C# Interlocked 類
【前言】
在日常開發工作中,我們經常要對變數進行操作,例如對一個int變數遞增++。在單執行緒環境下是沒有問題的,但是如果一個變數被多個執行緒操作,那就有可能出現結果和預期不一致的問題。
例如:
static void Main(string[] args)
{
var j = 0;
for (int i = 0; i < 100; i++)
{
j++;
}
Console.WriteLine(j);
//100
}
在單執行緒情況下執行,結果一定為100,那麼在多執行緒情況下呢?
static void Main(string[] args)
{
var j = 0;
var t1 = Task.Run(() =>
{
for (int i = 0; i < 50000; i++)
{
j++;
}
});
var t2 = Task.Run(() =>
{
for (int i = 0; i < 50000; i++)
{
j++;
}
});
Task.WaitAll(t1, t2);
Console.WriteLine(j);
//82869 這個結果是隨機的,和每個執行緒執行情況有關
}
我們可以看到,多執行緒情況下並不能保證執行正確,我們也將這種情況稱為 「非執行緒安全」
這種情況下我們可以通過加鎖來達到執行緒安全的目的
static void Main(string[] args)
{
var locker = new object();
var j = 0;
var t1 = Task.Run(() =>
{
for (int i = 0; i < 50000; i++)
{
lock (locker)
{
j++;
}
}
});
var t2 = Task.Run(() =>
{
for (int i = 0; i < 50000; i++)
{
lock (locker)
{
j++;
}
}
});
Task.WaitAll(t1, t2);
Console.WriteLine(j);
//100000 這裡是一定的
}
加鎖的確能解決上述問題,那麼有沒有一種更加輕量級,更加簡潔的寫法呢?
那麼,今天我們就來認識一下 Interlocked 類
【Interlocked 類下的方法】
Increment(ref int location)
Increment 方法可以輕鬆實現執行緒安全的變數自增
/// <summary>
/// thread safe increament
/// </summary>
public static void Increament()
{
var j = 0;
Task.WaitAll(
Enumerable.Range(0, 50)
.Select(t =>
Task.Run(() =>
{
for (int i = 0; i < 2000; i++)
{
Interlocked.Increment(ref j);
