是什麼讓.NET7的Min和Max方法效能暴增了45倍?
簡介
在之前的一篇文章.NET效能系列文章一:.NET7的效能改進中我們聊到Linq中的Min()和Max()方法.NET7比.NET6有高達45倍的效能提升,當時Benchmark程式碼和結果如下所示:
[Params(1000)]
public int Length { get; set; }
private int[] arr;
[GlobalSetup]
public void GlobalSetup() => arr = Enumerable.Range(0, Length).ToArray();
[Benchmark]
public int Min() => arr.Min();
[Benchmark]
public int Max() => arr.Max();
| 方法 | 執行時 | 陣列長度 | 平均值 | 比率 | 分配 |
|---|---|---|---|---|---|
| Min |  |
1000 | 3,494.08 ns | 53.24 | 32 B |
| Min |  |
1000 | 65.64 ns | 1.00 | - |
| Max | |
1000 | 3,025.41 ns | 45.92 | 32 B |
| Max | |
1000 | 65.93 ns | 1.00 | - |
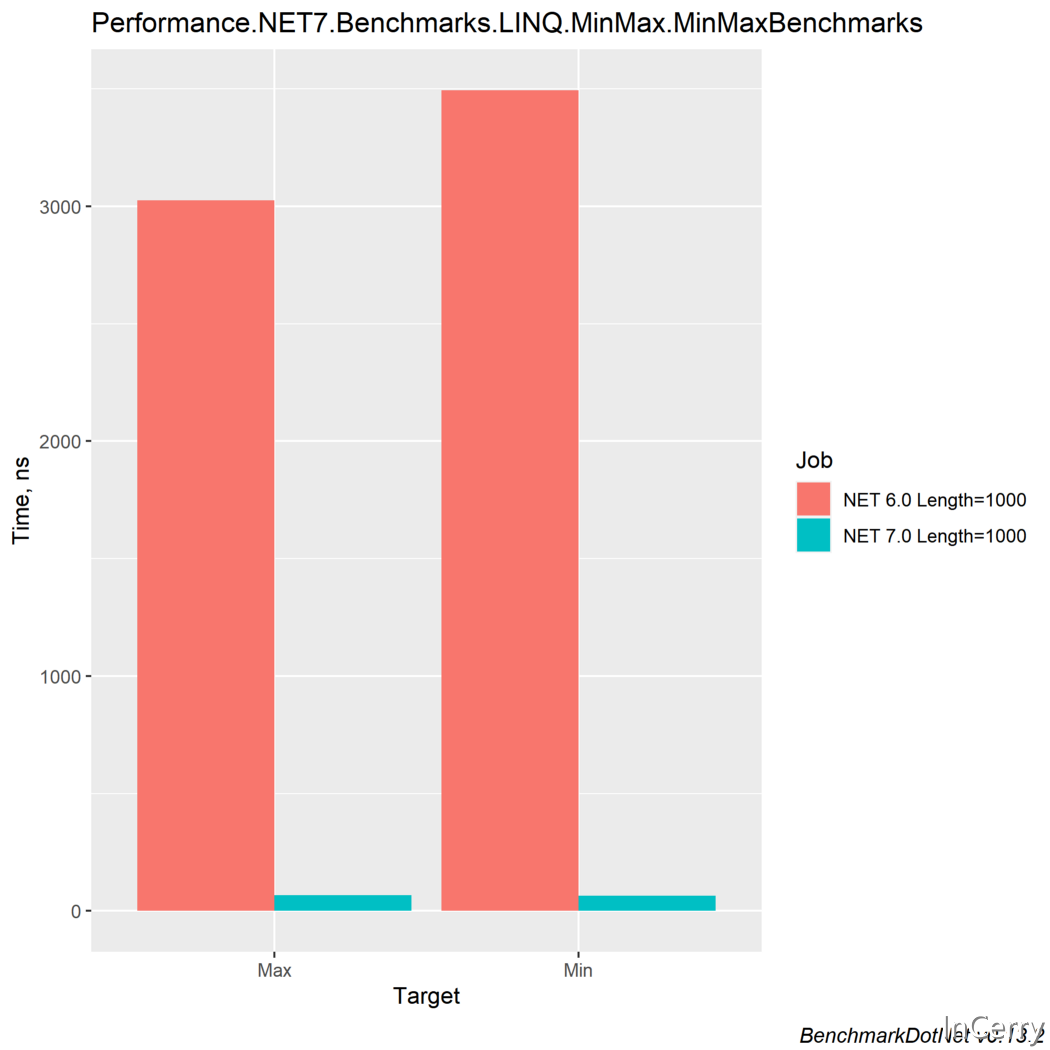
可以看到有高達45倍的效能提升,那就有小夥伴比較疑惑,在.NET7中到底是做了什麼讓它有如此大的效能提升?
所以本文就通過.NET7中的一些pr帶大家一起探索下.NET7的Min()和Max()方法是如何變快的。
探索
首先我們開啟.NET Runtime的倉庫,應該沒有人不會知道倉庫的地址吧?裡面包含了.NET執行時所有的程式碼,包括CLR和BCL庫。地址如下所示:
https://github.com/dotnet/runtime

