簡單聊聊MySQL中join查詢

程式設計師必備介面測試偵錯工具:
推薦學習:
索引對 join 查詢的影響
資料準備
假設有兩張表 t1、t2,兩張表都存在有主鍵索引 id 和索引欄位 a,b 欄位無索引,然後在 t1 表中插入 100 行資料,t2 表中插入 1000 行資料進行實驗
CREATE TABLE `t2` (
`id` int NOT NULL,
`a` int DEFAULT NULL,
`b` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `t2_a_index` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
CREATE PROCEDURE **idata**()
BEGIN
DECLARE i INT;
SET i = 1;
WHILE (i <= 1000)do
INSERT INTO t2 VALUES (i,i,i);
SET i = i +1;
END WHILE;
END;
CALL **idata**();
CREATE TABLE t1 LIKE t2;
INSERT INTO t1 (SELECT * FROM t2 WHERE id <= 100);登入後複製有索引查詢過程
我們使用查詢 SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);因為 join 查詢 MYSQL 優化器不一定能按照我們的意願去執行,所以為了分析我們選擇用 STRAIGHT_JOIN 來代替,從而更直觀的進行觀察
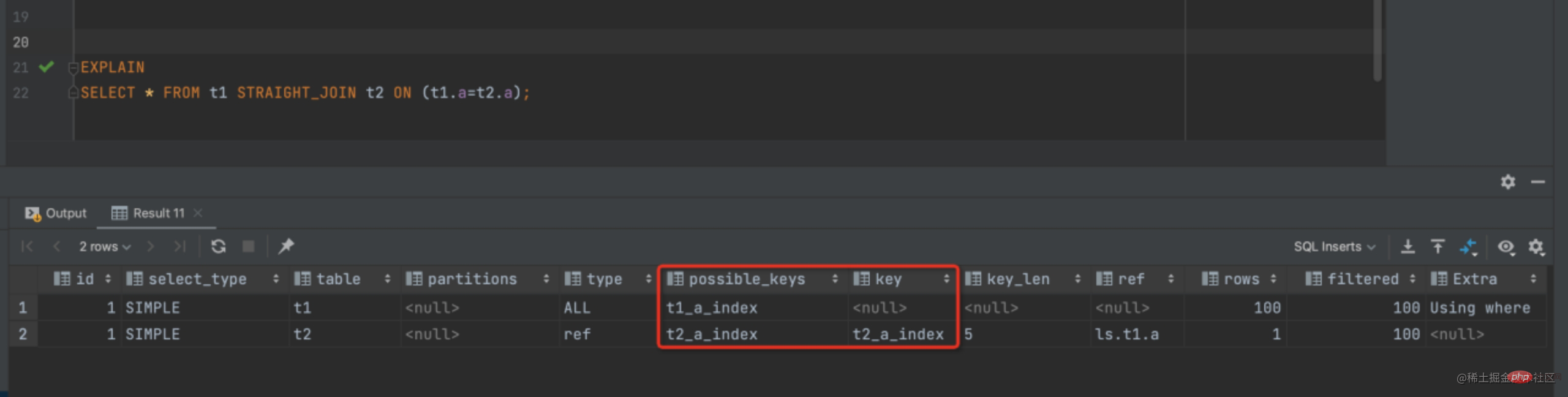 圖 1
圖 1
可以看出我們使用了 t1 作為驅動表,t2 作為被驅動表,上圖的 explain 中顯示本次查詢用上了 t2 表的欄位 a索引,所以這個語句的執行過程應該是下面這樣的:
從 t1 表中讀取一行資料 r
從資料 r中取出欄位 a到表 t2 中進行匹配
取出 t2 表中符合條件的行,和 r組成一行作為結果集的一部分
重複執行步驟 1-3,直到表 t1 迴圈資料
