供的靜態類進行序列化和反序列化,遺憾的是它沒有提供直接返回byte[]的方法,不得不使用一個MemoryStrem:
using ProtoBuf;
// Serialize
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static void ProtoBufDotNet<T>(T origin, Stream stream)
{
Serializer.Serialize(stream, origin);
}
// Deserialize
public T ProtobufDotNet(byte[] bytes)
{
using var stream = new MemoryStream(bytes);
return Serializer.Deserialize<T>(stream);
}
MessagePack
這裡我們使用的是Yoshifumi Kawai實現的MessagePack-CSharp,同樣也是引入一個Nuget包:
<PackageReference Include="MessagePack" Version="2.4.35" />
然後在類上只需要打一個MessagePackObject的特性,然後在需要序列化的屬性打上Key特性:
[MessagePackObject]
public partial class DemoClass
{
[Key(0)] public int P1 { get; set; }
[Key(1)] public bool P2 { get; set; }
[Key(2)] public string P3 { get; set; } = null!;
[Key(3)] public double P4 { get; set; }
[Key(4)] public long P5 { get; set; }
}
使用起來也非常簡單,直接呼叫MessagePack提供的靜態類即可:
using MessagePack;
// Serialize
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static byte[] MessagePack<T>(T origin)
{
return global::MessagePack.MessagePackSerializer.Serialize(origin);
