JAVA開發搞了一年多的巨量資料,究竟幹了點啥
JAVA開發搞了一年多巨量資料的總結
2021年7月份加入了當前專案組,以一個原汁原味的Java開發工程師的身份進來的,來了沒多久,專案組唯一一名巨量資料開發工程師要離職了,一時間一大堆的資料需求急需人來接手,此刻又招不來新的資料開發。沒轍,我和同組的另一位Java開發同事算是臨危受命,接下了巨量資料方面的工作,開啟了Java工程師從0到1搞巨量資料的漫長旅途,開始的磕磕碰碰叫苦不堪到如今的還算得心應手,已經整整16個月了,16個月期間雙向支援著資料分析和後端開發的工作,兩者時而穿插時而並行處理,巨量資料工作佔得比重之多,有時讓我懷疑我還是不是一名純粹的Java開發工作者,當我看見假期值班表中我的角色填寫一項變成「B端後端/資料」時,我就知道我已經不純粹了。
1.Sql -- 巨量資料分析的靈魂
搞巨量資料究竟每天在做些什麼?坦白講,情況和我想象的不太一樣,因為做巨量資料開發時最最主要的工作居然寫Sql,曾經我還以為它是有一套刁鑽困難冷門的牛逼技術,將海量資料玩弄於股掌之中。現在看來,我是每天和各種各樣的巨量資料表打交道,在巨量資料平臺用sql提取出業務方想要的資訊,有時會出各式各樣的資料包表,有時是為C端專案服務,提供底層海量資料計算的支援,有時是為各種資料看板服務,提供他們想要的銷量排行了、人群覆蓋情況了諸類。工作前兩年純粹寫java時也是對sql有所研究的,畢竟資料持久層的互動離不開sql,然後搞了巨量資料才明白,之前寫的sql都是小兒科,現在一條sql寫上百行那都是常有的事,而且最開始解讀大sql時總是慢半拍,好久才能搞明白前輩留下的交接檔案表達的是什麼,現在不一樣了,看見那些sql都親切很多,很多需求提出來總能迅速想到sql解決的方案,下面呢,我就開始分享一些我在寫大sql時經常會使用的一些語法,這些語法可能針對於只做Java的人並不會經常性的熟練使用。
1.1with.. as..
with temp1 as (
select * from ... where ..
),
temp2 as (
select * from ... where...
),
...
tempn as (
select * from ... inner join ... where
)
select a.*,b.*,c.* from temp1 a inner join temp2 b on a.id = b.id left join ..tempn c on a.iid = c.iid where ...
模板中的temp1,temp2,tempn都可以看做這個sql執行過程中的臨時表,存在週期僅限於執行這條sql期間,sql執行完畢臨時表也銷燬,並且和其他的sql是相互隔離的,下面的sql都可以使用之前的產生的臨時表(temp2就可以使用temp1的結果),使用with時最後一定跟的select語句,當然,跟的是insert into table ...... select * from也是可以的。
使用with..as..語法大大提高了長Sql的解讀性。
之前一直以為這個HiveSql特有的語法,後來才發現在mysql中也可以使用,只不過是mysql8.0以後的版本可以使用,之前的版本是沒有這個語法的。
1.2開窗函數:row_number() over(partition by file order by file2 desc/asc)
select row_number() over(partition by userid order by pay_time desc) as rn,userid,name,order_cd,goods_name,pay_time
from db_dw.table _order
having rn = 1
這個sql的作用就是找出每個使用者的最新付款的那筆訂單的訂單資訊。
實現思路就是利用開窗函數按照使用者id分組,再按照付款時間倒敘排序,給每組的資料加上一個rn的編號,每組的第一條rn 都等於 1 ,第二條rn = 2,以此類推,再通過having函數將結果中rn = 1的資料全取出來,這樣就能通過單條sql完成取每一個使用者最新一條訂單的資料需求。
1.3開窗函數lag(field, num, defaultvalue) over(partition by ..order by ..) 與 lead() over()
select lag(pay_time,1,NULL) over(partition by userid order by pay_time asc) as last_pay_time,userid,name,order_cd,goods_name,pay_time
