機器學習實戰-AdaBoost
2022-10-26 12:03:49
1.概念
從若學習演演算法出發,反覆學惡習得到一系列弱分類器(又稱基本分類器),然後組合這些弱分類器構成一個強分類器。簡單說就是假如有一堆資料data,不管是採用邏輯迴歸還是SVM演演算法對當前資料集通過分類器data進行分類,假如一些資料經過第一個分類器之後發現是對的,而另一堆資料經過第一個分類器之後發現資料分類錯了,在進行下一輪之前就可以對這些資料進行修改權值的操作,就是對上一輪分類對的資料的權值減小,上一輪分類錯的資料的權值增大。最後經過n個分類器分類之後就可以得到一個結果集
注意:adaboost演演算法主要用於二分類問題,對於多分類問題,adaboost演演算法效率在大多數情況下就不如隨機森林和決策樹
要解決的問題:如何將弱分類器(如上描述每次分類經過的每個分類器都是一個弱分類器)組合成一個強分類器:加大分類誤差小的瑞分類權值減小分類誤差大的弱分類器權值

1.1舉例分析



2.決策樹,隨機森林,adaboost演演算法比較
以乳腺癌為例來比較三種演演算法2.1 載入資料
#使用train_test_split將資料集拆分
from sklearn.model_selection import train_test_split
#將乳腺癌的資料匯入,return這個引數是指匯入的只有乳腺癌的資料
#如果沒有引數,那麼匯入的就是一個字典,且裡面有每個引數的含義
X,y=datasets.load_breast_cancer(return_X_y=True)
#測試資料保留整個資料集的20%
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size= 0.2)
2.2使用決策樹
score=0
for i in range(100):
model=DecisionTreeClassifier()
#將訓練集資料及類別放入模型中
model.fit(X_train,y_train)
y_ =model.predict(X_test)#預測測試集裡的資料型別
score+=accuracy_score(y_test,y_)/100
print("多次執行,決策樹準確率是:",score)
執行結果

2.3隨機森林
score=0
for i in range(100):
#隨機森林的兩種隨機性:一種是隨機抽樣,另一種是屬性的隨機獲取。而決策樹只有隨機抽樣一種隨機性
model=RandomForestClassifier()
#將訓練集資料及類別放入模型中
model.fit(X_train,y_train)
y_ =model.predict(X_test)#預測測試集裡的資料型別
score+=accuracy_score(y_test,y_)/100
print("多次執行,隨機森林的準確率為是:",score)

2.4adaboost自適應提升演演算法
score=0
for i in range(100):
model=AdaBoostClassifier()
#將訓練集資料及類別放入模型中
model.fit(X_train,y_train)
y_ =model.predict(X_test)#預測測試集裡的資料型別
score += accuracy_score(y_test,y_)/100
print("多次執行,adaboost準確率是:",score)

3.手撕演演算法
adaboost三輪計算結果
在程式碼中的體現就是X[i]的值
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn import tree
import graphviz
X=np.arange(10).reshape(-1,1)#二維,機器學習要求資料必須是二維的
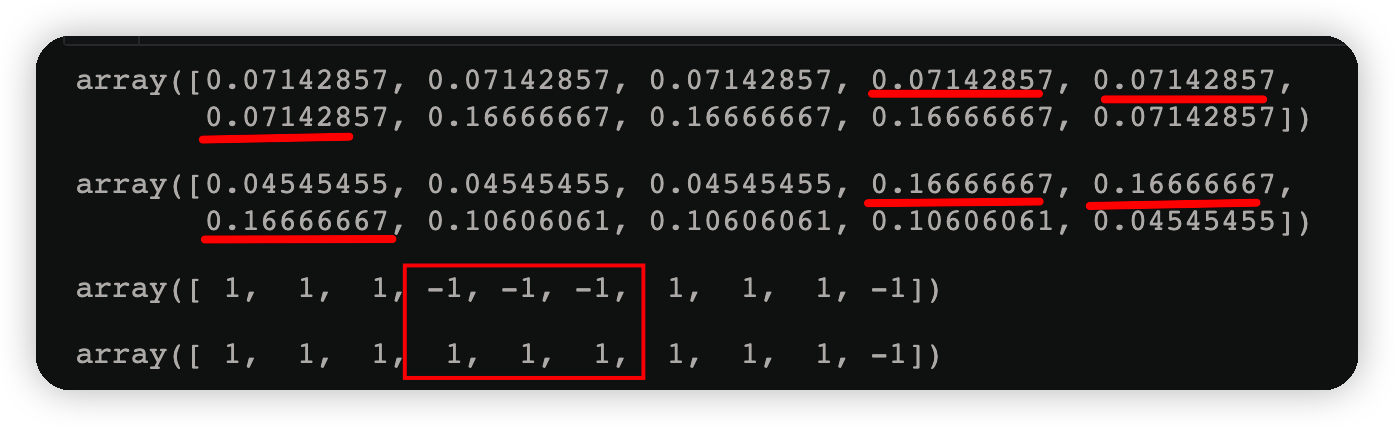
y=np.array([1,1,1,-1,-1,-1,1,1,1,-1])
display(X,y)
display(X,y)執行結果如下圖

