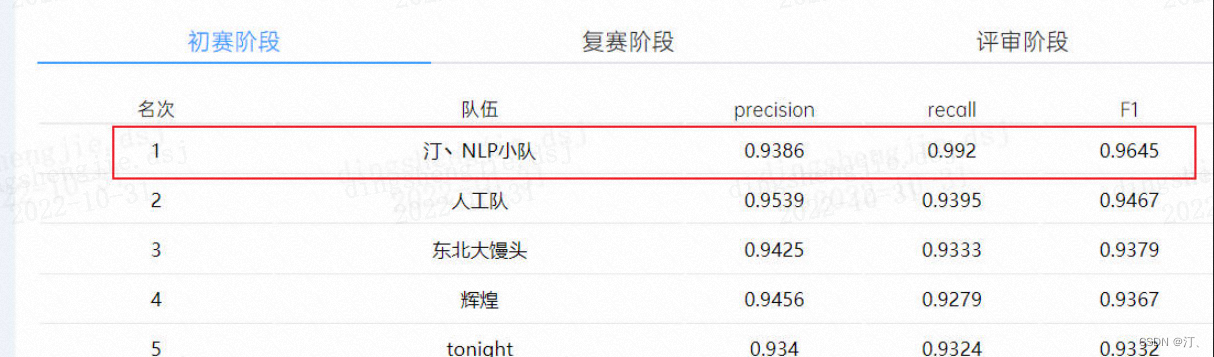
基線提升至96.45%:2022 司法杯犯罪事實實體識別+資料蒸餾+主動學習
本專案給出本次法研杯詳細的技術方案,從UIE-base開始到UIE資料蒸餾以及主動學習的建議,歡迎大家嘗試,ps:主動學習標註需要自行實現,參考專案,樓主就不標註了。
專案連結:https://aistudio.baidu.com/aistudio/projectdetail/4911042?contributionType=1
0.法研杯 LAIC2022 司法人工智慧挑戰賽犯罪事實實體識別
0.1比賽簡介
任務介紹
本賽道由中國司法巨量資料研究院承辦。
犯罪事實實體識別是司法NLP應用中的一項核心基礎任務,能為多種下游場景所複用,是案件特徵提取、類案推薦等眾多NLP任務的重要基礎工具。本賽題要求選手使用模型抽取出犯罪事實中相關預定義實體。
與傳統的實體抽取不同,犯罪事實中的實體具有領域性強、分佈不均衡等特性。
官網:http://data.court.gov.cn/pages/laic.html
資料介紹
- (1) 本賽題資料來源於危險駕駛罪的犯罪事實,分為有標註樣本和無標註樣本,供選手選擇使用;
- (2) 資料格式:訓練集資料每一行表示為一個樣本,context表示犯罪事實,entities表示實體對應的標籤(label)及其位置資訊(span);entities_text表示每個標籤label對應的實體內容;
- (3) 兩條標註樣本之間以換行符為分割;
- (4) 訓練集:有標註訓練樣本:200條(分初賽、複賽兩次提供,資料集包括驗證集,不再單獨提供驗證集,由選手自己切分);無標註樣本10000條;
- (5) 標註樣本範例:
{"datasetid": "2552", "id": "813087", "context": "經審理查明,2014年4月12日下午,被告人鄭某某酒後駕駛二輪摩托車由永定縣鳳城鎮往仙師鄉方向行駛過程中,與鄭某甲駕駛的小轎車相碰刮,造成交通事故。經福建南方司法鑑定中心司法鑑定,事發時被告人鄭某某血樣中檢出乙醇,乙醇含量為193.27mg/100ml血。經永定縣公安局交通管理大隊責任認定,被告人鄭某某及被害人鄭某甲均負事故的同等責任。案發後,被告人鄭某某與被害人鄭某甲已達成民事賠償協定並已履行,被告人鄭某某的行為已得到被害人鄭某甲的諒解。另查明,被告人鄭某某的機動車駕駛證E證已於2014年2月6日到期,且未在合理期限內辦理相應續期手續。", "entities": [{"label": "11341", "span": ["25;27"]}, {"label": "11339", "span": ["29;34"]}, {"label": "11344", "span": ["54;57", "156;159", "183;186", "215;218"]}, {"label": "11345", "span": ["60;63"]}, {"label": "11342", "span": ["34;47"]}, {"label": "11348", "span": ["164;168"]}], "entities_text": {"11341": ["酒後"], "11339": ["二輪摩托車"], "11344": ["鄭某甲", "鄭某甲", "鄭某甲", "鄭某甲"], "11345": ["小轎車"], "11342": ["由永定縣鳳城鎮往仙師鄉方向"], "11348": ["同等責任"]}}
評價方式:
$F_1=\frac{2 \times \text { 準確率 }(\text { precision }) \times \text { 召回率 }(\text { recall })}{\text { 準確率 }(\text { precision })+\text { 召回率 }(\text { recall })}$
其中:精確率(precision):識別出正確的實體數/識別出的實體數,召回率(recall):識別出正確的實體數 / 樣本的實體數
