Arctic 基於 Hive 的流批一體實踐
背景
隨著巨量資料業務的發展,基於 Hive 的數倉體系逐漸難以滿足日益增長的業務需求,一方面已有很大體量的使用者,但是在實時性,功能性上嚴重缺失;另一方面 Hudi,Iceberg 這類系統在事務性,快照管理上帶來巨大提升,但是對已經存在的 Hive 使用者有較大的遷移成本,並且難以滿足流式計算毫秒級延遲的需求。為了滿足網易內外部客戶對於流批一體業務的需求,網易數帆基於 Apache Iceberg 研發了新一代流式湖倉,相較於 Hudi,Iceberg 等傳統湖倉,它提供了流式更新,維表 Join,partial upsert 等功能,並且將 Hive,Iceberg,訊息佇列整合為一套流式湖倉服務,實現了開箱即用的流批一體,能幫助業務平滑地從 Hive 過渡到 Streaming Lakehouse。
Arctic 是什麼

Arctic 是搭建在 Apache Iceberg 之上的流式湖倉服務 ( Streaming LakeHouse Service )。相比 Iceberg、Hudi、Delta 等資料湖,Arctic 提供了更加優化的 CDC,流式更新,OLAP 等功能,並且結合了 Iceberg 高效的離線處理能力,Arctic 能服務於更多的流批混用場景。Arctic 還提供了包括結構自優化、並行衝突解決、標準化的湖倉管理功能等,可以有效減少資料湖在管理和優化上負擔。

Arctic Table 依賴 Iceberg 作為基礎表格式,但是 Arctic 沒有傾入 Iceberg 的實現,而是將 Iceberg 做為 lib 使用,同時 Arctic 作為專門為流批一體計算設計的流式湖倉,Arctic Table 還封裝了訊息佇列作為表的一部分,在流式計算場景下可以提供更低的訊息延遲,並且提供了流式更新,主鍵唯一性保證等功能。
流體一批的解決方案
在實時計算中,由於低延遲的要求,業務通常採用 Kafka 這類訊息佇列作為流表方案,但是在離線計算中,通常採用 Hive 作為離線表,並且由於訊息佇列不支援 AP 查詢,通常還需要額外的 OLAP 系統如 Kudu 以支援實時計算連結的最終資料輸出。這就是典型的 Lambda 架構:

這套架構最明顯的問題就是多套系統帶來的運維成本和重複開發帶來的低效率,其次就是兩套系統同時建模帶來的語意二義性問題,並且真實生產場景中,還會出現實時和離線檢視合併的需求,或者引入 KV 的實時維表關聯的需求。Arctic 的核心目標之一,就是為業務提供基於資料湖的去 Lambda 化,業務系統使用 Arctic 替代 Kafka 和Hive,實現儲存底座的流批一體。

為此 Arctic 提供了以下功能:
- Message Queue 的封裝:Arctic 通過將 MessageQueue 和資料湖封裝成一張表,實現了 Spark、Flink、Trino 等不同計算引擎存取時不需要區分流表和批表,實現了計算指標上的統一。
- 毫秒級流計算延遲:Message Queue 提供了毫秒級的讀延遲,並且提供了資料寫入和讀取的一致性保障。
- 分鐘級的 OLAP 延遲:Arctic 支援流式寫入以及流式更新,在查詢時通過 Merge on Read 實現分鐘級的 OLAP 查詢。
Table Store
Arctic Table 由不同的 Table Store 組成,TableStore 是 Arctic 在儲存系統中定義的表格式實體,Tablestore 類似於資料庫中的 cluster index,代表獨立的儲存結構,目前分為三種 TableStore。

