文字挖掘與NLP筆記——程式碼向:分詞
2022-10-27 21:02:50
分詞:jieba.cut
words = jieba.cut("我來到北京大學",cut_all=True)
print('全模式:'+'/'.join([w for w in words])) #全模式
words = jieba.cut("我來到北京大學",cut_all=False)
print('精確模式:'+'/'.join([w for w in words])) #精確模式,預設
words = jieba.cut_for_search("小明畢業於北京大學,後在美國哈佛大學深造")
print('/'.join([w for w in words])) #搜尋引擎模式,在精確模式的基礎上,對長詞在此劃分
全模式:我/來到/北京/北京大學/大學
精確模式:我/來到/北京大學
小明/畢業/於/北京/大學/北京大學/,/後/在/美國/哈佛/大學/美國哈佛大學/深造
請練習新增自定義詞典
詞性:jieba.posseg
import jieba.posseg as pg
for word, flag in pg.cut("你想去學校填寫學生寒暑假住校申請表嗎?"):
print('%s %s' % (word, flag))
'你/學校/填寫/學生/寒暑假/住校/申請表'
分詞引入停用詞
import jieba
import pandas as pd
import numpy as np
paths = '中英文停用詞.xlsx'
dfs = pd.read_excel(paths,dtype=str)
stopwords = ['想','去','嗎','?']
words = jieba.cut("你想去學校填寫學生寒暑假住校申請表嗎?")
'/'.join([w for w in words if (w not in stopwords)])#此處’/'表示換行
'你/學校/填寫/學生/寒暑假/住校/申請表'
txt轉dataframe函數
import random
import jieba.posseg as pg
import pandas as pd
import numpy as np
def generatorInfo(file_name):
# 讀取文字檔案
with open(file_name, encoding='utf-8') as file:
line_list = [k.strip() for k in file.readlines()]
data = []
for k in random.sample(line_list,1000):
t = k.split(maxsplit=1)
#data_label_list.append(t[0])
#data_content_list.append(t[1])
data.append([t[0],' '.join([w for w,flag in pg.cut(t[1]) if (w not in dfs['stopwords']) and (w !=' ') and (len(w)>=2)])])
return data
file_name = 'cnews.train.txt'
df = pd.DataFrame(np.array(generatorInfo(file_name)),columns=['類別','分詞'])
path = '訓練集分詞結果(隨機選取1000個樣本).xlsx'
df.to_excel(path,index=False)
df

詞雲圖:wordcloud
%pylab inline
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = ' '.join(list(df['分詞']))
wcloud = WordCloud(
font_path='simsun.ttc', #字型路徑
background_color='white', #指定背景顏色
max_words=500, #詞雲顯示最大詞數
max_font_size=150, #指定最大字號
#mask = mask #背景圖片
)
wcloud = wcloud.generate(text) #生成詞雲
plt.imshow(wcloud)
plt.axis('off')
plt.show()

提取關鍵詞:jieba.analyse.extract_tags
import jieba.analyse
import pandas as pd
import numpy as np
path = '訓練集分詞結果(隨機選取1000個樣本).xlsx'
df = pd.read_excel(path,dtype=str)
s = ' '.join(list(df['分詞']))
for w,x in jieba.analyse.extract_tags(s,withWeight=True):
print('%s %s' % (w,x))

請練習基於TextRank演演算法抽取關鍵詞
import jieba.analyse
import pandas as pd
import numpy as np
path = '訓練集分詞結果(隨機選取1000個樣本).xlsx'
df = pd.read_excel(path,dtype=str)
tag = list(set(list(df['類別'])))
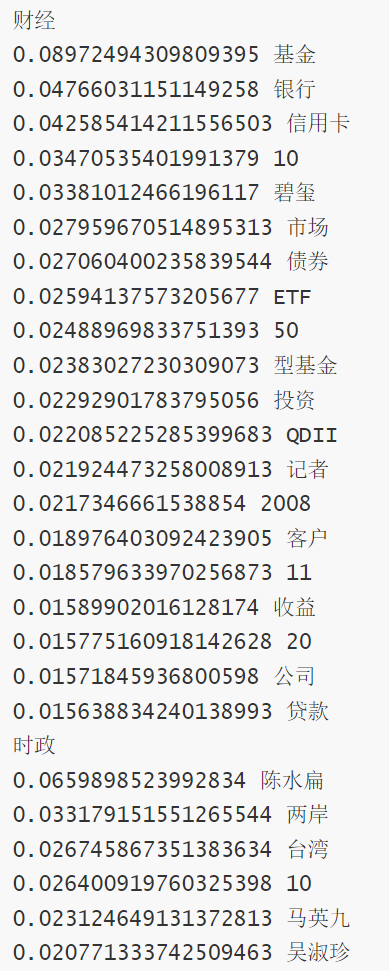
for t in tag:
s = ' '.join(list(df[df['類別']==t]['分詞']))
print(t)
for w,x in jieba.analyse.extract_tags(s,withWeight=True):
print('%s %s' % (x,w))
構建詞向量
構建詞向量簡單的有兩種分別是TfidfTransformer和 CountVectorizer
#CountVectorizer會將文字中的詞語轉換為詞頻矩陣
from sklearn.feature_extraction.text import CountVectorizer
path = '訓練集分詞結果(隨機選取1000個樣本).xlsx'
df = pd.read_excel(path,dtype=str)
corpus = df['分詞']
#vectorizer = CountVectorizer(max_features=5000)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(X)