from db_dw.table _order
select lead(pay_time,1,NULL) over(partition by userid order by pay_time asc) as next_pay_time,userid,name,order_cd,goods_name,pay_time
from db_dw.table _order
- lag(field, num, defaultvalue),其中fied是要查詢的欄位,num是向前取幾行,defaultvalue是取不到值時的預設值。向上面案例中那樣,假設按照userid分組後又按照pay_time排序了,第一個查出來的使用者剛好也有多條不同pay_time的資料,那麼查詢結果應該是第一行資料為last_pay_time為NULL,pay_time為該使用者的最小的時間,第二行資料的last_pay_time等於第一行資料的pay_time值,而pay_time為第二小的時間。
- lead(field, num, defaultvalue),其中fied是要查詢的欄位,num是向後取幾行,defaultvalue是取不到值時的預設值。向上面案例中那樣,假設按照userid分組後又按照pay_time排序了,第一個查出來的使用者剛好也有多條不同pay_time的資料,那麼查詢結果應該是第一行資料為next_pay_time為第二行的pay_time,pay_time為該使用者的最小的時間,第二行資料的next_pay_time等於第三行資料的pay_time值,而pay_time為第二小的時間,而該使用者的最後一行的next_pay_time則為NULL。
1.4case when <條件1> then <結果1> when <條件2> then <結果2> else <剩餘資料的結果> end as 欄位名
-- 將使用者年齡按照18歲及以下,18歲至65歲,65歲以上分類
select case when age<=18 then '未成年' when age>18 and age <=65 then '青中年' else '老年' end as age_group,name,age,sex
from user
case when 語法其實就是java語言的if...else if ...else if...else,當滿足條件時就進入該分支,不滿足的話就一直進入下面的分支,最後所有條件都不滿足則進入else分支,通常在Sql中我們使用case when then進行一些歸納分類,譬如我們的電商涉及到的商品種類眾多,可能需要按照某些規則進行分類,就免不了使用該語法。
1.5union,union all
select name from A
union
select name from B
select name from A
union all
select name from B
- 想去重使用union,不去重完全放一起使用union all
- 假設A表中某列有重複資料,然後A表和B表進行union,A表中的那列資料自動的去重,不僅僅是把B表中的那列和A表重複的資料去重。像案例中的union後的結果一樣,所得的name不會有一條重複資料,相當於整體的distinct了一下。
- union 和 union all查詢資料結果只以第一句sql的欄位名稱為準,後續的sql只按照順序匹配,不會識別欄位名稱
1.6partition分割區使用
-- 建立hive分割區表
create table db_demo.tb_demo (
filed1 string comment '欄位1',
filed2 int comment '欄位2'
)PARTITIONED BY(l_date string) ;
-- 刪除表分割區
alter table db_demo.tb_demo drop if exists partition(l_date = '${v_date}')
--將資料寫入表分割區
insert into table db_demo.tb_demo partition(l_date = '${v_date}')
select * from db_demo.tb_demo_v0 where ......
--覆蓋指定分割區表資料
insert overwrite table db_demo.tb_demo partition(l_date = '${v_date}')
select * from db_demo.tb_demo_v0 where ......