相關要求及提交說明
初賽階段採用上傳預測答案的方式進行測評,複賽需上傳模型,請選手嚴格按照以下說明規範提交:
1. 本賽題不允許通過增加額外有監督樣本數量提升模型的預測效果。
2. 只允許產出一個模型,複賽前需要列印模型結構進行驗證。主模型不允許多個模型序列或者並行,比如bert+bert;主模型以外允許適當的結構序列,比如bert+crf。模型結構隨壓縮包提供。
3. 模型儲存空間 ≤2.0G。
4. 法研基線模型請前往LAIC2022GitHub網站;請務必按照README中的相關說明組織檔案,並製成ZIP壓縮包上傳。
賽程安排
1. 初賽階段(2022年9月21日-2022年12月09日)
釋放初賽資料集,開放初賽排名榜。選手所提交答案的得分超過初賽基線模型分數,自動晉級複賽。
2. 複賽階段(2022年10月31日-2022年12月09日)
釋放複賽資料集,開放複賽排名榜;選手於複賽結束前選擇三個模型和所選模型對應的原始碼等審查材料[注]進入封測評審階段。
3. 封測評審階段(2022年12月10日-12月25日)
模型將在封閉資料集上進行測試,獲得模型的封測成績。
4. 技術交流會(2022年12月下旬)
邀請成績優異的選手進行模型分享,並和專家觀眾進行論證和討論。
5. 釋出成績(2022年12月底)
公佈最終成績,參賽者的最終成績為模型的封測成績和複賽成績按7:3加權取得的分數的最高分。
注:請提前準備,若未在規定時間內提交,視為放棄。
若選手所提供的原始碼無法復現初複賽結果,或被判為成績無效,最終解釋權歸中國司法巨量資料研究院所有。
結果預覽:
| 模型 | Precision | Recall | F1 |
|---|---|---|---|
| Base | 88.96 | 95.37 | 92.06 |
| Base+全量 | 93.86 (+4.9) | 99.2 (+3.83) | 96.45 (+4.39) |
| UIE Slim | 98.632 (+9.67) | 98.736 (+3.37) | 98.684(+6.62) |
0.2 資料集預覽:
無標註:
{"fullText": "經審理查明,2016年6月4日0時57分許,被告人張偉飲酒後駕駛號跨界高爾夫牌小型轎車由北向南行駛至濱河東路南中環橋向西轉匝道路段時,遇張某駕駛的無號牌東風-福龍馬牌中型載貨專項作業車逆向行駛後準備向南右轉時橫在濱河東路中間,二車發生相撞,造成同乘人曹某當場死亡、同乘人楊某經醫院搶救無效死亡、張偉本人受傷及兩車損壞的交通事故。經鑑定,從張偉送檢的血樣中檢出乙醇成分,含量為140.97mg/100ml。從張某送檢的血樣中未檢出乙醇成分,經交警部門依法認定,張偉、張某承擔事故的同等責任,楊某、曹某無責任。2016年6月13日,張某所屬的太原市高新技術產業開發區環境衛生管理中心向曹某、楊某家屬進行了民事賠償。被害人曹某的家屬對被告人張偉的行為表示諒解。", "id": "dfe98005-0491-4015-94ff-a7f50185aa70"}
有標註:
{"id": "813046", "context": "經審理查明,2016年9月24日19時20分許,被告人陳某某酒後駕駛蒙L80783號比亞迪牌小型轎車由東向西行駛至內蒙古自治區鄂爾多斯市準格爾旗薛家灣鎮鑫凱盛小區「金娃娃拉麵館」門前道路處時,與由西向東行駛至此處的駕駛人範某某駕駛的蒙ANB577號豐田牌小型越野客車相撞,造成兩車不同程度受損的道路交通事故。被告人陳某某在該起事故中承擔同等責任。經某政府1鑑定,被告人陳某某血液酒精含量檢驗結果為259.598mg/100ml,屬醉酒狀態。被告人陳某某明知他人報警而在現場等候。