from sklearn.feature_extraction.text import TfidfTransformer
import datetime
starttime = datetime.datetime.now()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
print(weight)

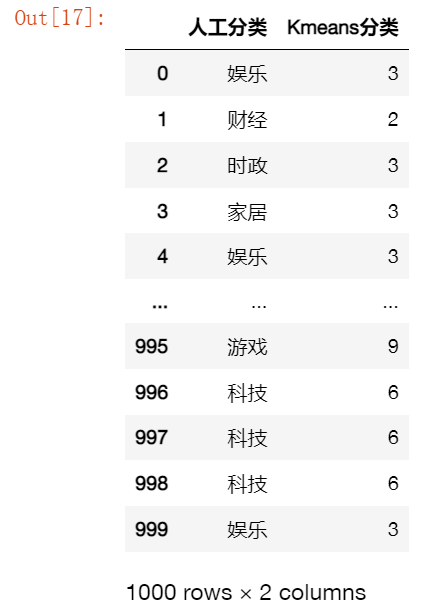
詞語分類:人工vsKmeans
from sklearn.cluster import KMeans
starttime = datetime.datetime.now()
path = '訓練集分詞結果(隨機選取1000個樣本).xlsx'
df = pd.read_excel(path,dtype=str)
corpus = df['分詞']
kmeans=KMeans(n_clusters=10) #n_clusters:number of cluster
kmeans.fit(weight)
res = [list(df['類別']),list(kmeans.labels_)]
df_res = pd.DataFrame(np.array(res).T,columns=['人工分類','Kmeans分類'])
path_res = 'Kmeans自動分類結果.xlsx'
df_res.to_excel(path_res,index=False)
df_res
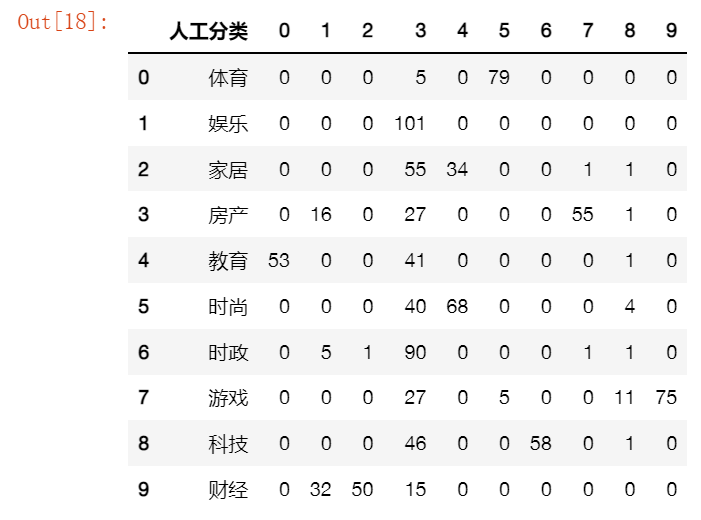
path = 'Kmeans自動分類結果.xlsx'
df = pd.read_excel(path,dtype=str)
df['計數'] = [1 for m in range(len(df['人工分類']))]
df1 = pd.pivot_table(df, index=['人工分類'], columns=['Kmeans分類'], values=['計數'], aggfunc=np.sum, fill_value=0)
co = ['人工分類']
co.extend(list(df1['計數'].columns))
df1 = df1.reset_index()
df2 = pd.DataFrame((np.array(df1)),columns=co)
path_res = '人工與Kmeans分類結果對照.xlsx'
df2.to_excel(path_res,index=False)
df2
import random
def is_contain_chinese(check_str):
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return 1
return 0
def generatorInfo(file_name):
"""
batch_size:生成資料的batch size
seq_length:輸入文字序列長度
num_classes:文字的類別數
file_name:讀取檔案的路徑
"""
# 讀取文字檔案
with open(file_name, encoding='utf-8') as file:
line_list = [k.strip() for k in file.readlines()]
#data_label_list = [] # 建立資料標籤檔案
#data_content_list = [] # 建立資料文字檔案
data = []
for k in random.sample(line_list,1000):
t = k.split(maxsplit=1)
#data_label_list.append(t[0])
#data_content_list.append(t[1])
data.append([t[0],' '.join([w for w,flag in jieba.posseg.cut(t[1]) if (w not in dfs['stopwords']) and (w !=' ') and (flag not in ["nr","ns","nt","nz","m","f","ul","l","r","t"]) and (len(w)>=2)])])
return data
#匯入中文停用詞表
paths = '中英文停用詞.xlsx'
dfs = pd.read_excel(paths,dtype=str)
file_name = 'cnews.train.txt'
df = pd.DataFrame(np.array(generatorInfo(file_name)),columns=['類別','分詞'])
df

