【一】ERNIE:飛槳開源開發套件,入門學習,看看行業頂尖持續學習語意理解框架,如何取得世界多個實戰的SOTA效果?
參考文章:
深度剖析知識增強語意表示模型——ERNIE_財神Childe的部落格-CSDN部落格_ernie模型
https://github.com/PaddlePaddle/ERNIE/blob/develop/README.zh.md
1.背景介紹
近年來,語意表示(language representation)技術的發展,使得 「預訓練-微調」 作為解決NLP任務的一種新的正規化開始出現。一個通用的表示能力強的模型被選擇為語意表示模型,在預訓練階段,用大量的語料和特定的任務訓練該模型,使其編碼海量的語意知識;在微調階段,該模型會被加上不同的簡單輸出層用以解決下游的 NLP 任務。早期較為著名的語意表示模型包括ELMo 和 GPT ,分別基於雙層雙向LSTM和Transformer Decoder框架,而真正讓語意表示技術大放異彩的是BERT (Bidirectional Encoder Representations from Transformers) 的提出。BERT以Transformer Encoder為骨架,以遮蔽語言模型 (Masked LM) 和下一句預測(Next Sentence Prediction)這兩個無監督預測任務作為預訓練任務,用英文Wikipedia和Book Corpus的混合語料進行訓練得到預訓練模型。結合簡單的輸出層,BERT提出伊始就在11個下游NLP任務上取得了 SOTA(State of the Art)結果,即效果最佳,其中包括了自然語言理解任務GLUE和閱讀理解SQuAD。
可以看到,用語意表示模型解決特定的NLP任務是個相對簡單的過程。因此,語意表示模型的預訓練階段就變得十分重要,具體來說,模型結構的選取、訓練資料以及訓練方法等要素都會直接影響下游任務的效果。當前的很多學術工作就是圍繞預訓練階段而展開的,在BERT之後各種語意表示模型不斷地被提了出來。
ERNIE(Enhanced Representation through kNowledge IntEgration)是百度提出的語意表示模型,同樣基於Transformer Encoder,相較於BERT,其預訓練過程利用了更豐富的語意知識和更多的語意任務,在多個NLP任務上取得了比BERT等模型更好的效果。
專案開源地址: https://github.com/PaddlePaddle/ERNIE
該專案包含了對預訓練,以及常見下游 NLP 任務的支援,如分類、匹配、序列標註和閱讀理解等。
2.原理介紹
2.1 Transformer Encoder
ERNIE 採用了 Transformer Encoder 作為其語意表示的骨架。Transformer 是由論文Attention is All You Need 首先提出的機器翻譯模型,在效果上比傳統的 RNN 機器翻譯模型更加優秀。Transformer 的簡要結構如圖1所示,基於 Encoder-Decoder 框架, 其主要結構由 Attention(注意力) 機制構成:
- Encoder 由全同的多層堆疊而成,每一層又包含了兩個子層:一個Self-Attention層和一個前饋神經網路。Self-Attention 層主要用來輸入語料之間各個詞之間的關係(例如搭配關係),其外在體現為詞彙間的權重,此外還可以幫助模型學到句法、語法之類的依賴關係的能力。
