教你如何解決T+0的問題
摘要:T+0查詢是指實時資料查詢,資料查詢統計時將涉及到最新產生的資料。
本文分享自華為雲社群《巨量資料解決方案:解決T+0問題》,作者: 小虛竹 。
T+0問題
T+0查詢是指實時資料查詢,資料查詢統計時將涉及到最新產生的資料。在資料量不大時,T+0很容易完成,直接基於生產資料庫查詢就可以了。但是,當資料量積累到一定程度時,在生產庫中進行巨量資料量的查詢會消耗過多的資料庫資源,嚴重時會影響交易業務,這就不能接受了,畢竟生產交易是更關鍵的任務。所以,我們常常會把大量用於查詢分析的歷史資料從生產庫中分離出去,使用單獨的資料庫儲存和查詢,以保證查詢統計不會影響生產業務,這就是常說的冷熱資料分離。
資料分離後就會產生T+0問題。資料拆分到兩個資料庫中,要查詢全量資料就涉及跨庫查詢。而且,我們知道,用於交易的生產庫大多使用能夠保證事務一致性的RDB,而分離出來的冷資料(量大且不再修改)則會更多使用專門的分析型資料庫或資料平臺儲存,即使是關聯式資料庫也很可能與原來的生產庫型別不同,這就不僅涉及跨庫,還需要跨異構庫(源)查詢。遺憾的是,當前實現跨庫查詢的技術都存在這樣那樣的問題。
資料庫自身的跨庫查詢功能(如Oracle的DBLink、MySQL的FEDERATED、MSSQL的Linked Server等)通常是將遠端資料庫的資料拉到本地,再在本地完成包括過濾在內的大部分計算,整個過程十分低效。不僅如此,這種方式還存在資料傳輸不穩定、不支援大物件操作、可延伸性低等很多不足。
除了資料庫自身的跨庫查詢能力,使用高階語言寫死也可以完成跨庫查詢,畢竟沒有什麼問題不是寫死解決不了的。這種方式雖然靈活,但使用難度卻很大,尤其對於當前大部分應用的開發語言Java來說,缺少足夠的結構化資料計算類庫使得完成跨庫查詢後的計算很難完成,通常只能做簡單的列表式查詢,而涉及到統計彙總類的運算就會異常麻煩。
事實上,要解決分庫後的T+0查詢問題也並非難事,只要有具備這樣一些能力的計算引擎就可以實現:能夠對接多種資料來源;擁有不依賴資料庫的完善計算能力以完成多庫資料歸集後的資料計算工作;還可以利用資料庫(源)的能力充分發揮資料庫的效能;提供簡單的資料計算介面;效能相對理想等。
引入SPL
可以藉助開源SPL可以實現這些目標。SPL是一款開源資料計算引擎,提供了大量結構化資料計算函數並擁有完備計算能力,支援多資料來源混合計算,可以同時連線儲存熱資料的業務庫和儲存冷資料的歷史庫完成全量資料T+0查詢。

由於具備獨立且完善的計算能力,SPL可以分別從不同的資料庫取數計算,因此可以很好適應異構資料庫的情況,還可以根據資料庫的資源狀況決定計算是在資料庫還是SPL中實施,非常靈活。在計算實現上,SPL的敏捷語法與過程計算可以大大簡化T+0查詢中的複雜計算,提升開發效率,SPL解釋執行支援熱部署。更進一步,依託SPL的強計算能力還可以完成冷熱資料分離時的ETL任務。
SPL還提供了自有的高效能二進位制檔案儲存,對效能要求較高時可以將歷史冷資料使用檔案儲存,再借助SPL的高效能演演算法與平行計算來提升查詢效率。此外,SPL封裝了標準應用介面(JDBC/ODBC/RESTful)供應用整合呼叫,也可以將SPL嵌入應用中使用,這樣應用就輕鬆具備了T+0查詢與複雜資料處理能力,將計算和儲存分離也更符合當代應用架構的需要。
冷熱混合計算
對於常見的冷熱分庫T+0查詢場景,SPL實現很簡單,這裡看一個例子。

本例中,Oracle作為生產庫儲存當期熱資料,MySQL儲存歷史冷資料。前端傳入一句標準SQL(A2),再借助SPL的轉換功能將標準SQL轉換成對應資料庫的語法(B3)並行給資料庫查詢(B4),最後歸併結果進行最後的彙總運算(A5)。這裡使用了多執行緒並行方式(A3)同時執行兩個SQL,效率更高。
在這裡,SPL不僅完成了兩個資料庫的跨庫查詢,還提供了SQL轉換方法,更利於前端應用使用,同時擁有合併兩個資料庫計算結果後的繼續計算能力,本例是分組彙總。SPL還有更豐富的結構化資料物件及其上的豐富運算,除了分組彙總、迴圈分支、排序過濾、集合運算等基礎計算外,位置計算、排序排名、不規則分組也不在話下。
除了RDB,對於有些場景涉及的NoSQL、Hadoop等資料來源也能支援,SPL具備多源混算能力,無論基於何種資料來源都可以進行混合查詢實現T+0。比如MongoDB與MySQL混合查詢:

SPL的計算能力還能用於ETL,將生產資料轉移到歷史庫中,還經常伴隨一些轉換計算,這些都可以使用SPL來完成。比如出於某些原因,要將生產資料某些編碼欄位通過某個對照表轉換成另一種編碼(遵守一致性的編碼規則、整理資料型別獲得更好效能等),而對照表通常並不會存在生產庫中,而不能直接在生產庫中計算好,這就涉及多資料來源計算了。

高效能
歷史冷資料量可能很大,使用RDB儲存容易受到資源容量等因素限制,而且資料讀取效率很差。相比之下,檔案儲存具備很多優勢,不僅讀取效率更高,還可以有效利用檔案壓縮、並行等機制提速,同時也不會像資料庫容易受到容量的限制。不過,開放的文字格式使用效率不高(無壓縮、解析資料型別慢等),一般會使用二進位制格式檔案。另外,檔案儲存的最大問題是沒有計算能力,不像資料庫使用SQL可以很方便完成資料處理,通過寫死處理的難度很大。
這些問題都可以通過SPL來解決,SPL提供了兩種高效能二進位制資料儲存格式集檔案和組表,再借助SPL的獨立計算能力可以直接基於檔案和資料庫混合計算實現高效T+0查詢。比如前面的例子,可以使用SPL檔案儲存歷史冷資料與生產庫熱資料混合查詢。

將歷史資料儲存在檔案後與生產庫混合查詢,歷史資料使用遊標可以支援巨量資料場景,A4針對檔案遊標進行分組彙總,A5歸併資料並彙總分組結果。這裡使用了SPL提供的二進位制集檔案(btx),相對文字更加高效。集檔案採用了壓縮技術(佔用空間更小讀取更快),儲存了資料型別(無需解析資料型別讀取更快),支援可追加資料的倍增分段機制,利用分段策略很容易實現平行計算,保證計算效能。
SPL還有另外一種支援列存的高效儲存形式組表,在參與計算的列數(欄位)較少時會有巨大優勢。組表上還實現了minmax索引,也支援倍增分段,這樣不僅能享受到列存的優勢,也更容易並行提升計算效能。
SPL還支援各種高效能演演算法。比如常見的TopN運算,在SPL中TopN被理解為聚合運算,這樣可以將高複雜度的排序轉換成低複雜度的聚合運算,而且很還能擴充套件應用範圍。
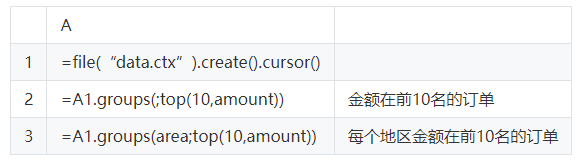
這裡的語句中沒有排序字樣,也不會產生大排序的動作,在全集還是分組中計算TopN的語法基本一致,而且都會有較高的效能,類似的演演算法在SPL中還有很多。
SPL也很容易實施平行計算,發揮多CPU的優勢。SPL有很多計算函數都提供並行機制,如檔案讀取、過濾、排序只要增加一個@m選項就可以自動實施平行計算,簡單方便。
易整合
SPL封裝了標準JDBC和ODBC介面供應用呼叫,特別對於Java應用可以將SPL嵌入應用內使用,T+0查詢能力在應用端實現,不再依賴資料來源,這樣可以充分解耦應用與資料來源,獲得很好的移植性和可延伸性。
JDBC呼叫SPL 程式碼範例:
Class.forName("com.esproc.jdbc.InternalDriver"); Connection conn =DriverManager.getConnection("jdbc:esproc:local://"); Statement st = connection.(); CallableStatement st = conn.prepareCall("{call splscript(?, ?)}"); st.setObject(1, 3000); st.setObject(2, 5000); ResultSet result=st.execute();
SPL是解釋執行的,天然支援熱切換。基於SPL的資料計算邏輯編寫、修改後不需要重啟,實時生效,使開發運維更加便捷。
相對其它T+0實現技術,SPL藉助自身獨立的強計算與跨資料來源計算能力可以更方便完成T+0查詢,同時提供的高效能儲存和高效能演演算法可以充分保障查詢效率,良好的整合性使得應用端可以輕鬆具備這些能力,是名副其實的T+0查詢利器。
參考資料