該過程稱之為 Index Nested-Loop Join,在這個流程裡,驅動表 t1 進行了全表掃描,因為我們給 t1 表插入了 100 行資料,所以本次的掃描行數是 100,而進行 join 查詢時,對於 t1 表的每一行都需去 t2 表中進行查詢,走的是索引樹搜尋,因為我們構造的資料都是一一對應的,所以每次搜尋只掃描一行,也就是 t2 表也是總共掃描 100 行,整個查詢過程掃描的總行數是 100+100=200 行。
無索引查詢過程
SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a = t2.b);
登入後複製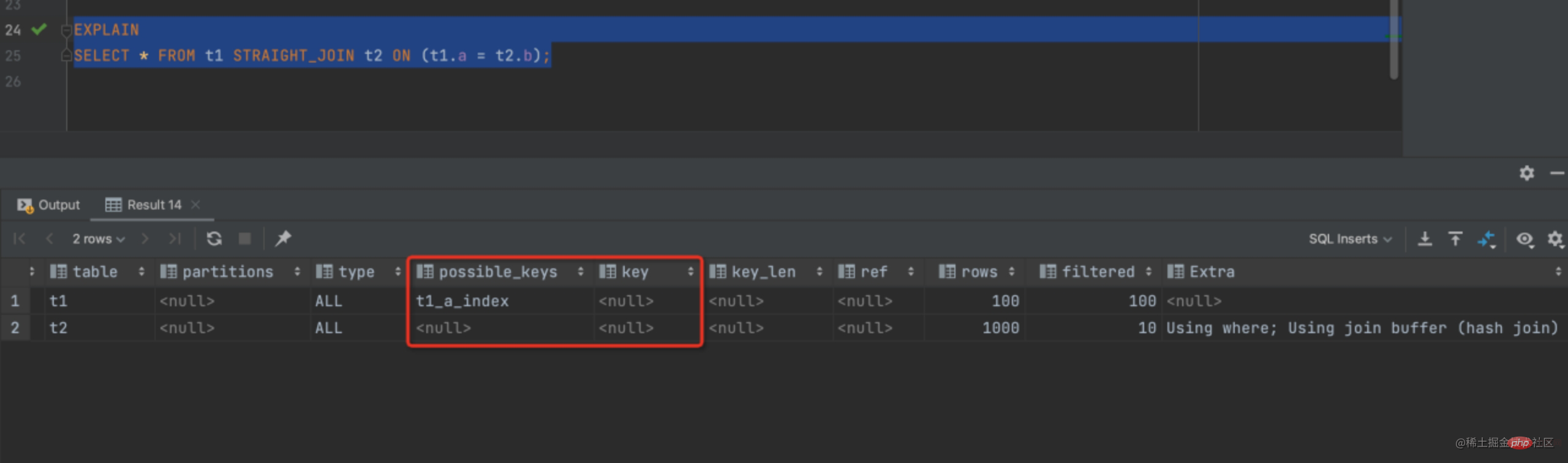 圖 2
圖 2
可以看出由於 t2 表欄位 B上沒有索引,所以按照上述 SQL 執行時每次從 t1 去匹配 t2 的時候都要做一次全表掃描,這樣算下來掃描 t2 多大 100 次,總掃描次數就是 100*1000 = 10 萬行。
當然了這個查詢結果還是在我們建的這兩個都是小表的情況下,如果是數量級 10 萬行的表,就需要掃描 100 億行,這就太恐怖了!
2. 瞭解 Block Nested-Loop Join
Block Nested-Loop Join查詢過程
那麼被驅動表上沒有存在索引,這一切都是怎麼發生的呢?
實際上當被驅動表上沒有可用的索引,演演算法流程是這樣的:
把 t1 的資料讀取執行緒記憶體 join_buffer 中,因為上述我們寫的是 select * from,所以相當於是把整個 t1 表放入了記憶體;
掃描 t2 的過程,實際上是把 t2 的每一行取出來,跟 join_buffer 中的資料去做對比,滿足 join 條件的,作為結果集的一部分進行返回。
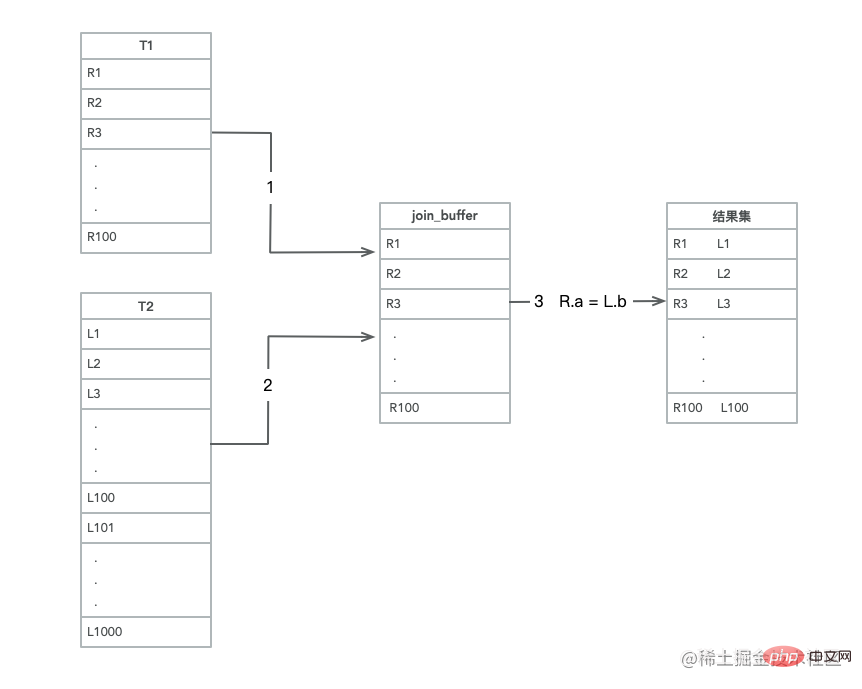
所以結合圖 2中 Extra 部分說明 Using join buffer 可以發現這一絲端倪,整個過程中,對錶 t1 和t2 都做了一次全表掃描,因此掃描的行數是 100+1000=1100 行,因為 join_buffer 是以無序陣列的方式組織的,因此對於表 t2 中每一行,都要做 100 次判斷,總共需要在記憶體中進行的判斷次數是 100*1000=10 萬次,但是因為這 10 萬次是發生在記憶體中的所以速度上要快很多,效能也更好。
Join_buffer