- 分割區表指的是在建立表時指定的partition的分割區空間。
- 一個表可以擁有一個或者多個分割區,每個分割區以資料夾的形式單獨存在表資料夾的目錄下。
- 分割區欄位會作為表的最後一個欄位出現。
1.7JSON處理
-- 取出JSON串中指定key的value值
-- 語法
get_json_object('{key1:value1,key2:value2}','$.key')
--比如取出JSON串中的name資訊
select get_json_object('{"age":1089,"name":"tom"}','$.name')
1.8日期函數
-- to_date:日期時間轉日期
select to_date(create_time) from demo_db.demo_table;
-- current_date :當前日期
select current_date
-- date_sub : 返回日期前n天的日期
select date_sub(pay_time,9) from demo_db.demo_table
-- date_add : 返回日期後n天的日期,即使放入時間引數,得到的也是日期,上一個同理,只比較日期位。
select date_add(pay_time,9) from demo_db.demo_table
-- unix_timestamp:獲取當前unix時間戳
select unix_timestamp('2022-10-10 10:22:11')
-- datediff:返回開始日期減去結束日期的天數,只比較日期位
select datediff('2022-10-10 23:22:11','2022-10-09 00:22:11')
-- 獲取當前月
select substr(current_date,1,7);
--獲取上個月最後一天
select DATE_SUB(FROM_UNIXTIME(UNIX_TIMESTAMP()),DAY(FROM_UNIXTIME(UNIX_TIMESTAMP())))
1.9炸裂函數
Hive版本:
select
id,
type_id_new
from table_one
lateral view explode(split(type_id,",")) table_one_temp as type_id_new
;
Mysql版本:
SELECT
a.id, substring_index(substring_index(a.type_id,',',b.help_topic_id + 1 ), ',' ,- 1 ) AS type_id
FROM
(select id, type_id from table_one) a
JOIN mysql.help_topic b ON b.help_topic_id <
(length(a.type_id) - length( replace(a.type_id, ',', '') ) + 1)
簡而言之,炸裂函數從命名上就可以看出,這是一個由1到多的過程,由一個裂變成多個。具體場景大概是某條資料的某個欄位裡面存放的是被相同符號分割的字串,我們暫時用逗號分割來講述,拿我們案例來講,假設一條資料的id = 1,type_id = 1,2,3 ,通過以上的炸裂函數處理之後,該條查詢結果將變成3條,分別為id=1、type_id_new =1,id=1、type_id_new =2,id=1、type_id_new =3,也就是被炸裂的欄位資料分割,剩餘欄位全部保持不變。
1.10 COALESCE ( expression,value1,value2……,valuen)
select coalesce(demo_id1,demo_id2,demo_id3) from demo_db.demo_table ;
select coalesce(case when demo_name like '%杰倫%' then '傑粉' when demo_name like '%許嵩% ' then '嵩鼠' else '小瀧包' end,
demo_name2);
