一臺虛擬機器器,基於docker搭建巨量資料HDP叢集
前言
好多人問我,這種基於巨量資料平臺的xxxx的畢業設計要怎麼做。這個可以參考之前寫得關於我巨量資料畢業設計的文章。這篇文章是將對之前的畢設進行優化。
個人覺得可以分為兩個部分。第一個部分就是基礎的平臺搭建。例如Hadoop叢集、Kafka叢集。
第二個部分就是上層應用的建設,例如基於巨量資料平臺的資料分析,以及大屏展示之類的視覺化應用。前者提供了基礎平臺能力,讓整個設計加入巨量資料元素;後者提供了上層應用能力,主要是讓別人明白你利用巨量資料平臺做了什麼。
前些日子閒得無聊,在一臺虛擬機器器上基於docker容器,使用Ambari搭建了一個HDP版本的Hadoop巨量資料叢集。所以就結合這篇文章,對第一部分進行闡述,提供一個新的思路。
思路
在叢集搭建的過程中,遇到了形形色色的問題。在問題裡去思考、去查閱資料。這是一個蠻有意思的事情。
在上一篇文章也寫了,我的巨量資料畢業設計的Hadoop平臺搭建部分,是基於三臺虛擬機器器實現的。當時使用的Apache版本的Hadoop。
Apache版本的缺點是沒有一個統一的管控平臺。
- 前期的安裝需要在每個節點手動分發安裝包、執行啟動命令。
- 後期的節點維護、服務啟停都需要去後臺執行命令。
加上三臺虛擬機器器,每次啟動費個老勁。所以我就尋思用Ambari來搭建一個HDP版本的、一個虛擬機器器就能搞定的、基於docker容器的Hadoop叢集。
整體架構
整個架構設計和技術選型,都是根據個人需求選擇,可以參考。
1. 技術選型
宿主機和docker的作業系統選擇的是centos7。我嘗試了centos8,不太行。主要
- docker:容器,代替虛擬機器器節點搭建叢集
- docker-compose:編排容器。對所有容器進行管理、啟動
- Ambari:2.7.3版本。視覺化安裝、監控、管理所有叢集。
- HDP:3.1版本。其中包括Hadoop、HDFS、Yarn、Spark、Kafka、Zookeeper等服務。
- MySQL:ambari後設資料庫。後面應用也會用到。
除此之外,還需要shell編寫一些指令碼。
2. 架構設計

平臺一覽
這就是Ambari的首頁儀表盤的部分,裡面可以看到HDFS的儲存,記憶體使用量指標。

Hadoop叢集
Hadoop叢集一共用了四個節點。NameNode,一個備用的NameNode,兩個DataNode。

點選右側的NameNode UI可以看到Hadoop叢集的UI介面。
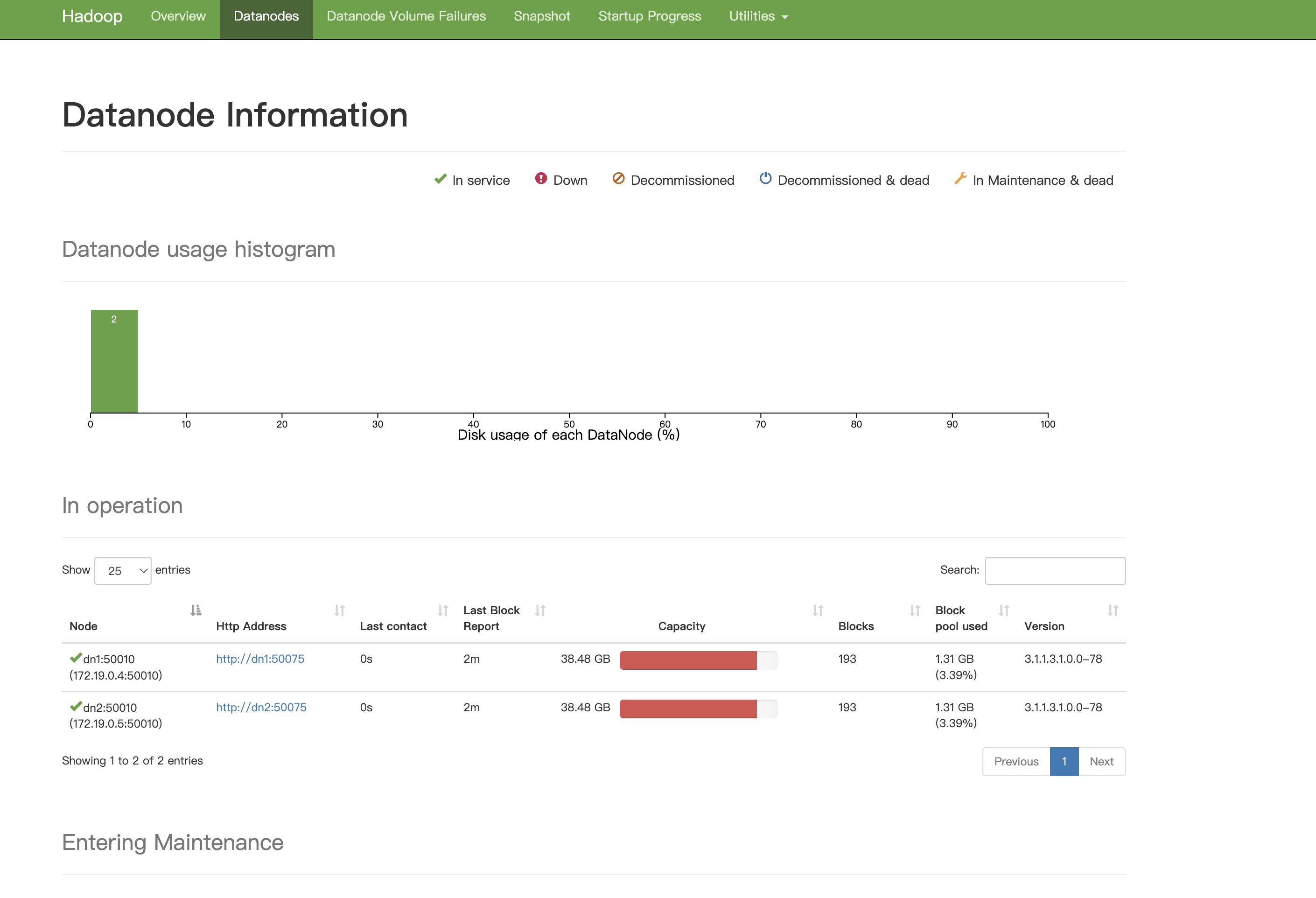
叢集節點
這裡的Hosts指的就是所有叢集節點的個數,也是docker節點的個數。這裡因為記憶體有限,所以一個docker啟動了好幾個服務。

