圖資料探勘:冪律分佈和無標度網路
1 冪律分佈和指數分佈
我們在部落格中《圖資料探勘(二):網路的常見度量屬性 》提到,節點度分佈\(p(k)\)為關於\(k\)的函數,表示網路中度為\(k\)的節點佔多大比例。我們發現,現實世界許多網路的節點度分佈與冪函數乘正比:
比如下圖就是對Flick社群網路中\(p(k)\)的概率分佈影象的視覺化:
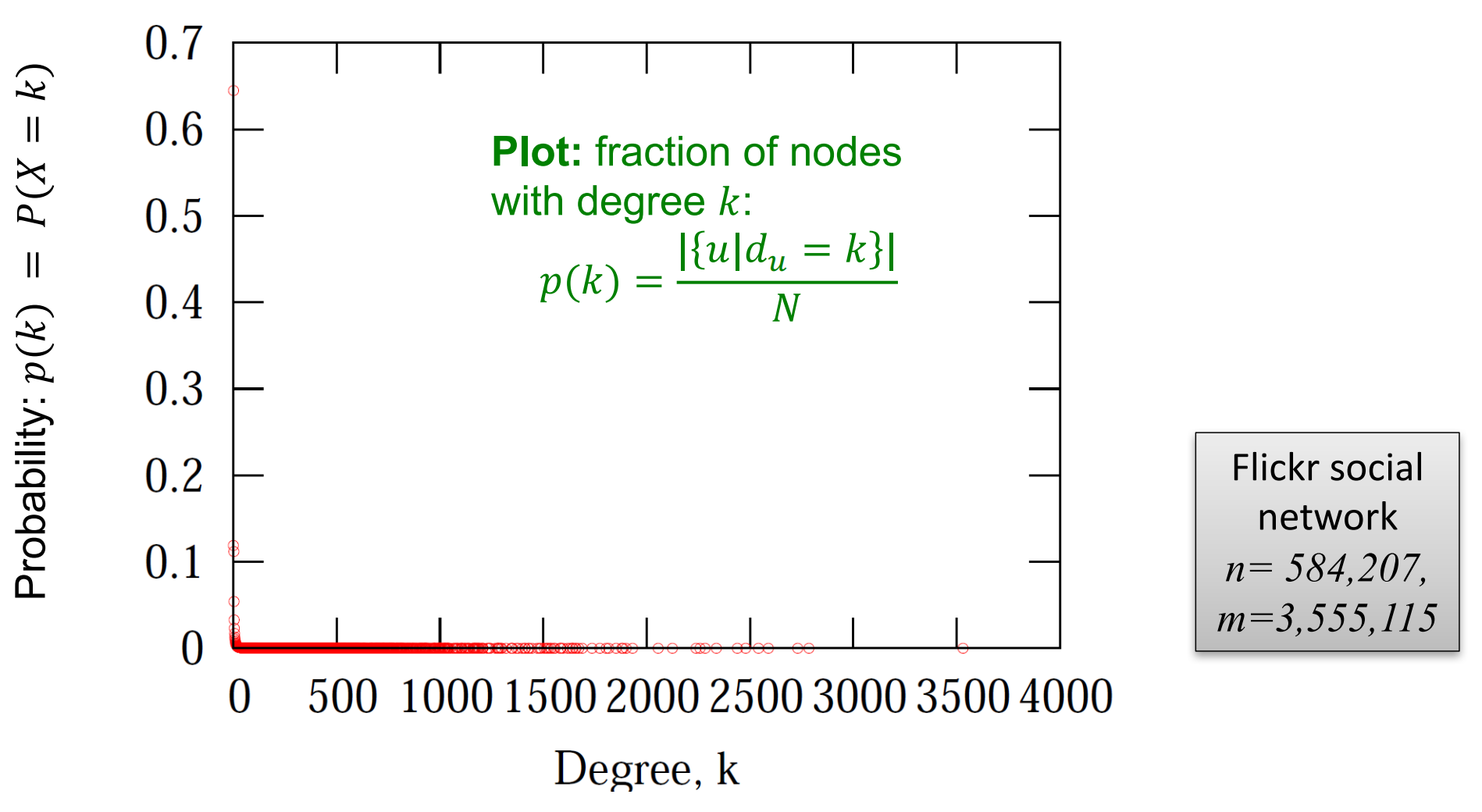
由於對\(y=x^{-\alpha}\)兩邊取對數可以得到\(\log(y)=-\alpha \log(x)\),因此我們使用原資料在log-log尺度上繪製影象得到:

可以看到此時冪律分佈像一條斜率為\(-\alpha\)的直線。事實上,我們可以用該方法快速檢測一個資料集是否服從冪律分佈。像與冪律分佈\(p(k) \propto \exp (-k)\)和指數分佈\(p(k) \propto k^{-\alpha}\)就可以使用取對數的方法進行區分,因為對\(y=f(x)=e^{-x}\)兩邊取對數我們得到的是\(\log(y)=-x\)。
我們繼續看在原始座標軸下,冪律分佈和指數分佈的對比圖:

可以看到,當\(x\)值高於某個特定的值後,冪律分佈影象會高於指數分佈。如果我們在log-log或者半log(log-lin)尺度上繪製影象則可以看到

我們再來看一下現實生活中的冪律分佈和其它分佈的對比。事實上,航空網路的度分佈常常滿足冪律分佈;而高速公路網路的度分佈則常常滿足泊松分佈(指數族分佈的一種),其均值為平均度\(\bar{k}\)。它們的對比如下圖所示:

2 冪律分佈的數學性質
2.1 重尾分佈
如果分佈\(p(x)\)對應的互補累計分佈函數(complementary cumulative distribution function,CCDF)\(P(X>x)\)滿足:
則我們稱分佈\(p(x)\)是重尾分佈(heavy tailed distribution)。

冪律分佈就是一種典型的重尾分佈(就像我們前面所展示的節點度高度傾斜)。但需要注意的事,以下分佈不是重尾分佈:
- 正態分佈:\(p(x)=\frac{1}{\sqrt{2 \pi \sigma}} e^{-\frac{(x-\mu)^2}{2 \sigma^2}}\)
- 指數分佈:\(p(x)=\lambda e^{-\lambda x}\)(\(P(X>x)=1-P(X \leq x)=e^{-\lambda x}\))。
事實上,重尾分佈有著不同的變種和形式,包括:長尾分佈(long tailed distribution),齊夫定律(Zipf's law),帕累託定律(Pareto law,也就是所謂的「二八法則」)等。
對於重尾分佈而言,其概率密度函數\(p(x)\)正比於:
- 冪律分佈: \(p(x) \propto x^{-\alpha}\)
- 具有指數截止的冪律分佈(power law with exponential cutoff):\(x^{-\alpha} e^{-\lambda x}\)
- 擴充套件指數分佈(stretched exponential):\(x^{\beta-1} e^{-\lambda x^\beta}\)
- 對數正態分佈(log-normal):\(\frac{1}{x} \exp \left[-\frac{(\ln x-\mu)^2}{2 \sigma^2}\right]\)
2.2 歸一化常數
接下來我們考慮冪律分佈
的歸一化常數\(Z\)應該怎麼取。由於要讓\(p(x)\)是一個概率分佈的話則需要滿足:\(\int p(x) d x=1\)。由於\(p(x)\)在\(x \rightarrow 0\)的時候是發散的,我們取一個最小值\(x_m\),接著我們有:
當\(\alpha>1\)時,我們有\(Z=(\alpha-1) x_m^{\alpha-1}\)。於是,可以得到歸一化後的冪律分佈形式:
2.3 數學期望
冪律分佈隨機變數\(X\)的期望值
當\(\alpha>2\)時,我們有
若\(\alpha \leq 2\),則\(E[X]=\infty\),若\(\alpha\leq3\),則\(Var[X]=\infty\)。事實上當方差太大時均值就沒有意義了。
在真實的網路中\(2<\alpha<3\),所以\(E[X]=\text{const}\),\(Var[X]=\infty\)。
為了印證我們上面的理論,我們通過實驗模擬當冪律分佈的指數\(\alpha\)的取不同值時,從分佈中所採的\(n\)個樣本的均值和方差隨著\(n\rightarrow \infty\)的變化情況:

可以看到,和我們上面的理論符合。
3 無標度網路
3.1 隨機和無標度網路的對比
網路度分佈遵循冪律分佈的網路我們稱為無標度(scale-free)網路(也稱無尺度網路)。所謂無標度(Scale-Free),其實來源於統計物理學裡的相轉移理。網路一階矩是平均度,二階矩是度的方差。我們在部落格《圖資料探勘:Erdos-Renyi隨機圖的生成方式及其特性》中說過,ER隨機網路的平均度\(\bar{k}\)與度方差\(\sigma^2\)都是可以估計的,這就是所謂「有尺度」。但正如我們前面所分析的,在冪律分佈網路中,方差和期望都可能不存在,這也是Barabási等人將其稱為「無尺度」的原因[2][3]。
我們下面展示了隨機網路(Erdos-Eenyi隨機圖)和無標度網路的對比:

3.2 網路的彈性
網路的彈性(resilience)意為網路對攻擊的抵抗能力,而這可以通過網路的一些度量屬性隨攻擊的變化來體現。
節點的移除方式包括兩種:
- 隨機事故(random failure): 均勻隨機地移除節點
- 針對性攻擊(targeted attack): 按照度的降序來移除節點。

網路的彈性分析對網際網路的魯棒性和流行病學都非常重要。接下來我們就來看幾種經典網路型別的彈性分析實驗。我們採取的度量屬性包括:
- 在巨大連通分量(gaint connected component)中的節點所佔的比例
- 最大連通分量中的節點之間的平均路徑長度。
可以看到,無標度網路對隨機攻擊具有彈性,但是對針對性攻擊敏感:

接下來的實驗展示了對於無標度網路而言,如需讓巨連通分量\(S\)消失,有多大比例的隨機節點必須要被移除。

\(\gamma<3\)的無限大的無標度網路在隨機攻擊下永遠不會被解體。
下面是無標度網路和隨機網路的平均路徑長度在針對性攻擊和隨機攻擊下的變化圖:

可見無標度網路對於隨機事故是有彈性的,而\(G_{np}\)對於針對性攻擊有著更好的彈性。
在現實網路中的彈性試驗情況如下圖所示(來源於[5]):

對上述影象進行放大的結果如下圖所示,圖中E是指\(G_{np}\)而SF是指scale-free,橫座標表示百分之多少的節點被移除。這裡我們可以看到針對性攻擊是怎樣快速地讓網路變得不連通的。

3.3 優先連線模型和富者更富現象
最後,我們來看冪律分佈形成的原因。而這需要從整個網路的形成過程來思考。

我們設節點以順序\(1,2,\cdots, n\)到達。在第\(j\)步,一個新的節點\(j\)到達了並建立了\(m\)個出連結(out-links),則節點\(j\)連結到之前的節點\(i\)(\(i<j\))的概率正比於\(i\)的度\(d_i\):
這被稱之為擇優連結模型(Preferential attachment)[3],或富者更富現象,就是指新來的節點更傾向於去連結度已經很高的節點。而冪律就是從「富者更富」(累計優勢)中產生。現實中中常見的例子就是在論文參照中,論文新增的參照量和它已經有的參照量成正比(部落格文章的點贊也是這個道理,所以如果你看到我這篇文章贊同量很少,不要猶豫幫我點個贊啦o(╥﹏╥)o)。
為了推導冪律分佈的形式,我們分析下列模型:節點以順序\(1,2,3\cdots,n\)到達。當節點\(j\)被建立時它用一個連結指向一個更早的節點\(i\),節點\(i\)是按以下規則選擇的:
- \(j\)以概率\(p\)從更早的節點中均勻隨機選擇\(i\)。
- \(j\)以概率\(1-p\)連結到節點\(l\),其中\(l\)被選擇的概率正比於\(d_l\)(\(l\)的入度)。

注意,因為我們的圖是有向圖,每個節點的出度都為\(1\)。
則在我們上述模型產生的網路中,入度為\(k\)的節點所佔的比例滿足:
這裡\(q=1-p\)。這樣,我們就得到了指數\(\alpha=1+\frac{1}{1-p}\)的冪律度分佈。
參考
- [1] Broder A, Kumar R, Maghoul F, et al. Graph structure in the web[J]. Computer networks, 2000, 33(1-6): 309-320.
- [2] wiki:無標度網路
- [3] Barabási A L, Albert R. Emergence of scaling in random networks[J]. science, 1999, 286(5439): 509-512.
- [4] Albert R, Jeong H, Barabási A L. Error and attack tolerance of complex networks[J]. nature, 2000, 406(6794): 378-382.
- [5] http://web.stanford.edu/class/cs224w/
- [6] Easley D, Kleinberg J. Networks, crowds, and markets: Reasoning about a highly connected world[M]. Cambridge university press, 2010.
- [7] Barabási A L. Network science[J]. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2013, 371(1987): 20120375.