從小白到架構師(3): 揭開分散式資料庫的面紗
「從小白到架構師」系列努力以淺顯易懂、圖文並茂的方式向各位讀者朋友介紹 WEB 伺服器端從單體架構到今天的大型分散式系統、微服務架構的演進歷程。「從小白到架構師」 系列的前兩篇中多次提到各類分散式資料庫,第三篇文章「揭開分散式系統的面紗」我們從基本的分庫出發,來一一探索構建高可靠、高效能分散式資料庫路上遇到的難題。
分散式系統是由一組通過網路進行通訊、為了完成共同的任務而協調工作的計算機節點組成的系統。從概念上說,將業務伺服器和資料庫部署在兩臺伺服器上並通過 tcp 連線便組成了一個最簡單的分散式系統。當然這樣的分散式系統並沒有研究的意義,我們研究分散式系統是為了解決實際問題:
- 是為了用廉價的、普通的機器完成單個計算機無法完成的計算、儲存任務。
- 通過多機備份避免單機故障
- 通過增加或減少機器數量靈活調整系統的吞吐量
在本系列中我們已經提到過很多分散式儲存系統了, 比如高可靠的 Etcd、ZooKeeper 前面提到的 TiDB 資料庫。無論這些資料庫看上去多麼 fancy 他們的思路歸根到底無外乎資料分片和副本。
資料分片
我們在「應對高並行」一文中提到過的分庫分表便是資料分片思想最直觀的展現:
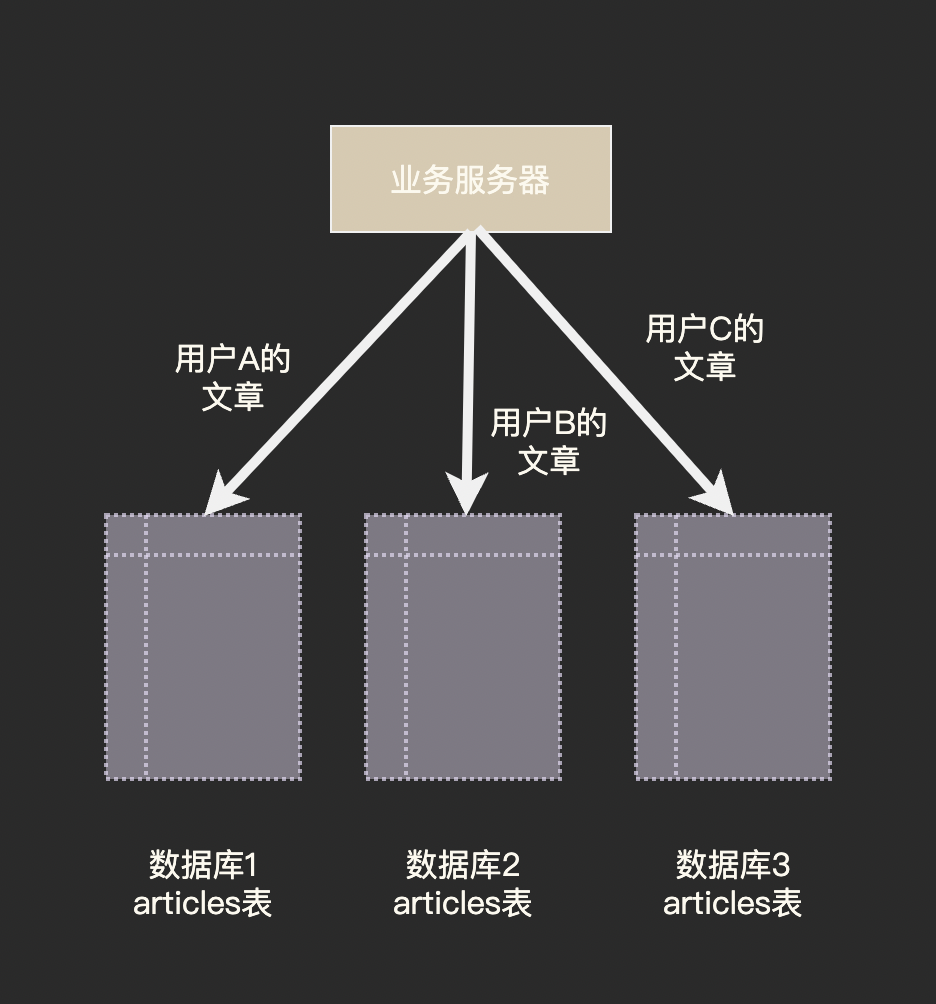
資料分片的核心是分片策略,即如何決定一條資料應該放到哪一個分片中。
首先要決定根據哪個欄位進行分片,我們將這個決定分片的欄位稱為分片鍵(partition key), 在上圖的範例中使用者 ID 就是我們的分片鍵。
對於關係型資料庫而言,通常在建立資料表時指定分片鍵,比如 Cassandra 和 TiDB 都需要在建表時指定分片鍵,對於 Redis 這類 KV 結構資料庫來說只有一個 key 可以用來做分片鍵了。
CREATE TABLE articles (
id INT NOT NULL PRIMARY KEY,
uid INT,
title VARCHAR(60),
content TEXT,
create_time DATE NOT NULL DEFAULT '1970-01-01',
)
PARTITION BY HASH(uid) // TiDB 建表語句,按照 store_id 進行 hash 分割區
PARTITIONS 3;
決定分片鍵後,就需要將分片鍵對映到節點上。最簡單的方法是通過雜湊 hash(partition_key) % db_num, 還有一種常用的方法是號段法(Range),即 partition key 1~1000 的在節點A、1000~2000的在節點 B……
雜湊分片的好處在於資料均勻分佈,單個節點的負載不會太大;而號段法則可能將一段時間內產生的資料都集中在一個分片上(特別是 partition key 為自增或由 snowflake 演演算法生成時),從另一個方面看某個時間段內的資料都集中在一個分片更便於進行範圍查詢或者統計分析,比如儲存交易資料時就可以採用號段法。
麻煩才剛剛開始
再平衡
看上去資料分片就是把資料分散到多臺機器上,但是分散式系統中的節點並不是固定的,有些節點會下線,有時候需要新增新的節點。 觀察 node_id = hash(partition_key) % node_num 這個公式我們發現只要 node_num 發生變化, 幾乎所有 partition_key 所屬的 node_id 都會改變。