根據上述已經知道了,沒有索引的情況下 MySQL 是將資料讀取記憶體進行迴圈判斷的,那麼這個記憶體肯定不是無限制讓你使用的,這時我們就需要用到一個引數 join_buffer_size,該值預設大小 256k,如下圖:
SHOW VARIABLES LIKE '%join_buffer_size%';
登入後複製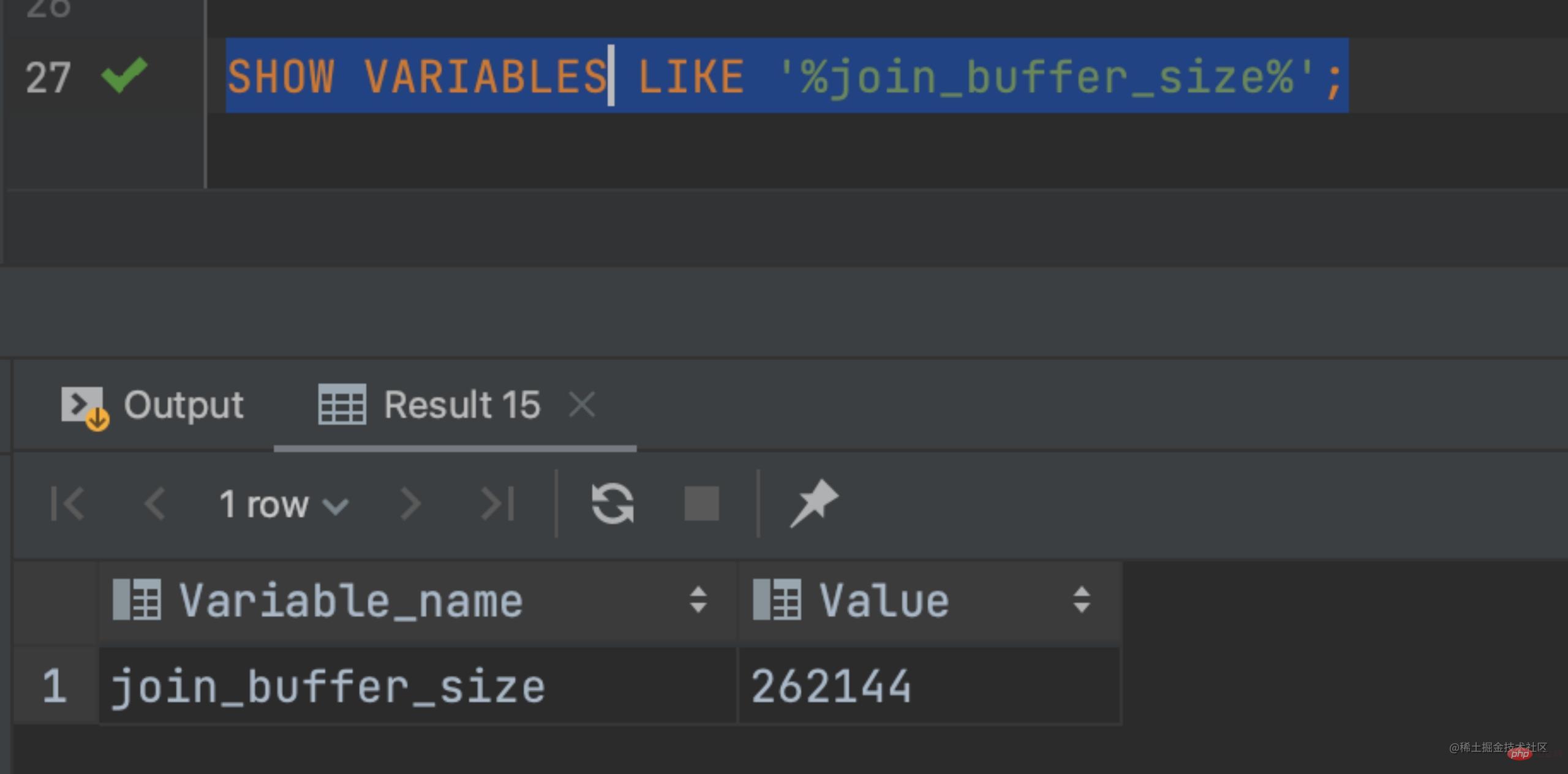
圖 4
假如查詢的資料過大一次載入不完,只能夠載入部分資料(80 條),那麼查詢的過程就變成了下面這樣
掃描表 t1,順序讀取資料行放入 join_buffer 中,直至載入完第 80 行滿了
掃描表 t2,把 t2 表中的每一行取出來跟 join_buffer 中的資料做對比,將滿足條件的資料作為結果集的一部分返回
清空 join_buffer
繼續掃描表 t1,順序讀取剩餘的資料行放入 join_buffer 中,執行步驟 2
這個流程體現了演演算法名稱中 Block 的由來,分塊 join,可以看出雖然查詢過程中 t1 被分成了兩次放入 join_buffer 中,導致 t2 表被掃描了 2次,但是判斷等值條件的次數還是不變的,依然是(80+20)*1000=10 萬次。
所以這就是有時候 join 查詢很慢,有些大佬會讓你把 join_buffer_size 調大的原因。
如何正確的寫出 join 查詢
驅動表的選擇
有索引的情況下
在這個 join 語句執行過程中,驅動表是走全表掃描,而被驅動表是走樹搜尋。
假設被驅動表的行數是 M,每次在被驅動表查詢一行資料,先要走索引 a,再搜尋主鍵索引。每次搜尋一棵樹近似複雜度是以 2為底的 M的對數,記為 log2M,所以在被驅動表上查詢一行資料的時間複雜度是 2*log2M。
假設驅動表的行數是 N,執行過程就要掃描驅動表 N 行,然後對於每一行,到被驅動表上 匹配一次。因此整個執行過程,近似複雜度是 N + N2log2M。顯然,N 對掃描行數的影響更大,因此應該讓小表來做驅動表。
那沒有索引的情況
上述我知道了,因為 join_buffer 因為存在限制,所以查詢的過程可能存在多次載入 join_buffer,但是判斷的次數都是 10 萬次,這種情況下應該怎麼選擇?
假設,驅動表的資料行數是 N,需要分 K 段才能完成演演算法流程,被驅動表的資料行數是 M。這裡的 K不是常數,N 越大 K就越大,因此把 K 表示為λ*N,顯然λ的取值範圍 是 (0,1)。