例如這個kafka1節點,即安裝了Kafka,又安裝了Zookeeper。

環境準備
我在實踐docker搭建叢集的時候,90%的時間都花費在了環境準備上。同樣,遇到的90%的問題也都在這個步驟上。
1. 虛擬機器器準備
我自己的架構是一臺虛擬機器器,然後其他節點都是用docker代替的。docker你可以理解為輕量虛擬機器器。
我選擇docker的理由:
- 覺得挺有意思,想挑戰一下自己的軟肋。
- *一個虛擬機器器可能需要佔用20G儲存,一個docker只佔用幾百MB**。
- 只需要啟動一臺虛擬機器器即可。docker作為應用服務執行在這臺虛擬機器器上。
其實,這裡我是建議使用3 ~ 4臺虛擬機器器的。因為docker本身對於很多人來說是有一定難度的,再加上需要將docker構建成節點,是需要花費很多時間的。
2. docker容器準備
如果說是頭鐵非要用docker,那麼可以看看這一步。我在這一步構建節點docker映象的時候,反覆構建了很多次。
dockerfile
我們要自己編寫dockerfile幾月centtos7來構建docker容器的系統映象。而且,docker容器代替了虛擬機器器,那麼docker容器裡的環境就要和虛擬機器器一樣。所以dockerfile需要滿足以下條件。
- 開放22埠,啟動sshd服務
- 設定jdk、scala
- 生成金鑰,設定ssh免密登入
- python2.7(centos7自帶)
- yum安裝一些軟體,例如chrony等
- 設定hosts
在編寫dockerfile階段,查閱了很多資料,反覆構建,嘗試了很多次才成功。
docker-compose
docker-compose是docker容器的編排工具,需要編寫一個yaml組態檔,通過start/stop來啟動/停止所有的容器。

這個centos_hdp就是我自己構建的映象,ports來開放容器的埠,volumes來掛載宿主機的目錄。
3. 下載安裝包
我在2016年畢業設計中,所搭建的巨量資料平臺的各個元件都是獨立下載安裝的。Hadoop的安裝包需要去Hadoop官網下載,Kafka安裝包需要去Kafka官網下載。想安裝哪個版本就安裝哪個版本。
基於Ambari安裝,所有元件都包含在HDP安裝包裡,不過這個安裝包挺大的,10G。
ambari-2.7.3.0-centos7.tar.gz
HDP-3.1.0.0-centos7-rpm.tar.gz
HDP-UTILS-1.1.0.22-centos7.tar.gz
HDP-GPL-3.1.0.0-centos7-gpl.tar.gz
上面就是所需安裝包的列表,下載到之後,放到本地搭建的http伺服器中,在ambari安裝中時使用。
結語
本篇文章主要講了巨量資料叢集搭建的架構設計和實現思路部分,後面文章會探討上層應用的構建。我現在自己也在學前端,想自己實現一些web應用。關於巨量資料叢集搭建、後臺實現以及前端技術,可以私我加群互相交流。
基於docker使用Ambari搭建Hadoop是有難度的,謹慎嘗試。