}
// Deserialize
public T MessagePack<T>(byte[] bytes)
{
return global::MessagePack.MessagePackSerializer.Deserialize<T>(bytes);
}
另外它提供了Lz4演演算法的壓縮程式,我們只需要設定Option,即可使用Lz4壓縮,壓縮有兩種方式,Lz4Block和Lz4BlockArray,我們試試:
public static readonly MessagePackSerializerOptions MpLz4BOptions = MessagePackSerializerOptions.Standard.WithCompression(MessagePackCompression.Lz4Block);
// Serialize
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static byte[] MessagePackLz4Block<T>(T origin)
{
return global::MessagePack.MessagePackSerializer.Serialize(origin, MpLz4BOptions);
}
// Deserialize
public T MessagePackLz4Block<T>(byte[] bytes)
{
return global::MessagePack.MessagePackSerializer.Deserialize<T>(bytes, MpLz4BOptions);
}
MemoryPack
這裡也是Yoshifumi Kawai大佬實現的MemoryPack,同樣也是引入一個Nuget包,不過需要注意的是,目前需要安裝VS 2022 17.3以上版本和.NET7 SDK,因為MemoryPack程式碼生成依賴了它:
<PackageReference Include="MemoryPack" Version="1.4.4" />
使用起來應該是這幾個二進位制序列化協定最簡單的了,只需要給對應的類加上partial關鍵字,另外打上MemoryPackable特性即可:
[MemoryPackable]
public partial class DemoClass
{
