淺談長連線負載均衡
hello,大家好,我是小樓,終於忙完了一陣,今天來更新一篇長連線的負載均衡問題。
首先說明下,長連線我不是專業的,只是在工作上有一點點的接觸,分享也是基於一點點的經驗和一些思考,如有出入,歡迎私聊。
長連線介紹
說長連線,與之對應的是短連線,關於這兩個的介紹網上比較多,這裡只用一個表格來總結下他們的工作流程、優缺點、適用場景等:
| 短連線 | 長連線 | |
|---|---|---|
| 流程 | 建立連線 -> 傳輸資料 -> 關閉連線 | 建立連線 -> 傳輸資料 -> 傳輸資料 ->... -> 關閉連線 |
| 優點 | 實現簡單 | 耗時(DNS解析、TCP 握、揮手)少;能實現伺服器端推播 |
| 缺點 | 耗時(DNS解析、TCP 握、揮手)多 | 需要管理連線,實現複雜;連線多時伺服器端消耗大 |
| 場景 | 單使用者端不頻繁操作但使用者端數量多;如 Web 服務 | 單使用者端頻繁操作;如資料庫、需要推播能力的服務 |
長連線負載均衡
長連線為什麼需要負載均衡
長連線單機的連線數是存在上限的。
存在上限的原因,可能有同學認為是單機的埠數限制,也就是經常聽到的問題「一臺伺服器最多能支撐多少個 TCP 連線?」
有人回答「65535」,其實不然,如果硬體限制不考慮,單機能撐200多萬億個 TCP 連線,但這太理想,現實是撐個百萬連線還是可以的。具體怎麼回事,可以戳飛哥這篇文章《漫畫 | 一臺Linux伺服器最多能支撐多少個TCP連線?》瞭解詳細。
從經驗來看,CPU 和 記憶體是限制連線數的主要原因。
記憶體不必多說,每個連線的保持都要佔用一點記憶體,一條空連線,也要佔用幾 KB 的記憶體,如果再塞點資料,幾百 KB 到幾 MB 也是常有的事,按一條連線 1MB 算,一臺 128GB 記憶體的物理機能撐十幾萬的連線。
其次是 CPU,我們上面說了長連線的場景一般是單個使用者端操作頻繁,這就會導致每增加一條連線,CPU 消耗就增加一些,一般單機能撐十萬的連線,已經算是可以了。
基於單機效能和高可用容災的考慮,生產環境長連線服務通常會部署多個節點,為此,我們需要考慮長連線服務的負載均衡問題。
長連線負載均衡粒度
與短連線每次請求都做負載均衡策略不同,長連線不光有請求粒度的負載均衡,還有連線粒度的負載均衡。
請求粒度負載均衡的實現方式是一個使用者端與每個伺服器端都建立連線,傳送請求時按照某種負載均衡策略選擇一個伺服器端進行請求;連線粒度的負載均衡則是使用者端在建立連線時按照某種負載均衡策略挑選一個節點進行建連,後續請求都發往這個節點。

如何選擇主要是考量單個伺服器端可能的連線數量,如果連線數遠不是瓶頸的時候(個人認為萬級以下),可考慮請求粒度,否則連線粒度的負載均衡策略更佳。
舉個例子,Dubbo 一個 Provider 節點和來自訂閱 Consumer 的所有節點都建立了連線,前提是 Dubbo 一個 Provider 基本不太會可能被幾萬個節點消費,所以 Dubbo 可以做請求粒度的長連線負載均衡。但如果是 Nacos,所有需要服務發現的機器都要和 Nacos 伺服器端建立連線,長連線數量就和公司伺服器數量級相關,規模大的情況,幾萬、上十萬、百萬也是有可能的,所以如果 Nacos 也像 Dubbo 那樣設計,就無法支撐大規模服務發現了。