coalesce函數其實就是找到第一個不為NULL的表示式,將其結果返回,假設全部為NULL,最後只能返回NULL,從我以上案例可以看出來,每個引數不僅僅可以寫欄位,也可以嵌入其他的表示式,像第二行嵌入了一串case when then,那也僅僅是一個引數而已。
注意點,coalesce函數只是判斷是否為NULL,它不會判斷空串,假設第一個不為NULL的引數為空串‘’,那麼它也會將這個空串當做有值查出來的。
1.11 group by field1,field2 having
select year,sex,goods_name,sum(goods_number) as num
from demo_db.demo_table
group by year,sex,goods_name
having num>1000
group by 用法確實比較常見,寫在這裡也是因為平時做資料統計基本每次都會用得到,想著寫上吧顯得沒什麼技術含量,不寫又對不起這個好用的聚合語法,以上的demo呢便是統計每一年男女各對每種商品的購買量是多少,並把銷量在1000以上的資料找出來,這個寫法便是先對年份分組,再對性別分組,然後又對商品名稱分組,分好組後便使用sum函數對商品銷量進行求和。
1.12 隨機抽樣:distribute by rand() sort by rand()
select * from ods_user_bucket_log distribute by rand() sort by rand() limit 10;
rand函數前的distribute和sort關鍵字可以保證資料在mapper和reducer階段是隨機分佈的,像用例中寫的那樣就是隨機抽樣取10條資料。
1.13 A left join B on a.field1= b.filed1 where B.field1 is null
select a.*
from demo_db.demo_tableA a
left join demo_db.demo_tableB b
on a.demo_id = b.demo_id where b.demo_id is null
left join 這個寫法一讓我拿出來介紹屬實讓人笑掉大牙,左連線麼,誰不會,左表全查白。當然,我列出來這個當然不是通俗的告訴大家一下我會左連線哎,我好棒棒啊,其實就是因為平時工作時總是需要把某表A和另一表B中做比較,將A中存在的屬於B的部分給排除掉,此刻,我上述寫的萬能公式便能用到了,別笑,語法簡單,但是遇到這種情況時,不經常寫Sql的人可能都想不太到。
再補充一個知識點,在使用連線時,主表越小,那麼查詢效率越高,因此如果遇到一些inner join場景,主表次表換一下位置對查詢結果沒影響的話,可以記著將資料量欄位量小的表放在主表位置上。
1.14 建立函數呼叫Jave-Jar中的方法
--語法
create temporary function 方法名 as 'java類的全限定名' using jar 'jar包在hdfs上的位置';
--案例
create temporary function decryption as 'com.zae.aes.Decrypt' using jar 'hdfs://namenodeha/user/zae/secret/decryption_demo.jar';
1.15 擺出一條大SQL看看

這個是最近寫的一條中等規模大小的SQL吧,只有50行左右而已,其他太長的也不好截圖,裡面就用到了一些前面講述的SQL語法,當然,這個SQL的業務場景需求我就不再贅述了,因為原本的SQL已經被我大批次的用新隨便定義的表名和欄位給替換了,目前已經面目全非了,畢竟不能暴露公司的一些業務的東西吧,之所以粘出來還是想實際的介紹下我前面那14條是怎樣的結合著嵌入到一個SQL中的,隨便看看就好,不需要深究其意思。
2.Presto/Spark/Mapreduce 計算引擎對比