2016年9月29日被告人陳某某的妻子馮某某與駕駛人範某某就車損賠償達成了私了協定書。", "entities": [{"label": "11341", "span": ["30;32"]}, {"label": "11339", "span": ["46;50"]}, {"label": "11340", "span": ["50;56"]}, {"label": "11342", "span": ["57;94"]}, {"label": "11346", "span": ["97;106"]}, {"label": "11344", "span": ["110;113", "265;268"]}, {"label": "11345", "span": ["127;133"]}, {"label": "11348", "span": ["168;172"]}, {"label": "11350", "span": ["215;219"]}], "entities_text": {"11341": ["酒後"], "11339": ["小型轎車"], "11340": ["由東向西行駛"], "11342": ["內蒙古自治區鄂爾多斯市準格爾旗薛家灣鎮鑫凱盛小區「金娃娃拉麵館」門前道路處"], "11346": ["由西向東行駛至此處"], "11344": ["範某某", "範某某"], "11345": ["小型越野客車"], "11348": ["同等責任"], "11350": ["醉酒狀態"]}}
實體型別:
'11339': '被告人交通工具',
'11340': '被告人行駛情況',
'11341': '被告人違規情況',
'11342': '行為地點',
'11343': '搭載人姓名',
'11344': '其他事件參與人',
'11345': '參與人交通工具',
'11346': '參與人行駛情況',
'11347': '參與人違規情況',
'11348': '被告人責任認定',
'11349': '參與人責任認定',
'11350': '被告人行為總結',
1.baseline——模型訓練預測(UIE model)
UIE模型使用情況參考下面連結,寫的很詳細了要考慮了工業部署情況方案
參考連結:
UIE Slim滿足工業應用場景,解決推理部署耗時問題,提升效能!
PaddleNLP之UIE資訊抽取小樣本進階(二)[含doccano詳解]
Paddlenlp之UIE模型實戰實體抽取任務【打車資料、快遞單】
1.1 資料處理
#資料轉化
import json
span={'11339': '被告人交通工具',
'11340': '被告人行駛情況',
'11341': '被告人違規情況',
'11342': '行為地點',
'11343': '搭載人姓名',
'11344': '其他事件參與人',
'11345': '參與人交通工具',
'11346': '參與人行駛情況',
'11347': '參與人違規情況',
'11348': '被告人責任認定',
'11349': '參與人責任認定',
'11350': '被告人行為總結',
}
def convert_record(source):
target = {}
target["id"] = int(source["id"])
target["text"] = source["context"]
target["relations"] = []
target["entities"] = []
id = 0
for item in source["entities"]:
for i in range(len((item['span']))):
tmp = {}
tmp['id'] = id
id = id + 1
tmp['start_offset'] = int(item['span'][i].split(';')[0])
tmp['end_offset'] = int(item['span'][i].split(';')[1])
tmp['label'] = span[item['label']]
target["entities"].append(tmp)
return target
if __name__ == '__main__':
train_file = 'data/train.json'
json_data = []