然後我們熟練的根據名稱空間System.Linq找到Linq所在的資料夾位置,如下所示:

可以看到很多Linq相關的方法都在這個資料夾內,讓我們先來找一找Max()方法所對應的類。就是下方所示,我們可以看到剛好非同步小王子Stephen Toub大佬提交了一個優化程式碼。

然後我們點選History檢視這個類的提交歷史,我們發現Stephen大佬在今年多次提交程式碼,都是優化其效能。

找到Stephen大佬的第一個提交,我們發現在Max的程式碼中,多了一個特殊的路徑,如果資料型別為int[],那麼就走單獨的一個方法過載,並在這個過載中啟用了SIMD向量化,程式碼如下所示:

SIMD向量化在我之前的多篇文章中都有提到(如:.NET如何快速比較兩個byte陣列是否相等),它是CPU的特殊指令,使用它可以大幅度的增強運算效能,我猜這就是效能提升的原因。
我們可以看到在上面只為int[]做了優化,然後繼續瀏覽了Stephen大佬的其它幾個PR,Stephen大佬將程式碼抽象了一下,使用了泛型的特性,然後順便為其它的基本值型別都做了優化。能享受到效能提升的有byte sbyte ushort short uint int ulong long nuint nint。

所以我們以最後一個提交為例,看看到底是用了什麼SIMD指令,什麼樣的方法來提升的效能。抽取出來的核心程式碼如下所示:
private static T MinMaxInteger<T, TMinMax>(this IEnumerable<T> source)
where T : struct, IBinaryInteger<T>
where TMinMax : IMinMaxCalc<T>
{
T value;
if (source.TryGetSpan(out ReadOnlySpan<T> span))
{
if (span.IsEmpty)
{
ThrowHelper.ThrowNoElementsException();
}
// 判斷當前平臺是否支援使用Vector-128 或者 總資料長度是否小於128位元
// Vector128是指硬體支援同時計算128位元二進位制資料
if (!Vector128.IsHardwareAccelerated || span.Length < Vector128<T>.Count)
{
// 進入到此路徑,說明最基礎的Vector128都不支援,那麼直接使用for迴圈來比較
value = span[0];
for (int i = 1; i < span.Length; i++)
{
if (TMinMax.Compare(span[i], value))
{
value = span[i];
}
}
}
// 判斷當前平臺是否支援使用Vector-256 或者 總資料長度是否小於256位
// Vector256是指硬體支援同時計算256位二進位制資料
else if (!Vector256.IsHardwareAccelerated || span.Length < Vector256<T>.Count)
{
// 進入到此路徑,說明支援Vector128但不支援Vector256
// 那麼進入128位元的向量化的比較
// 獲取當前陣列的首地址,也就是指向第0個元素
ref T current = ref MemoryMarshal.GetReference(span);
// 獲取Vector128能使用的最後地址,因為整個陣列佔用的bit位有可能不能被128整除
// 也就是說最後的尾巴不夠128位元讓CPU跑一次,那麼就直接最後往前數128位元,讓CPU能完整的跑完
ref T lastVectorStart = ref Unsafe.Add(ref current, span.Length - Vector128<T>.Count);
// 從記憶體首地址載入0-127bit資料,作為最大值的基準
Vector128<T> best = Vector128.LoadUnsafe(ref current);
// 計算下一個的位置,也就是偏移128位元
current = ref Unsafe.Add(ref current, Vector128<T>.Count);
// 迴圈比較 確保地址小於最後地址
while (Unsafe.IsAddressLessThan(ref current, ref lastVectorStart))
{
// 此時TMinMax.Compare過載程式碼 => Vector128.Max(left, right);
// Vector128.Max 會根據型別一一比較,每x位最大的返回,
// 比如int就是每32位元比較,詳情可以看我後文的解析
best = TMinMax.Compare(best, Vector128.LoadUnsafe(ref current));
current = ref Unsafe.Add(ref current, Vector128<T>.Count);
}
// 最後一組Vector128進行比較
best = TMinMax.Compare(best, Vector128.LoadUnsafe(ref lastVectorStart));
// 由於Vector128最後的結果是128位元,比如我們型別是int32,那麼最後的結果就有