- Decoder 也由全同的多層堆疊而成,每一層同樣包含了兩個子層。在 Encoder 和 Decoder 之間還有一個Encoder-Decoder Attention層。Encoder-Decoder Attention層的輸入來自於兩部分,一部分是Encoder的輸出,它可以幫助解碼器關注輸入序列哪些位置值得關注。另一部分是 Decoder 已經解碼出來的結果再次經過Decoder的Self-Attention層處理後的輸出,它可以幫助解碼器在解碼時把已翻譯的內容中值得關注的部分考慮進來。例如將「read a book」翻譯成中文,我們把「book」之所以翻譯成了「書」而沒有翻譯成「預定」就是因為前面Read這個讀的動作。
在解碼過程中 Decoder 每一個時間步都會輸出一個實數向量,經過一個簡單的全連線層後會對映到一個詞典大小、被稱作對數機率(logits)的向量,再經過 softmax 歸一化之後得到當前時間步各個詞出現的概率分佈。
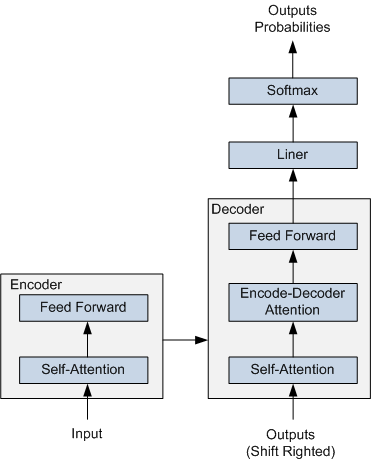
圖 1 Transformer 的簡要結構圖
Transformer 在機器翻譯任務上面證明了其超過 LSTM/GRU 的卓越表示能力。從 RNN 到 Transformer,模型的表示能力在不斷的增強,語意表示模型的骨架也經歷了這樣的一個演變過程。如圖2所示,該圖為BERT、GPT 與 ELMo的結構示意圖,可以看到 ELMo 使用的就是 LSTM 結構,接著 GPT 使用了 Transformer Decoder。進一步 BERT 採用了雙向 Transformer Encoder,從理論上講其相對於 Decoder 有著更強的語意表示能力,因為Encoder接受雙向輸入,可同時編碼一個詞的上下文資訊。最後在NLP任務的實際應用中也證明了Encoder的有效性,因此ERNIE也採用了Transformer Encoder架構。

圖2 BERT、GPT 與 ELMo
2.2 ERNIE
介紹了 ERNIE 的骨架結構後,下面再來介紹了 ERNIE 的原理。
ERNIE 分為 1.0 版和 2.0 版,其中ERNIE 1.0是通過建模海量資料中的詞、實體及實體關係,學習真實世界的語意知識。相較於BERT學習原始語言訊號,ERNIE 1.0 可以直接對先驗語意知識單元進行建模,增強了模型語意表示能力。例如對於下面的例句:「哈爾濱是黑龍江的省會,國際冰雪文化名城」
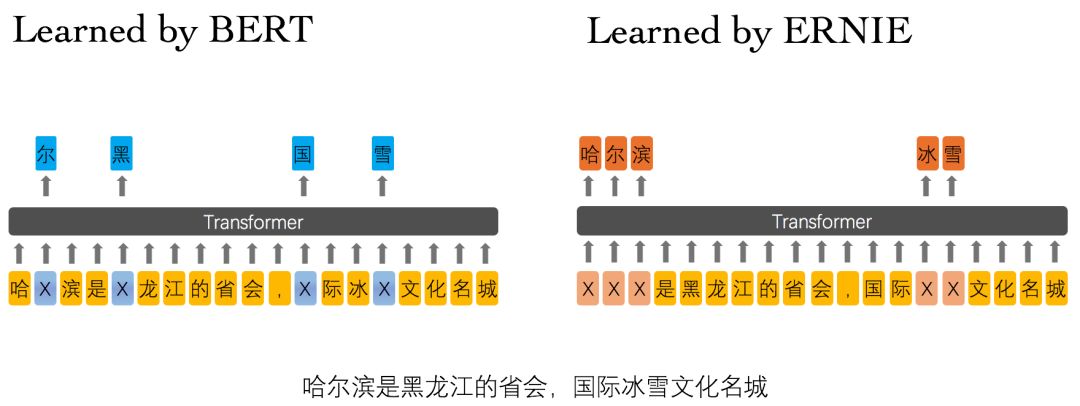
圖3 ERNIE 1.0 與 BERT 詞遮蔽方式的比較
BERT在預訓練過程中使用的資料僅是對單個字元進行遮蔽,例如圖3所示,訓練Bert通過「哈」與「濱」的區域性共現判斷出「爾」字,但是模型其實並沒有學習到與「哈爾濱」相關的知識,即只是學習到「哈爾濱」這個詞,但是並不知道「哈爾濱」所代表的含義;而ERNIE在預訓練時使用的資料是對整個詞進行遮蔽,從而學習詞與實體的表達,例如遮蔽「哈爾濱」與「冰雪」這樣的詞,使模型能夠建模出「哈爾濱」與「黑龍江」的關係,學到「哈爾濱」是「黑龍江」的省會以及「哈爾濱」是個冰雪城市這樣的含義。