content_len=[]
for line in open(train_file, 'r',encoding='utf-8'):
json_data.append(json.loads(line))
content_len.append(len(json.loads(line)["context"]))
ff = open('data/train_new.txt', 'w')
for item in json_data:
target = convert_record(item)
ff.write(json.dumps(target, ensure_ascii=False ) + '\n')
ff.close()
print(content_len)
1.2 模型訓練驗證
#模型訓練
!python finetune.py \
--train_path "./data/train.txt" \
--dev_path "./data/dev.txt" \
--save_dir "./checkpoint_base" \
--learning_rate 5e-6 \
--batch_size 32 \
--max_seq_len 512 \
--num_epochs 30 \
--model "uie-base" \
--seed 1000 \
--logging_steps 10 \
--valid_steps 100 \
--device "gpu"
訓練結果預覽:
[2022-10-31 10:25:43,181] [ INFO] - global step 510, epoch: 8, loss: 0.00172, speed: 2.33 step/s
[2022-10-31 10:25:45,959] [ INFO] - global step 520, epoch: 8, loss: 0.00171, speed: 3.60 step/s
[2022-10-31 10:25:51,260] [ INFO] - global step 530, epoch: 9, loss: 0.00169, speed: 1.89 step/s
[2022-10-31 10:25:55,512] [ INFO] - global step 540, epoch: 9, loss: 0.00167, speed: 2.35 step/s
[2022-10-31 10:25:59,746] [ INFO] - global step 550, epoch: 9, loss: 0.00166, speed: 2.36 step/s
[2022-10-31 10:26:04,010] [ INFO] - global step 560, epoch: 9, loss: 0.00164, speed: 2.35 step/s
[2022-10-31 10:26:08,215] [ INFO] - global step 570, epoch: 9, loss: 0.00162, speed: 2.38 step/s
[2022-10-31 10:26:12,343] [ INFO] - global step 580, epoch: 9, loss: 0.00160, speed: 2.42 step/s
[2022-10-31 10:26:16,597] [ INFO] - global step 590, epoch: 10, loss: 0.00159, speed: 2.35 step/s
[2022-10-31 10:26:20,881] [ INFO] - global step 600, epoch: 10, loss: 0.00157, speed: 2.33 step/s
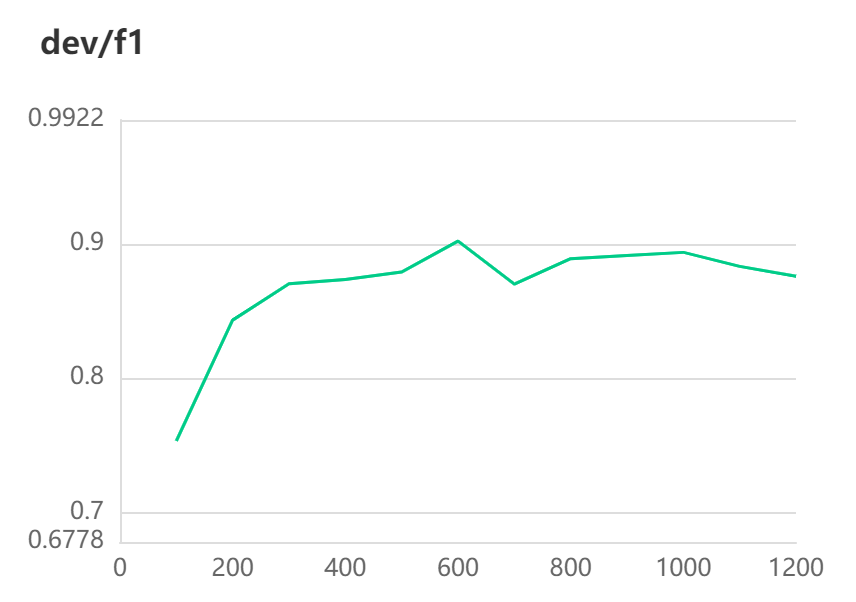
[2022-10-31 10:26:26,571] [ INFO] - Evaluation precision: 0.90678, recall: 0.89727, F1: 0.90200
