G1 垃圾收集器深入剖析(圖文超詳解)

G1(Garbage First)垃圾收集器是目前垃圾回收技術最前沿的成果之一。
G1 同 CMS 垃圾回收器一樣,關注最小時延的垃圾回收器,適合大尺寸堆記憶體的垃圾收集。但是,G1 最大的特點是引入分割區的思路,弱化了分代的概念,合理利用垃圾收集各個週期的資源,解決了其他收集及 CMS 的很多缺陷。
官方推薦使用 G1 來代替 CMS。
通過本篇,我們可以瞭解掌握 G1 收集器的基本概念、堆記憶體、回收流程、GC模式、推薦用例等核心知識。
目錄
G1 收集器概述
HotSpot 團隊一直努力朝著高效收集、減少停頓 (STW: Stop The World) 的方向努力,貢獻了從序列 Serial 收集器、到並行收集器 Parallerl 收集器,再到 CMS 並行收集器,乃至如今的 G1 在內的一系列優秀的垃圾收集器。
G1(Garbage First) 垃圾收集器,是關注最小時延的垃圾回收器,也同樣適合大尺寸堆記憶體的垃圾收集,官方推薦選擇使用 G1 來替代 CMS 。
1. G1 收集器的最大特點
- G1最大的特點是引入分割區的思路,弱化了分代的概念。
- 合理利用垃圾收集各個週期的資源,解決了其他收集器、甚至 CMS 的眾多缺陷。
2. G1 的改進(相比較 CMS )
- 演演算法: G1 基於標記--整理演演算法, 不會產生空間碎片,在分配大物件時,不會因無法得到連續的空間,而提前觸發一次 FULL GC 。
- 停頓時間可控: G1可以通過設定預期停頓時間(Pause Time)來控制垃圾收集時間避免應用雪崩現象。
- 並行與並行:G1 能更充分的利用 CPU 多核環境下的硬體優勢,來縮短 stop the world 的停頓時間。
3. CMS 和 G1 的區別
- CMS 中,堆被分為 PermGen,YoungGen,OldGen ;而 YoungGen 又分了兩個 survivo 區域。在 G1 中,堆被平均分成幾個區域 (region) ,在每個區域中,雖然也保留了新老代的概念,但是收集器是以整個區域為單位收集的。
- G1 在回收記憶體後,會立即同時做合併空閒記憶體的工作;而 CMS ,則預設是在 STW(stop the world)的時候做。
- G1 會在 Young GC 中使用;而 CMS 只能在 O 區使用。
4. G1 收集器的應用場景
目前,CMS 還是預設首選的 GC 策略。
G1 垃圾收集演演算法,主要應用在多 CPU 大記憶體的服務中,在滿足高吞吐量的同時,儘可能的滿足垃圾回收時的暫停時間。
在以下場景中,G1 更適合:
- 伺服器端多核 CPU、JVM 記憶體佔用較大的應用(至少大於4G);
- 應用在執行過程中,會產生大量記憶體碎片、需要經常壓縮空間;
- 想要更可控、可預期的 GC 停頓週期,防止高並行下應用雪崩現象。
G1 的堆記憶體演演算法
1. G1 之前的 JVM 記憶體模型

- 新生代:伊甸園區 (eden space) + 2個倖存區
- 老年代
- 持久代 (perm space):JDK1.8 之前
- 元空間 (metaspace):JDK1.8 之後取代持久代
2. G1收集器的記憶體模型
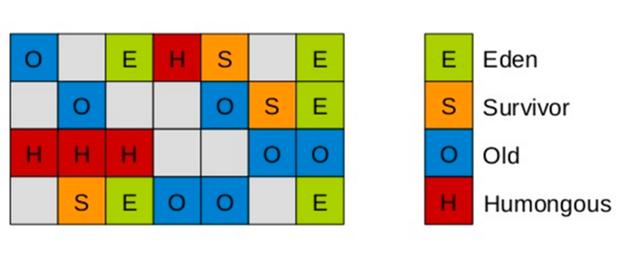
2.1 G1 堆記憶體結構
堆記憶體會被切分成為很多個固定大小區域(Region),每個是連續範圍的虛擬記憶體。
堆記憶體中一個區域 (Region) 的大小,可以通過 -XX:G1HeapRegionSize 引數指定,大小區間最小 1M 、最大 32M ,總之是 2 的冪次方。
預設是將堆記憶體按照 2048 份均分。
2.2 G1 堆記憶體分配
每個 Region 被標記了 E、S、O 和 H,這些區域在邏輯上被對映為 Eden,Survivor 和老年代。
存活的物件從一個區域轉移(即複製或移動)到另一個區域。區域被設計為並行收集垃圾,可能會暫停所有應用執行緒。如上圖所示,區域可以分配到 Eden,survivor 和老年代。
