Mysql InnoDB Buffer Pool
參考書籍《mysql是怎樣執行的》
一丶為什麼需要Buffer Pool
對於InnoDB儲存引擎的表來說,無論是用於儲存使用者資料的索引,還是各種系統資料,都是以頁的形式存放在表空間中,歸根結底還是儲存在磁碟上。因此InnoDB儲存引擎處理使用者端的請求是,如果需要存取某個頁的資料,需要把完整的頁資料載入到記憶體中,即便是隻需要一條資料,也需要把整個頁的資料載入到記憶體後進行讀寫存取。如果在讀寫頁後將其快取在記憶體中,便可以減少這種磁碟IO提高mysql效能。
二丶InnoDB Buffer Pool及其內部組成
InnoDB 會在mysql伺服器起到是就向作業系統申請一塊連續的記憶體,(innodb_buffer_pool_size可以控制大小,單位位元組)用來對InnoDB的頁做快取操作。
Buffer Pool對應一片連續的記憶體被劃分為若干個頁面,頁面的大小和InnoDB頁面大小一致(16kb)每一個buffer pool 頁都對應一些控制資訊(表空間編號,頁號等)這些控制資訊被抽象為控制塊(後文我們把buffer pool的頁稱為緩衝頁,和表空間中頁做區分)
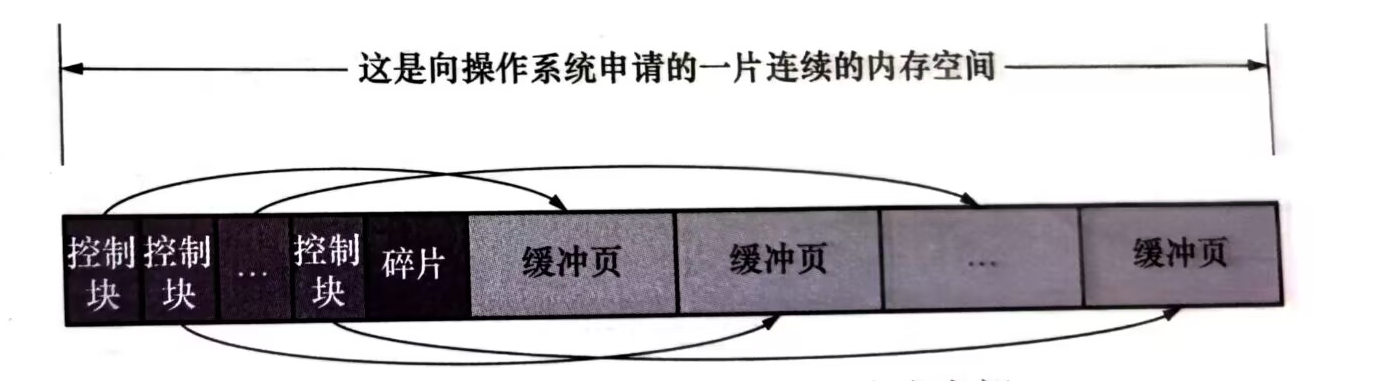
三丶空閒緩衝頁管理——free 連結串列
從磁碟上讀取一個頁到buffer pool中時,應該把這個頁快取到哪兒暱。buffer pool的做法時將空閒的緩衝頁對應的控制塊作為一個節點放在連結串列中,這個連結串列稱作free連結串列。
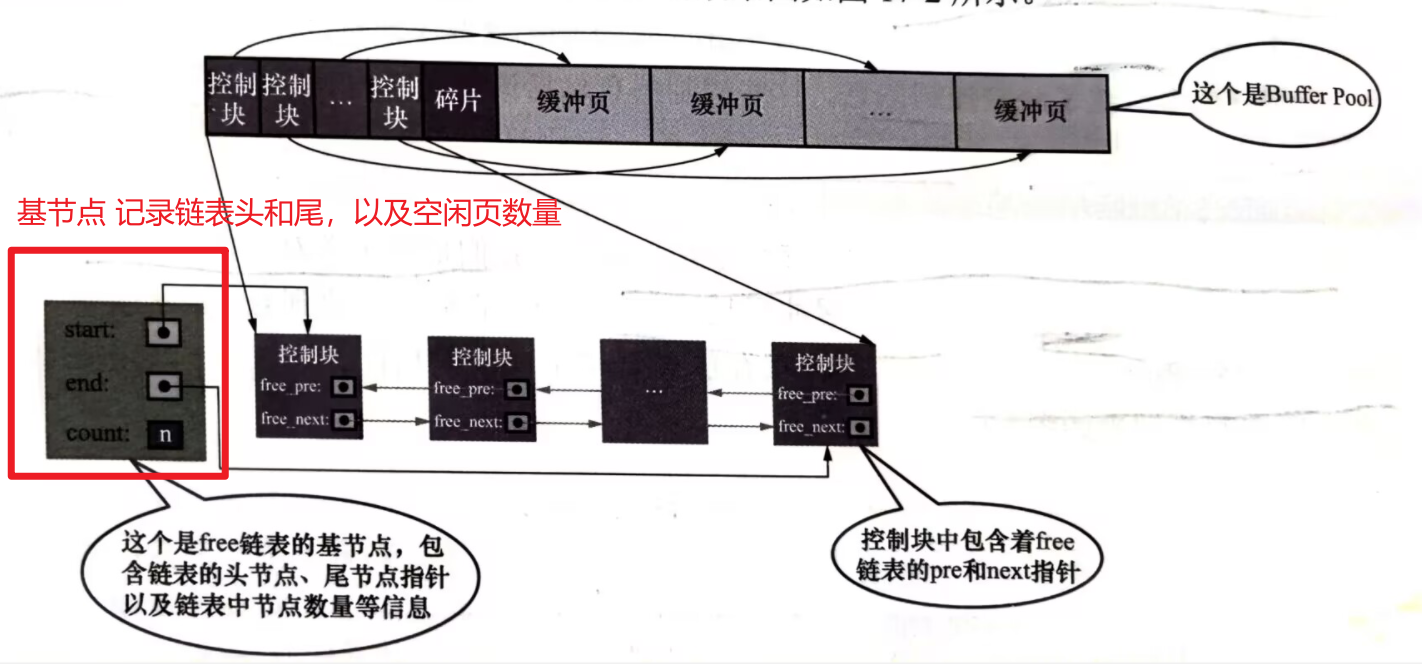