[2022-10-31 10:26:26,571] [ INFO] - best F1 performence has been updated: 0.87898 --> 0.90200
best模型已儲存
2.全量訓練
專案連結:https://aistudio.baidu.com/aistudio/projectdetail/4911042?contributionType=1
[2022-10-31 11:02:25,276] [ INFO] - global step 2010, epoch: 8, loss: 0.00076, speed: 2.36 step/s
[2022-10-31 11:02:29,618] [ INFO] - global step 2020, epoch: 8, loss: 0.00075, speed: 2.30 step/s
[2022-10-31 11:02:33,167] [ INFO] - global step 2030, epoch: 8, loss: 0.00075, speed: 2.82 step/s
[2022-10-31 11:02:37,961] [ INFO] - global step 2040, epoch: 9, loss: 0.00075, speed: 2.09 step/s
[2022-10-31 11:02:42,213] [ INFO] - global step 2050, epoch: 9, loss: 0.00074, speed: 2.35 step/s
[2022-10-31 11:02:46,600] [ INFO] - global step 2060, epoch: 9, loss: 0.00074, speed: 2.28 step/s
[2022-10-31 11:02:50,923] [ INFO] - global step 2070, epoch: 9, loss: 0.00074, speed: 2.31 step/s
[2022-10-31 11:02:55,188] [ INFO] - global step 2080, epoch: 9, loss: 0.00074, speed: 2.34 step/s
[2022-10-31 11:02:59,528] [ INFO] - global step 2090, epoch: 9, loss: 0.00073, speed: 2.30 step/s
[2022-10-31 11:03:03,827] [ INFO] - global step 2100, epoch: 9, loss: 0.00073, speed: 2.33 step/s
[2022-10-31 11:03:27,192] [ INFO] - Evaluation precision: 0.98632, recall: 0.98736, F1: 0.98684
[2022-10-31 11:03:27,193] [ INFO] - best F1 performence has been updated: 0.98193 --> 0.98684
best模型已儲存

在各種主動學習方法中,查詢函數的設計最常用的策略是:不確定性準則(uncertainty)和差異性準則(diversity)。 不確定性越大代表資訊熵越大,包含的資訊越豐富;而差異性越大代表選擇的樣本能夠更全面地代表整個資料集。
對於不確定性,我們可以藉助資訊熵的概念來進行理解。我們知道資訊熵是衡量資訊量的概念,也是衡量不確定性的概念。資訊熵越大,就代表不確定性越大,包含的資訊量也就越豐富。事實上,有些基於不確定性的主動學習查詢函數就是使用了資訊熵來設計的,比如熵值裝袋查詢(Entropy query-by-bagging)。所以,不確定性策略就是要想方設法地找出不確定性高的樣本,因為這些樣本所包含的豐富資訊量,對我們訓練模型來說就是有用的。
