OpenMP 入門
OpenMP 入門
簡介
OpenMP 一個非常易用的共用記憶體的並行程式設計框架,它提供了一些非常簡單易用的API,讓程式設計人員從複雜的並行程式設計當中釋放出來,專注於具體功能的實現。openmp 主要是通過編譯指導語句以及他的動態執行時庫實現,在本篇文章當中我們主要介紹 openmp 一些入門的簡單指令的使用。
認識 openmp 的簡單易用性
比如現在我們有一個任務,啟動四個執行緒列印 hello world,我們看看下面 C 使用 pthread 的實現以及 C++ 使用標準庫的實現,並對比他們和 openmp 的實現複雜性。
C 語言實現
#include <stdio.h>
#include <pthread.h>
void* func(void* args) {
printf("hello world from tid = %ld\n", pthread_self());
return NULL;
}
int main() {
pthread_t threads[4];
for(int i = 0; i < 4; i++) {
pthread_create(&threads[i], NULL, func, NULL);
}
for(int i = 0; i < 4; i++) {
pthread_join(threads[i], NULL);
}
return 0;
}
上面檔案編譯命令:gcc 檔名 -lpthread 。
C++ 實現
#include <thread>
#include <iostream>
void* func() {
printf("hello world from %ld\n", std::this_thread::get_id());
return 0;
}
int main() {
std::thread threads[4];
for(auto &t : threads) {
t = std::thread(func);
}
for(auto &t : threads) {
t.join();
}
return EXIT_SUCCESS;
}
上面檔案編譯命令:g++ 檔名 lpthread 。
OpenMP 實現
#include <stdio.h>
#include <omp.h>
int main() {
// #pragma 表示這是編譯指導語句 表示編譯器需要對下面的並行域進行特殊處理 omp parallel 表示下面的程式碼區域 {} 是一個並行域 num_threads(4) 表示一共有 4 個執行緒執行 {} 內的程式碼 因此實現的效果和上面的效果是一致的
#pragma omp parallel num_threads(4)
{
printf("hello world from tid = %d\n", omp_get_thread_num()); // omp_get_thread_num 表示得到執行緒的執行緒 id
}
return 0;
}
上面檔案編譯命令:gcc 檔名 -fopenmp ,如果你使用了 openmp 的編譯指導語句的話需要在編譯選項上加上 -fopenmp。
從上面的程式碼來看,確實 openmp 寫並行程式的複雜度確實比 pthread 和 C++ 低。openmp 相比起其他構建並行程式的方式來說,使用 openmp 你可以更加關注具體的業務實現,而不用太關心並行程式背後的啟動與結束的過程,OenpMP 會幫我們實現很多細節,讓程式的執行符合我們的直覺。
opnemp 基本原理
在上文當中我們寫了一個非常簡單的 openmp 程式,使用 4 個不同的執行緒分別列印 hello world 。我們仔細分析一下這個程式的執行流程:

在 openmp 的程式當中,你可以將程式用一個個的並行域分開,在並行域(parallel region)中,程式是有並行的,但是在並行域之外是沒有並行的,只有主執行緒(master)在執行,整個過程如下圖所示:

現在我們用一個程式去驗證上面的過程:
#include <stdio.h>
#include <omp.h>
#include <unistd.h>
int main() {
#pragma omp parallel num_threads(4)
{
printf("parallel region 1 thread id = %d\n", omp_get_thread_num());
sleep(1);
}
printf("after parallel region 1 thread id = %d\n", omp_get_thread_num());
#pragma omp parallel num_threads(4)
{
printf("parallel region 2 thread id = %d\n", omp_get_thread_num());
sleep(1);
}
printf("after parallel region 2 thread id = %d\n", omp_get_thread_num());
#pragma omp parallel num_threads(4)
{
printf("parallel region 3 thread id = %d\n", omp_get_thread_num());
sleep(1);
}
printf("after parallel region 3 thread id = %d\n", omp_get_thread_num());
return 0;
}
程式執行之後的一種輸出(還有很多其他的輸出形式,因為是多執行緒程式,執行緒的輸出是不確定的)如下所示:
parallel region 1 thread id = 0
parallel region 1 thread id = 3
parallel region 1 thread id = 1
parallel region 1 thread id = 2
after parallel region 1 thread id = 0
parallel region 2 thread id = 0
parallel region 2 thread id = 2
parallel region 2 thread id = 3
parallel region 2 thread id = 1
after parallel region 2 thread id = 0
parallel region 3 thread id = 0
parallel region 3 thread id = 1
parallel region 3 thread id = 3
parallel region 3 thread id = 2
after parallel region 3 thread id = 0
從上面的輸出我們可以瞭解到,id = 0 的執行緒就是主執行緒,在並行域內部程式的輸出是沒有順序的,但是在並行域的外部是有序的,在並行域的開始部分程式會進行並行操作,但是在並行域的最後會有一個隱藏的同步點,等待所有執行緒到達這個同步點之後程式才會繼續執行,現在再看上文當中 openmp 的執行流圖的話就很清晰易懂了。
積分例子
現在我們使用一個簡單的函數積分的例子去具體瞭解 openmp 在具體的使用場景下的並行。比如我們求函數 \(x^2\) 的積分。

比如我們現在需要 x = 10 時,\(x^2\) 的積分結果。我們在程式裡面使用微元法去計算函數的微分結果,而不是直接使用公式進行計算,微元法對應的計算方式如下所示:
微元法的本質就是將曲線下方的面積分割成一個一個的非常小的長方形,然後將所有的長方形的面積累加起來,這樣得到最終的結果。