其中有一個基節點負責記錄連結串列的頭和尾,每一個空閒的頁都將在free 連結串列中串聯起來,每當innodb需要快取一個頁的時候,就通過基節點獲取一個空閒的buffer pool 緩衝頁,然後在這個緩衝頁中記錄下表空間,頁號之類的資訊。然後把緩衝頁對應的free連結串列節點移除。
在快取一個頁的時候,還需要判斷當前頁是否已經被快取,innodb 對已經快取的頁,根據其表空間和頁號兩個值作為hash的key,建立hash表,這樣可以很快的進行判斷。
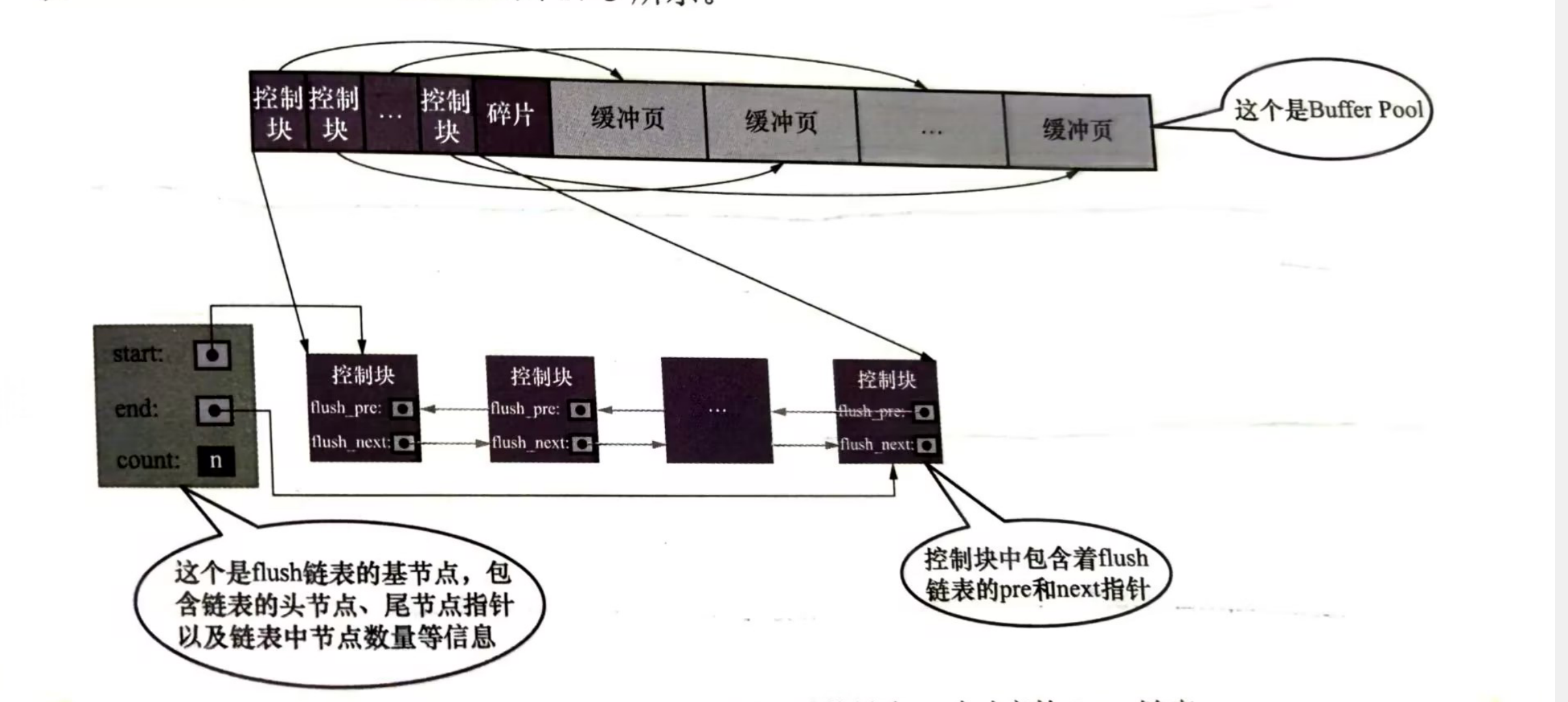
四丶緩衝頁刷盤——flush連結串列
當innodb修改一個磁碟上的頁並快取到buffer pool中,這時候記憶體中快取的資料和磁碟就不一致這種頁稱為髒頁。如果每次執行完修改都立馬將資料重新整理到磁碟中的頁會影響到程式的效能,所以innodb不會立馬重新整理到磁碟,而是使用flush連結串列將髒頁對應的控制塊串聯起來
五丶緩衝空間不夠怎麼辦——LRU連結串列管理
1.簡單的LRU連結串列
buffer pool的大小畢竟是有限的,當free 連結串列中不存在更多空閒的緩衝頁了,這時候就需要採取一些淘汰策略對一些無用的緩衝頁進行淘汰。
這裡就是涉及到兩個問題:什麼樣的緩衝頁是無用的,如何維護這些緩衝頁來實現此淘汰策略。這時候自然是使用LRU演演算法(最近最少使用)淘汰最近最少使用到緩衝頁。LRU演演算法使用一個連結串列來實現,當innodb存取某個頁的時候:
- 如果該頁不在buffer pool中,那麼把該頁從磁碟載入到buffer pool中的緩衝頁是,就把該頁的控制塊放在LRU連結串列的頭部