這意味著幾乎所有資料都需要從一個節點搬到另一個節點,可想而知這樣的資料遷移會消耗巨量的資源和時間,而且在遷移過程中的分片幾乎是無法運作的。在分散式資料庫領域我們把這種將負載從叢集中的一個節點向另一個節點移動的過程稱為再平衡(rebalancing)。
為了緩解資料再平衡的壓力,一致性雜湊演演算法應運而生。一致性雜湊不再使用取餘的方法決定 node_id, 而是將整數空間連成一個環將 node_id 雜湊後放在環上, partition_key 同樣雜湊後放到環上,從 partion_key 的位置開始沿著環順時針行走遇到的第一個節點就是 partition_key 所屬的節點。
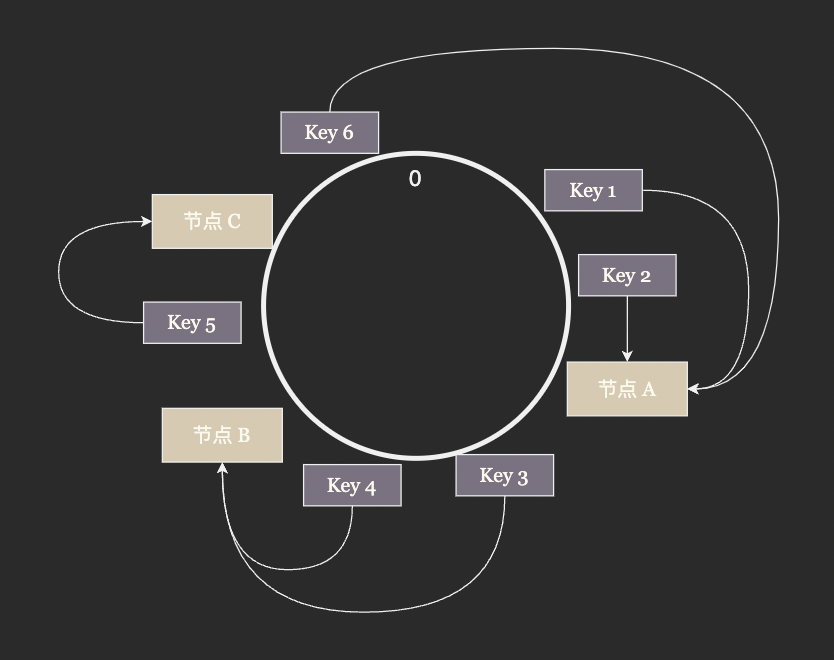
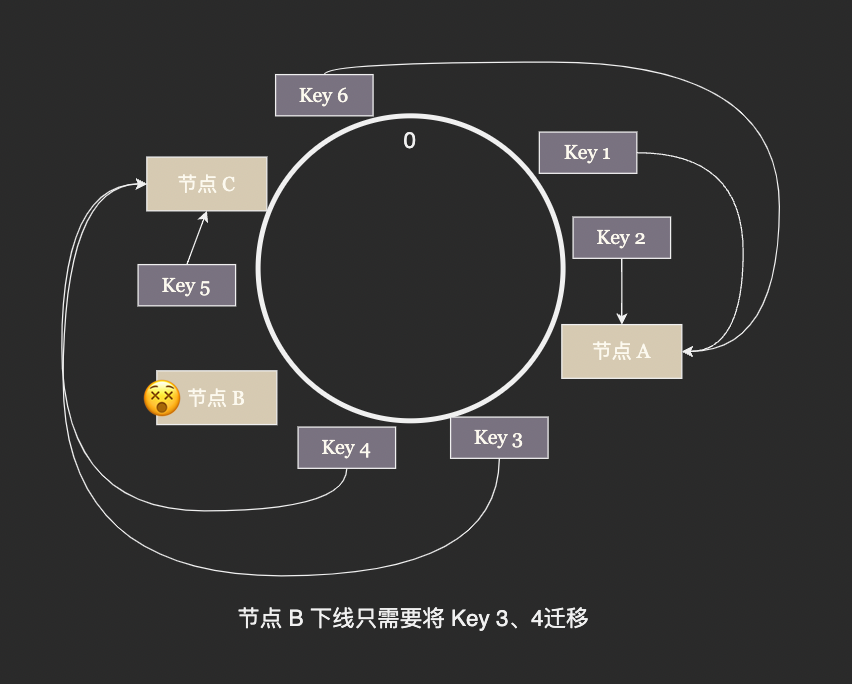
這樣環上的 node_id 將整個雜湊空間分成了若干段,每次有節點加入只需要將原來的一段分成兩段,有節點退出時只需要將兩段合併成一段,極大的減少了 rebalancing 需要遷移的資料量。
跨節點查詢
我們已經習慣了使用 SQL 來運算元據庫,我們建立一個按班級分片的成績表:
CREATE TABLE grades (
student_id INT NOT NULL PRIMARY KEY,
class_no INT,
score INT,
)
PARTITION BY HASH(class_no)
PARTITIONS 20;
然後嘗試查詢全校前 10 名的學號:
select student_id from grades order by score desc limit 5 offset 5;
這裡麻煩就麻煩就在分頁器 limit 5 offset 5 上,全校第 10 名可能是自己班的第 1 名也有可能是自己班的第 10 名, 某個班可能沒有一個學生是全校前 10 名,也有可能全校前 10 名都在同一個班中。
總之他們的分佈完全隨機,我們只能保證全校前 10 名一定是自己班級的前 10 名。 所以我們的解決方案是先把每個班的前 10 名都查出來,把他們混合在一起重新排序,在重新排序的表中找出全校第 5 到 10 名:

分散式事務
我們剛剛討論了跨表查詢在邏輯上的難點,然而與跨表寫入相比,查詢時小小邏輯問題可以說是微不足道了。
資料庫作為一個並行系統,我們強烈依賴其事務機制提供的 ACID 保證。以經典的轉賬操作為例,事務機制要提供如下保證:
- Atomicity 原子性:轉賬操作要麼完成要麼沒有開始,不允許出現一方扣款另一方未收款的情況。
- Consistent 一致性:任何賬戶的餘額都不應該為負數。
- Isolation 隔離性:其它事務不應該看到一方扣款另一方未收款的情況。
- Durability 永續性:轉賬操作一旦完成,對資料的修改就是永久的,即便系統故障也不會丟失。
在此例子中隔離性與原子性的表現類似,隔離性強調其它事務不應該看到執行了一半的狀態,原子性強調執行過程不可分割、不可被其它操作插入
我們設計一個賬戶餘額表並按照賬戶ID進行雜湊分片, 若我們要對分佈在不同節點(分庫)上的兩個賬戶進行轉賬,那應該如何操作呢?