此外,還有第四種型別,被稱為巨型區域(Humongous Region)。
Humongous 區域主要是為儲存超過 50% 標準 region 大小的物件設計,它用來專門存放巨型物件。如果一個 H 區裝不下一個巨型物件,那麼 G1 會尋找連續的 H 分割區來儲存。為了能找到連續的 H 區,有時候不得不啟動 Full GC 。
G1 回收流程
在執行垃圾收集時,G1 以類似於 CMS 收集器的方式執行。
1. G1 收集器的階段,大致分為以下步驟:
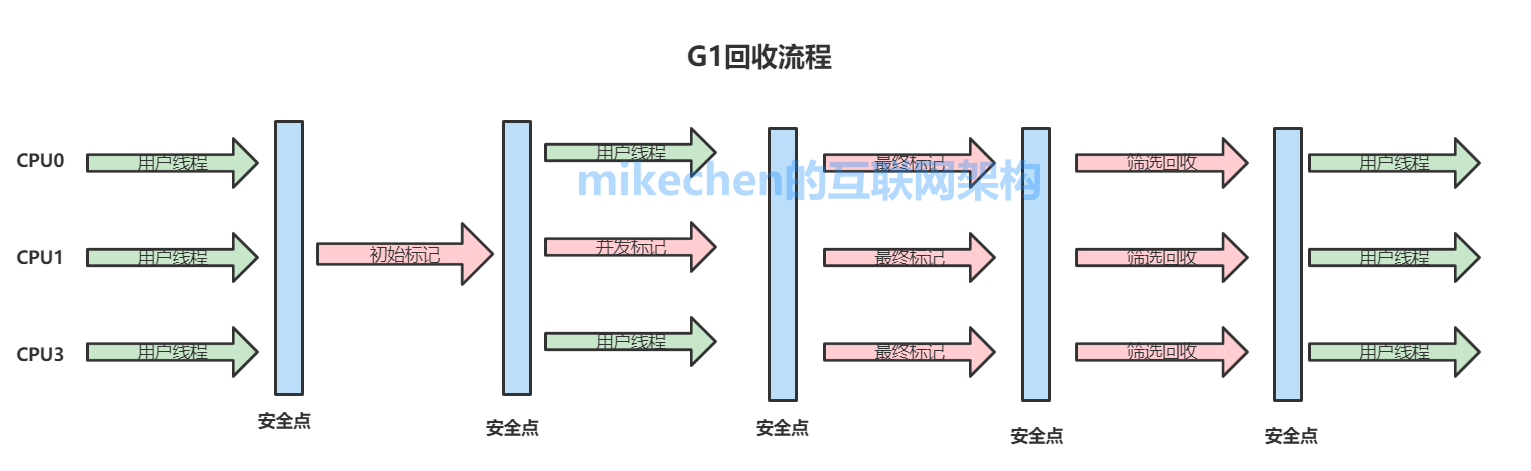
1.1 G1 執行的第一階段:初始標記 ( Initial Marking )
這個階段是 STW(Stop the World ) 的,所有應用執行緒會被暫停,標記出從 GC Root 開始直接可達的物件。
1.2 G1 執行的第二階段:並行標記
從 GC Roots 開始,對堆中物件進行可達性分析,找出存活物件,耗時較長。
當並行標記完成後,開始最終標記 ( Final Marking ) 階段。
1.3 最終標記
標記那些在並行標記階段發生變化的物件,將被回收。
1.4 篩選回收
首先,對各個 Regin 的回收價值和成本進行排序,根據使用者所期待的 GC 停頓時間,來指定回收計劃,回收一部分 Region 。
G1 中提供了 Young GC、Mixed GC 兩種垃圾回收模式,這兩種垃圾回收模式,都是 Stop The World(STW) 的。
G1 的 GC 模式
1. YoungGC 年輕代收集
在分配一般物件(非巨型物件)時,當所有 eden region 使用達到最大閥值、並且無法申請足夠記憶體時,會觸發一次 YoungGC 。
每次 younggc 會回收所有Eden 、以及 Survivor 區,並且將存活物件複製到 Old 區以及另一部分的 Survivor 區。
YoungGC 的回收過程:
- 根掃描,跟 CMS 類似,Stop the world,掃描 GC Roots 物件;
- 處理 Dirty card,更新 RSet;
- 掃描 RSet ,掃描 RSet 中所有 old 區,對掃描到的 young 區或者 survivor 區的參照;
- 拷貝掃描出的存活的物件到 survivor2/old 區;
- 處理參照佇列、軟參照、弱參照、虛參照。
2. mixed gc
當越來越多的物件晉升到老年代 old region 時,為了避免堆記憶體被耗盡,虛擬機器器會觸發一個混合的垃圾收集器,即 mixed gc ,該演演算法並不是一個 old gc ,除了回收整個 young region ,還會回收一部分的 old region 。
這裡需要注意:是一部分老年代,而不是全部老年代,可以選擇哪些 old region 進行收集,從而可以對垃圾回收的耗時時間進行控制。
G1 沒有 fullGC 概念,需要 fullGC 時,呼叫 serialOldGC 進行全堆掃描(包括 eden、survivor、o、perm)。
G1 的推薦用例
G1 的第一個重要特點:是為使用者的應用程式的提供一個低GC延時和大記憶體GC的解決方案。
這意味著堆大小 6GB 或更大,穩定和可預測的暫停時間將低於 0.5 秒。
如果應用程式使用 CMS 或 ParallelOld 垃圾回收器,具有一個或多個以下特徵,將有利於切換到 G1:
- Full GC 持續時間太長或太頻繁;
- 物件分配率或年輕代升級老年代很頻繁;
- 不期望的很長的垃圾收集時間或壓縮暫停(超過 0.5 至 1 秒)。
注意:
如果你正在使用 CMS 或 ParallelOld 收集器,且應用程式沒有遇到長時間的垃圾收集暫停,則保持當前收集器就可以了。升級 JDK ,並不需要更新收集器為 G1 。
以上,是 G1 垃圾收集器的解析,歡迎評論區留言交流或拓展。
如果覺得有用,請順手關注+推薦+轉發支援下,謝謝。
作者簡介
陳睿 | mikechen , 10年+大廠架構經驗,「mikechen 的網際網路架構」系列文章作者,專注於網際網路架構技術。