- 如果該頁已經在buffer pool中,那麼移動節點到LRU連結串列頭部
這樣可以實現,被使用到緩衝頁,會盡量靠近LRU連結串列的頭部,自然而然尾部便是最近最少使用到的資料。LRU演演算法基於——最近使用到的資料,後續也會到使用到的思想,使用LRU可以提高Buffer pool快取的命中率。
2.簡單LRU連結串列無法解決的問題
-
預讀
innodb認為在執行當前請求的時候,後續可能會讀取某些頁面的時候,會把這些頁面也載入到buffer pool
-
線性預讀
如果順序存取某個區的頁面超過
innodb_read_ahead_threshold的值,那麼會觸發一次線性預讀,非同步的讀取下一個區中全部的頁面到buffer pool中。 -
隨機預讀
如果某個區的13個連續的也都被載入到buffer pool中,無論是否是順序讀取的頁面,都會非同步讀取本區中所有的其他頁面到buffer pool中,
innodb_random_read_ahead設定為on可以開啟隨機預讀
預讀的目的是提高語句的執行效率,相當於innodb 認為你會用到,非同步的幫你載入到快取中,後續不需要繼續讀磁碟。但是在LRU的管理中,如果預讀的頁面很多沒用用到的話,還將預讀的頁面放在連結串列頭部,後續淘汰的頁面反而是需要用到的,會極大的降低快取命中率。
預讀導致載入到buffer pool中頁的不一定會使用到 -
-
全表掃描語句
當一個sql沒有合適的索引或者沒用where限定條件的時候,innodb會掃描該表聚集索引所有的頁。如果頁非常多,buffer pool無法容納的時候,就會把其他有用的緩衝頁進行淘汰,降低快取命中率。