第一種思路被稱為 TCC (try-confirm-catch) 事務,TCC 事務分為三個階段:
- Try 階段: 事務協調器要求參與方完成所有一致性檢查然後預留並鎖定事務所需資源;
- Confirm 階段: 若所有參與方都表示資源充足可以提交,事務協調器會向所有參與方發出 Confirm 指令,要求實際執行事務。 Confirm 階段只確認修改生效,不作任何業務檢查,只使用Try階段預留的資源,
- Cancel 階段: 若 Try 或 Confirm 階段任一參與者表示無法繼續事務協調器會向所有參與方發出 Cancel 指令解鎖預留資源並回滾事務。
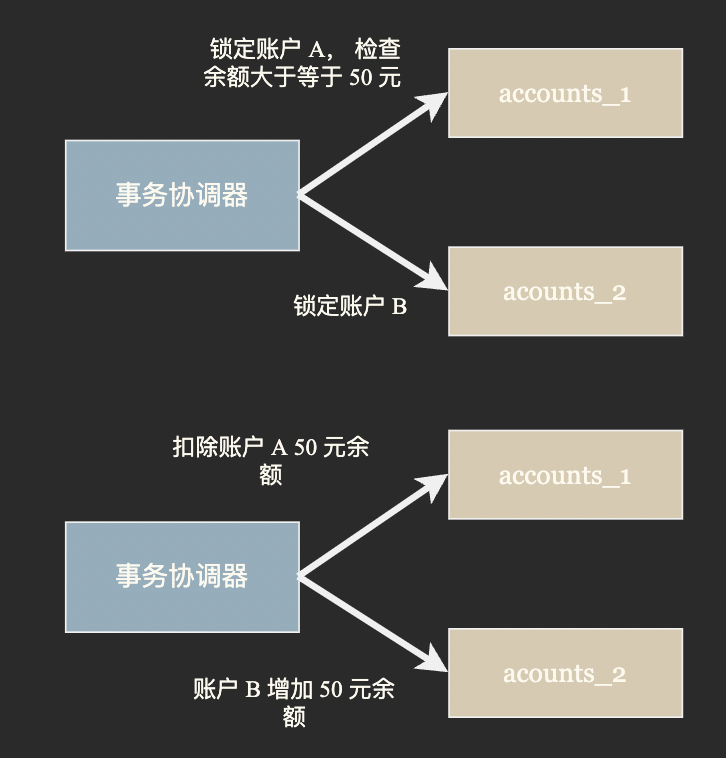
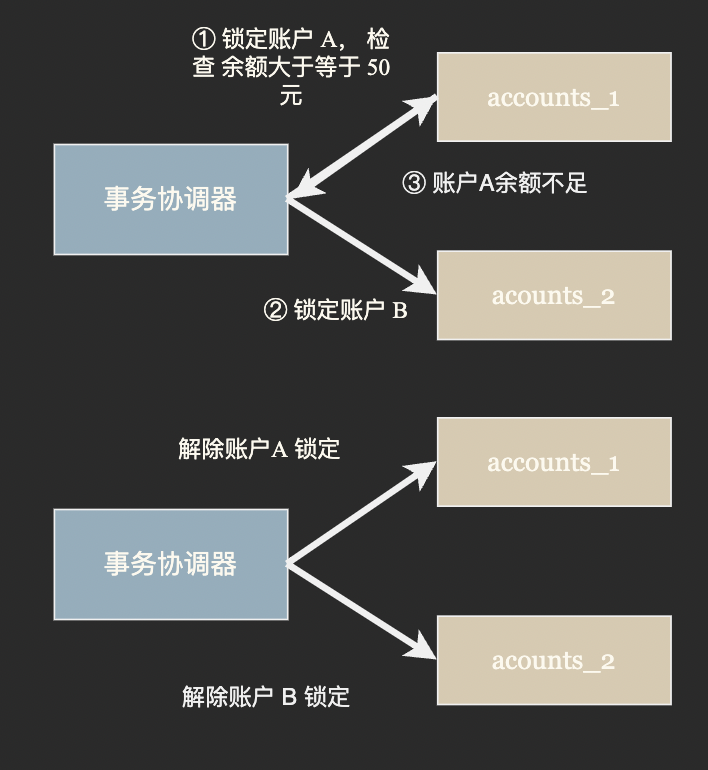
由於 TCC 事務在 Try 階段就進行了鎖定,隔離性和一致性相對較好。同時由於鎖定了資源會阻止其它事務進行,會損失一些吞吐量。
第二種實現思路的典型代表是 Saga 事務,Saga 事務將一個大事務拆分成多個有序的子事務,並且每個子事務都準備了復原操作,事務協調器會順序的執行子事務,如果某個步驟失敗,則根據相反順序一次執行一次復原操作。
Saga 事務的問題顯而易見,一是在實際執行前沒有進行檢查,有些子事務一旦執行便無法復原;二是子事務提交之後便立刻生效,其它事務可以看到事務執行了一半的狀態,隔離性比較差。
副本
我們開篇時提到使用分散式系統的目的之一是:通過多機備份提高系統的可靠性。在《應對高並行》一文中我們提到可以搭建從庫一方面作為熱備,另一方面做為讀寫分離緩解主庫的的負載。
那麼現在的問題是從庫是如何主庫保持同步的呢?通常主從同步由兩個步驟組成:快照複製+紀錄檔傳播。這裡我們以 KV 結構的 Redis 進行說明。
資料庫中所有的資料修改都是由寫命令引起的,那麼我們只要將主庫收到的寫命令按照原來的順序傳送到從庫再次執行一遍就可以保持兩者同步了:
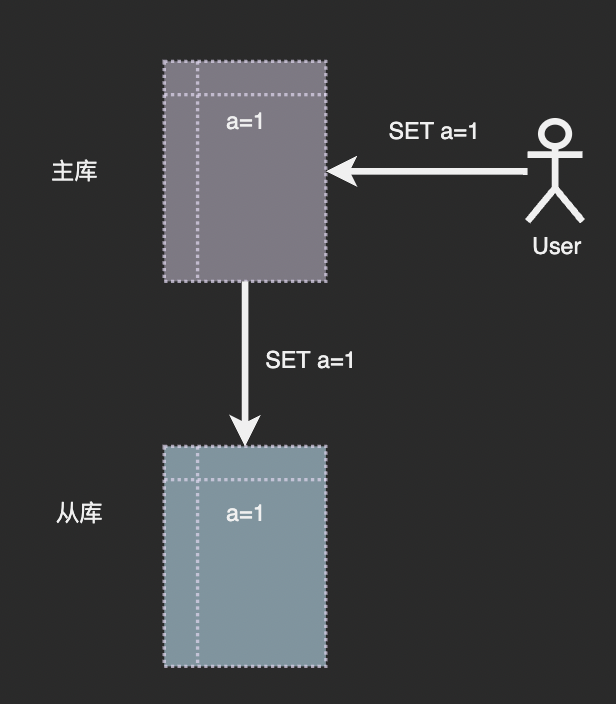
從理論上說這麼做沒有問題,但是大多數情況下從庫不是在主庫啟動後便一直跟隨。若主庫已經執行了一段時間並積累了相當規模的資料,此時再為其新增從庫會有什麼問題嗎?