# SAMME表示構建樹的時候,採用相同的裂分方式
#n_estimators表示分裂為三顆樹
model = AdaBoostClassifier(n_estimators=3,algorithm='SAMME')
model.fit(X,y)
y_=model.predict(X)
第一顆樹的視覺化
dot_data=tree.export_graphviz(model[0],filled=True,rounded=True)
graphviz.Source(dot_data)
執行結果

第二棵樹的視覺化
dot_data=tree.export_graphviz(model[1],filled=True,rounded=True)
graphviz.Source(dot_data)
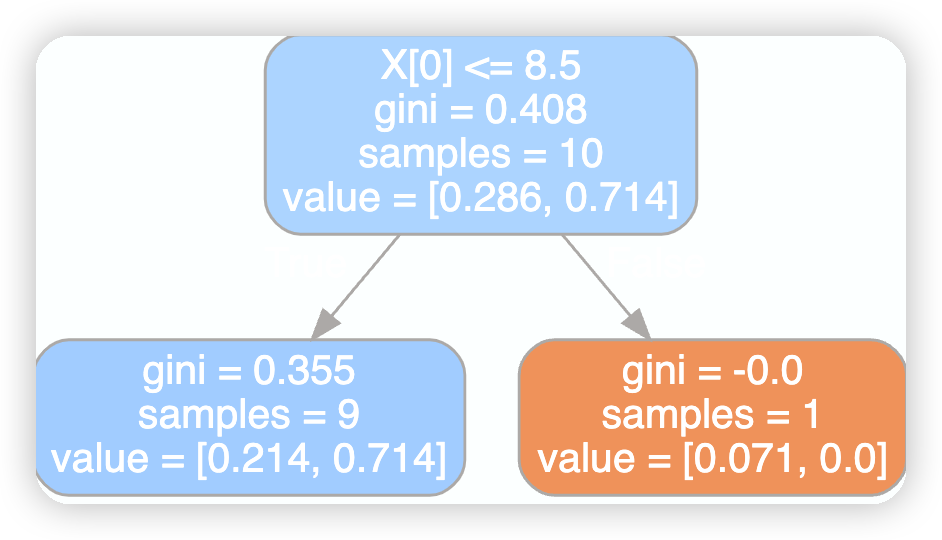
第三課樹的視覺化
dot_data=tree.export_graphviz(model[2],filled=True,rounded=True)
graphviz.Source(dot_data)