平時一直使用巨量資料平臺進行一些資料的處理,在執行查詢語句時,是可以選擇使用Presto,Spark,MapReduce不同的計算引擎進行工作,坦白講,初次接觸時也沒搞明白它們的區別是什麼,只知道有些SQL放在Presto引擎上執行準報錯,但是放在Spark上就不會報錯,它們的語法還是有差異的,presto沒有spark內嵌的函數多。據資料前輩給交接介紹時,大致就說,如果是單表查詢,查詢一些單表的資料量,聚合分組諸類,就使用Presto,相對來講是比較快的;但是要同時使用到多個巨量資料表查詢,那就使用Spark和MR是比較快些的;另外,Spark和MR相比,Spark運算速度應該有一些優勢,但是遇到了特別特別大的計算量級時,資源再不夠用,那麼可能就會發生一些job abort,time out等比較讓人牙疼的報錯,畢竟這些報錯不是由於SQL本身的編寫出現的問題,而是和資源不夠用相關,而且往往出現這個問題都是發生在SQL執行很久之後,記著我剛接手巨量資料沒一個月時,曾經寫了一條SQL執行了三個小時,最後給我了報了個time out,氣得我沒把鍵盤摔了!反過來看,使用MR的話好像很少會發生以上陳述問題,它可能會慢些,但它最後一定會不辱使命幫你執行完畢。
2.1 Presto
Presto我講不了特別深,畢竟我平時對於它的使用也僅僅是選擇了這個引擎,然後執行了我寫下的單表執行的SQL,不過有一點可以確定,他對你填寫的型別的要求是苛刻的,比如假設你定義了一個欄位叫做user_id,給定的它的型別為string(不是誤寫,在hive中就是定義為string,你可以理解為mysql中的varchar型別),於是你寫了一條SQL:select * from demo_db.demo_user where user_id = 1001,那麼它對於presto引擎執行那將會報錯的,因為他檢查語法時會發現你輸入的1001是個整型數值,和string型別不匹配,但是對於Spark引擎執行時就不會出這個問題,我覺得Spark底層應該是對1001做了轉化,將這個整型數值1001轉化為了字串‘1001’,故可以去做正常的查詢。下面我將整理幾條關於Presto的介紹吧放在這裡,也是我從各類網站中瞭解來的,可能對實際開發用處不大,但起碼我們知道自己用了個什麼計算引擎吧。
- Presto是一個facebook開源的分散式SQL查詢引擎,適用於互動式分析查詢,資料量支援GB到PB位元組
- Presto是一款記憶體計算型的引擎,所以對於記憶體管理必須做到精細,才能保證query有序、順利的執行,部分發生餓死、死鎖等情況。也正是因為它是基於記憶體計算的,它的速度也是很快的。
- Presto採用典型的master-slave模型,master主要負責對從節點的一些管理以及query的解析和排程,而slave則是負責一些計算和讀寫。
2.2 Spark
Spark是一個平行計算框架,適用於大規模的資料處理。Spark也是一個基於記憶體的計算引擎,專門解決巨量資料的分散式問題,它是hadoop的一個補充,因此可以在Haddop檔案系統中並行執行。
平時使用最多的還是SparkSql,用於一些查詢,或者是搭建一些定時Job,使用SparkSql元件去完成對資料的抽取、轉換、載入,但是查閱了相關介紹,Spark的應用遠遠不止這些,它還有一些流計算、機器學習、圖計算的場景應用,下面有一段關於Spark應用場景介紹,是從<https://help.aliyun.com/document_detail/441938.html>中看來了,我就不用我笨拙的語言來編排了,放在下面供大家探討一下:
-
離線ETL
離線ETL主要應用於資料倉儲,對大規模的資料進行抽取(Extract)、轉換(Transform)和載入(Load),其特點是資料量大,耗時較長,通常設定為定時任務執行。
-
線上資料分析(OLAP)
線上資料分析主要應用於BI(Business Intelligence)。分析人員互動式地提交查詢作業,Spark可以快速地返回結果。除了Spark,常見的OLAP引擎包括Presto和Impala等。Spark 3.0的主要特性在EMR中的Spark 2.4版本已支援,更多特性詳情請參見Spark SQL Guide。
-
流計算
流計算主要應用於實時大屏、實時風控、實時推薦和實時報警監控等。流計算主要包括Spark Streaming和Flink引擎,Spark Streaming提供DStream和Structured Streaming兩種介面,Structured Streaming和Dataframe用法類似,門檻較低。Flink適合低延遲場景,而Spark Streaming更適合高吞吐的場景,詳情請參見Structured Streaming Programming Guide。