寫命令的資料量十分巨大,儲存和傳輸完整的寫入紀錄檔是非常浪費資源和時間的做法。而且很多寫命令是無用的,比如我們對一行記錄進行了多次 update 最後將其刪除,那麼這行記錄的 insert、update、delete 命令都不需要同步到從庫。
所以在很多資料庫的主從複製流程中主庫會定期生成快照,當有新的從庫加入時首先將快照傳送給從庫,然後將快照生成後紀錄檔持續複製到從庫。如此便避免了儲存和傳輸完整紀錄檔.
在分散式資料庫中資料分片和從庫(或者說是副本)通常結合使用。以 Redis 叢集為例,資料通過一致性雜湊演演算法分佈在主節點上,每個主節點部署有若干個從節點。當叢集發現某個主節點崩潰時便將它的一個從節點提升為主節點,代替崩潰的主節點繼續工作:
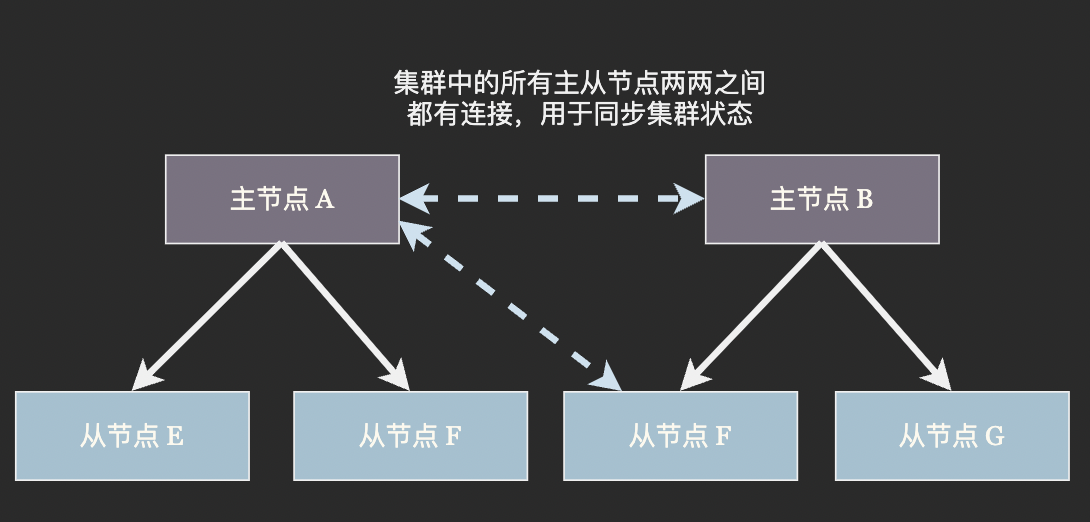
在另外一些資料庫中並沒有主節點和從節點之分,而是在一個節點中存在著若干個主分片(primary partition)和從副本分片(replica partition)。當叢集發現某個節點崩潰後,剩餘的節點會挑選一個從分片接替主分片。Cassandra、ElasticSearch 等資料庫均使用這種節點平等的架構。