}
}
))
.ToArray()
);
Console.WriteLine($"multi thread increament result={j}");
//result=100000
}
看到這裡,我們一定好奇這個方法底層是怎麼實現的?
我們通過ILSpy反編譯檢視原始碼:
首先看到 Increment 方法其實是通過呼叫 Add 方法來實現自增的

再往下看,Add 方法是通過 ExchangeAdd 方法來實現原子性的自增,因為該方法返回值是增加前的原值,因此返回時增加了本次新增的,結果便是相加的結果,當然 location1 變數已經遞增成功了,這裡只是為了友好地返回增加後的結果。
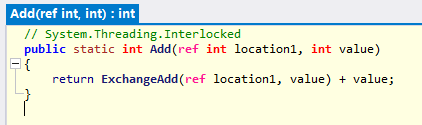
我們再往下看
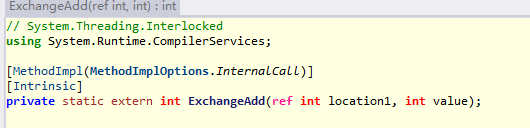
這個方法用 [MethodImpl(MethodImplOptions.InternalCall)] 修飾,表明這裡呼叫的是 CLR 內部程式碼,我們只能通過檢視原始碼來繼續學習。
我們開啟 dotnetcore 原始碼:https://github.com/dotnet/corefx
找到 Interlocked 中的 ExchangeAdd 方法
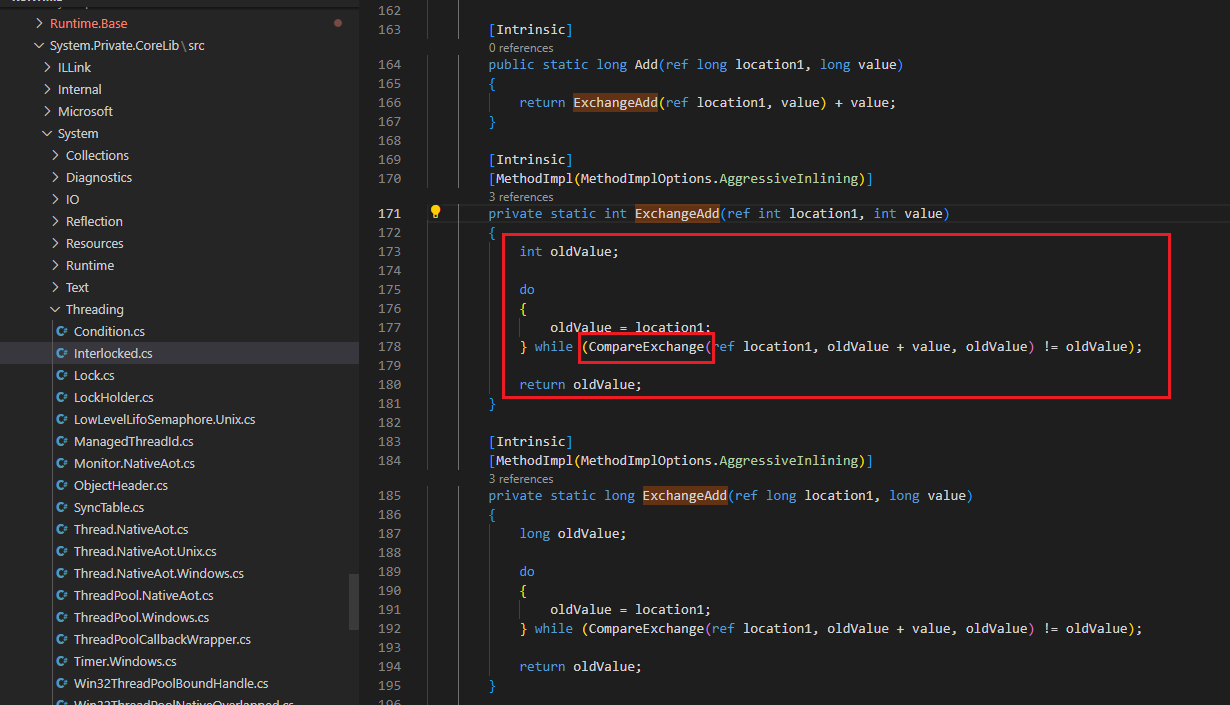
可以看到,該方法用迴圈不斷自旋賦值並檢查是否賦值成功(CompareExchange返回的是修改前的值,如果返回結果和修改前結果是一致,則說明修改成功)
我們繼續看內部實現
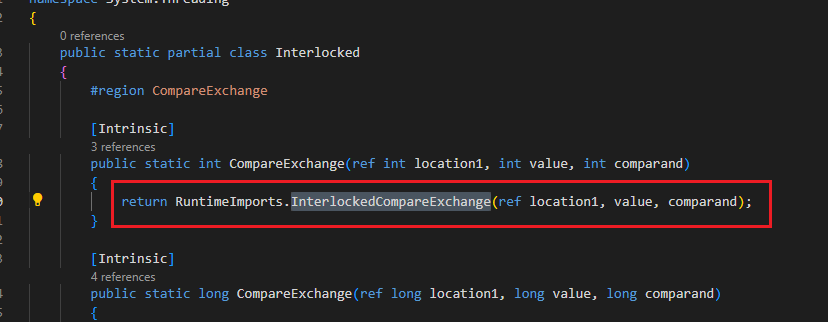

內部呼叫 InterlockedCompareExchange 函數,再往下就是直接呼叫的C++原始碼了


在這裡將變數新增 volatile 修飾符,阻止暫存器快取變數值(關於volatile不在此贅述),然後直接呼叫了C++底層內部函數 __sync_val_compare_and_swap 實現原子性的比較交換操作,這裡直接用的是 CPU 指令進行原子性操作,效能非常高。
相同機制函數
和 Increment 函數機制類似,Interlocked 類下的大部分方法都是通過 CompareExchange 底層函數來操作的,因此這裡不再贅述
- Add 新增值
- CompareExchange 比較交換
- Decrement 自減
- Exchange 交換
- And 按位元與
- Or 按位元或
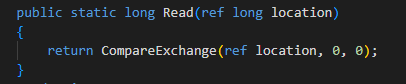
- Read 讀64位元數值
public static long Read(ref long location)
Read 這個函數著重提一下

可以看到這個函數沒有 32 位(int)型別的過載,為什麼要單獨為 64 位的 long/ulong 型別單獨提供原子性讀取操作符呢?
