這個面試題居然從11年前就開始討論了,而官方今年才表態。
大家好,我是歪歪。
這期給大家盤一個面試題啊,就是下面的第二題。

這個面試題的圖片都被弄的有一點「包漿」了。
所以為了你的觀感,我還是把第二道題目手打一遍。
嘖嘖嘖,這行為,暖男作者實錘了:
spring 在啟動期間會做類掃描,以單例模式放入 ioc。但是 spring 只是一個個類進行處理,如果為了加速,我們取消 spring 自帶的類掃描功能,用寫程式碼的多執行緒方式並行進行處理,這種方案可行嗎?為什麼?
老實說,我第一次看到這個面試題的時候,人是懵的。

我知道 Spring 在啟動期間會把 bean 放到 ioc 容器中,但是到底是單執行緒還是多執行緒放,我還真不清楚。
所以我做的第一件事情是去驗證題目中這句話:但是 spring 只是一個個類進行處理。
怎麼去驗證呢?
肯定是找原始碼啊,原始碼之下無祕密啊。
怎麼去找呢?
這個就需要你個人的經驗積累了,抽絲剝繭的去翻 Spring 原始碼,這個就不是本文重點了,所以我就不細說了。
但是我可以教你一個我一般用的比較多的奇技淫巧。
首先你肯定要搞個 Bean 在專案裡面,比如我這裡的 Person:

然後把專案紀錄檔級別調整為 debug:
logging.level.root=debug
接著啟動專案,在專案裡面找 Person 的關鍵字。
原理就是這是一個 Bean,Spring 在操作它的時候一定會列印相關紀錄檔,從紀錄檔反向去查詢程式碼,要快的多。
所以通過 Debug 紀錄檔,我們能定位到這樣一行關鍵紀錄檔:
Identified candidate component class: xxxx.Person.class]

然後全域性搜尋鍵碼,就能找到這個地方:

這個地方,就是打第一個斷點的地方。
然後啟動專案,從呼叫堆疊往前找,能找到這個地方:

這個類就是我要找的類:
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan
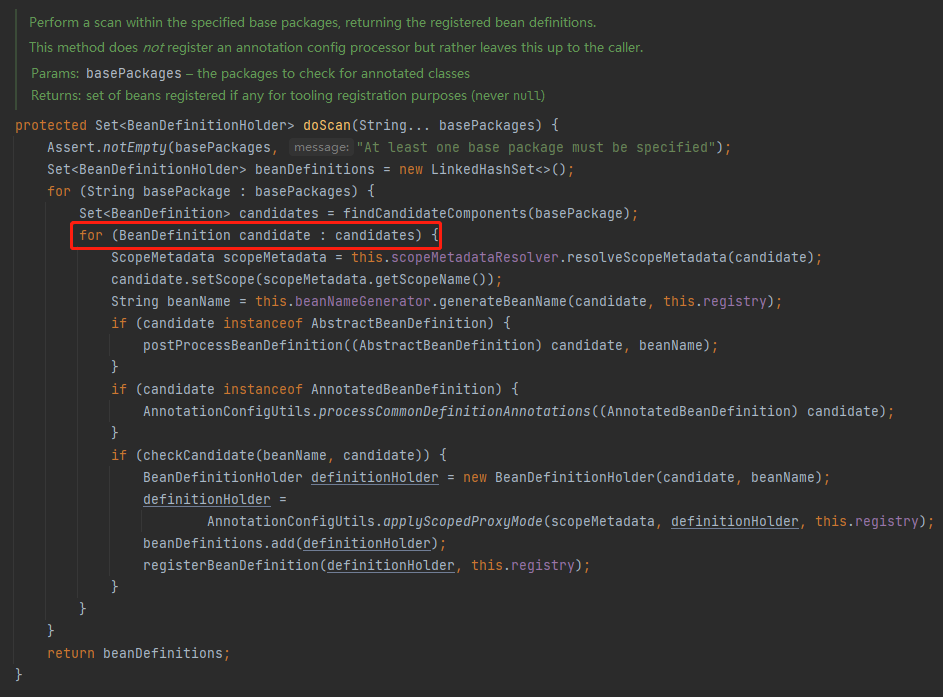
從原始碼上看,裡面確實沒有並行相關的操作,看起來確實是在 for 迴圈裡面單執行緒一個個處理的 Bean 的。
那麼從理論上講,如果是兩個沒有任何關聯關係的 Bean,比如我下面 Person 和 Student 這兩個 Bean,它們在交給 Spring 託管,往 ioc 容器裡面放的時候,完全可以用兩個不同的執行緒處理嘛:
所以問題就來了:
如果為了加速,我們取消 spring 自帶的類掃描功能,用寫程式碼的多執行緒方式並行進行處理,這樣可以嗎?
可以嗎?
我也不知道啊。
但是我知道去哪裡找答案。
但是在找答案之前,我先大膽的猜一個答案:不可以。
為什麼?
因為我看的是 Spring 5.x 版本的原始碼,在這個版本里面還是單執行緒處理 Bean。
對於 Spring 這種使用規模如此之大的開源框架來說,如果能支援多執行緒載入的話,肯定老早就支援了。
所以我先盲猜一個:不可以。

