Java 編碼那些事(二)
建議先閱讀:Java 編碼那些事(一)
現在說說編碼在Java中的實際運用。在使用tomcat的時候,絕大部分同學都會遇到亂碼的問題,查查檔案,google一下解決方案啥的,都是設定這裡,設定那裡,或者在程式碼中新增編碼方式,雖然最終問題解決了,但是你真的知道這是什麼意思麼?
在平時開發Java的時候,我們會遇到很多編碼設定,其中包括:
-
Java檔案的編碼:
Java檔案的編碼表示編寫程式碼得時候,.java檔案本身的編碼,這個編碼的影響在於將你的寫的程式碼原始檔複製一份,使用其他編輯器開啟,若兩個編輯器的預設編碼方式不一樣,則開啟原始檔就會變成亂碼。一般英文的影響不大,因為大多數編碼都相容ASCII編碼,但是中文要是編碼不正確,則會亂碼。IDEA的設定在:Setting->Editor->File Encodings中設定 -
JVM編碼:
JVM編碼表示JVM在讀取String型別的預設編碼,可以使用Charset.defaultCharset().name()獲取。可以在JVM啟動引數中使用-Dfile.encoding=UTF-8進行設定。
一般需要區分的就是這兩種編碼。下面著重說下JVM編碼的體現。
位元組流與字元流
熟悉IO的同學應該都明白這兩個流的區別。一般會出現字元亂碼都在於需要與其他程式進行IO的時候。
先看看使用位元組流進行讀取檔案的時候:
public static void main(String[] args){ String path="G:\\test.txt"; try(BufferedInputStream inputStream=new BufferedInputStream(new FileInputStream(path))) { for (byte bytes[] = new byte[1024]; inputStream.read(bytes) != -1; ) { String context = new String(bytes); System.out.println(context); } }catch (IOException e){ e.printStackTrace(); } }
然後再G盤新建一個文字檔案,輸入一段文字。使用預設的格式儲存。
可以檢視輸出:
�����ļ��ļ�
亂碼了,下面來分析一下:
首先這裡是JVM執行時的編碼,因此和JVM的編碼設定有關。列印JVM目前的編碼設定:
System.out.println(Charset.defaultCharset().name());
輸出:UTF-8
找到剛剛新建的檔案test.txt,點選另存為,可以發現預設編碼為ANSI,前一篇文章中說過,ANSI作為windows系統中的特殊存在,它在簡體中文編碼的情況下預設為GBK編碼。這便是亂碼的原因,解決方案有兩種:
- 設定
JVM啟動項:-Dfile.encoding = GB2312 - 在編碼
byte陣列的時候,指定GB2312編碼:String context = new String(bytes,"GB2312");
這裡推薦第二種,畢竟UTF8更加通用
問題完美解決。
同理,網路IO也能通過以上方法解決。
看明白了上面的發現問題和解決問題的流程的同學,下次遇到檔案編碼的問題,相信應該能夠獨立解決問題。
實戰
明白了各種編碼問題,現在我們可以著手進行實戰。
第一次使用IDEA開發Servlet的時候,大多數都會遇見亂碼問題,包括:
-
控制檯輸出
Tomcat紀錄檔亂碼 -
網頁顯示
Servlet返回的中文亂碼
雖然各種Google後,終於解決了,但是可能依然不明白其中的緣由。下面我們來一探究竟
Tomcat紀錄檔
