.NET效能系列文章二:Newtonsoft.Json vs. System.Text.Json
微軟終於追上了?

圖片來自 Glenn Carstens-Peters Unsplash
歡迎來到.NET效能系列的另一章。這個系列的特點是對.NET世界中許多不同的主題進行研究、基準和比較。正如標題所說的那樣,重點在於使用最新的.NET7的效能。你將看到哪種方法是實現特定主題的最快方法,以及大量的技巧和竅門,你如何能以較低的努力最大化你的程式碼效能。如果你對這些主題感興趣,請繼續關注
在這篇文章中,我們將比較兩個最突出的.NET的json框架。:
Newtonsofts Json.NET 和 Microsofts System.Text.Json.
Newtonsoft.Json是NuGet上下載量最大的軟體包,下載量超過23億。System.Text.Json稍稍落後,大約有6億次下載。然而,我們需要考慮的是,System.Text.Json自.NET Core 3.1起就預設隨.NET SDK交付。既然如此,Newtonsoft似乎仍然是最受歡迎的json框架。讓我們來看看,它是否能保持它的名次,或者微軟是否在效能方面緩慢但肯定地領先。
測試方案
為了模擬現實生活中應用的真實場景,我們將測試兩個主要用例。
- 第一,單個巨量資料集的序列化和反序列化。
- 第二是許多小資料集的序列化和反序列化。
一個真實的場景也需要真實的資料。對於測試資料集,我決定使用NuGet包Bogus。通過Bogus,我能夠快速生成許多不同的使用者,包括個人姓名、電子郵件、ID等。
[Params(10000)]
public int Count { get; set; }
private List<User> testUsers;
[GlobalSetup]
public void GlobalSetup()
{
var faker = new Faker<User>()
.CustomInstantiator(f => new User(
Guid.NewGuid(),
f.Name.FirstName(),
f.Name.LastName(),
f.Name.FullName(),
f.Internet.UserName(f.Name.FirstName(), f.Name.LastName()),
f.Internet.Email(f.Name.FirstName(), f.Name.LastName())
));
testUsers = faker.Generate(Count);
}
對於基準,我們將使用每個軟體包的最新版本,目前是(2022年10月):
- Newtonsoft.Json — 13.0.1 and
- System.Text.Json — 7.0.0-rc.2
序列化測試
序列化大物件
為了測試一個大物件的序列化,我們簡單地使用List<User>,我們在GlobalSetup()方法中設定了它。我們的基準方法看起來像這樣:
[Benchmark(Baseline = true)]
public void NewtonsoftSerializeBigData() =>
_ = Newtonsoft.Json.JsonConvert.SerializeObject(testUsers);
[Benchmark]
public void MicrosoftSerializeBigData() =>
_ = System.Text.Json.JsonSerializer.Serialize(testUsers);
這些方法都使用預設的ContractResolver,它只被範例化一次,因此是兩個框架中效能最好的序列化選項。如果你使用自定義的JsonSerializerSettings,注意不要多次範例化ContractResolver,否則你會降低很多效能。
現在我們來看看結果:
| Method | Count | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| NewtonsoftSerializeBigData | 10000 | 7.609 ms | 1.00 | 8.09 MB | 1.00 |
| MicrosoftSerializeBigData | 10000 | 3.712 ms | 0.49 | 3.42 MB | 0.42 |