連線粒度的負載均衡
對於長連線,連線粒度的負載均衡問題遇到的更多,所以這裡著重說明下。
連線數均衡
由於連線建立之後,除非異常不會斷開,所以問題就來了,如果某一個節點的連線數相比較其他節點要多出很多,這種就屬於不均衡了。出現這種問題的情況最常見的就是伺服器端釋出(重啟)。重啟時服務不可用,該節點原先的連線會斷開,找到存活的節點進行連線,當這臺服務起來時,它的連線數將非常少。如果是一輪發布,最先發布的機器最後連線數最多,最後釋出的連線數最少。
這種情況下,我們可以調整建連的負載均衡演演算法為最小連線數模式,當服務重啟完成後,後續的連線就能全部連線到此節點。
但這個方法並不總是奏效,因為服務在重啟時,斷開的連線已經和其他節點建立了連線。
這時我們可能需要額外的均衡手段,如定時從全域性視角看各個節點的連線數是否均衡,如果不均衡則要斷開最多連線的節點,直到平衡。
這裡我們的使用者端需要對連線的斷開處理特別小心,當然我覺得這是必須的。
但也要說明一點,如果連線不是長時間保持的,額外的均衡手段可能就不需要了,等一會就自然平衡了。這種發生在什麼情況呢?比如公網的長連線,使用者端的網路情況沒內網那麼好,經常斷開連線,這就相當於幫我們自動平滑連線了。
如果是內網服務,連線能一直保持,額外的平衡手段就顯得有必要了。
伺服器規格不同
我們通常為了單機能保持更多的長連線,一般會選用物理機部署服務,有時候各個物理機規格不統一,如果我們的均衡手段一視同仁,每個節點連線數差不多,規格差的伺服器可能壓力就比其他機器大。
所以建連的負載均衡演演算法和額外的均衡手段也要考慮伺服器規格,可以簡單地把伺服器規格與當前的連線數抽象為一個權重,使用者端建連時加權再選擇。
擴容無效問題
我們的長連線服務理應是可水平擴容的,連線數變多,加機器就可以,我們的設計大多也是如此。
但有時候可能不小心,導致水平擴容無效。
舉個例子,還是註冊中心,假設有3個節點的註冊中心叢集,此時有 1w 個使用者端連上來,訂閱了各種各樣的服務,由於使用者端的數量遠遠大於註冊中心節點,所以基本可以認為每個註冊中心節點訂閱的服務是差不多的,近似每個服務的變更,每個註冊中心節點都要處理,CPU 消耗自然就多了。如果把註冊中心節點擴容為5臺,其實每臺服務只是少了一點連線,但依然每個註冊中心節點還是近乎要處理所有的服務變更。
這種情況下就要審視長連線服務設計的是否合理,一般採取分層的思想,長連線這層服務只專注推播,一般稱為通道層或者 session 層,它並不複雜複雜的計算邏輯。
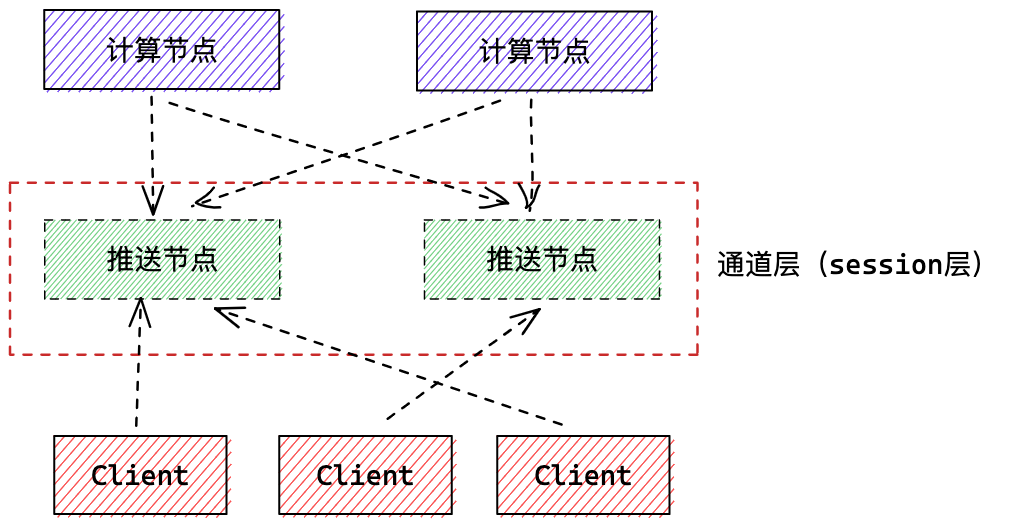
如果設計有問題,短時間又沒法修改,可以試試按照服務訂閱者的名字路由到特定的伺服器端節點,保證同一個 Conusmer 只連同一個註冊中心節點,這樣某服務變更時,該節點只需要計算一次,就可以推播給所有 Conusmer,運氣好的話,其他節點都不用計算。
結語
本文介紹了長連線與短連線的特點,為什麼需要做長連線負載均衡,以及幾個長連線負載均衡的問題和解法,相對來說還是比較通俗易懂,希望對大家有所幫助。
搜尋關注微信公眾號"捉蟲大師",後端技術分享,架構設計、效能優化、原始碼閱讀、問題排查、踩坑實踐。