怎麼使用Python進行多執行緒並行下載圖片

程式設計師必備介面測試偵錯工具:
有時候,下載大量影象需要幾個小時——讓我們來解決這個問題
我明白了——你已經厭倦了等待你的程式下載影象。有時我必須下載數千張影象需要幾個小時,而且你不可能一直等待你的程式完成下載這些愚蠢的影象。你有很多重要的事情要做。
讓我們構建一個簡單的影象下載器指令碼,它將讀取一個文字檔案並以超快的速度下載一個資料夾中列出的所有影象。
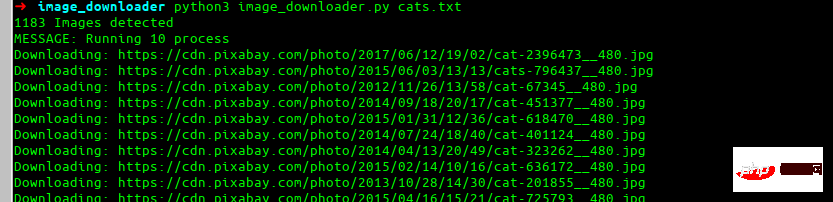
最終效果
這就是我們最終要構建的效果。

安裝依賴項
讓我們安裝每個人最喜歡的 requests 庫。
pip install requests
登入後複製現在,我們將看到一些用於下載單個 URL 並嘗試自動查詢影象名稱以及如何使用重試的基本程式碼。
import requests
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1登入後複製在這裡,我們重試下載影象五次,以防失敗。現在,讓我們嘗試自動找到影象的名稱並儲存它。
import more required library
import io
from PIL import Image
# lets try to find the image name
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]登入後複製解釋
假設我們要下載的 URL 是:
instagram.fktm7-1.fna.fbcdn.net/vp...
好吧,這是一團糟。讓我們分解一下程式碼對 URL 的作用。我們首先使用 rfind 找到最後一個正斜槓(/),然後選擇之後的所有內容。這是結果:
65872070_1200425330158967_6201268309743367902_n.jpg?_nc_ht=instagram.fktm7–1.fna.fbcdn.net&_nc_cat=111
現在我們的第二部分找到一個 ?,然後只取它前面的任何東西。
這是我們最終的影象名稱:
65872070_1200425330158967_6201268309743367902_n.jpg
這個結果非常好,適用於大多數用例。
現在我們已經下載了影象名稱和影象,我們將儲存它。
i = Image.open(io.BytesIO(res.content))
i.save(image_name)
登入後複製如果你在想,「我到底應該怎麼使用上面的程式碼?」那麼你的想法是正確的。這是一個漂亮的函數,我們在上面所做的一切都被扁平處理了。在這裡,我們還測試了下載的型別是否為影象,以防找不到影象名稱。
def image_downloader(img_url: str):
"""
Input:
param: img_url str (Image url)
Tries to download the image url and use name provided in headers. Else it randomly picks a name
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1
# checking the type for image
if 'image' not in res.headers.get("content-type", ''):
print('ERROR: URL doesnot appear to be an image')
return False
# Trying to red image name from response headers
try:
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
except:
image_name = str(random.randint(11111, 99999))+'.jpg'
i = Image.open(io.BytesIO(res.content))
download_location = 'cats'
i.save(download_location + '/'+image_name)
return f'Download complete: {img_url}'登入後複製現在,你可能會問:「這個人所說的多處理在哪裡?」。
這很簡單。我們將簡單地定義我們的池並將我們的函數和影象 URL 傳遞給它。
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)登入後複製讓我們把它放在一個函數中:
def run_downloader(process:int, images_url:list):
"""
Inputs:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)登入後複製再一次,你可能會說,「這一切都很好,但我想立即開始下載我的 1000 張影象列表。我不想複製和貼上所有這些程式碼並試圖弄清楚如何合併所有內容。」
這是一個完整的指令碼。它執行以下操作:
以影象列表文字檔案和程序號作為輸入
按照您想要的速度下載它們
列印下載檔案的總時間
還有一些不錯的函數可以幫助我們讀取檔名並處理錯誤和其他東西
完整的指令碼
# -*- coding: utf-8 -*-
import io
import random
import shutil
import sys
from multiprocessing.pool import ThreadPool
import pathlib
import requests
from PIL import Image
import time
start = time.time()
def get_download_location():
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n$python image_downloader.py cats.txt')
name = url_input.split('.')[0]
pathlib.Path(name).mkdir(parents=True, exist_ok=True)
return name
def get_urls():
"""
通過讀取終端中作為引數提供的 txt 檔案返回 url 列表
"""
try:
url_input = sys.argv[1]
except IndexError:
print('ERROR: Please provide the txt file\n Example \n\n$python image_downloader.py dogs.txt \n\n')
sys.exit()
with open(url_input, 'r') as f:
images_url = f.read().splitlines()
print('{} Images detected'.format(len(images_url)))
return images_url
def image_downloader(img_url: str):
"""
輸入選項:
引數: img_url str (Image url)
嘗試下載影象 url 並使用標題中提供的名稱。否則它會隨機選擇一個名字
"""
print(f'Downloading: {img_url}')
res = requests.get(img_url, stream=True)
count = 1
while res.status_code != 200 and count <= 5:
res = requests.get(img_url, stream=True)
print(f'Retry: {count} {img_url}')
count += 1
# checking the type for image
if 'image' not in res.headers.get("content-type", ''):
print('ERROR: URL doesnot appear to be an image')
return False
# Trying to red image name from response headers
try:
image_name = str(img_url[(img_url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
except:
image_name = str(random.randint(11111, 99999))+'.jpg'
i = Image.open(io.BytesIO(res.content))
download_location = get_download_location()
i.save(download_location + '/'+image_name)
return f'Download complete: {img_url}'
def run_downloader(process:int, images_url:list):
"""
輸入項:
process: (int) number of process to run
images_url:(list) list of images url
"""
print(f'MESSAGE: Running {process} process')
results = ThreadPool(process).imap_unordered(image_downloader, images_url)
for r in results:
print(r)
try:
num_process = int(sys.argv[2])
except:
num_process = 10
images_url = get_urls()
run_downloader(num_process, images_url)
end = time.time()
print('Time taken to download {}'.format(len(get_urls())))
print(end - start)登入後複製將其儲存到 Python 檔案中,然後執行它。
python3 image_downloader.py cats.txt
登入後複製這是 GitHub 儲存庫的連結。
用法
python3 image_downloader.py <filename_with_urls_seperated_by_newline.txt> <num_of_process>
登入後複製這將讀取文字檔案中的所有 URL,並將它們下載到名稱與檔名相同的資料夾中。
num_of_process 是可選的(預設情況下,它使用 10 個程序)。
例子
python3 image_downloader.py cats.txt
登入後複製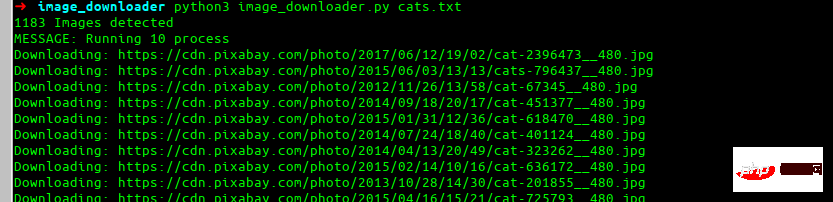

我很樂意就如何進一步改進這一點做出任何迴應。
【相關推薦:Python3視訊教學 】
以上就是怎麼使用Python進行多執行緒並行下載圖片的詳細內容,更多請關注TW511.COM其它相關文章!