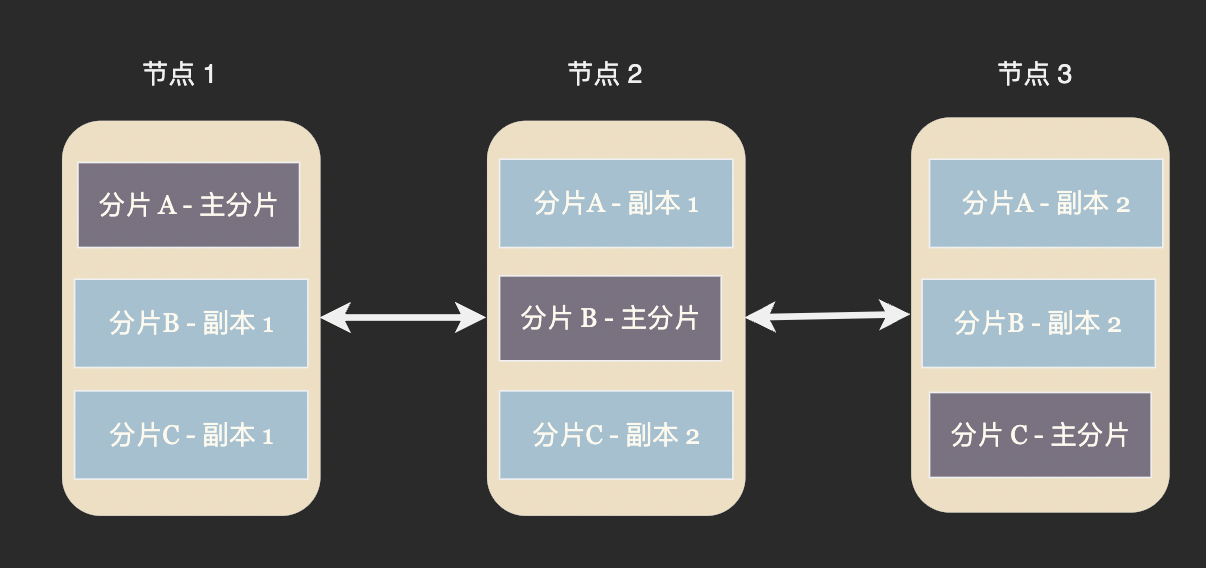
在 redis 叢集中從節點只負責寫不負責讀,這其實也是一種資源的浪費,雖然對於寫入吞吐量超高的記憶體資料庫來說這種浪費無傷大雅。但對於 Cassandra 這些需要持久化的資料庫來說磁碟 IO 資源非常有限,所以每個節點都會承擔部分寫任務來提高系統整體的吞吐量。
副本帶來的錯誤資料風險
雖然主節點將紀錄檔持續傳送給從節點,但是網路傳輸和從節點執行紀錄檔中的命令是需要時間的,就是說從節點的資料和主節點並不完全一致,而可能是幾十毫秒前的狀態。
回顧一下上面討論過的分散式事務,如果主節點剛剛提交了某個事務,在新資料同步到從節點前便崩潰了,在從節點被提升為主節點之後資料庫中便出現了錯誤的資料:
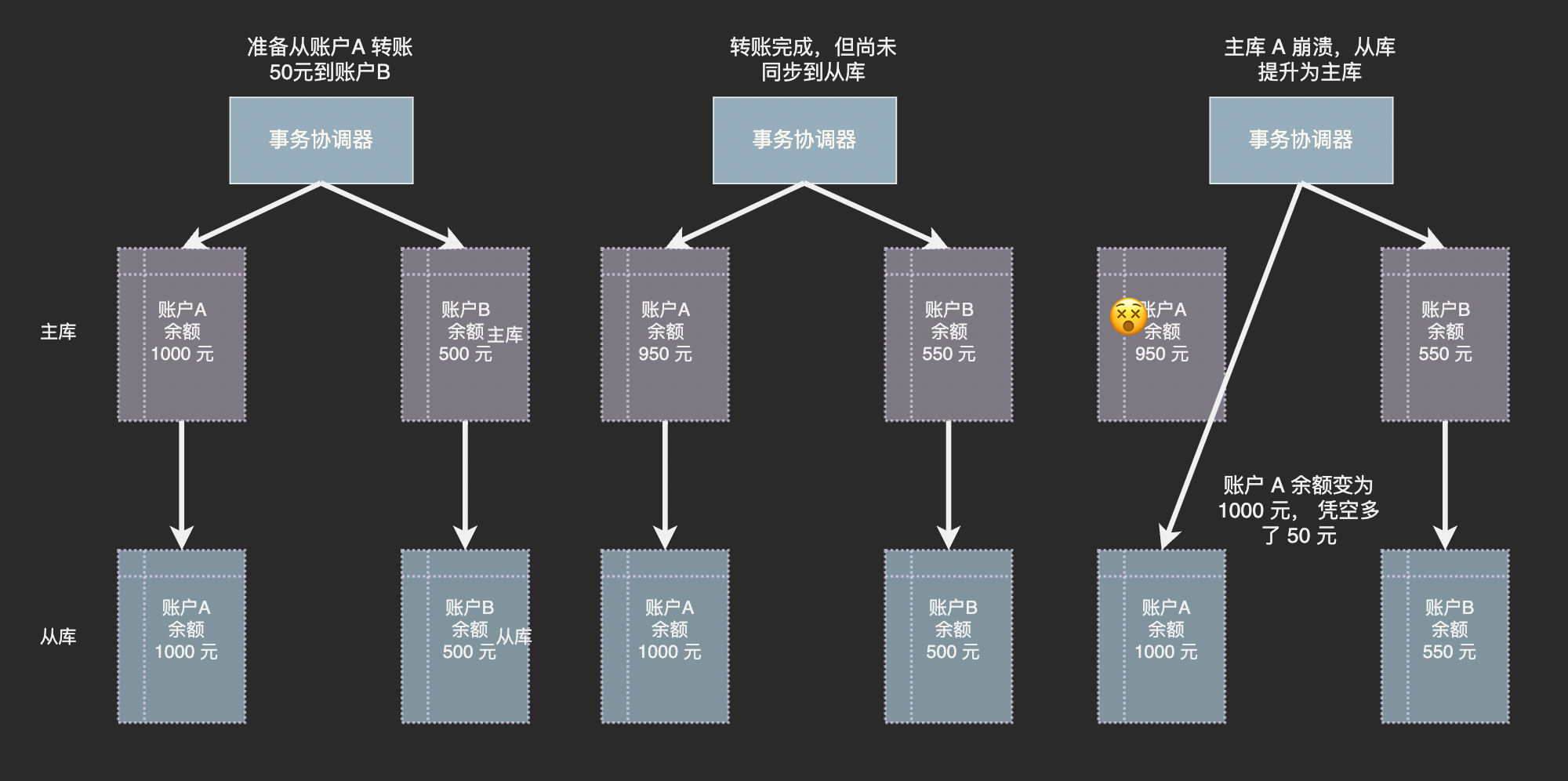
誰是 Master?