全表掃描導致許多使用頻率低的頁被同時載入到buffer pool中,導致使用頻率高的頁從buffer pool中被移除(這裡可以看出LFU演演算法的好處,哈哈哈)
3.innodb 如何解決預讀和全表掃描導致快取命中率降低的問題
innodb 根據一定比例將LRU連結串列分為兩部分:
- 熱資料區:使用頻率很高的緩衝頁構成,稱為young區
- 冷資料區:使用頻率不是很高的快取頁構成,稱為old區
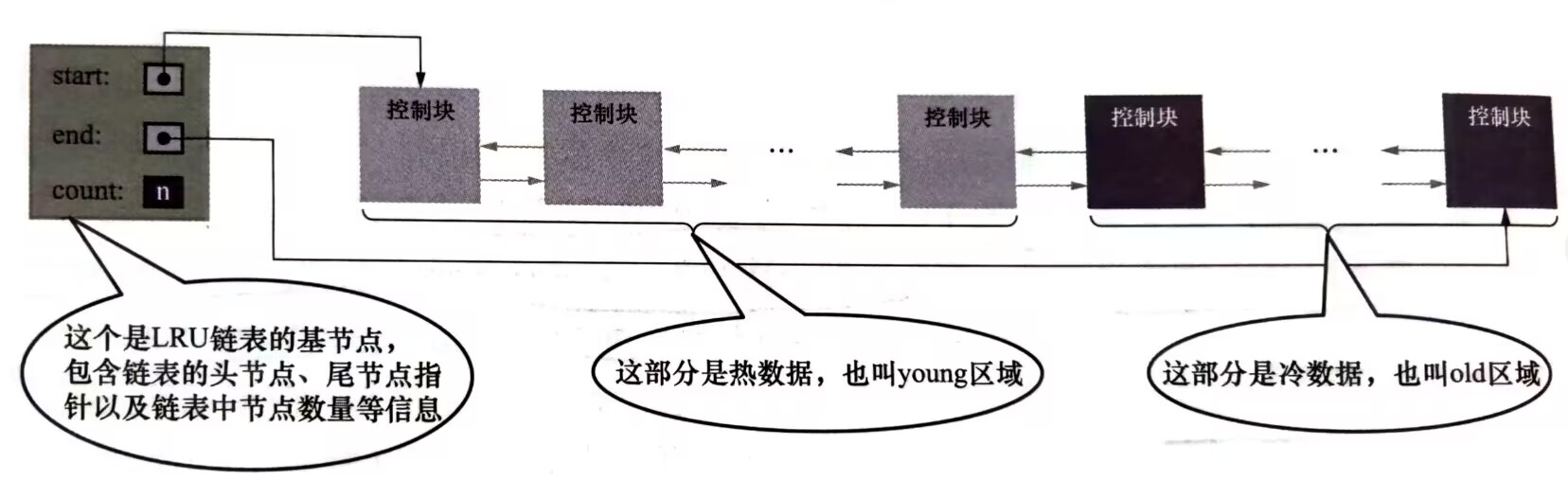
innodb_old_bolocks_pet可以設定old區佔用的比列,預設是37%
3.1解決預讀頁面後續也許使用不到的問題
innodb規定當磁碟某個頁面在初次載入到buffer pool中某個緩衝頁時,該緩衝頁對應的控制塊會放在old區域的頭部,這樣預讀到的且後續如果不進行後續存取的頁面會逐漸從old區移除,而不影響young區使用頻率高的緩衝頁。
3.2解決全表掃描短時間存取大量使用頻率低頁面的問題
在進行全表掃描時,雖然首次存取放在old區頭部,但是後續會馬上被存取到,這時候會把該頁放在young區域的頭部,這樣依舊會影響到使用頻率高的頁面。
為了解決這個問題,innodb規定對於某個處於old區的緩衝頁第一次存取時,就在其控制塊中記錄下存取時間,如果後續存取的時間和第一次存取的時間,在某個時間存取間隔內(innodb_old_blocks_time可以進行設定)那麼頁面不會從old區移動到young區,反之移動到young區中。這個時間間隔預設時1000ms,基本上多次存取同一個頁面中的多個記錄的時間不會超過1s。
