pytorch模型儲存與載入中的一些問題實戰記錄
2022-11-03 18:00:34

程式設計師必備介面測試偵錯工具:
【相關推薦:Python3視訊教學 】
一、torch中模型儲存和載入的方式
1、模型引數和模型結構儲存和載入
torch.save(model,path)
torch.load(path)
登入後複製2、只儲存模型的引數和載入——這種方式比較安全,但是比較稍微麻煩一點點
torch.save(model.state_dict(),path)
model_state_dic = torch.load(path)
model.load_state_dic(model_state_dic)
登入後複製二、torch中模型儲存和載入出現的問題
1、單卡模型下儲存模型結構和引數後載入出現的問題
模型儲存的時候會把模型結構定義檔案路徑記錄下來,載入的時候就會根據路徑解析它然後裝載引數;當把模型定義檔案路徑修改以後,使用torch.load(path)就會報錯。
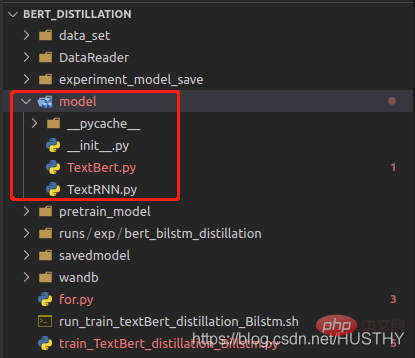
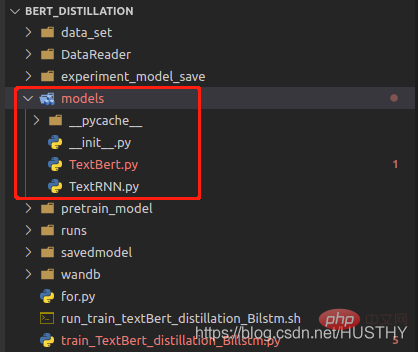

把model資料夾修改為models後,再載入就會報錯。
import torch
from model.TextRNN import TextRNN
load_model = torch.load('experiment_model_save/textRNN.bin')
print('load_model',load_model)登入後複製這種儲存完整模型結構和引數的方式,一定不要改動模型定義檔案路徑。
2、多卡機器單卡訓練模型儲存後在單卡機器上載入會報錯
在多卡機器上有多張顯示卡0號開始,現在模型在n>=1上的顯示卡訓練儲存後,拷貝在單卡機器上載入
import torch
from model.TextRNN import TextRNN
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin')
print('load_model',load_model)登入後複製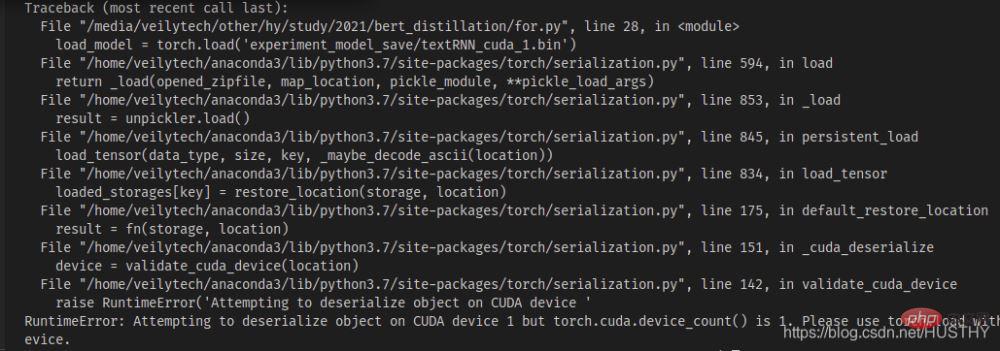
會出現cuda device不匹配的問題——你儲存的模程式碼段 小部件型是使用的cuda1,那麼採用torch.load()開啟的時候,會預設的去尋找cuda1,然後把模型載入到該裝置上。這個時候可以直接使用map_location來解決,把模型載入到CPU上即可。
load_model = torch.load('experiment_model_save/textRNN_cuda_1.bin',map_location=torch.device('cpu'))登入後複製3、多卡訓練模型儲存模型結構和引數後載入出現的問題
當用多GPU同時訓練模型之後,不管是採用模型結構和引數一起儲存還是單獨儲存模型引數,然後在單卡下載入都會出現問題
a、模型結構和引數一起保然後在載入

torch.distributed.init_process_group(backend='nccl')
登入後複製模型訓練的時候採用上述多程序的方式,所以你在載入的時候也要宣告,不然就會報錯。
b、單獨儲存模型引數
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load('train_model/clip/experiment.pt')
model.load_state_dict(state_dict)登入後複製同樣會出現問題,不過這裡出現的問題是引數字典的key和模型定義的key不一樣