這是因為CPU有 32 位處理器和 64 位處理器,在 64 位處理器上,暫存器一次處理的資料寬度是 64 位,因此在 64 位處理器和 64 位元運算系統上執行的程式,可以一次性讀取 64 位數值。
但是在 32 位處理器和 32 位元運算系統情況下,long/ulong 這種數值,則要分成兩步操作來進行,分別讀取 32 位資料後,再合併在一起,那顯然就會出現多執行緒情況下的並行問題。
因此這裡提供了原子性的方法來應對這種情況。
這裡底層同樣用了 CompareExchange 操作來保證原子性,引數這裡就給了兩個0,可以相容如果原值是 0 則寫入 0 ,如果原值非 0 則不寫入,返回原值。
__sync_val_compare_and_swap 函數
在寫入新值之前, 讀出舊值, 當且僅當舊值與儲存中的當前值一致時,才把新值寫入儲存
【關於效能】
多執行緒下實現原子性操作方式有很多種,我們一定會關心在不同場景下,不同方法間的效能問題,那麼我們簡單來對比下 Interlocked 類提供的方法和 lock 關鍵字的效能對比
我們同樣用執行緒池排程50個Task(內部可能執行緒重用),分別執行 200000 次自增運算
public static void IncreamentPerformance()
{
//lock method
var locker = new object();
var stopwatch = new Stopwatch();
stopwatch.Start();
var j1 = 0;
Task.WaitAll(
Enumerable.Range(0, 50)
.Select(t =>
Task.Run(() =>
{
for (int i = 0; i < 200000; i++)
{
lock (locker)
{
j1++;
}
}
}
))
.ToArray()
);
Console.WriteLine($"Monitor lock,result={j1},elapsed={stopwatch.ElapsedMilliseconds}");
stopwatch.Restart();
//Increment method
var j2 = 0;
Task.WaitAll(
Enumerable.Range(0, 50)