3.3 優化每次都需要移動young區節點到LRU連結串列頭部的問題
如果每次存取一個緩衝頁都需要移動到LRU連結串列的頭部,像young區中這種熱點資料,每次都需要更新連結串列頭部,並且這還是一個高並行操作,需要CAS或者鎖,開銷也不小。為了解決這個問題 innodb規定只有被存取的緩衝頁位於young區的前1/4範圍外,才會進行移動,所以前1/4的高熱度的資料,不會頻繁移動
六丶髒頁刷盤
innodb後臺有專門的執行緒負責將髒頁重新整理到磁碟
-
從LRU連結串列中的冷資料重新整理一部分頁面到磁碟
後臺執行緒定時從LRU連結串列尾部掃描一些頁面,掃描的頁面數量可以通過
innodb_lru_scan_depth指定,如果在LRU中發現髒頁,那麼重新整理到磁碟 -
從flush連結串列重新整理一部分頁面到磁碟
後臺執行緒也會定時從flush連結串列中重新整理一部分頁面到磁碟,重新整理速率取決於系統是否繁忙
如果後臺執行緒重新整理的很慢,且有新的頁面需要進行快取,這時候會從LRU連結串列尾部看看是否有可以直接釋放的非髒頁,如果不存在那麼需要刷盤然後快取新的頁。
這裡我們可以看到buffer pool沒用保證修改的資料一定被磁碟持有化,那麼事務的永續性如何實現暱,怎麼保證mysql服務突然掛了,已經提交的事務不會丟失暱,這就得提到redo log了
七丶多個buffer pool範例