-
機器學習
Spark的MLlib提供了較豐富的機器學習庫,包括分類、迴歸、協同過濾、聚合,同時提供了模型選擇、自動調參和交叉驗證等工具來提高生產力。MLlib主要支援非深度學習的演演算法模組,詳情請參見Machine Learning Library (MLlib) Guide。
-
圖計算
Spark的GraphX支援圖計算的庫,支援豐富的圖計算的運算元,包括屬性運算元、結構運算元、Join運算元和鄰居聚合等。詳情請參見GraphX Programming Guide。
2.3 MapReduce
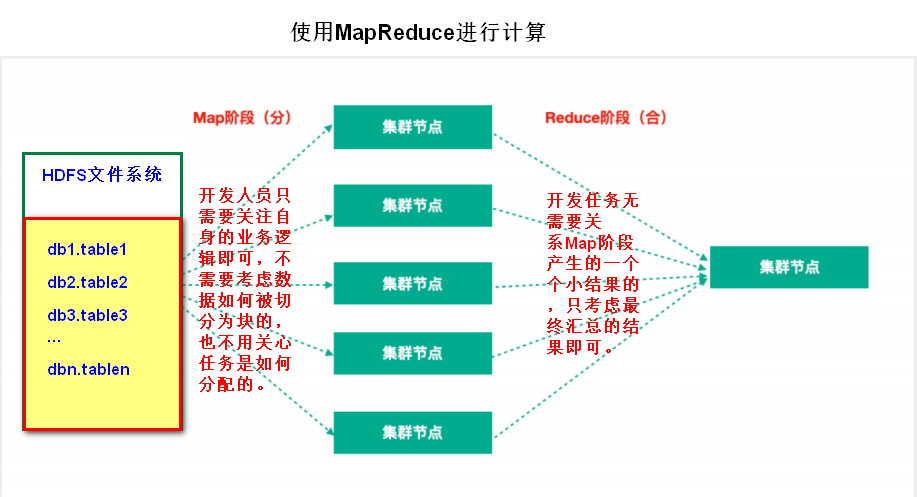
Hadoop MapReduce:一個分散式的離線平行計算框架,它是Hadoop全家桶的一部分,它的思想是分而治之,也就是說將一個大的複雜的問題切割成一個個小的問題加以解決,最後再彙總,這從MapReduce的字面就可以看出來。MapReduce處理任務過程是分為兩個階段的:
- Map階段:Map階段的主要作用是「分」,即把複雜的任務分解為若干個「簡單的任務」來並行處理。Map階段的這些任務可以平行計算,彼此間沒有依賴關係。
- Reduce階段:Reduce階段的主要作用是「合」,即對map階段的結果進行全域性彙總。
下面從一張圖例來看下MapReduce計算的處理過程:
3.由資料同步想到的
所謂巨量資料,必然和形形色色的資料表打交道,但是要清楚一點,對於一個規模還算可以的企業來講,那下面的專案組肯定是一片一片的,他們之間的資料沒有辦法做到百分之百的共用,有時你想要的去做一些資料的分析,可能就需要其他專案組甚至第三方企業的支援,從別的渠道去拿到資料進行使用,因此,資料同步接入變成了巨量資料開發中必不可少的工作。
其實資料同步接入的方式有很多,如果有資料庫的許可權,可以直接使用巨量資料平臺自帶的同步元件,編寫一定的規則,設定好接入的頻率,將資料接入過來;如果是第三方外部企業的資料,為了安全起見,我們通常也會選擇介面的方式進行資料的接入,再同步至巨量資料平臺;當然,使用訊息中介軟體也是很不錯的方式,比如Kafka,但是這東西總歸有些嚴格意義上的限制,很多企業為了安全是不會對外暴露自身的Kafka服務地址的;還有一些資料量過大的情況,可以考慮sftp伺服器的方式,直接將資料上傳到指定的伺服器的資料夾裡,不過這個總歸有些依賴於手工支援的弊端在裡面,不過據說好像也可以編寫指令碼完成自動化的上傳和拉取,對於我這個搞Java的來講,這方面的解決策略還是不太懂的;其他方法也可以使用DolphinScheduler(DS)裡面的一些小元件,去執行一些指令碼來完成同步,當然指令碼的編寫就類似於hadoop distcp -update hdfs://主機名/源資料路徑 hdfs://主機名/目標資料路徑,這是將資料表從hdfs的一個檔案目錄下複製到指定位置,同樣,flinkX也支援類似的功能。
總之,方案不少,具體場景具體分析,資料同步的問題也有很多,比如上游資料來源斷了,導致目標日期的資料沒有過來;使用的同步的伺服器宕機了,那時候就需要詳細的排查了,儘快將資料同步修復。
4.任重道遠,仍需砥礪前行
我清楚,要是徹頭徹尾的搞明白巨量資料,除了會寫寫複雜SQL是遠遠不夠的,我記著有些歸類中將ES和Kafka也作為巨量資料開發的範疇,當然,這兩塊的知識點我也是有所涉獵的,只不過是Java後端程式碼中使用的,也許這兩塊還有其他用法可以用於巨量資料,比如結合著Scala語言使用。Scala語言是函數語言程式設計,因為在Java方向已經沉浸多年,所以看了幾天scala語言的語法也沒有那麼抗拒,都大致瞭解了下,但是瞭解語法和實際使用這門語言進行工作上的開發又是另外一回事,由於各種原因沒有深入的去研究下去略表遺憾。 總的來講,目前我還是比較喜歡java的,但是因為最近這一年裡也做了不少巨量資料相關工作,所以總覺得不為它寫一篇部落格總歸對不起這一年的收穫,所以還是找個地方記錄下來吧,將來有一天如果我在java方向鑽研透了,想再探索巨量資料的廣袤無垠時,我想,我會認認真真繫系統統的去學一遍,像scala,spark,flink,hadoop他們深層次技術,我一定要每一個都好好品嚐下。