那麼差異性怎麼來理解呢?之前說到或查詢函數每次迭代中查詢一個或者一批樣本。我們當然希望所查詢的樣本提供的資訊是全面的,各個樣本提供的資訊不重複不冗餘,即樣本之間具有一定的差異性。在每輪迭代抽取單個資訊量最大的樣本加入訓練集的情況下,每一輪迭代中模型都被重新訓練,以新獲得的知識去參與對樣本不確定性的評估可以有效地避免資料冗餘。但是如果每次迭代查詢一批樣本,那麼就應該想辦法來保證樣本的差異性,避免資料冗餘。
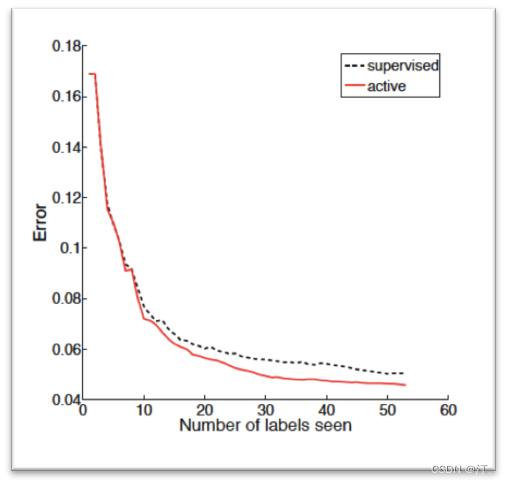
從上圖也可以看出來,在相同數目的標註資料中,主動學習演演算法比監督學習演演算法的分類誤差要低。這裡注意橫軸是標註資料的數目,對於主動學習而言,相同的標註資料下,主動學習的樣本數>監督學習,這個對比主要是為了說明兩者對於訓練樣本的使用效率不同:主動學習訓練使用的樣本都是經過演演算法篩選出來對於模型訓練有幫助的資料,所以效率高。但是如果是相同樣本的數量下去對比兩者的誤差,那肯定是監督學習佔優,這是毋庸置疑的。
4.2active learning與半監督學習的不同
很多人認為主動學習也屬於半監督學習的範疇了,但實際上是不一樣的,半監督學習和直推學習(transductive learning)以及主動學習,都屬於利用未標記資料的學習技術,但基本思想還是有區別的。
如上所述,主動學習的「主動」,指的是主動提出標註請求,也就是說,還是需要一個外在的能夠對其請求進行標註的實體(通常就是相關領域人員),即主動學習是互動進行的。
而半監督學習,特指的是學習演演算法不需要人工的干預,基於自身對未標記資料加以利用。
4.3.主動學習基礎策略(小試牛刀)
常見主動學習策略
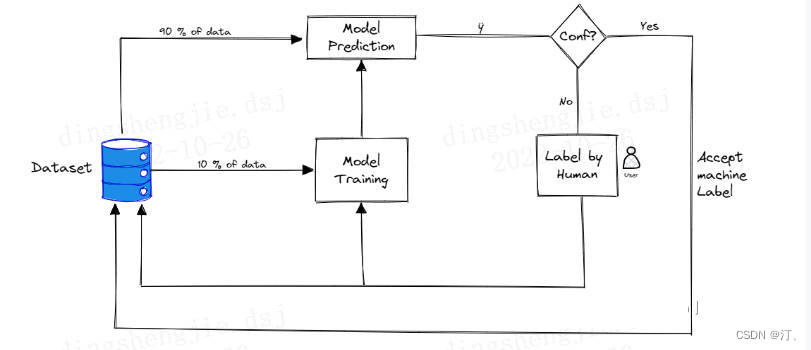
在未標記的資料集上使用主動學習的步驟是:
- 首先需要做的是需要手動標記該資料的一個非常小的子樣本。
- 一旦有少量的標記資料,就需要對其進行訓練。該模型當然不會很棒,但是將幫助我們瞭解引數空間的哪些領域需要首標記。
- 訓練模型後,該模型用於預測每個剩餘的未標記資料點的類別。
- 根據模型的預測,在每個未標記的資料點上選擇分數
- 一旦選擇了對標籤進行優先排序的最佳方法,這個過程就可以進行迭代重複:在基於優先順序分數進行標記的新標籤資料集上訓練新模型。一旦在資料子集上訓練完新模型,未標記的資料點就可以在模型中執行並更新優先順序分值,繼續標記。
- 通過這種方式,隨著模型變得越來越好,我們可以不斷優化標籤策略。
參考專案:主動學習(Active Learning)綜述以及在文字分類和序列標註應用
5.總結
| 模型 | Precision | Recall | F1 |
|---|---|---|---|
| Base | 88.96 | 95.37 | 92.06 |
| Base+全量 | 93.86 (+4.9) | 99.2 (+3.83) | 96.45 (+4.39) |
| UIE Slim | 98.632 (+9.67) | 98.736 (+3.37) | 98.684(+6.62) |
簡單歸納一下:增加標註量是關鍵
-
資料標註佔比很重要,未利用的1w資料需要利用起來,而且小樣本資料下資料覆蓋面需要用一定方法維持,目前得分高的應該都是額外增加標註量了
-
提升預測速度,UIE資料蒸餾方案推薦使用(GlobalPointer),並可以在這個基礎上優化,用mini等更小的模型
-
主動學習用起來,篩選出困難樣本,爭取達到30%標註量實現全樣本效果!通過多輪迭代實現在這個任務的智慧標註
最後感謝肝王@javaroom之前提供的baseline的資料預處理過程和提交資料轉換,剩了編寫處理時間。
參考專案:主動學習(Active Learning)綜述以及在文字分類和序列標註應用
UIE模型使用情況參考下面連結,寫的很詳細了要考慮了工業部署情況方案
參考連結:
UIE Slim滿足工業應用場景,解決推理部署耗時問題,提升效能!
PaddleNLP之UIE資訊抽取小樣本進階(二)[含doccano詳解]
Paddlenlp之UIE模型實戰實體抽取任務【打車資料、快遞單】