在並行量比較大的時候,多個執行緒操作同一個buffer pool,必然涉及到同步機制,影響到請求的處理速度,所以在buffer pool比較大的時候,會被拆分成多個小的buffer pool,獨立進行使用,在高並行的時候不會相互影響(雖然也不能公用彼此的快取內容)提高並行處理能力。只有在innodb_buffer_pool_size設定的buffer pool大小大於1g的時候,通過innodb_buffer_pool_instances設定的buffer pool範例個數才會生效
八丶動態的擴大縮小buffer pool
為了能夠在執行的時候動態的擴大縮小buffer pool,innodb提出chunk的概念,innodb 不在一次申請為某一個buffer pool申請一大片連續的記憶體空間,而是以chunk作為單位進行申請。一個chunk就是一個連續的記憶體空間,其內部包含了若干緩衝頁和其對應的控制塊。
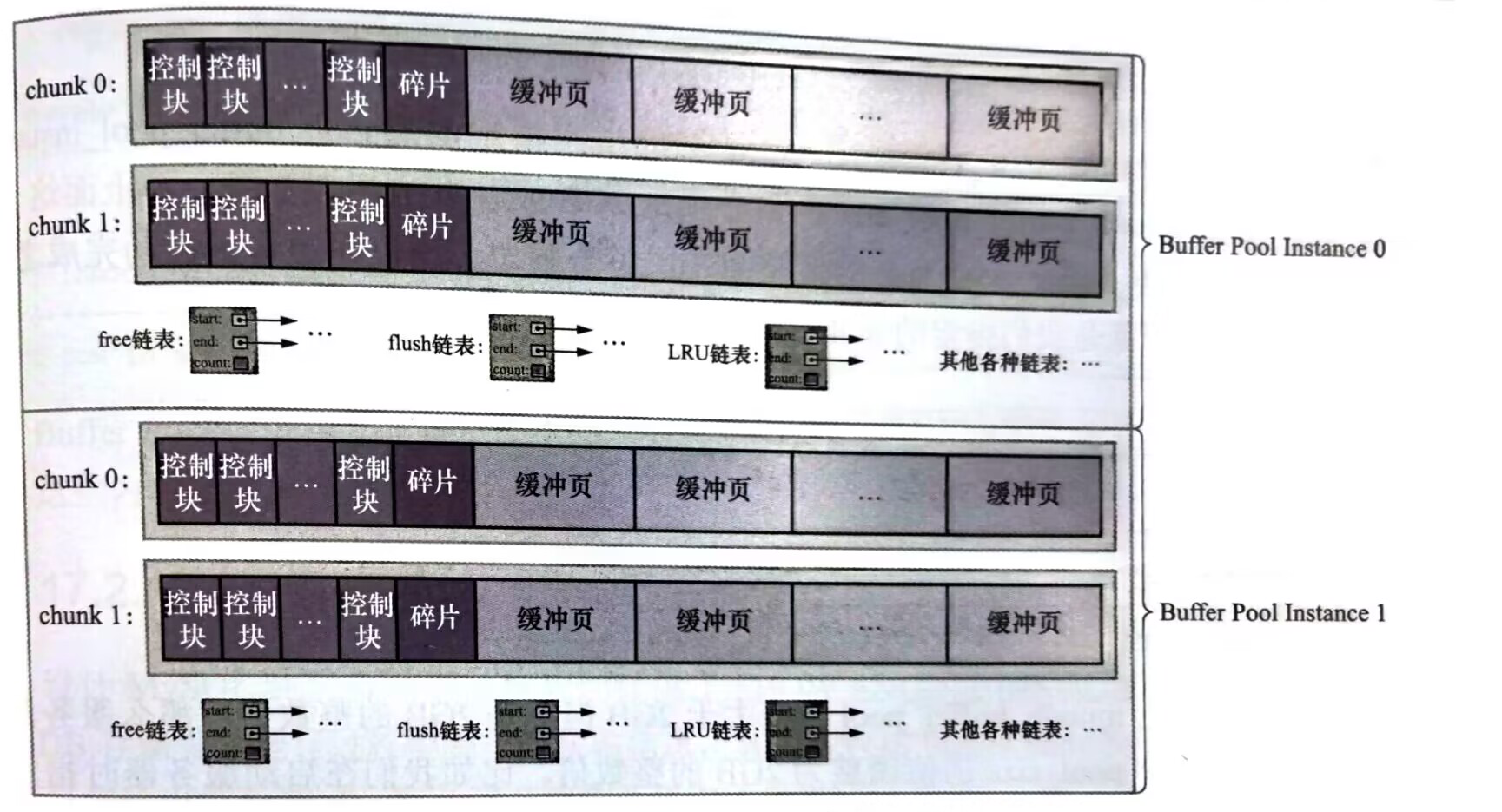
可以通過innodb_buffer_pool_chunk_size設定每一個chunk的大小,預設時128mb。
所以我們最好讓innodb_buffer_pool_size = innodb_buffer_pool_chunk_size x innodb_buffer_pool_instances的若干倍保證每一個buffer pool範例中chunk數相同,如果innodb_buffer_pool_chunk_size x innodb_buffer_pool_instances大於innodb_buffer_pool_size ,innodb_buffer_pool_chunk_size 會自動被調整為innodb_buffer_pool_size / innodb_buffer_pool_instances的大小