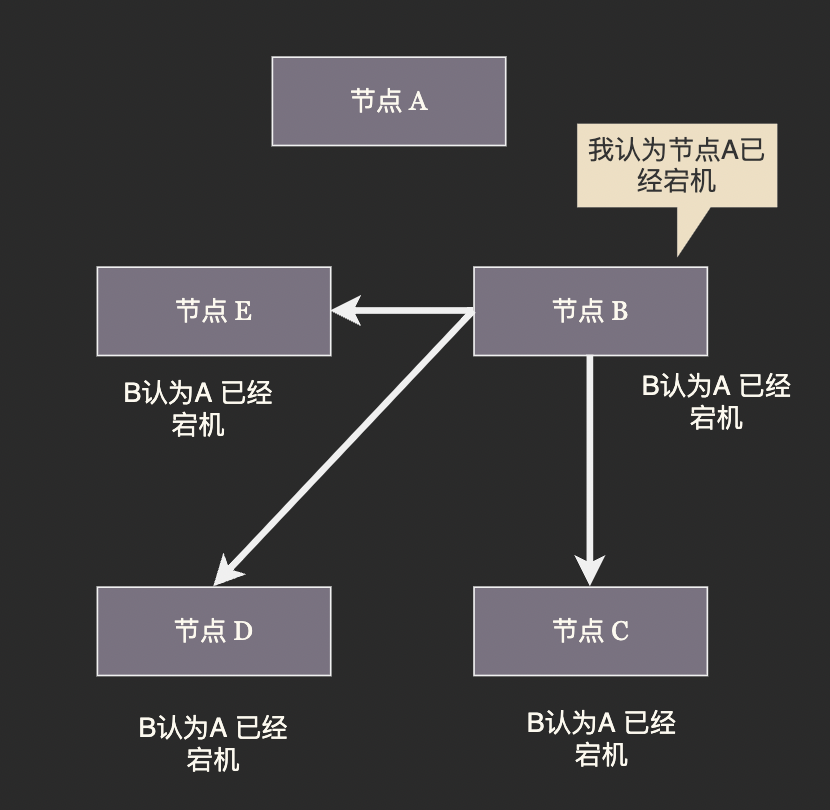
在剛才我們對副本的討論中提到當叢集發現某個節點崩潰後會將從節點(副本)提升為主節點,這裡的重點不在於「主節點是否崩潰」而是叢集如何確認它已經崩潰。
分散式系統的節點之間通過網路進行通訊,而網路是不可靠的。某個從節點發現主節點停止響應並不一定是主節點宕機,而可能是自己與主節點之間的網路中斷了。若某個從節點認為原來的主節點宕機然後將自己提升為新主節點,那麼叢集中就會出現兩個主節點。兩個主節點各自寫各自的資料,顯而易見的會發生嚴重的資料衝突。我們將這種叢集中出現多個主節點的故障稱為「腦裂」:
因此進行主從切換的關鍵在於讓所有節點對於主節點是否崩潰、應給提升哪個從節點作為新的主節點達成共識。(至於原來的主節點是否真的崩潰了並不重要,重要的是叢集都認為它下線了。
Gossip 協定
Gossip 意為流言,它的原理也非常簡單:每個節點定時將自己檢測到的其它節點的狀態在叢集內廣播,當某個節點收到過半節點廣播了同一條訊息時,它遍認為這條訊息是真實的。

我們發現 Gossip 對網路節點的連通性和穩定性幾乎沒有任何要求;能夠容忍網路上節點的隨意地增加或者減少,隨意地宕機或者重啟,新增加或者重啟的節點的狀態最終會與其他節點同步達成一致。Gossip 把網路上所有節點都視為平等而普通的一員,沒有任何中心化節點或者主節點的概念,這些特點使得 Gossip 具有極強的健壯性。
Gossip 的缺點同樣顯而易見,它需要經過數輪的廣播才能讓所有節點達成共識,在達成共識之前必然存在各節點認知不一致的情況。為了避免認知不一致造成腦裂進而出現資料錯誤,Redis 叢集的 gossip 協定需要經過多輪協商才能選出新的主的節點, 在協商過程中故障主節點上的分片是無法進行寫入的。
這個過程可以簡單的分為下列幾步:
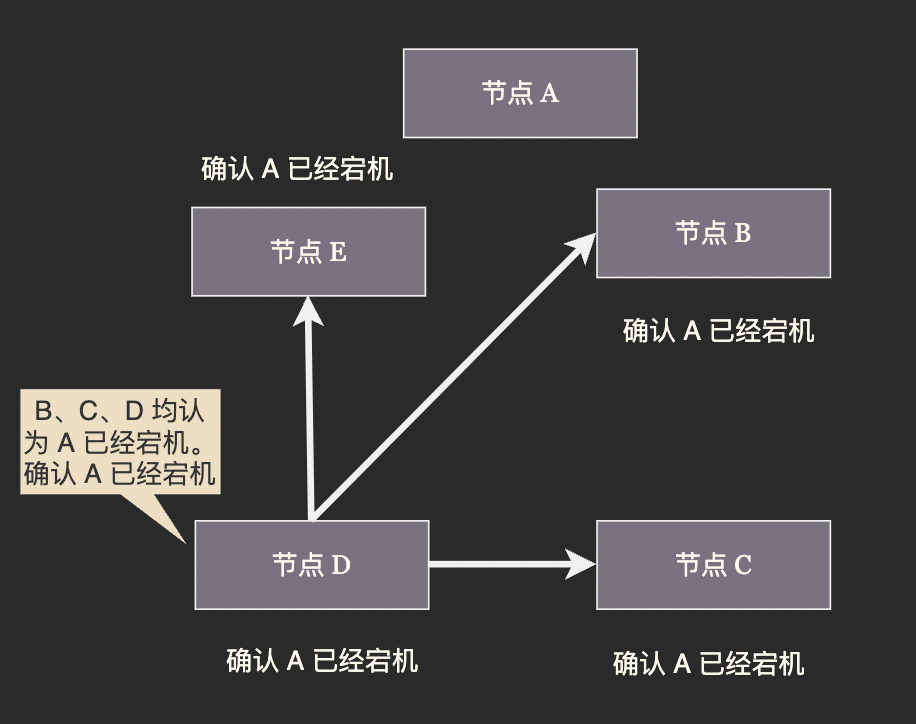
疑似下線
某些節點發現主節點 A 停止響應,便將其標記為「疑似下線」狀態, 並在隨後的 Gossip 廣播中通告疑似下線的訊息。

下線判決
當一個節點收到過半節點通報的 「A 疑似下線」 訊息後,便做出 A 已經下線的判決。A 下線的判決會盡快通過 Gossip 廣播通知所有節點,收到 A 下線判決的節點會立即將 A 標記為下線,而不再關注 「A 疑似下線的訊息」。這樣做是為了減少達成共識所需的時間。
演演算法正常工作要求叢集中不存在惡意節點,節點可能因為自身視角原因無法做出判斷但不會故意發出錯誤資訊。因此任意一個節點都可以做出下線判決。
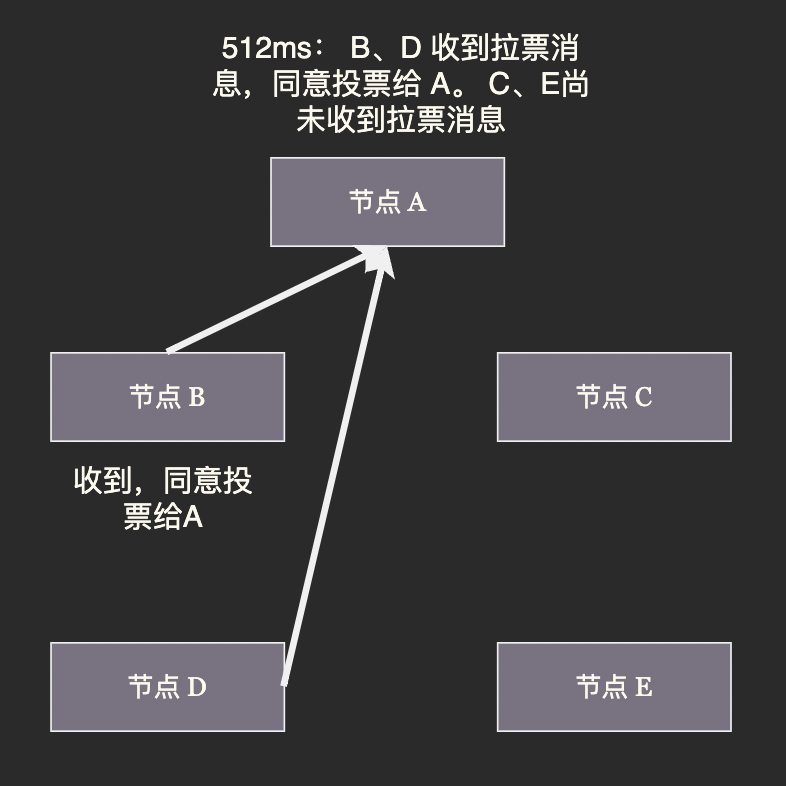
新主節點選舉
從節點在收到其主節點的下線判決時會等待一段時間,然後向叢集廣播一條請求訊息,請求所有收到這條訊息並且具有投票權的主節點給自己投票。
這段等待時長根據下面的公式決定:
500ms + random()%500ms + rank*1000ms