彙總
import random
import jieba
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfTransformer
def is_contain_chinese(check_str):
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return 1
return 0
def generatorInfo(file_name):
"""
batch_size:生成資料的batch size
seq_length:輸入文字序列長度
num_classes:文字的類別數
file_name:讀取檔案的路徑
"""
# 讀取文字檔案
with open(file_name, encoding='utf-8') as file:
line_list = [k.strip() for k in file.readlines()]
#data_label_list = [] # 建立資料標籤檔案
#data_content_list = [] # 建立資料文字檔案
data = []
for k in random.sample(line_list,1000):
t = k.split(maxsplit=1)
#data_label_list.append(t[0])
#data_content_list.append(t[1])
data.append([t[0],' '.join([w for w,flag in jieba.posseg.cut(t[1]) if (w not in dfs['stopwords']) and (w !=' ') and (flag not in ["nr","ns","nt","nz","m","f","ul","l","r","t"]) and (len(w)>=2)])])
return data
#匯入中文停用詞表
paths = '中英文停用詞.xlsx'
dfs = pd.read_excel(paths,dtype=str)
file_name = 'cnews.train.txt'
df = pd.DataFrame(np.array(generatorInfo(file_name)),columns=['類別','分詞'])
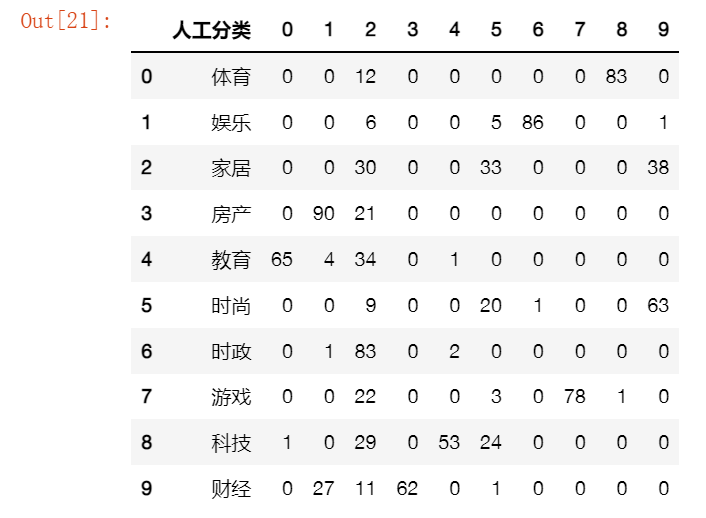
#統計詞頻
corpus = df['分詞'] #語料中的單詞以空格隔開
#vectorizer = CountVectorizer(max_features=5000)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
#文字向量化
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
word = vectorizer.get_feature_names()
weight = tfidf.toarray()
kmeans=KMeans(n_clusters=10) #n_clusters:number of cluster
kmeans.fit(weight)
res = [list(df['類別']),list(kmeans.labels_)]
df_res = pd.DataFrame(np.array(res).T,columns=['人工分類','Kmeans分類'])
df_res['計數'] = [1 for m in range(len(df_res['人工分類']))]
df1 = pd.pivot_table(df_res, index=['人工分類'], columns=['Kmeans分類'], values=['計數'], aggfunc=np.sum, fill_value=0)
co = ['人工分類']
co.extend(list(df1['計數'].columns))
df1 = df1.reset_index()
df2 = pd.DataFrame((np.array(df1)),columns=co)
df2
df['Kmeans分類'] = df_res['Kmeans分類']
df