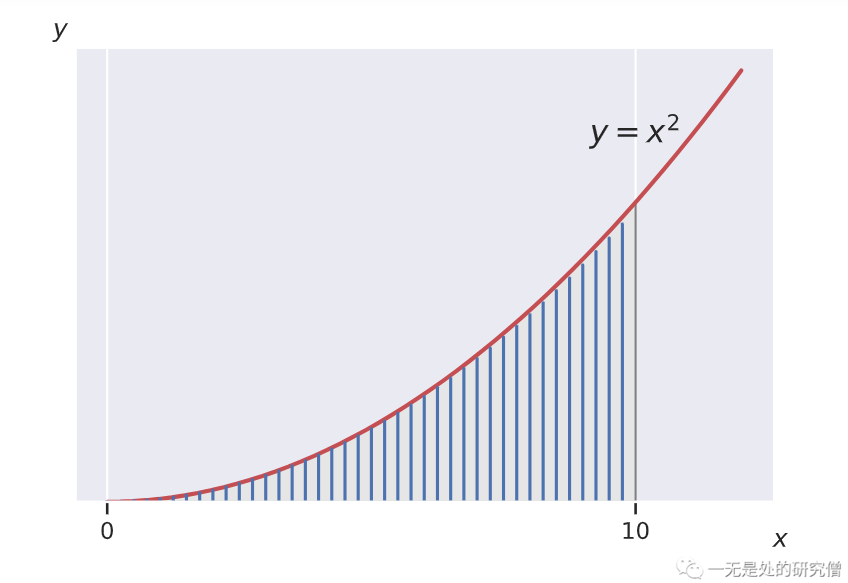
如果你不懂上面所談到的求解方法也沒關係,只需要知道我們需要使用 openmp 去計算一個計算量比較大的任務即可。根據上面微元法的公式我們有一個非常大的求和公式,如果是在單執行緒的情況下我們使用一個迴圈就可以了,但是現在我們有多個執行緒,那麼我們可以讓每個執行緒求某一個區間的和,最後將各個區間的和加起來得到最終的結果,這就是在並行場景下的實現思路。
openmp 具體的實現程式碼如下所示:
#include <stdio.h>
#include <omp.h>
#include <math.h>
/// @brief 計算 x^2 一部分的面積
/// @param start 執行緒開始計算的位置
/// @param end 執行緒結束計算的位置
/// @param delta 長方形的邊長
/// @return 計算出來的面積
double x_square_partial_integral(double start, double end, double delta) {
double s = 0;
for(double i = start; i < end; i += delta) {
s += pow(i, 2) * delta;
}
return s;
}
int main() {
int s = 0;
int e = 10;
double sum = 0;
#pragma omp parallel num_threads(32) reduction(+:sum)
{
// 根據執行緒號進行計算區間的分配
// omp_get_thread_num() 返回的執行緒 id 從 0 開始計數 :0, 1, 2, 3, 4, ..., 31
double start = (double)(e - s) / 32 * omp_get_thread_num();
double end = (double)(e - s) / 32 * (omp_get_thread_num() + 1);
sum = x_square_partial_integral(start, end, 0.0000001);
}
printf("sum = %lf\n", sum);
return 0;
}
在上面的程式碼當中 #pragma omp parallel num_threads(4) 表示啟動 4 個執行緒執行 {} 中的程式碼,reduction(+:sum) 表示需要對 sum 這個變數進行一個規約操作,當 openmp 中的執行緒遇到 reduction 子句的時候首先會拷貝一份 sum 作為本地變數,然後在並行域當中使用的就是每一個執行緒的本地變數,因為有 reduction 的規約操作,因此在每個執行緒計算完成之後還需要將每個執行緒本地計算出來的值對操作符 + 進行規約操作,也就是將每個執行緒計算得到的結果求和,最終將得到的結果賦值給我們在 main 函數當中定義的變數 sum 。最終我們列印的變數 sum 就是各個執行緒求和之後的結果。上面的程式碼執行過程大致如下圖所示:
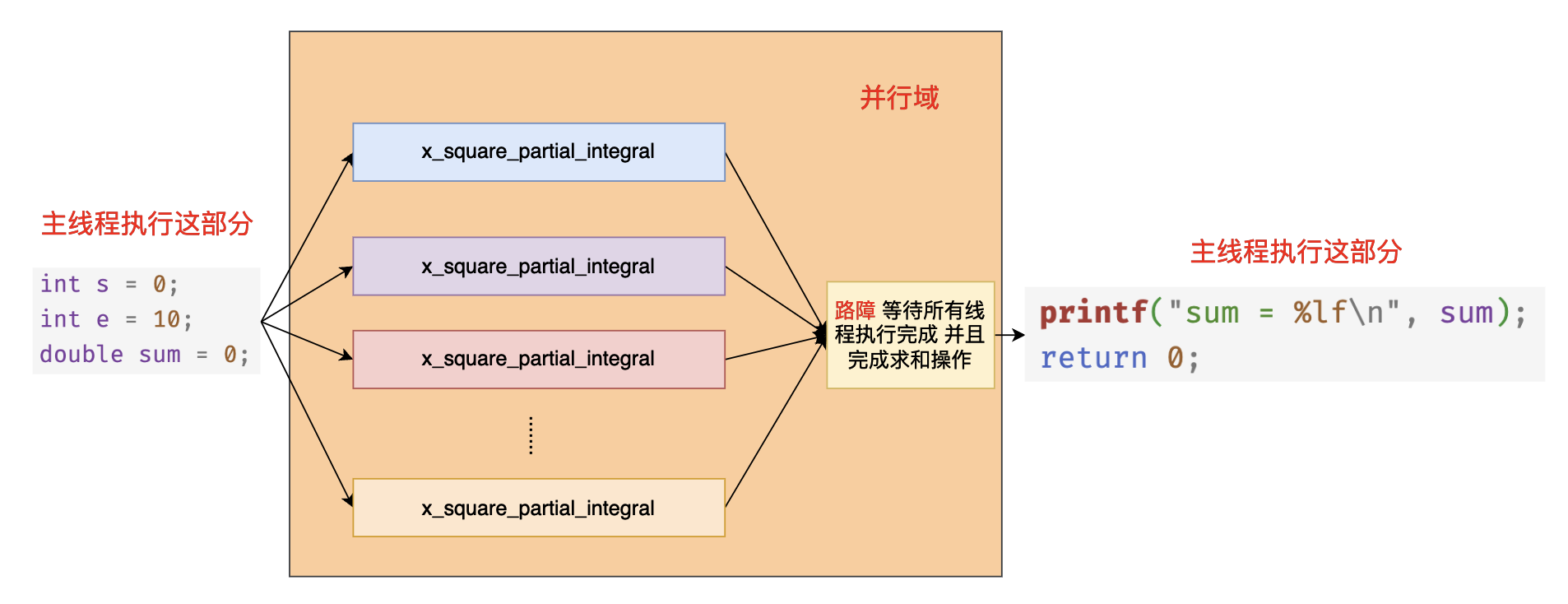
注意事項:你在編譯上述程式的時候需要加上編譯選項 -fopenmp 啟動openmp 編譯選項和 -lm 連結數學庫。
上面程式的執行結果如下所示:

總結
在本篇文章當中主要給大家介紹了 OpenMP 的基本使用和程式執行的基本原理,在後續的文章當中我們將仔細介紹各種 OpenMP 的子句和指令的使用方法,希望大家有所收穫!
更多精彩內容合集可存取專案:https://github.com/Chang-LeHung/CSCore
關注公眾號:一無是處的研究僧,瞭解更多計算機(Java、Python、計算機系統基礎、演演算法與資料結構)知識。