// 4個int32元素,我們還需要從這4個int32元素中找到最大的
value = best[0];
for (int i = 1; i < Vector128<T>.Count; i++)
{
// 這裡 TMinMax.Compare就是簡單的大小於比較
// left > right
if (TMinMax.Compare(best[i], value))
{
value = best[i];
}
}
}
else
{
// Vector256執行流程和Vector128一致
// 只是它能一次性判斷256位,舉個例子就是一個指令8個int32
ref T current = ref MemoryMarshal.GetReference(span);
ref T lastVectorStart = ref Unsafe.Add(ref current, span.Length - Vector256<T>.Count);
Vector256<T> best = Vector256.LoadUnsafe(ref current);
current = ref Unsafe.Add(ref current, Vector256<T>.Count);
while (Unsafe.IsAddressLessThan(ref current, ref lastVectorStart))
{
best = TMinMax.Compare(best, Vector256.LoadUnsafe(ref current));
current = ref Unsafe.Add(ref current, Vector256<T>.Count);
}
best = TMinMax.Compare(best, Vector256.LoadUnsafe(ref lastVectorStart));
value = best[0];
for (int i = 1; i < Vector256<T>.Count; i++)
{
if (TMinMax.Compare(best[i], value))
{
value = best[i];
}
}
}
}
else
{
// 如果不是基本型別的陣列,那麼進入迭代器,使用原始方法比較
using (IEnumerator<T> e = source.GetEnumerator())
{
if (!e.MoveNext())
{
ThrowHelper.ThrowNoElementsException();
}
value = e.Current;
while (e.MoveNext())
{
T x = e.Current;
if (TMinMax.Compare(x, value))
{
value = x;
}
}
}
}
return value;
}
以上就是程式碼的解析,相信很多人疑惑的地方就是Vector128.Max做了什麼,我們可以構造一個程式碼,讓大家簡單的看出來發生了什麼。程式碼和執行結果如下所示:
// 定義一個陣列
var array = new int[] { 4, 3, 2, 1, 1, 2, 3, 4 };
// 拿到陣列首地址指標
ref int current = ref MemoryMarshal.GetReference(array.AsSpan());
// 從首地址載入128位元資料,上面是int32
// 所以x = 4, 3, 2, 1
var x = Vector128.LoadUnsafe(ref current);
// 偏移128位元以後,繼續載入128位元資料
// 所以y = 1, 2, 3, 4
var y = Vector128.LoadUnsafe(ref Unsafe.Add(ref current, Vector128<int>.Count));
// 使用Vector128.Max進行計算
var result = Vector128.Max(x, y);
// 列印輸出結果
x.Dump();
y.Dump();
result.Dump();

從執行的結果可以看到,result中儲存的是x和y對應位置的最大值,這樣是不是就覺得清晰明瞭,Stephe大佬上文的程式碼就是做了這樣一個操作。
同樣,如果我們把int32換成int64,也就是long型別,由於一個元素佔用64位元,所以一次只能載入2個int64元素比較最大值,得出對應位置的最大值:

最後使用下面的for迴圈程式碼,從result中找到最大的那個int32元素,從我們上文的案例中就是4,結果和程式碼如下所示:
var value = result[0];
for (int i = 1; i < Vector128<int>.Count; i++)
{
if (value < result[i])
{
value = result[i];
}
}

要注意的是,為了演示方便我這裡陣列bit長度剛好是128倍數,實際情況中需要考慮不是128倍數的場景。
總結
答案顯而易見,試.NET7中Min()和Max()方法效能暴增45倍的原因就是Stephe大佬對基本幾個連續的值型別比較做了SIMD優化,而這樣的優化在本次的.NET7版本中有非常多,後面有時間帶大家一起看看SIMD又是如何提升其它方面的效能的。