儘管Newtonsoft在他們的第一個檔案網站上說。
高效能:比.NET的內建JSON序列化器快
我們可以清楚地看到,到目前為止,他們並不比內建的JSON序列化器快。至少在這個用例中是這樣。讓我們來看看,在其他使用情況下是否也是如此。
序列化許多小物件
這個用例在實際應用中比較常見,例如在REST-Apis中,每個網路請求都必須處理JSON序列化資料,並且也要用JSON序列化資料進行響應。
為了實現這個用例,我們使用之前建立的List<User>,並簡單地迴圈通過它,同時單獨序列化每個使用者。
[Benchmark(Baseline = true)]
public void NewtonsoftSerializeMuchData()
{
foreach (var user in testUsers)
{
_ = Newtonsoft.Json.JsonConvert.SerializeObject(user);
}
}
[Benchmark]
public void MicrosoftSerializeMuchData()
{
foreach (var user in testUsers)
{
_ = System.Text.Json.JsonSerializer.Serialize(user);
}
}
在我的機器上,這個基準測試導致了以下結果:
| Method | Count | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| NewtonsoftSerializeMuchData | 10000 | 8.087 ms | 1.00 | 17.14 MB | 1.00 |
| MicrosoftSerializeMuchData | 10000 | 3.944 ms | 0.49 | 3.64 MB | 0.21 |

我們可以看到對於許多小物件來說,效能又快了近100%。不僅System.Text.Json的效能比Newtonsoft快了一倍,而且堆分配的記憶體甚至少了5倍! 正如我在以前的文章中提到的,節省堆記憶體甚至比速度更重要,你在這裡看到了。堆記憶體最終將不得不被垃圾回收,這將阻塞你的整個應用程式的執行。
反序列化測試
在現實世界的應用中,你不僅要序列化,還要從JSON序列化的字串中反序列化物件。在下面的基準中,我們將再次使用Bogus,建立一組使用者,但這次我們要把它們序列化為一個大的字串,用於巨量資料物件,並把許多小資料物件序列化為List<string>。
private string serializedTestUsers;
private List<string> serializedTestUsersList = new();
[GlobalSetup]
public void GlobalSetup()
{
var faker = new Faker<User>()
.CustomInstantiator(f => new User(
Guid.NewGuid(),
f.Name.FirstName(),
f.Name.LastName(),
f.Name.FullName(),
f.Internet.UserName(f.Name.FirstName(), f.Name.LastName()),
f.Internet.Email(f.Name.FirstName(), f.Name.LastName())
));
var testUsers = faker.Generate(Count);
serializedTestUsers = JsonSerializer.Serialize(testUsers);
foreach (var user in testUsers.Select(u => JsonSerializer.Serialize(u)))
{
serializedTestUsersList.Add(user);
}
}
反序列化大物件
第一個反序列化基準將一個大的JSON字串反序列化為相應的.NET物件。在這種情況下,它又是List<User>,我們在前面的例子中也使用了它。
[Benchmark(Baseline = true)]
public void NewtonsoftDeserializeBigData() =>
_ = Newtonsoft.Json.JsonConvert.DeserializeObject<List<User>>(serializedTestUsers);