其中,固定延時 500 ms 是為了確保下線判決能傳播到叢集中其他節點;隨機延時為了避免兩個從節點同時拉票造成最終無人得票過半,不得不進行下一輪投票。
選舉演演算法的目標是儘快選出新的主節點,至於誰當選並不重要。
rank 是拉票的從節點在下線主節點的所有從節點中的排名,排名根據主從同步程序而定,資料越新(和主節點資料最為接近)的從節點當選新主節點的概率越高


確認選舉結果
若某一個從節點收到了過半的選票,則會當選為新一任主節點,若一輪投票結束沒有從節點選票過半則進入下一次投票。
要求選票過半才能當選而不是隻要得票最高就可以直接當選,是因為叢集中最多有一個節點能獲得過半選票,這樣設計徹底封死了腦裂的可能。

選舉完成後新當選的從節點會將自身切換為主節點模式,原主節點的其它從節點會與新主節點建立連線。至此叢集從故障中恢復。
Redis Cluster、Consul 和 Cassandra 都是使用 Gossip 協定的知名軟體。
Raft 協定
與去中心化的 Gossip 協定相對,Raft 協定是一種中心化的分散式共識協定。Raft 叢集中的每個節點可能處於 Leader、Follower、Candidate 三種狀態之一。Raft 協定有 Leader Selection(領導節點選舉) 和 Log Replication (紀錄檔複製)兩部分組成。
Raft 叢集中最多有一個 Leader, 叢集中所有寫入操作都由 Leader 負責。 一次寫入的過程是這樣的:
- 使用者端將更改提交給 Leader, Leader 會在自己的紀錄檔中寫入一條未提交的記錄(Entry)
- 在下一次心跳時 Leader 會將更改傳送給所有 Follower
- 一旦收到過半節點的確認 Leader 就會提交自己紀錄檔中的記錄並向用戶端返回寫入成功
- Leader 會在下一次心跳時通知所有節點提交紀錄檔
https://img2020.cnblogs.com/blog/793413/202102/793413-20210228163354456-964717881.png
這個過程我們稱為紀錄檔複製。由於在紀錄檔複製到過半節點後才返回成功,所以即使主節點返回成功後宕機某個 Follower 成為新的主節點,它也可以通過自己的紀錄檔恢復這條資料。
Leader 會定時向 Follower 廣播心跳包,在叢集執行過程任何一個 Follower 出現心跳超時都會引發新一輪選舉。Raft 的選舉策略和我們剛剛介紹的 Redis 叢集的選舉策略可以說是一模一樣。
當 Follower 發現 Leader 超時便會隨機等待一段時間,然後轉變為 Candidate 向其它節點傳送拉票資訊。收到拉票請求的其它 Follower 會根據投票輪數、自己是否已經投票、Candidate 的紀錄檔條數來決定投票給誰。當一個 Candidate 獲得超過半數的選票後便會成為新任的 Leader.