原因是多GPU訓練下,使用分散式訓練的時候會給模型進行一個包裝,程式碼如下:
model = torch.load('train_model/clip/Vtransformers_bert_6_layers_encoder_clip.bin')
print(model)
model.cuda(args.local_rank)
。。。。。。
model = nn.parallel.DistributedDataParallel(model,device_ids=[args.local_rank],find_unused_parameters=True)
print('model',model)登入後複製包裝前的模型結構:
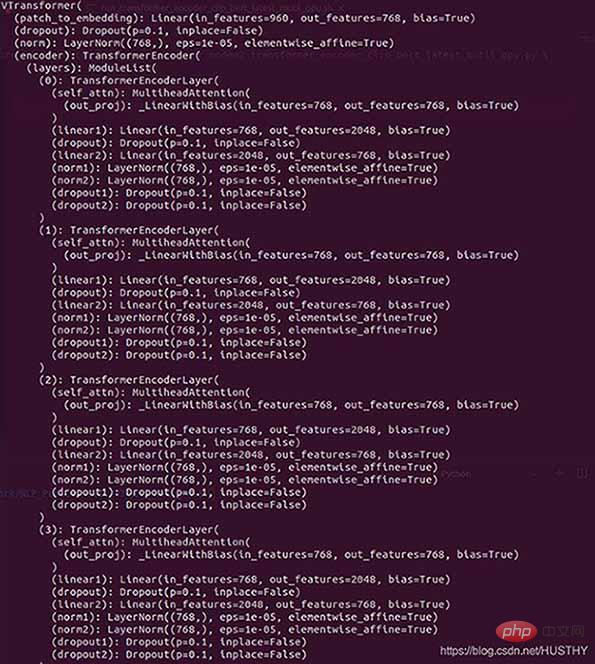
包裝後的模型
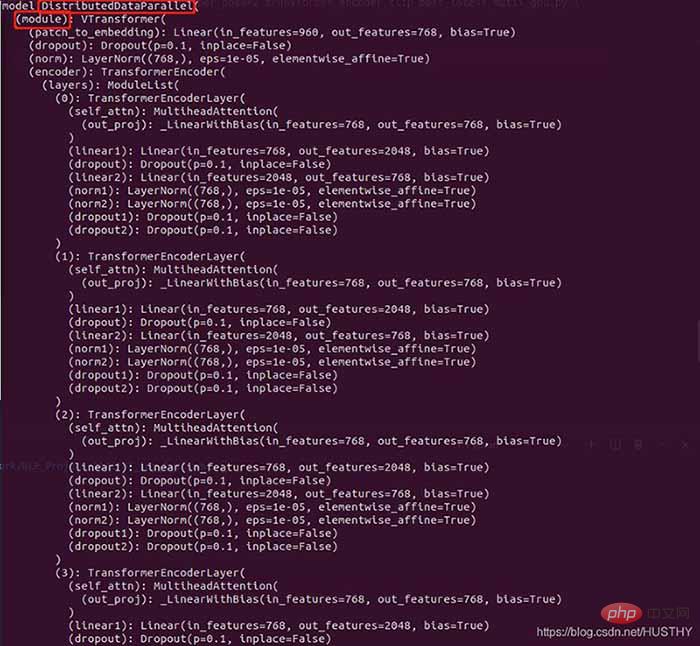
在外層多了DistributedDataParallel以及module,所以才會導致在單卡環境下載入模型權重的時候出現權重的keys不一致。
三、正確的儲存模型和載入的方法
if gpu_count > 1:
torch.save(model.module.state_dict(),save_path)
else:
torch.save(model.state_dict(),save_path)
model = Transformer(num_encoder_layers=6,num_decoder_layers=6)
state_dict = torch.load(save_path)
model.load_state_dict(state_dict)登入後複製這樣就是比較好的正規化,載入不會出錯。
【相關推薦:Python3視訊教學 】
以上就是pytorch模型儲存與載入中的一些問題實戰記錄的詳細內容,更多請關注TW511.COM其它相關文章!