訓練資料方面,除百科類、資訊類中文語料外,ERNIE 1.0 還引入了論壇對話類資料,利用對話語言模式(DLM, Dialogue Language Model)建模Query-Response對話結構,將對話Pair對作為輸入,引入Dialogue Embedding標識對話的角色,利用對話響應丟失(DRS, Dialogue Response Loss)學習對話的隱式關係,進一步提升模型的語意表示能力。
因為 ERNIE 1.0 對實體級知識的學習,使得它在語言推斷任務上的效果更勝一籌。ERNIE 1.0 在中文任務上全面超過了 BERT 中文模型,包括分類、語意相似度、命名實體識別、問答匹配等任務,平均帶來 1~2 個百分點的提升。
我們可以發現 ERNIE 1.0 與 BERT 相比只是學習任務 MLM 作了一些改進就可以取得不錯的效果,那麼如果使用更多較好的學習任務來訓練模型,那是不是會取得更好的效果呢?因此 ERNIE 2.0 應運而生。ERNIE 2.0 是基於持續學習的語意理解預訓練框架,使用多工學習增量式構建預訓練任務。如圖4所示,在ERNIE 2.0中,大量的自然語言處理的語料可以被設計成各種型別的自然語言處理任務(Task),這些新構建的預訓練型別任務(Pre-training Task)可以無縫的加入圖中右側的訓練框架,從而持續讓ERNIE 2.0模型進行語意理解學習,不斷的提升模型效果。

圖4 ERNIE 2.0框架
ERNIE 2.0 的預訓練包括了三大類學習任務,分別是:
- 詞法層任務:學會對句子中的詞彙進行預測。
- 語法層任務:學會將多個句子結構重建,重新排序。
- 語意層任務:學會判斷句子之間的邏輯關係,例如因果關係、轉折關係、並列關係等。
通過這些新增的語意任務,ERNIE 2.0語意理解預訓練模型從訓練資料中獲取了詞法、句法、語意等多個維度的自然語言資訊,極大地增強了通用語意表示能力。ERNIE 2.0模型在英語任務上幾乎全面優於BERT和XLNet,在7個GLUE任務上取得了最好的結果;中文任務上,ERNIE 2.0模型在所有9箇中文NLP任務上全面優於BERT。
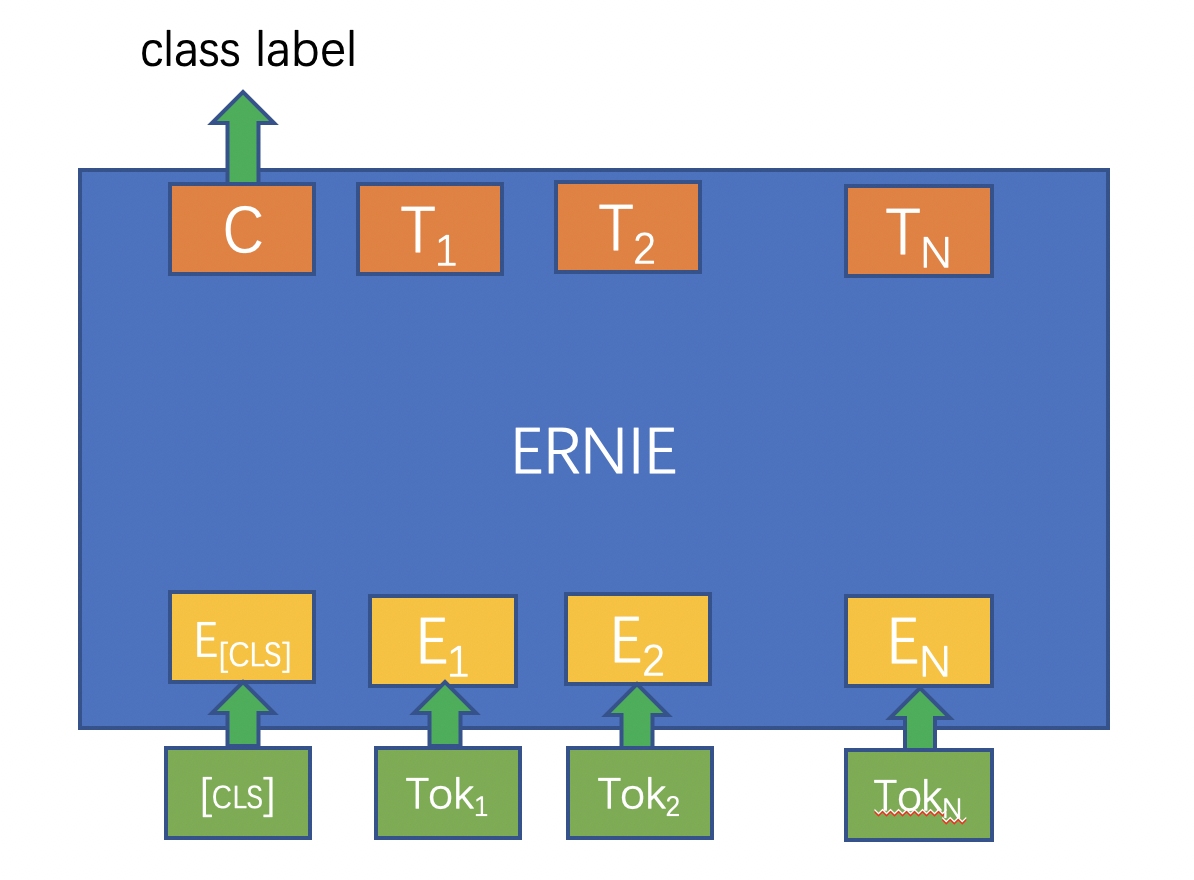
完成預訓練後,如何用 ERNIE 來解決具體的 NLP 問題呢?下面以單句分類任務(如情感分析)為例,介紹下游 NLP 任務的解決過程:
- 基於tokenization.py指令碼中的Tokenizer對輸入的句子進行token化,即按字粒度對句子進行切分;
- 分類標誌符號[CLS]與token化後的句子拼接在一起作為ERNIE模型的輸入,經過 ERNIE 前向計算後得到每個token對應的embedding向量表示;
- 在單句分類任務中,[CLS]位置對應的嵌入式向量會用來作為分類特徵。只需將[CLS]對應的embedding抽取出來,再經過一個全連線層得到分類的 logits 值,最後經過softmax歸一化後與訓練資料中的label一起計算交叉熵,就得到了優化的損失函數;
- 經過幾輪的fine-tuning,就可以訓練出解決具體任務的ERNIE模型。
關於ERNIE更詳細的介紹,可以參考這兩篇學術論文:
- ERNIE: Enhanced Representation through Knowledge Integration
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
本教學不對預訓練過程作過多展開,主要關注如何使用ERNIE解決下游的NLP任務。