.Select(t =>
Task.Run(() =>
{
for (int i = 0; i < 200000; i++)
{
Interlocked.Increment(ref j2);
}
}
))
.ToArray()
);
stopwatch.Stop();
Console.WriteLine($"Interlocked.Increment,result={j2},elapsed={stopwatch.ElapsedMilliseconds}");
}
運算結果

可以看到,採用 Interlocked 類中的自增函數,效能比 lock 方式要好一些
雖然這裡看起來效能要好,但是不同的業務場景要針對性思考,採用恰當的編碼方式,不要一味追求效能
我們簡單分析下造成執行時間差異的原因
我們都知道,使用lock(底層是Monitor類),在上述程式碼中會阻塞執行緒執行,保證同一時刻只能有一個執行緒執行 j1++ 操作,因此能保證操作的原子性,那麼在多核CPU下,也只能有一個CPU核心在執行這段邏輯,其他核心都會等待或執行其他事件,執行緒阻塞後,並不會一直在這裡傻等,而是由作業系統排程執行其他任務。由此帶來的代價可能是頻繁的執行緒上下文切換,並且CPU使用率不會太高,我們可以用分析工具來印證下。
Visual Studio 自帶的分析工具,檢視執行緒使用率
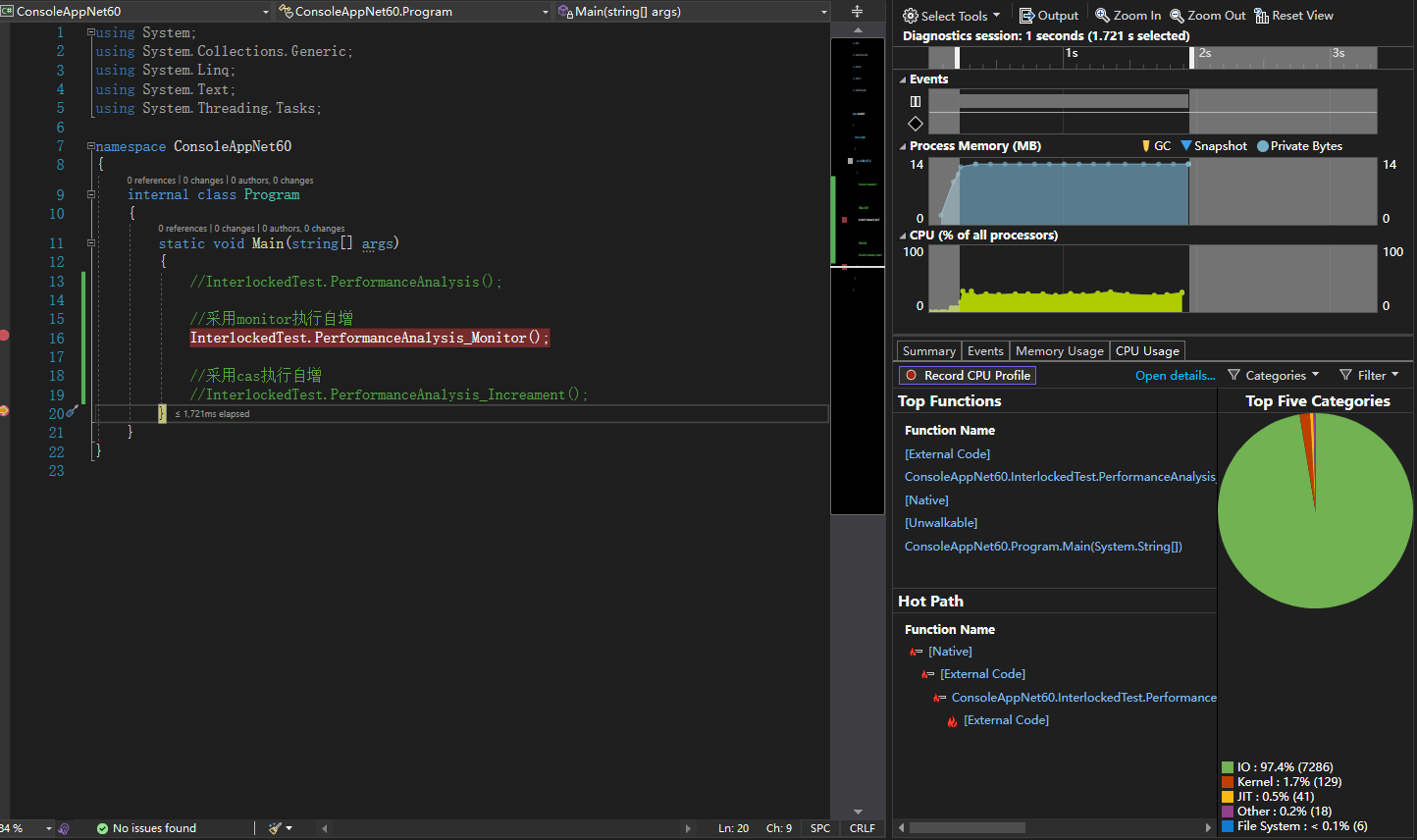
使用 Process Explorer 工具檢視程式碼執行過程中上下文切換數
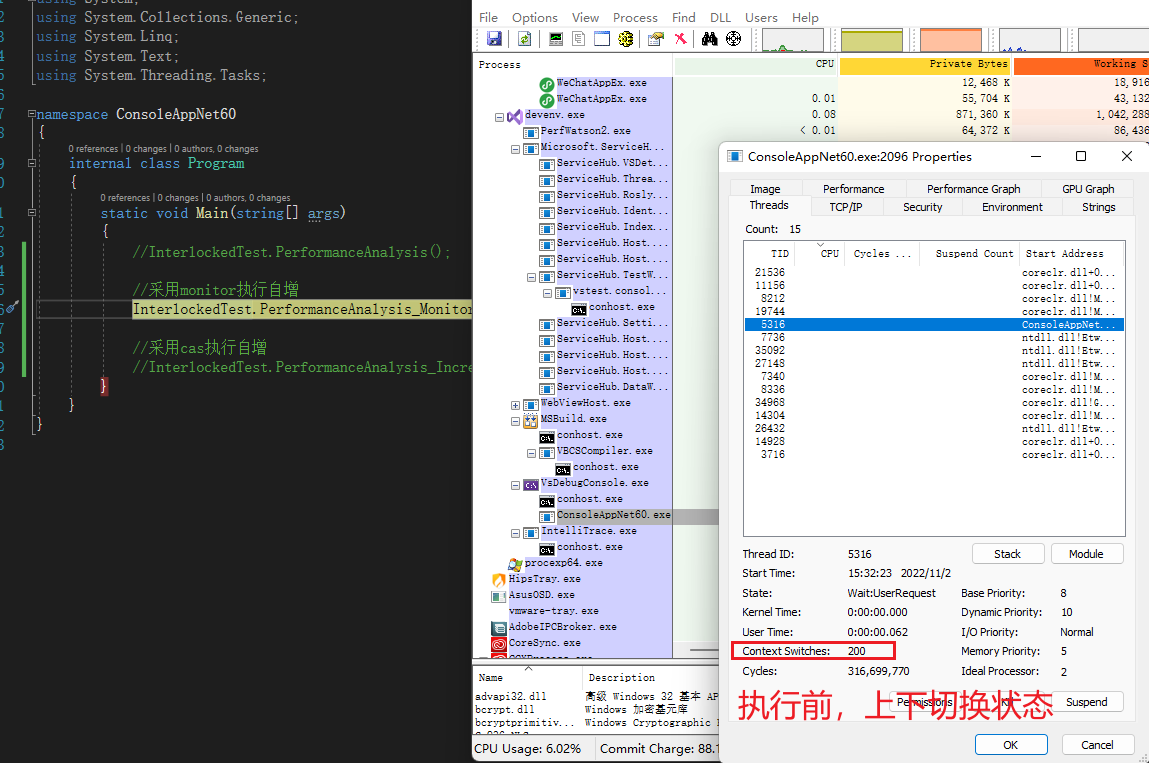
可以大概估計出,採用 lock(Monitor)同步自增方式,上下文切換 243 次
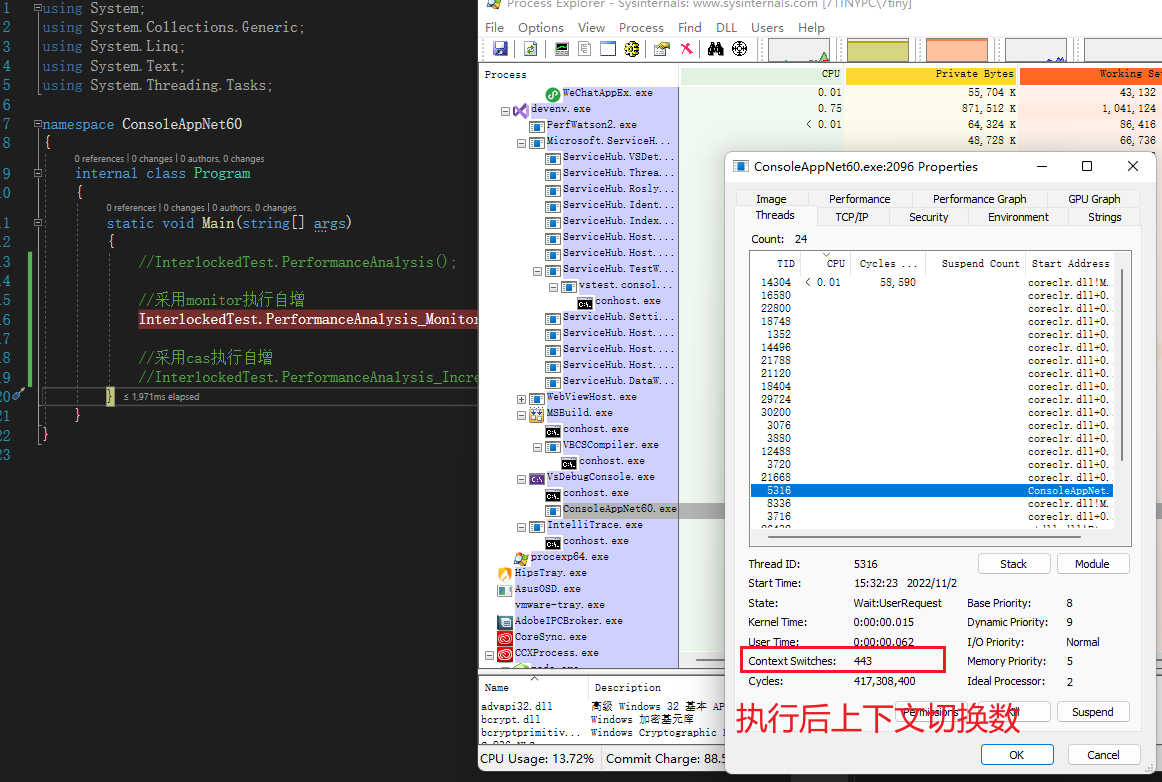
那麼我們用同樣的方式看下底層用 CAS 函數執行自增的開銷
Visual Studio 自帶的分析工具,檢視執行緒使用率
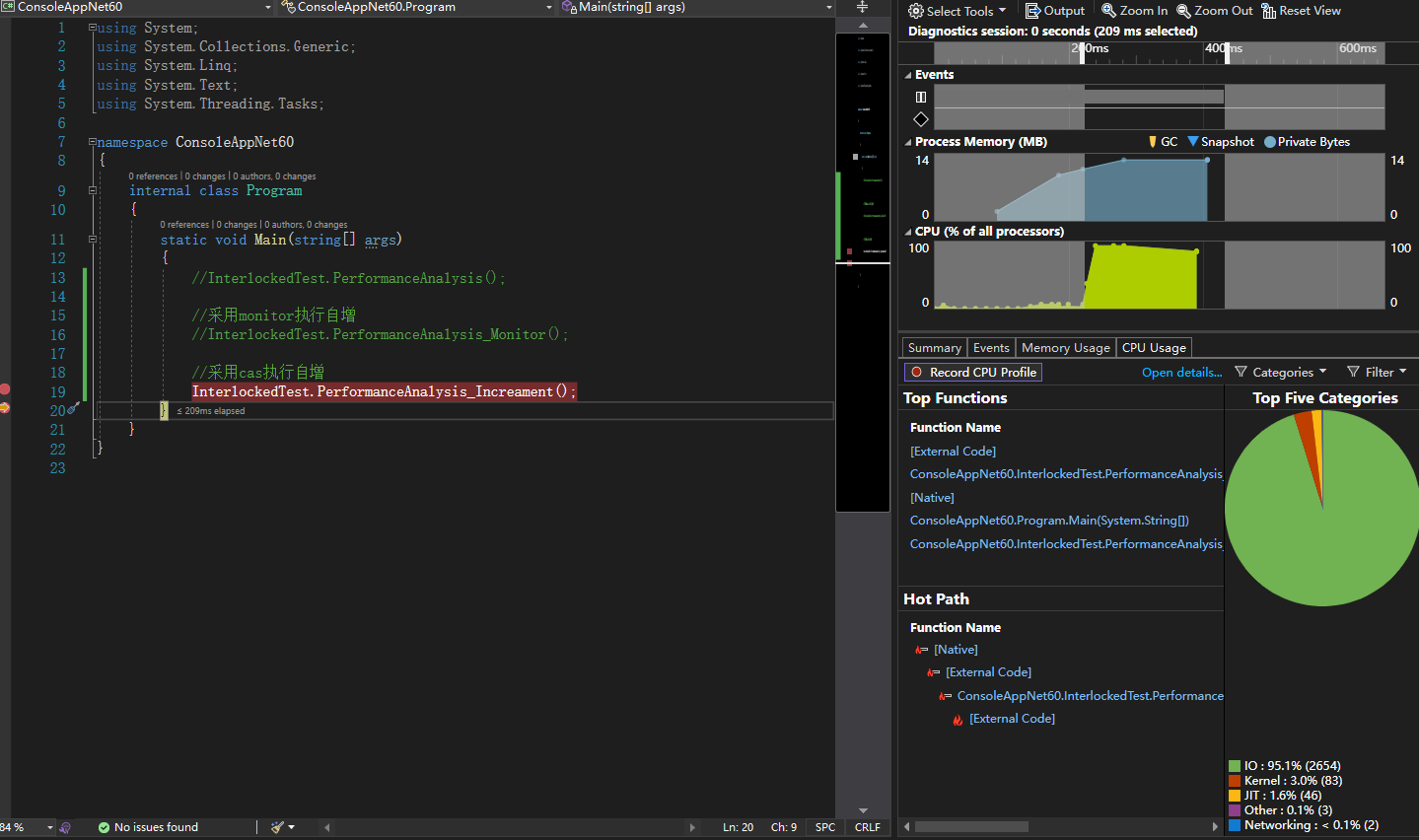
使用 Process Explorer 工具檢視程式碼執行過程中上下文切換數
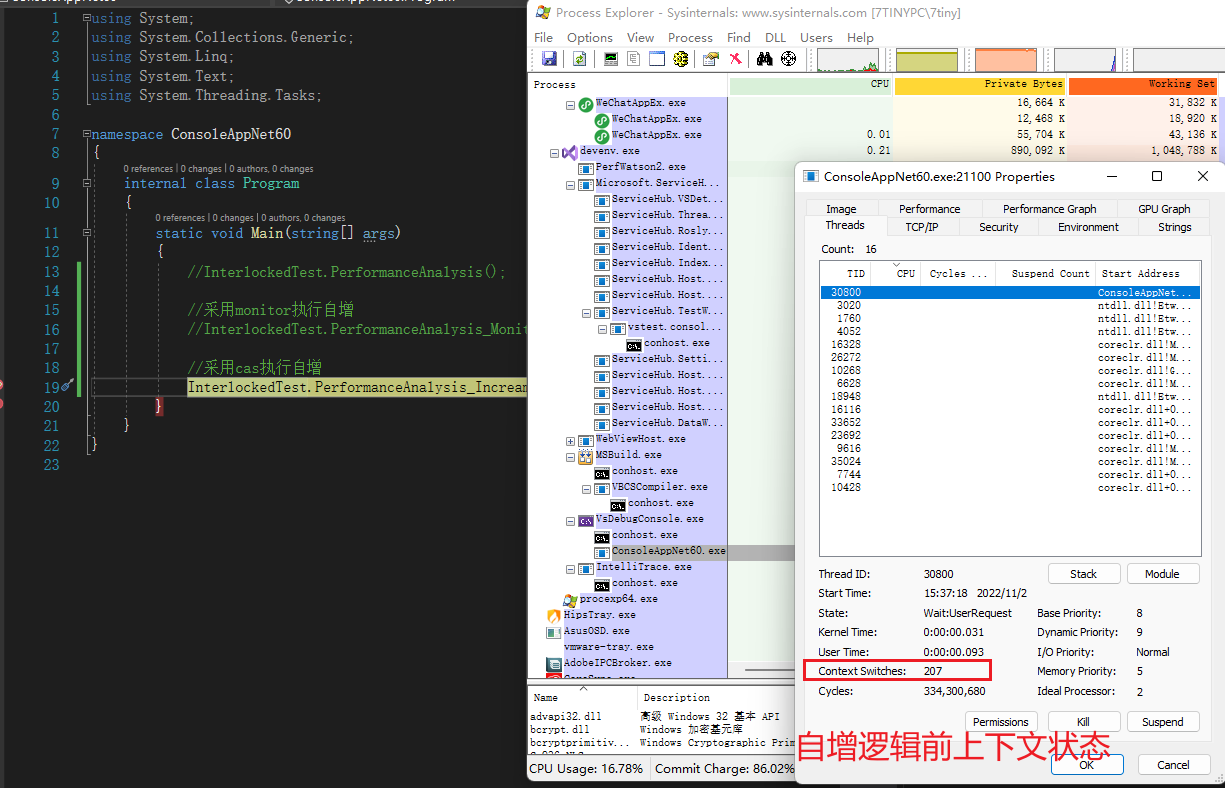
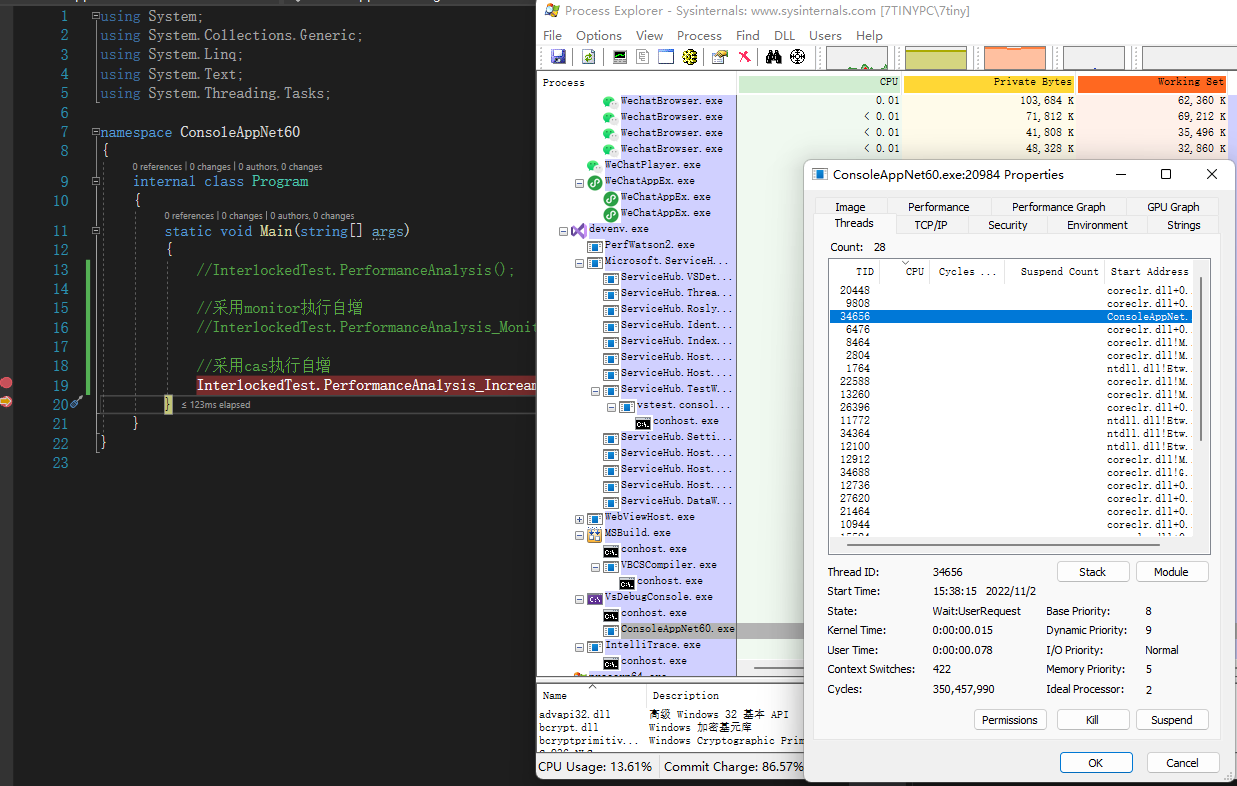