掃描的行數就變成了 N+λNM,顯然記憶體的判斷次數是不受哪個表作為驅動表而影響的,而考慮到掃描行數,在 M和 N大小確定的情況下,N 小一些,整個算是的結果會更小,所以應該讓小表作為驅動表
總結:真相大白了,不管是有索引還是無索引參與 join 查詢的情況下都應該是使用小表作為驅動表。
什麼是小表
還是以上面表 t1 和表 t2 為例子:
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.b = t2.b WHERE t2.id <= 50;
SELECT * FROM t2 STRAIGHT_JOIN t1 ON t1.b = t2.b WHERE t2.id <= 50;
登入後複製上面這兩條 SQL 我們加上了條件 t2.id <= 50,我們使用了欄位 b,所以兩條 SQL 都沒有用上索引,但是第二條 SQL 可以看出 join_buffer 只需要放入前 50 行,顯然查詢更快,所以 t2 的前 50 行就是那個相對較小的表,也就是我們上面說所說的‘小表’。
再看另一組:
SELECT t1.b,t2.* FROM t1 STRAIGHT_JOIN t2 ON t1.b = t2.b WHERE t2.id <= 100;
SELECT t1.b,t2.* FROM t2 STRAIGHT_JOIN t1 ON t1.b = t2.b WHERE t2.id <= 100;
登入後複製這個例子裡,表 t1 和 t2 都是隻有 100 行參加 join。 但是,這兩條語句每次查詢放入 join_buffer 中的資料是不一樣的: 表 t1 只查欄位 b,因此如果把 t1 放到 join_buffer 中,只需要放入欄位 b 的值; 表 t2 需要查所有的欄位,因此如果把表 t2 放到 join_buffer 中的話,就需要放入三個字 段 id、a 和 b。
這裡,我們應該選擇表 t1 作為驅動表。也就是說在這個例子裡,」只需要一列參與 join 的 表 t1「是那個相對小的表。
結論:
在決定哪個表做驅動表的時候,應該是兩個表按照各自的條件過濾,過 濾完成之後,計算參與 join 的各個欄位的總資料量,資料量小的那個表,就是「小表」, 應該作為驅動表。
推薦學習:
以上就是簡單聊聊MySQL中join查詢的詳細內容,更多請關注TW511.COM其它相關文章!