首先解決Tomcat紀錄檔亂碼的問題,首先要明白:Tomcat作為一個獨立的程序,IDEA是怎麼獲取到Tomcat紀錄檔的呢?在IDEA控制檯中的Tomcat啟動紀錄檔中,我們可以找到一個紀錄檔記錄:
-Dcatalina.base=C:\xxx\.IntelliJIdea2018.3\system\tomcat\xxx
複製選項中的路徑,在資料夾中開啟,進入logs資料夾,就可以發現這個是tomcat的紀錄檔檔案輸出路徑,而IDEA正是讀取了這個檔案中的內容輸出到控制檯中,我們可以使用記事本開啟紀錄檔檔案,然後選擇另存為,可以發現檔案的預設編碼是ANSI,也就說在簡體中文下是GBK編碼。
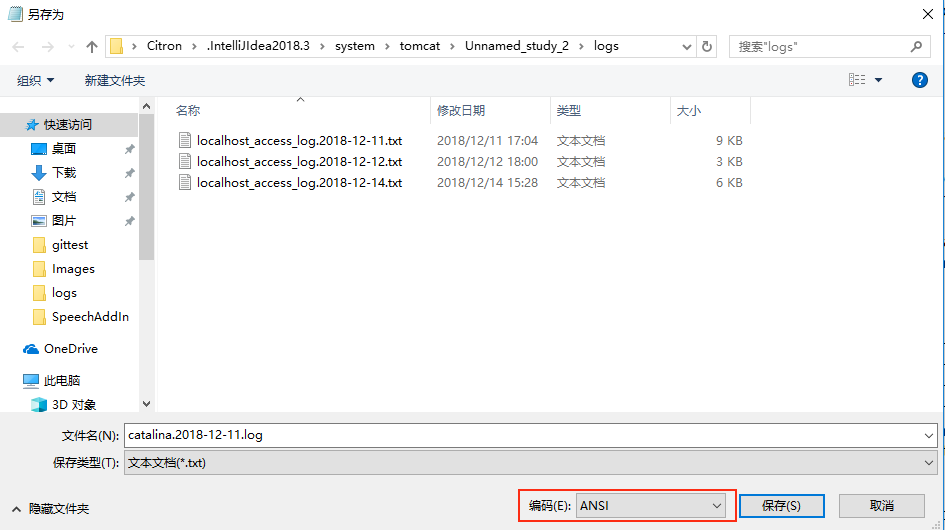
而讀取文字檔案內容一般有兩種方式,第一種是字元流,第二種是位元組流,位元組流可以指定字元編碼也可以通過的JVM啟動引數-Dfile.encoding指定預設編碼。
明白了上面的問題,我們就能知道為什麼亂碼了,這是因為IDEA的預設編碼和這個紀錄檔檔案的編碼格式不統一導致的。
解決方案很簡單,統一兩個系統的編碼,對於Tomcat的輸出的紀錄檔檔案,我們可以設定Tomcat啟動的VM選項:Edit Configurations->Server-> VM options編輯新增:-Dfile.encoding=UTF-8
設定完Tomcat編碼後,刪除剛剛路徑中的紀錄檔檔案,重啟Tomcat服務,再使用記事本開啟剛剛的紀錄檔檔案,另存為我們可以發現,編碼已經變成了UTF-8。
IDEA
接下來設定IDEA的編碼,IDEA預設編碼暫時沒有找到查詢方式,我們也可以將其指定為UTF-8,找到IDEA的安裝路徑,在bin目錄中可以發現一個名為idea.exe.vmoptions和idea64.exe.vmoptions選項,分別開啟,新增-Dfile.encoding=UTF-8後,重啟IDEA.
完成上面兩步後,再次啟動Tomcat服務,你會發現紀錄檔已經正常。
注:如果依然發現亂碼,則可能是IDEA快取了當前專案的編碼設定,你可以在當前專案的
.idea資料夾中找到encoding.xml檔案,刪除所有不是UTF-8的編碼設定,重啟IDEA即可。
網頁亂碼
我們都知道,瀏覽器瀏覽的網頁其實是從伺服器傳送的HTML檔案到瀏覽器中顯示,而傳送的是通過位元組流傳輸,這個過程就涉及到解碼->編碼的過程,在HTTP協定中,編碼的協定通過Header中的charset中設定。
為什麼放
header,因為HTTP請求會先解析header,而且header一般不會有ascii無法解析的字元,一般都是英文
網頁亂碼其實很好解決,如果發現在Servlet中,返回中文給瀏覽器的時候瀏覽器返回的是???
點選F12,抓包網路後,找到Response Body 中的charset選項,可以發現charset=ISO-8859-1
也就說預設的Tomcat使用的編碼是ISO-8859-1,這是西歐的語言編碼,它是不相容中文的。如果你在Servlet返回的結果中新增一點法語:Ä ä或者德語什麼的,你會發現會正常顯示。
charset的意思便是Tomcat是以什麼樣的方式編碼位元組,而瀏覽器便會以這樣的編碼方式解碼位元組。
我們可以將charset修改為相容中文的即可,比如UTf-8,GB2312等,建議使用UTF-8,在Servlet中,設定編碼的方式為:
response.setCharacterEncoding("UTF-8");
也可以如下:
resp.setContentType("text/html;charset=UTF-8");
建議第一種方式。
到這裡,所有的亂碼問題都已經解決。
其實,亂碼不可怕,可怕的是經歷了這麼多次亂碼卻依然不去了解它。
~~
微信搜尋公眾號:StackTrace,關注我們,不斷學習,不斷提升