找答案
這個問題的答案肯定就藏在 Spring 的 issues 裡面。
不要問我為什麼知道。這是來自老程式設計師的直覺。
所以我直接就是來到了這裡:
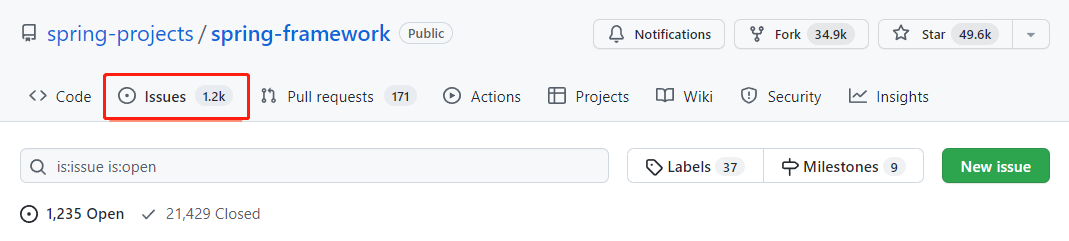
1.2k 個 issue,怎麼找到我想要找的呢?
肯定是用關鍵詞搜尋一波。基於現在掌握的資訊,你說關鍵詞是什麼?
肯定是我們前面找到的這個方法、這個類啊,這也是你唯一掌握到的資訊:
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#doScan
話不多說,先拿著類名搜一搜,看看啥情況。
從搜尋結果上看,真的是一搜就中:

我帶你看看這個 issue 的具體內容:
https://github.com/spring-projects/spring-framework/issues/28221
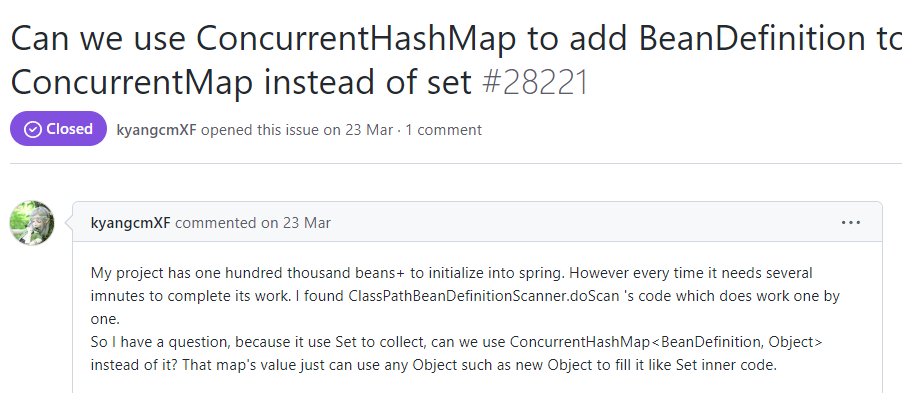
有個叫做 kyangcmXF 的同學...
呃,我第一眼看到他的名字的時候,看到有 F,K 還有 C,第一瞬間想起的是「瘋狂星期四」。
那我就叫他「星期四」同學吧。
「星期四」同學說:我的專案有數以萬計的 Bean 要被 Spring 初始化。所以每次專案啟動的時候需要好幾分鐘才能完成工作。
然後他發現 doScan 的程式碼是單執行緒,一個一個的去處理 Bean 的。
所以他提出了一個問題:我是不是可以用 ConcurrentHashMap 來代替 Set 資料結果,然後並行載入。
他的問題和我們文章開頭提出的面試題可以說是一模一樣。而他甚至還給出了實現的程式碼:
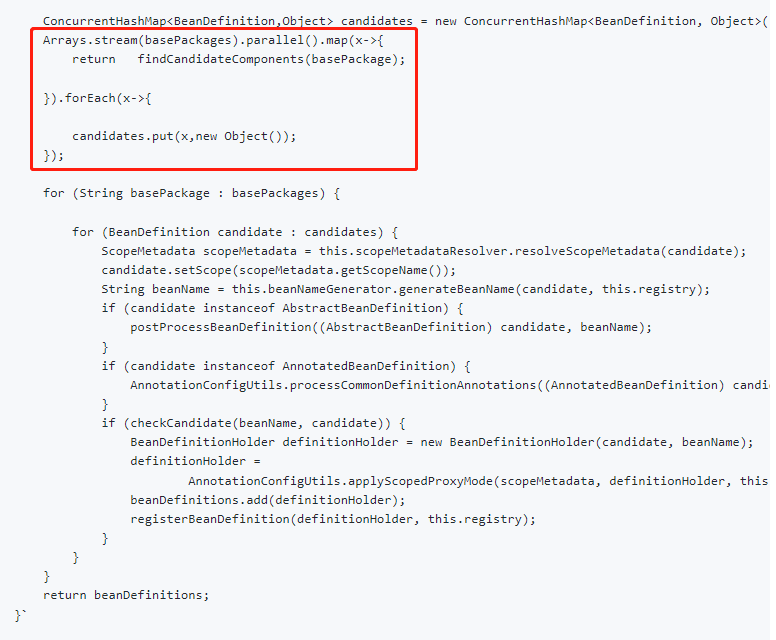
然後這個 issue 下只有一個回覆,是這樣的:

首先,我們先看看這條回覆的人是誰:

他就是 Spring 的 Contributors,他的回答可以說就是官方回答了。
他給「星期四」同學說:thanks 老鐵,but not possible。
but post-processing bean definitions asynchronously is not possible at the moment.
目前不可能非同步的對 bean 進行後置處理。
到這裡,我們至少知道了,想用非同步載入的方式確實是在實現上有困難,不僅僅是簡單的單執行緒改多執行緒。
然後,這個老哥給「星期四」同學指了條路,說如果你想要進一步瞭解的話,可以看看編號為 13410 的 issue。
雖然我們現在已經有一個答案了,但是既然大佬指路了,那我肯定高低得帶你去瞅上一眼。

還得從11年前說起
根據大佬指路的方向,我點開這個 issue 的時候都震驚了:
https://github.com/spring-projects/spring-framework/issues/13410

題目翻譯過來是「在啟動期間並行的處理 Bean 的初始化」,緊扣我們的面試題。
讓我震驚的主要是這個 issue 的建立時間:2011 年 10 月 12 號。
好傢伙,原來 11 年前大家就提出了這個問題並進行了討論。
但是根據我多年在 github 上衝浪的經驗,遇到這種「年久失修」的 issue 不能從頭到尾的看,得反著來,得先看最後一個回覆是什麼時候。
所以我直接就是一個拉到最後,沒想到最後一個回覆還挺新鮮,是三個月前:

回答的這個哥們,也是 Spring 的官方人員,所以可以理解針對這個問題的官方回答:
這個哥們說了很長一段,我簡單的翻譯一下:
他說這個問題在最新的 6.0 版本中也不會被解決,因為它目前的優先順序並不是特別高。
在處理真正的啟動案例時,我們經常發現,時間都花在少數幾個相互依賴的特定 bean 上。在那裡引入並行化,在很多情況下並不能節省多少,因為這並不能加快關鍵路徑。這通常與 ORM 設定和資料庫遷移有關。
你也可以使用「應用程式啟動跟蹤功能」(application startup tracking)為自己的應用程式收集更多這方面的資訊:可以看到啟動時間花在哪裡以及是如何花的,以及並行化是否會改善這種情況。
對於 Spring Framework 6.0,我們正專注於本地用例的 Ahead Of Time 功能,以及啟動時間的改進。
到這裡,就再次證明了官方對於並行化處理 bean 的態度:

但是這個哥們的回答中倒沒有說「這個功能做不了」,他說的是「經過調研,這個功能實現後的收益並不大」。
而且他還透露了一個關鍵的資訊,針對 Spring 啟動速度,在 6.0 裡面的方向是 AOT。
其這也不算透露,早在 2020 年,甚至更早,我記得 Spring 就說過以後的努力方向是 AOT,提前編譯(Ahead-of-Time Compilation)。
如果你對於 AOT 很陌生的話,可以去了解一下,不是本文重點,提一下就行。
接下來,關於這個 11 年前的貼文,裡面的內容還是比較多,我只能帶你簡單瀏覽一下貼文,如果你想要了解細節的話,還得自己去看看。
首先,提出這個問題的人其實已經提出了自己的解決之道:
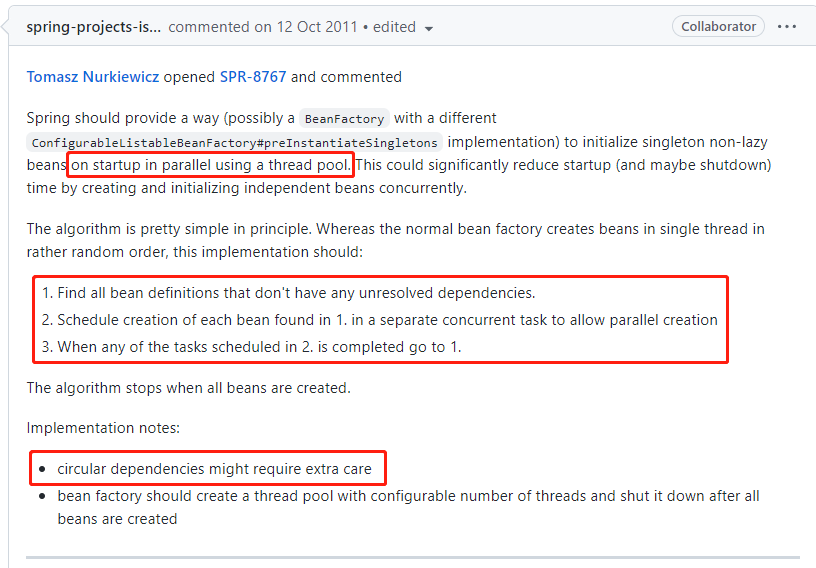
核心想法還是在 Bean 初始化的時候引入執行緒池,然後並行初始化 Bean。只是需要特別考慮的是存在迴圈依賴的 Bean。
然後官方立馬就站出來對線了:

小老弟,雖然從程式碼上看,在 Spring 容器中引入並行的 Bean 初始化看起來是直截了當的方法,但在實現起來並非看起來這麼簡單。重要的是我們需要看到更多的反饋和需求,當大家都在說「Spring 容器的初始化從根本上說太慢了」,我們才會認真考慮這種改變。
接著有個老哥跳出來說:我這邊有個應用啟動花了 2 小時 30 分...

官方針對這個時長也表示很震驚:

但是他們的核心觀點還是:在 Spring 容器中並行化 Bean 初始化的好處對於少數使用 Spring 的應用程式來說是非常重要的,而壞處是不可避免的 Bug、增加的複雜性和意想不到的副作用,這些可能會影響所有使用 Spring 的應用程式,恐怕這不是一個有吸引力的前景。
官方還是把這個問題定義為"不會修復",因為如果沒有強有力的理由,官方確實不太可能在核心框架中引入這麼大的變化。
這個觀點也和他的第一句話很匹配:more pragmatic approach.
more 大家都認識。
approach,也應該是一個比較熟悉的單詞:

那麼 pragmatic 是什麼意思呢?
這個單詞不認識很正常,屬於生僻詞,但是你知道的,我寫技術文的時候順便教單詞。
pragmatic,翻譯過來是「務實的」的意思:
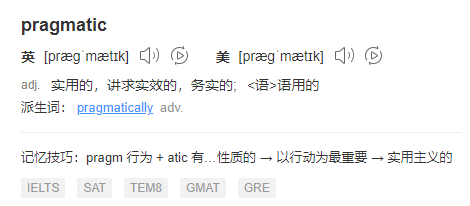
所以「more pragmatic approach」,是啥意思,來跟我大聲的讀一遍:更務實的方法。
官方的意思是,更務實的方法,就是先找到啟動慢的根本原因,而不是把問題甩鍋給 Spring,關鍵是這是核心邏輯,沒有強有力的理由,能不動,就別動。
然後期間就是使用者和官方之間的相互扯皮,一直扯到 5 年後,也就是 2016 年 6 月 30 日:

官方重要決定:好吧,把這個問題的優先順序提升一下,提升為"Major"任務,保留在 5.0 的積壓專案中。
但是...
好像官方這波放了鴿子。
直到 2018 年,網友又忍不住了,這個啥進度了呀?

沒有迴應。
又到了 2019 年,啥進度了啊,我很期待啊:

還是沒有迴應。
然後,時間來到了 2020 年。
三年之後又三年,現在都 9 年了,大佬,啥進度了啊?

斗轉星移,白駒過隙,白雲蒼狗,換了人間。時間很快,來到了 2021 年。
讓我們共同恭喜這個 issue 已經懸而未決 10 週年了:

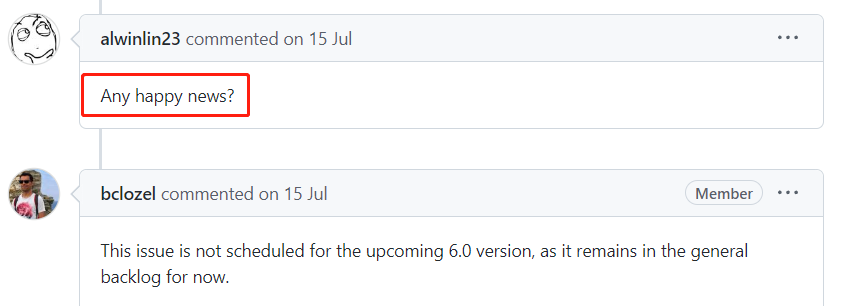
最後,就是今年了,7 月 15 日,網友提問:有什麼好訊息了嗎?
官方答:別問了,我鴿了,咋滴吧?