public int P1 { get; set; }
public bool P2 { get; set; }
public string P3 { get; set; } = null!;
public double P4 { get; set; }
public long P5 { get; set; }
}
序列化和反序列化也是呼叫靜態方法:
// Serialize
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static byte[] MemoryPack<T>(T origin)
{
return global::MemoryPack.MemoryPackSerializer.Serialize(origin);
}
// Deserialize
public T MemoryPack<T>(byte[] bytes)
{
return global::MemoryPack.MemoryPackSerializer.Deserialize<T>(bytes)!;
}
它原生支援Brotli壓縮演演算法,使用如下所示:
// Serialize
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public static byte[] MemoryPackBrotli<T>(T origin)
{
using var compressor = new BrotliCompressor();
global::MemoryPack.MemoryPackSerializer.Serialize(compressor, origin);
return compressor.ToArray();
}
// Deserialize
public T MemoryPackBrotli<T>(byte[] bytes)
{
using var decompressor = new BrotliDecompressor();
var decompressedBuffer = decompressor.Decompress(bytes);
return MemoryPackSerializer.Deserialize<T>(decompressedBuffer)!;
}
跑個分吧
我使用BenchmarkDotNet構建了一個10萬個物件序列化和反序列化的測試,原始碼在末尾的Github連結可見,比較了序列化、反序列化的效能,還有序列化以後佔用的空間大小。
public static class TestData
{
//
public static readonly DemoClass[] Origin = Enumerable.Range(0, 10000).Select(i =>
{
return new DemoClass
{
P1 = i,
P2 = i % 2 == 0,
P3 = $"Hello World {i}",
P4 = i,
P5 = i,
Subs = new DemoSubClass[]
{
new() {P1 = i, P2 = i % 2 == 0, P3 = $"Hello World {i}", P4 = i, P5 = i,},
new() {P1 = i, P2 = i % 2 == 0, P3 = $"Hello World {i}", P4 = i, P5 = i,},
new() {P1 = i, P2 = i % 2 == 0, P3 = $"Hello World {i}", P4 = i, P5 = i,},
new() {P1 = i, P2 = i % 2 == 0, P3 = $"Hello World {i}", P4 = i, P5 = i,},
}
};
}).ToArray();
public static readonly DemoClassProto.DemoClassArrayProto OriginProto;
static TestData()
{
OriginProto = new DemoClassArrayProto();
for (int i = 0; i < Origin.Length; i++)
{
OriginProto.DemoClass.Add(
DemoClassProto.DemoClassProto.Parser.ParseJson(JsonSerializer.Serialize(Origin[i])));
}
}
}
序列化
序列化的Bemchmark的結果如下所示:
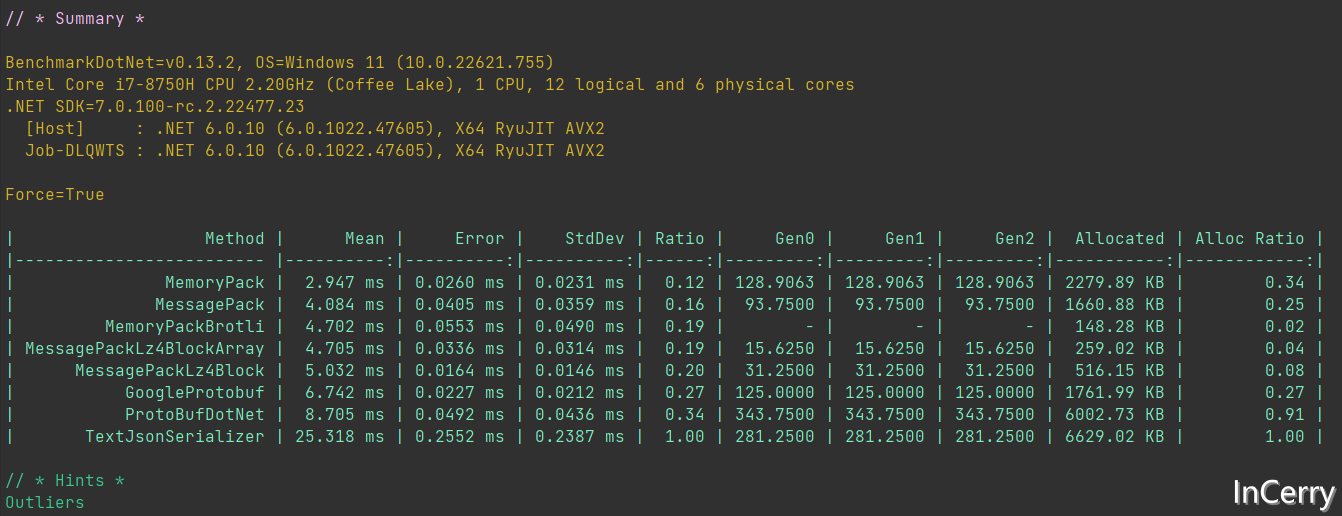
從序列化速度來看MemoryPack遙遙領先,比JSON要快88%,甚至比Protobuf快15%。