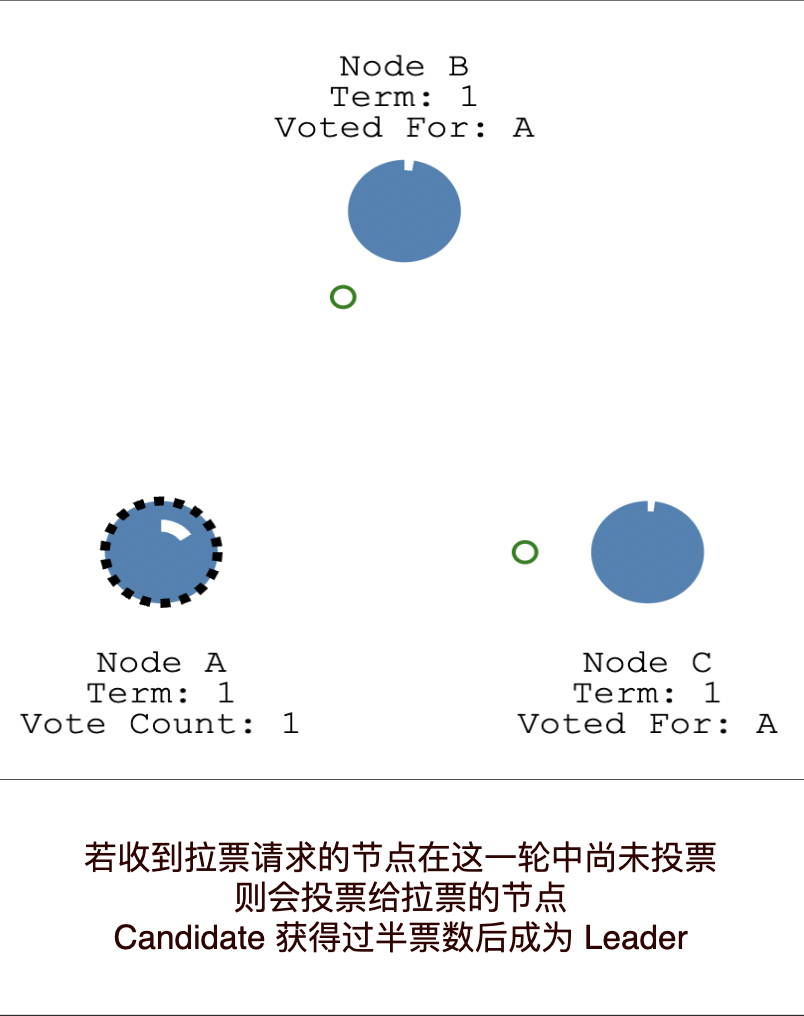
The Secret Lives of Data-CN 以圖文方式介紹 Raft 演演算法,是非常好的入門材料。將其閱讀完後您應該已經瞭解了 Raft 演演算法。
如果您還有疑惑 Raft Scope 是 Raft 官方提供的互動式演示程式,它展示了 Raft 叢集的工作狀態。您可以用它模擬節點宕機、心跳超時等各種情況。有了 Raft Scope 我們可以親自「動手」 觀察 Raft 叢集是如何工作、如何處理各種故障的。Raft Scope 缺少說明,若在使用中遇到困難您可以閱讀這篇說明:看動畫輕鬆學會 Raft 演演算法。
Multi Raft
與 Gossip 通常只用來同步宕機、主從切換等叢集元資訊不同,Raft 協定不僅負責 Leader 選舉也規定了如何將資料同步到副本定義了一個完善的分散式儲存模型。
一個 Raft 組中只有一個 Leader 可以處理寫請求,我們在資料分片一節中提到這樣做比較浪費資源。解決方案也比較類似,將叢集劃分成多個 Raft 組,並且儘量讓每個 Raft 組的 Leader 分佈在不同的節點上。
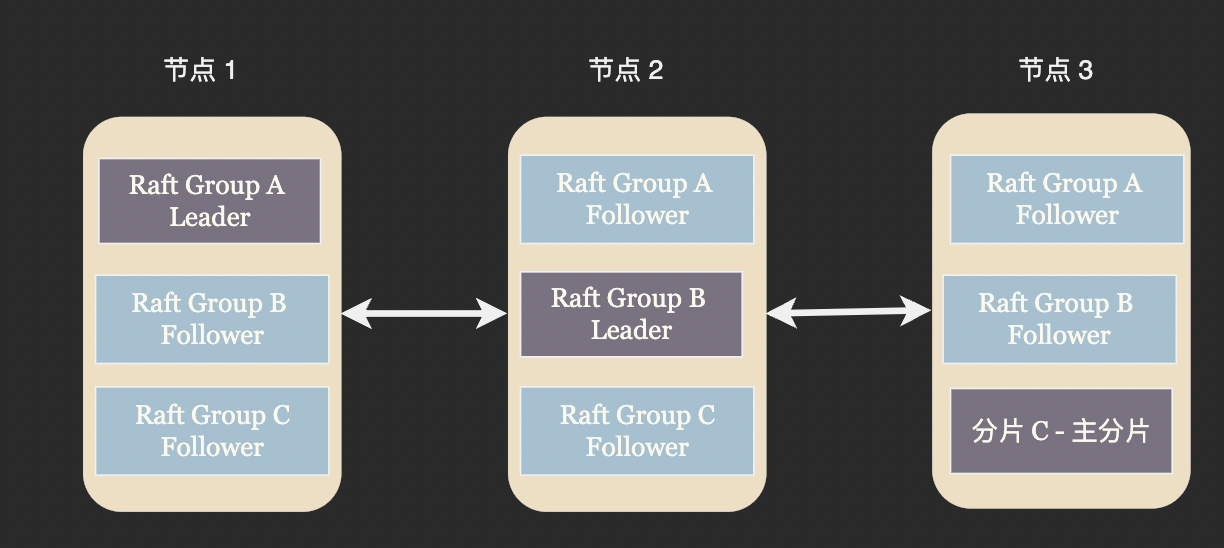
ZooKeeper、Etcd 等分散式設定中心由於一致性要求較高,吞吐量要求較低通常採用單 Raft 實現,而 TiDB 這類高一致性的資料庫則通常使用 Multi Raft.
總結
分散式資料庫將資料劃分為多個分片儲存在多臺機器上, 採用分而治之的思路處理單機資料庫儲存不了、處理不完的資料。在進行資料分片之後我們發現讀寫都出現了額外的額外的麻煩,比如很難繼續維持事務的 ACID 特性。為此我們嘗試通過 Try-Confirm-Catch 或者 Saga 演演算法來在分散式資料庫中保持事務的原子性。
單臺伺服器總會故障,因此我們為資料設定了副本,以便在主節點故障時將副本提升為新的主節點維持系統的正常工作。此時我們發現由於網路不可靠,叢集難以就某個節點是否宕機達成共識。我們為解決分散式共識問題引入 Gossip 和 Raft 兩個演演算法。
Gossip 演演算法通過廣播的方式將叢集的最新狀態通知到每個節點,Gossip 對網路質量幾乎沒有要求也沒有中心節點,健壯性比較好。但由於需要幾輪廣播才能在叢集中達成共識,中間不可避免的存在不一致的狀態。所以我們需要在上層構建相應的策略通過多輪廣播來避免不一致狀態造成資料錯誤。
Raft 演演算法則是中心化的分散式一致性解決方案,它巧妙的通過隨機延時的方法來進行 Leader 選舉,這種選舉方式也被 Redis Cluster 等使用 Gossip 協定的分散式系統使用。Raft 不僅定義瞭如何選舉 leader, 也定義瞭如何將資料變更同步到副本,以在主從切換後保證不丟失資料。