可以大概估計出,採用 CAS 自增方式,上下文切換 220 次
可見,不論使用什麼技術手段,執行緒建立太多都會帶來大量的執行緒上下文切換
這個應該是和測試的程式碼相關
兩者比較大的區別在CPU的使用率上,因為 lock 方式會造成執行緒阻塞,因此不會所有的CPU核心同時參與運算,CPU在當前程序上使用率不會太高,但 cas 方式CPU在自己的時間分片內並沒有被阻塞或重新排程,而是不停地執行比較替換的動作(其實這種場景算是無用功,不必要的負開銷),造成CPU使用率非常高。
【總結】
簡單來說,Interlocked 類提供的方法給我們帶來了方便快捷操作欄位的方式,比起使用鎖同步的程式設計方式來說,要輕量不少,執行效率也大大提高。但是該技術並非銀彈,一定要考慮清楚使用的場景後再決定使用,比如伺服器web應用下,多執行緒執行大量耗費CPU的運算,可能會嚴重影響應用吞吐量。雖然表面看起來執行這個單一的任務效率高一些(代價是CPU全部撲在這個任務上,無法響應其他任務),其實在我們的測試中,總共執行了 10000000 次運算,這種場景應該是比較極端的,而且在web應用場景下,用 lock 的方式響應時間也沒有達到不能容忍的程度,但是用 lock 的好處是cpu可以處理其他使用者請求的任務,極大提高了吞吐量。
我們建議在競爭較少的場景,或者不需要很高吞吐量的場景下(簡單說是CPU時間不那麼寶貴的場景下)我們可以用 Interlocked 類來保證操作的原子性,可以適當提升效能。而在競爭非常激烈的場景下,一定不要用 Interlocked 來處理原子性操作,改用 lock 方式會好很多。
【原始碼地址】
https://github.com/sevenTiny/CodeArts/blob/master/CSharp/ConsoleAppNet60/InterlockedTest.cs
【博主宣告】
作者:
7tiny
Software Development
北京市海淀區 Haidian Area Beijing 100089,P.R.China
郵箱Email : [email protected] 
網址Http: http://www.7tiny.com
WeChat: seven-tiny
更多聯絡方式點我哦~
Best Regard ~