怎麼才能快?
在尋找答案的過程中,我找到了這樣的一個專案:
https://github.com/dsyer/spring-boot-allocations

這個專案是對於不同版本的 Spring Boot 做了啟動時間上的基準測試。
測試的結論最終都被官方採納了,所以還是很有權威性的。
整個測試方法和測試過程以及火焰圖什麼都在連結裡面貼了,我就不贅述了。
只是把最後的結論搬出來,給大家看看:
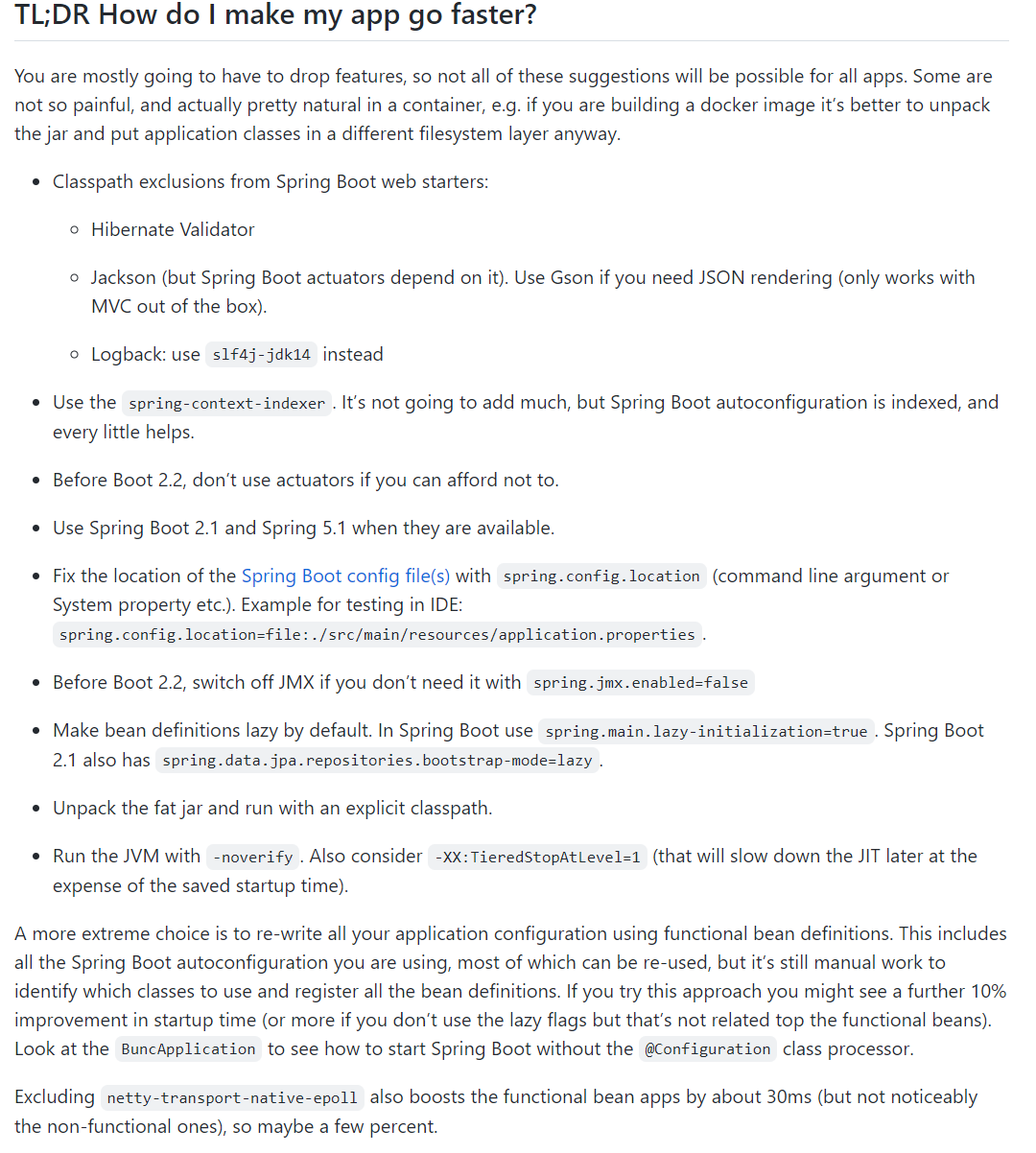
我按照自己的理解翻譯一下。
首先,如果你要採用下面的方法,你就要放棄一些功能,所以不是所有的建議都能適用於所有的應用程式。
從 Spring Boot web starters 中排除下面這些 Classpath:Hibernate Validator;Jackson(但Spring Boot actuators 依賴於它)。如果你需要JSON渲染,請使用 Gson;Logback:使用slf4j-jdk14代替 使用 spring-context-indexer,它不會有很大的幫助,但是有一點點,算一點點。 如果可以,別使用 actuators。 使用 Spring Boot 2.1 和Spring 5.1 版本。當 2.2 和 5.2 可用時,升級到 2.2 和 5.2 版本 用 spring.config.location(命令列引數或 System 屬性等)固定 Spring Boot 組態檔的位置。 如果你不需要 JMX,就用 spring.jmx.enabled=false 來關閉它(這是 Spring Boot 2.2 的預設值)。 把 Bean 設定為 lazy,也就是懶載入。在 Spring Boot 2.2 中有一個設定項 spring.main.lazy-initialization=true 可以用。 解壓 fat jar 並以明確的 classpath 執行。 用 -noverify 執行JVM。也可以考慮 -XX:TieredStopAtLevel=1 。目的是關閉分層編譯。
至於每個點背後的原因,答案就藏在前面說到的 issue 裡面,感興趣,自己去翻,我就是指個路,就不細說了,有興趣自己去翻一翻。
好了,就到這裡啦,歡迎大家關注公眾號「why技術」,文章全網首發。