ChangeStore
ChangeStroe 是一張 Iceberg 表,它代表了表上的增量資料,或者說最新的資料變更,通常由 Apache Flink 任務實時寫入,並用於下游任務近實時的消費。
BaseStore
BaseStore 也是張 Iceberg 表,它代表了表上的存量資料。通常來自批計算的全量初始化,或者通過Optimizer 定時將來自 ChangeStore 的資料合併入 BaseStore。在對Arctic 表執行查詢時, BaseStore 的資料會聯合 ChangeStore 的資料一起通過Merge-On-Read 返回。
LogStore
儘管 Changestore 已經能夠為表提供近實時的 CDC 能力,但在對延遲有更高要求的場景仍然需要諸如 Apache Kafka 這樣的訊息佇列提供毫秒級的 CDC 資料分發能力。而訊息佇列在 Arctic 表中被封裝為 Logstore。它由 Flink 任務實時寫入,並用於下游 Flink 任務進行實時消費。
Arctic 對 Hive 的相容
在真實業務實踐中,Hive 有著非常龐大的存量使用者以及圍繞其構建的中臺體系,要想一步直接完成從 Hive 到湖倉系統的轉換難度非常大,因此如何利用已有的 Hive 生態是 Arctic 實現流批一體首先需要解決的問題。為此 Arctic 提供了 Hive 相容的能力,以幫助 Hive 使用者可以平滑的遷移到流式數倉中。具體到細節,Arctic 提供了以下 Hive 相容能力:
- 資料存取層面的相容:Arctic 與 Hive原生的讀寫方式保持相容,即通過 Arctic 寫入的資料,Hive 可以讀;Hive 寫入的資料,Arctic 可以讀。
- 後設資料層面的相容:Arctic 表可以在 HMS 上註冊並管理,使用者直接對 Hive 表執行 DDL 可以被 Arctic 感知到。
- Hive 生態的相容:Arctic 表可以複用目前圍繞 Hive 的生態,比如可以直接通過 ranger 對 Hive 進行許可權管理的方式對 Arctic 表進行授權。
- 存量 Hive 表的相容:海量的存量 Hive 表,如果有實時化的需求,可以以很低的代價將 Hive 表升級為 Arctic 表。
Hive 相容的 Table Store
解決 Hive 相容的首要問題是需要解決 Hive 和 Arctic 檔案分佈上的不同,在 Arctic 表中被分為 ChangeStore、BaseStore、LogStore 三個不同的 Table Store,從定義上,BaseStore 代表著表的存量資料,這與 Hive 的離線數倉定位是一致的,但是在實現上,Arctic 並未直接將 BaseStore 替換為 Hive Table , 而是仍然保留 Iceberg Table 作為 BaseStore 的實現以提供 ACID 等特性,並通過目錄劃分的方式,劃分出對 Hive 相容的目錄空間,具體結構如下圖所示:

重點我們關注 Basestore 下的結構,其中區分了兩個目錄空間:
- hive location: Hive 表(或分割區)的目錄空間,會記錄在 Hive Meta Store 中,用原生的 Hive reader 會讀到這部分資料。
- iceberg location: 儲存近實時寫入資料的目錄空間,用 Iceberg 管理,包含 insert file 與 delete file,原生的 Hive reader 無法讀取到其中的資料, Arctic reader 能讀取到。
兩個目錄空間的設計保障了支援 Arctic 完整特性的基礎之上仍然相容 Hive 原生讀取。
Hive 資料同步
Hive location 的劃分實現了 Arctic 寫入資料對 Hive 查詢引擎讀的相容,但是通過 Hive 查詢引擎寫入的資料或者 schema 變更卻無法讓 Arctic 立即識別,為此 Arctic 引入了 Hive Syncer 用於識別通過 Hive 查詢引擎對錶結構和資料的變更。Hive Syncer 包括 2 個目標:
- Hive 表結構變更同步到 Arctic
- Hive 表資料變更同步到 Arctic
_Table Metadata Sync_Hive
表結構資訊的同步是通過對比 Arctic Table Schema 和 Hive Table Schema 的差異實現的,由於對比代價較小,Arctic 採取的方式是在所有的讀取/寫入/schema 查詢/變更 執行前都會執行 Metadata Sync 操作。通過對 Schema 的對比,Arctic 可以自動識別在 Hive 表上的 DDL 變更。Hive Schema 的同步能力使得 Arctic 的資料開發可以繼續複用Hive生態下的資料建模工具,資料開發只需要如同對 Hive 表建模一樣即可完成對 Arctic 表的建模。
_Table Data Sync_Hive
表資料的變更的檢查是通過分割區下的 transient_lastDdlTime 欄位識別的,讀取 Hive 分割區下資料時會對比分割區的修改時間是否和 Arctic 的 metadata 中記載是否一致,如果不一致就通過 HDFS 的 listDir 介面獲取分割區下的全部檔案,並對比 Arctic 表最新 snapshot 對應的檔案,如果檔案列表有差異,說明有通過非 Arctic 的途徑對 Hive 表的資料進行了修改,此時 Arctic 會生成一個新的快照,對 Arctic 表的檔案資訊進行修正。由於 HDFS 的 listDir 操作是一個比較重的操作,預設情況下是通過 AMS 定時觸發 DataSync 檢查,如果對資料一致性要求更高,可以通過引數 base.hive.auto-sync-data-write 設定為每次查詢前進行 Data Sync 檢查。Hive 資料同步的能力使得使用者從離線開發鏈路遷移到實時開發連結的過程中保留離線資料開發的邏輯,通過離線完成對實時的資料修正,並且保證了實時和離線建模的統一以及指標的統一。
存量 Hive 表原地升級
Arctic 不僅支援建立 Hive 相容表,還支援直接將已經存在的 Hive 表升級為一張 Arctic 下的 Hive 相容表。在 AMS 上匯入 HMS 對應的 hive-site.xml 即可看到 HMS 上對應的表,在對應的 Hive 表上點選 Upgrade 按鈕即可對 Hive 表進行原地升級。

Arctic 還支援在進行原地升級時指定主鍵,這樣可以將 Hive 表升級為有主鍵的 Arctic 表。

Hive 的原地升級操作是非常輕量級的,在執行 Upgrade 操作的背後,AMS 僅僅是新建一個空的 Arctic Table,然後掃描 Hive 目錄,並建立一個包括所有 Hive 下的 Parquet 檔案的 Snapshot 即可,整個過程並不涉及到資料檔案的複製和重寫。
相容 Hive 表的許可權管理
圍繞著 Hive 已經有了一套完整的巨量資料生態,其中對於表的許可權管理和資料脫敏極為重要,當前 Arctic的 Hive 相容表已經適配了 incubator-kyuubi 專案下的 spark-auth 外掛 https://github.com/apache/incubator-kyuubi 通過該外掛 Arctic 完成了對 Ranger 的適配,在實際應用中,通過 Ranger 對 Arctic 對應的 Hive 進行授權,在 SparkJob 中即可完成對 Arctic 表的鑑權。
基於Hive 的流批一體實踐
Arctic 的 Hive 相容模式是為了幫助適應了 Hive 的使用者快速上手 Arctic,對於 Hive 使用者來說,如果滿足以下其中一點:
1. 有大量的存量 Hive 表,並且其中部分 Hive 表有流式寫入、訂閱的需求
2. 在離線場景下有成熟的產品構建,並且希望為離線賦予部分實時的能力,但是又不想對離線平臺做過多的改造
即可嘗試通過 Arctic Hive 相容表解決你的痛點。
實踐案例:網易雲音樂特徵生產工程實時化
網易雲音樂的推薦業務圍繞著 Spark+Hive 已經構建了一套成熟的巨量資料+AI 開發體系,隨著業務的增長,業務對整套系統的實時性要求在不斷增強,但是直接通過 Flink + Kafka 構建的實時鏈路並不夠完善。在離線鏈路中圍繞著 Hive 有著完善的基礎設施和方法論,資料開發和演演算法工程師通過模型設計中心完成表的設計,資料開發負責資料的攝取,清洗,打寬,聚合等基礎處理,演演算法工程師負責在 DWS 層的資料上實現特徵生產演演算法,分析師通過對 ODS 層、DWD 層以及 DWS 層的表執行 Ad Hoc 式的查詢並構建分析報表以評估特徵資料質量。整套鏈路層次分明、分工清晰,即最大限度的複用了計算結果,又比較好的統一了指標口徑,是典型的 T+1 的數倉建設。但是在實時鏈路中,資料開發僅僅協助完成原始資料到 Kafka 的攝取,演演算法工程師需要從 ODS 層資料進行加工,整個鏈路缺乏資料分層,既不能複用離線計算結果,也無法保證指標的一致性。
整個特徵工程的生產路線的現狀如下圖所示:
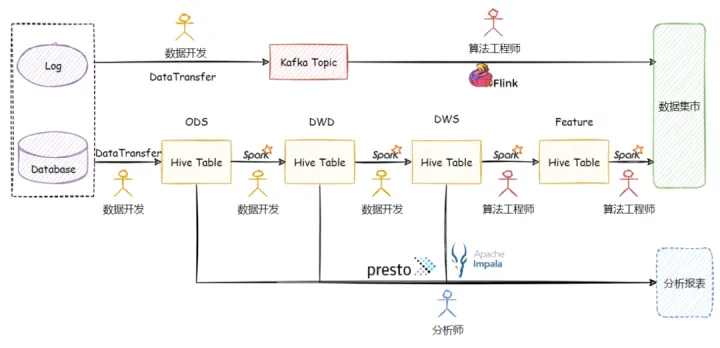
由於存在大量的存量 Hive 表,並且還有來自 Presto 和 Impala 的查詢鏈路需要複用 ODS 和 DWD 層的 Hive 表,整個特徵工程想直接使用 Iceberg 或 Hudi 這樣的系統其切換代價還是很大的,系統切換期間對系統整體 SLA 要求較高,新系統磨合過程中如果造成資料產出延遲,對於業務來說是不可接受的。最終我們採用了 Arctic Hive 相容表的模式, 分階段的將 Hive 表升級為 Arctic 下的 Hive 相容表,升級後的資料生產鏈路如下圖所示:

升級後Arctic 為整個特徵工程帶來了以下好處:
1. Arctic 以無感知的方式完成了約 2PB 級別的 Hive 表實時化,由於做到 Hive 的讀寫相容,本身 T+1 的全量資料回補以及分析師的報表查詢 SQL 不用做任何修改,升級過程中保證了不影響離線鏈路開發。
2. 實時特徵的生產複用了數倉 DWS 層資料,不需要從 ODS 層直接構建特徵演演算法,而數倉的清洗、聚合均由資料開發完成,提升了演演算法工程師的人效,使得演演算法工程師可以更好的專注於特徵演演算法本身。平均下來每個演演算法節省人效約 1 天。
3. 完成了實時鏈路和離線鏈路的統一,在資料血緣,資料指標,模型設計上可以做到更好的資料治理。
4. Arctic 本身可以為 ODS 和 DWD 層的表設定更激進的 Optimize 策略,以 10 分鐘的頻率對 Hive Table 的資料進行 Overwrite, 分析師可以享受到更加實時的分析報表。
總結
本文介紹了網易數帆開源的新一代流式湖倉 Arctic 以及其基於 Hive 的流批一體實踐。希望讀者可以經此文章瞭解 Arctic 並對業務構建流批一體的資料湖有幫助。感謝一直一來對 Arctic 社群的支援,如果您對 Arctic 、湖倉一體、流批一體感興趣,並想一起推動它的發展,請在 Github 上關注 Arctic 專案https://github.com/NetEase/arctic。也歡迎加入 Arctic 交流群:微信新增「kllnn999」為好友,註明「Arctic 交流」。
瞭解更多
作者簡介:
張永翔,網易數帆資深平臺開發工程師,Arctic Committer,6 年從業經驗,先後從事網易 RDS、資料中臺、實時計算平臺等開發,目前主要負責 Arctic 流式湖倉服務開發。
胡溢勝,網易雲音樂資料專家,10 年數倉經驗,涉及通訊、網際網路、環保、醫療等行業。2020 年加入網易雲音樂,目前負責網易雲音樂社交直播業務線的資料建設。