[Benchmark]
public void MicrosoftDeserializeBigData() =>
_ = System.Text.Json.JsonSerializer.Deserialize<List<User>>(serializedTestUsers);
在我的機器上執行這些基準測試,得出以下結果:
| Method | Count | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| NewtonsoftDeserializeBigData | 10000 | 21.20 ms | 1.00 | 10.55 MB | 1.00 |
| MicrosoftDeserializeBigData | 10000 | 12.12 ms | 0.57 | 6.17 MB | 0.59 |

就效能而言,微軟仍然遠遠領先於Newtonsoft。然而,我們可以看到,Newtonsoft並沒有慢一半,而是慢了40%左右,這在與序列化基準的直接比較中是一個進步。
反序列化許多小物件
本章的最後一個基準是許多小物件的反序列化。在這裡,我們使用我們在上面的GlobalSetup()方法中初始化的List<string>,在一個迴圈中反序列化資料物件:
[Benchmark(Baseline = true)]
public void NewtonsoftDeserializeMuchData()
{
foreach (var user in serializedTestUsersList)
{
_ = Newtonsoft.Json.JsonConvert.DeserializeObject<User>(user);
}
}
[Benchmark]
public void MicrosoftDeserializeMuchData()
{
foreach (var user in serializedTestUsersList)
{
_ = System.Text.Json.JsonSerializer.Deserialize<User>(user);
}
}
其結果甚至比相關的序列化基準更令人吃驚:
| Method | Count | Mean | Ratio | Allocated | Alloc Ratio |
|---|---|---|---|---|---|
| NewtonsoftDeserializeMuchData | 10000 | 15.577 ms | 1.00 | 35.54 MB | 1.00 |
| MicrosoftDeserializeMuchData | 10000 | 7.916 ms | 0.51 | 4.8 MB | 0.14 |
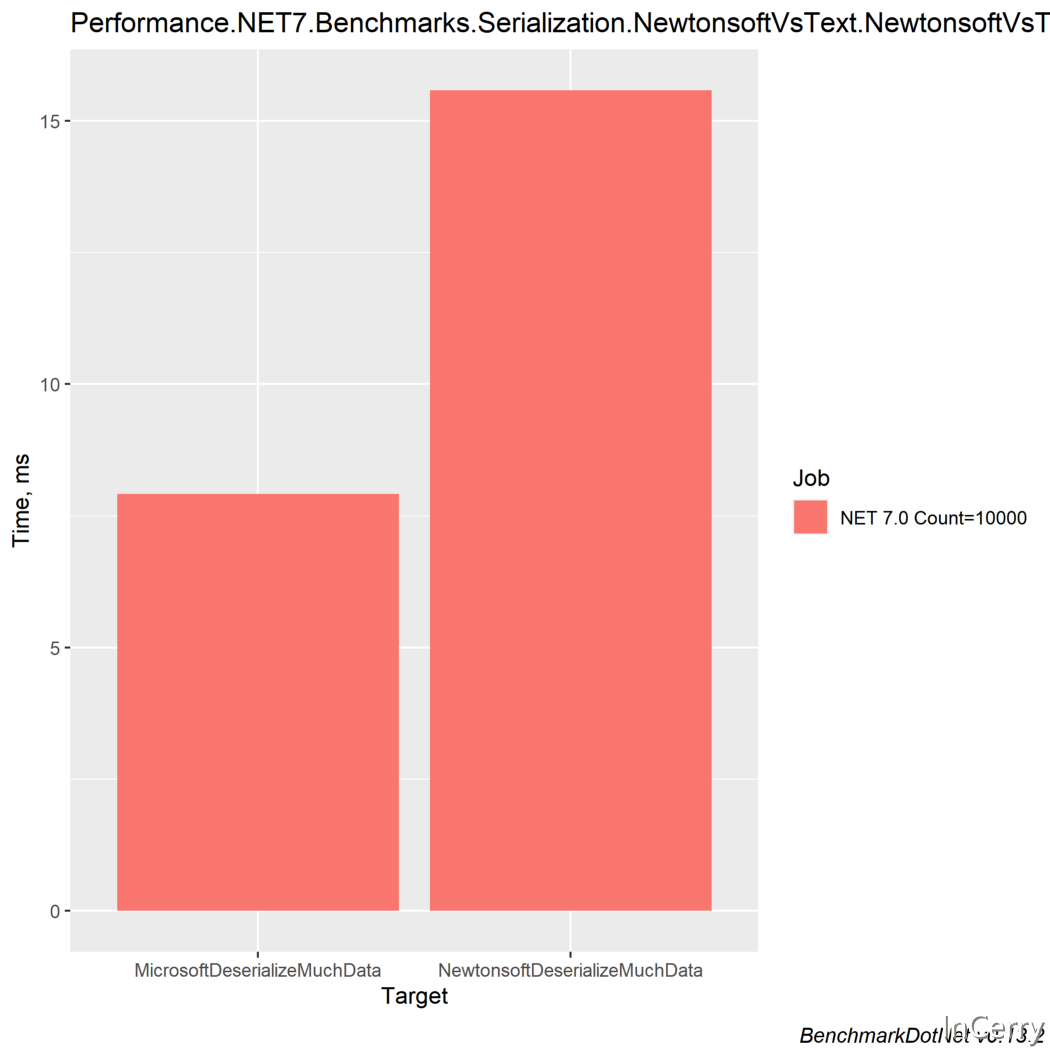
在Microsofts框架下,速度又快了一倍,記憶體效率是驚人的7倍,比Newtonsoft還要好!
總結
儘管Newtonsoft在他們的檔案上說:
高效能:比.NET的內建JSON序列化器更快
很明顯,至少從.NET 7開始,Microsofts的System.Text.Json在所有測試的用例中至少快了一倍,命名為。
- 序列化一個巨量資料集
- 序列化許多小資料集
- 對一個巨量資料集進行反序列化
- 對許多小資料集進行反序列化
所有這些都是在每個框架的預設序列化器設定下進行的。
不僅速度快了100%,而且在某些情況下,分配的記憶體甚至比Newtonsoft的效率高5倍以上。
我甚至認為,可以推斷出結果,目前使用System.Text.Json比Newtonsoft.Json更快。
請記住,這些結果只對最新的.NET 7有效。如果你使用的是其他版本的.NET,情況可能正好相反,Newtonsoft可能會更快。
我希望,我的文章可以幫助你對序列化器做出選擇選擇,並讓你對效能和基準測試的世界有一個有趣的切入點。
如果你喜歡這個系列的文章,請一定要關注我,因為還有很多有趣的話題等著你。
謝謝你的閱讀!
版權
原文版權:Tobias Streng
翻譯版權:InCerry
原文連結:https://medium.com/@tobias.streng/net-performance-series-2-newtonsoft-vs-system-text-json-2bf43e037db0