從序列化佔用的記憶體來看,MemoryPackBrotli是王者,它比JSON佔用少98%,甚至比Protobuf佔用少25%。其中ProtoBufDotNet記憶體佔用大主要還是吃了沒有byte[]返回方法的虧,只能先建立一個MemoryStream。

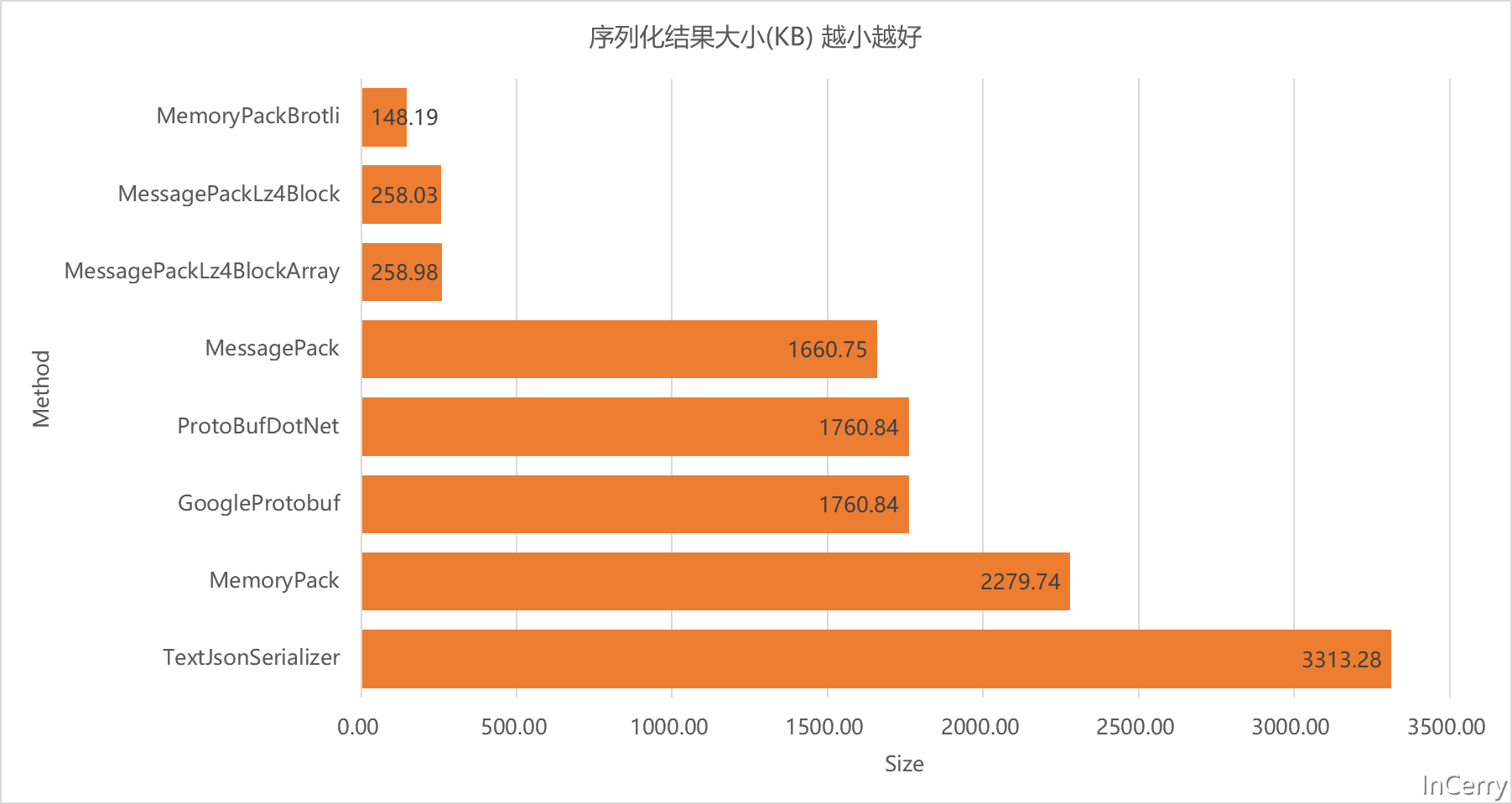
序列化結果大小
這裡我們可以看到MemoryPackBrotli贏麻了,比不壓縮的MemoryPack和Protobuf有著10多倍的差異。
反序列化
反序列化的Benchmark結果如下所示,反序列化整體開銷是比序列化大的,畢竟需要建立大量的物件:
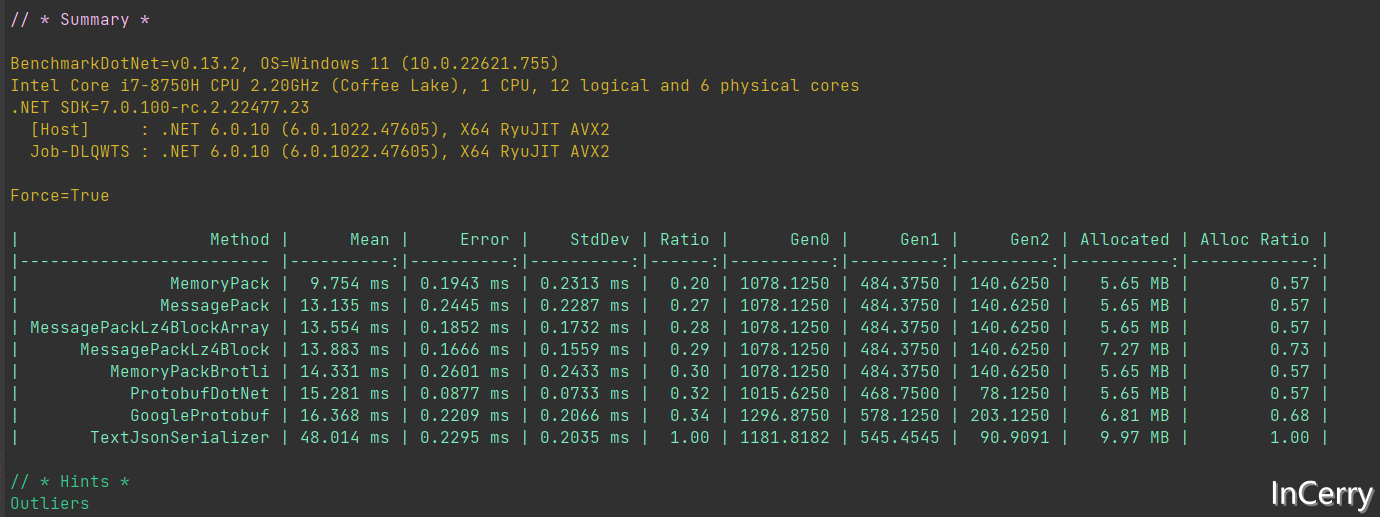
從反序列化的速度來看,不出意外MemoryPack還是遙遙領先,比JSON快80%,比Protobuf快14%。
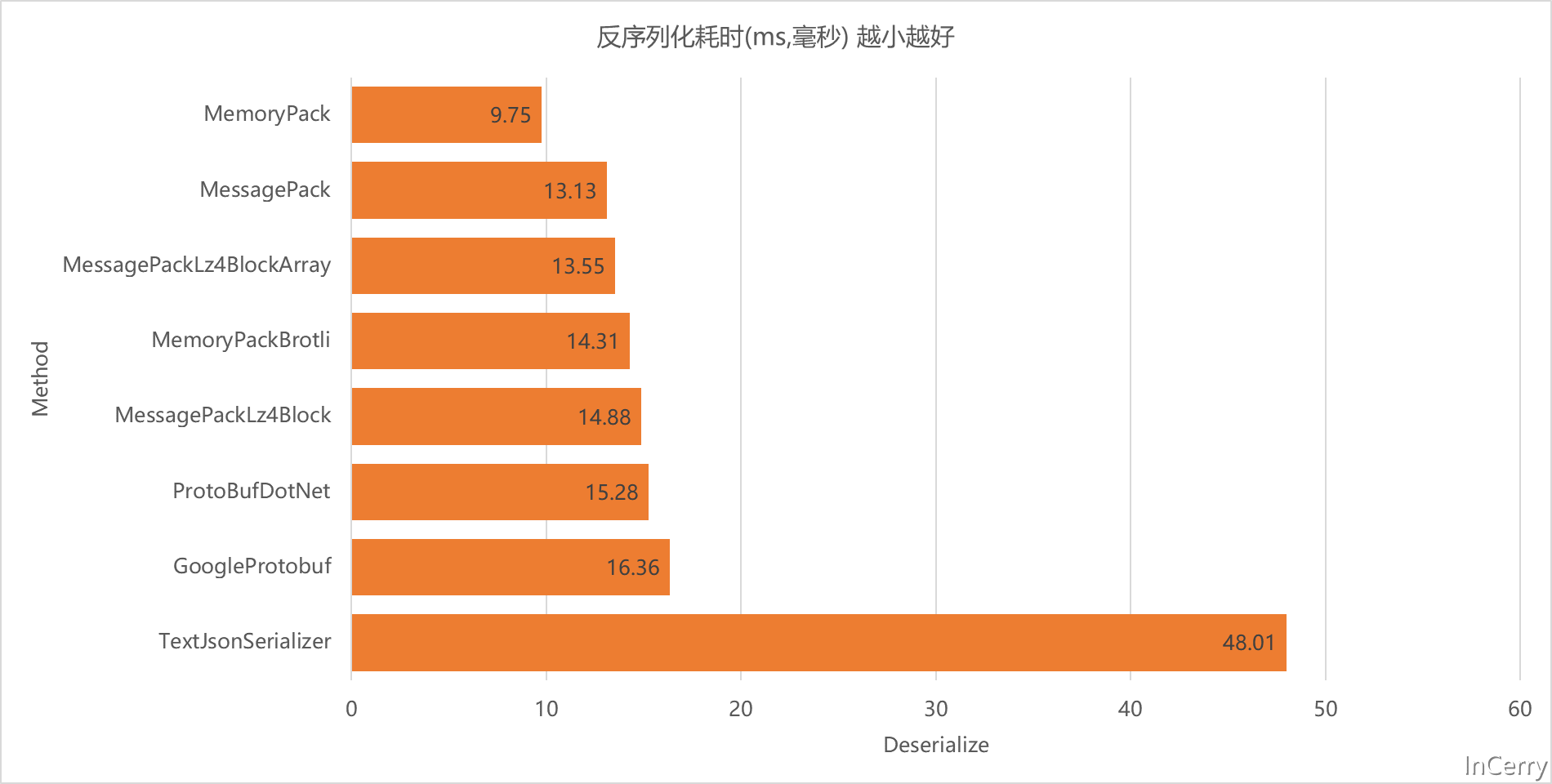
從記憶體佔用來看ProtobufDotNet是最小的,這個結果聽讓人意外的,其餘的都表現的差不多:
總結
總的相關資料如下表所示,原始資料可以在文末的Github專案地址獲取:
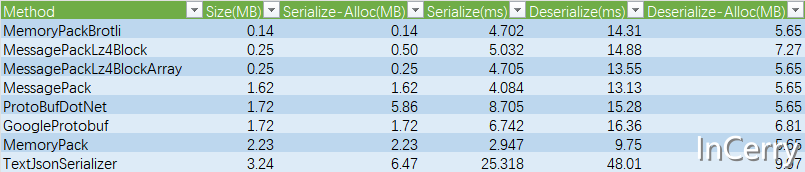
從圖表來看,如果要兼顧序列化後大小和效能的話我們應該要選擇MemoryPackBrotli,它序列化以後的結果最小,而且兼顧了效能:

不過由於MemoryPack目前需要.NET7版本,所以現階段最穩妥的選擇還是使用MessagePack+Lz4壓縮演演算法,它有著不俗的效能表現和突出的序列化大小。
回到文首的技術選型問題,筆者那個專案最終選用的是Google Protobuf這個序列化協定和框架,因為當時考慮到需要和其它語言互動,然後也需要有較小空間佔用,目前看已經佔用了111GB的Redis空間佔用。
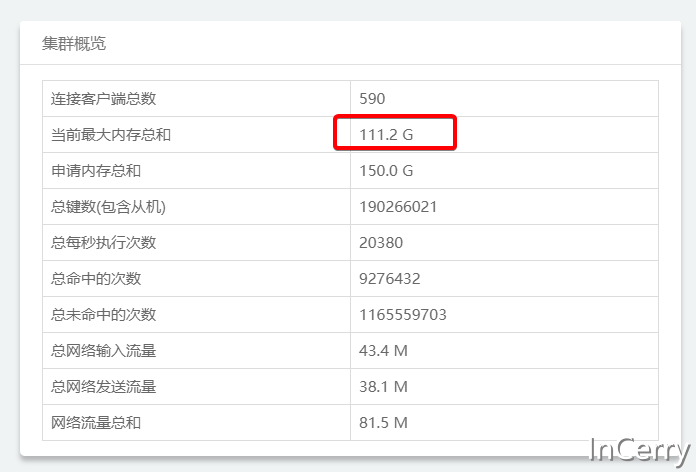
如果後續進一步增大,可以換成MessagePack+Lz4方式,應該還能節省95GB的左右空間。那可都是白花花的銀子。
當然其它協定也是可以進一步通過Gzip、Lz4、Brotli演演算法進行壓縮,不過鑑於時間和篇幅關係,沒有進一步做測試,有興趣的同學可以試試。
附錄
程式碼連結: https://github.com/InCerryGit/WhoIsFastest-Serialization