3.1第一輪
3.1.2gini係數的計算
此處計算的X[i]的值也就是v的值w1=np.full(shape=10,fill_value=0.1)#初始的樣本權重
cond=y ==1 #類別1條件
p1 = w1[cond].sum()
p2= 1-p1
display(p1,p2)
gini=p1*(1-p1)+p2*(1-p2)
上圖可知第一棵樹的X[0]=2.5的由來方式如下程式碼如實現
gini_result=[]
best_split={}#最佳分裂條件,X[0]<=2.5
lower_gini = 1#比較
for i in range(len(X)-1):#陣列下標從0到9,10個資料一共要切九刀
split=X[i:i+2].mean()#裂開條件,就是假如一開始要將0和1裂開並取出
cond=(X<=split).ravel()#變成一維的,左邊資料
left=y[cond]
right=y[~cond]#取反
#左右兩邊的gini係數
gini_left=0
gini_right=0
for j in np.unique(y):#y表示類別
p_left=(left==j).sum()/left.size#計算左邊某個類別的概率
gini_left=p_left*(1-p_left)
p_right=(right==j).sum()/right.size#計算右邊某個類別的概率
gini_right=p_right*(1-p_right)
#左右兩邊的gini係數合併
left_p=cond.sum()/cond.size
right_p=1-left_pc
gini=gini_left*left_p + gini_right*right_p
gini_result.append(gini)
if gini <lower_gini:
lower_gini=gini
best_split.clear()
best_split['X[0]<=']=split
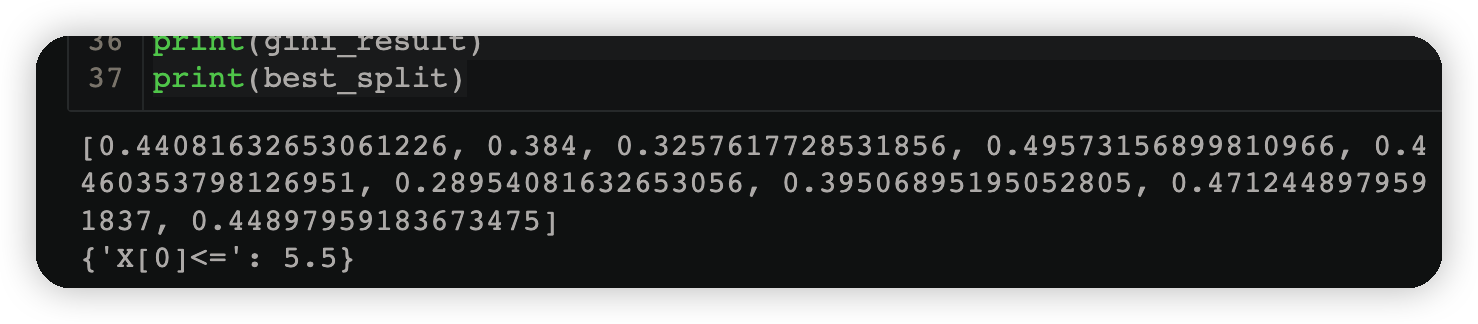
print(gini_result)
print(best_split)
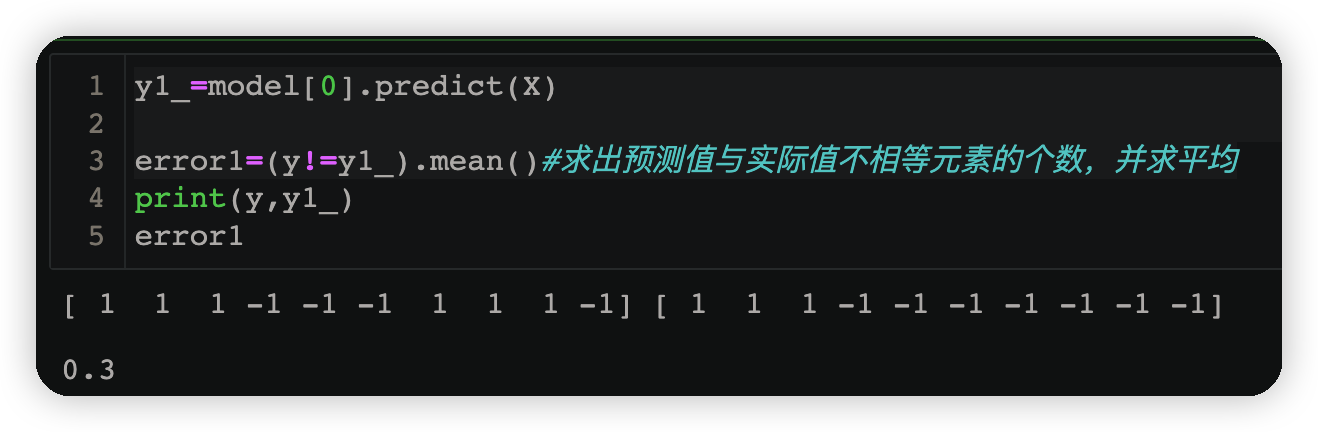
3.1.3求誤差
y1_=model[0].predict(X)#由v得到的預測結果小於v為1,大於v為-1
error1=(y!=y1_).mean()#求出預測值與實際值不相等元素的個數,並求平均
3.1.4計算第一個若學習器的權重

alpha_1=1/2*np.log((1-error1)/error1)

3.1.5 跟新樣本權重
#上一次權重的基礎上進行跟新
#y表示真是的目標值
#ht(X)表示當前若學習器預測的結果
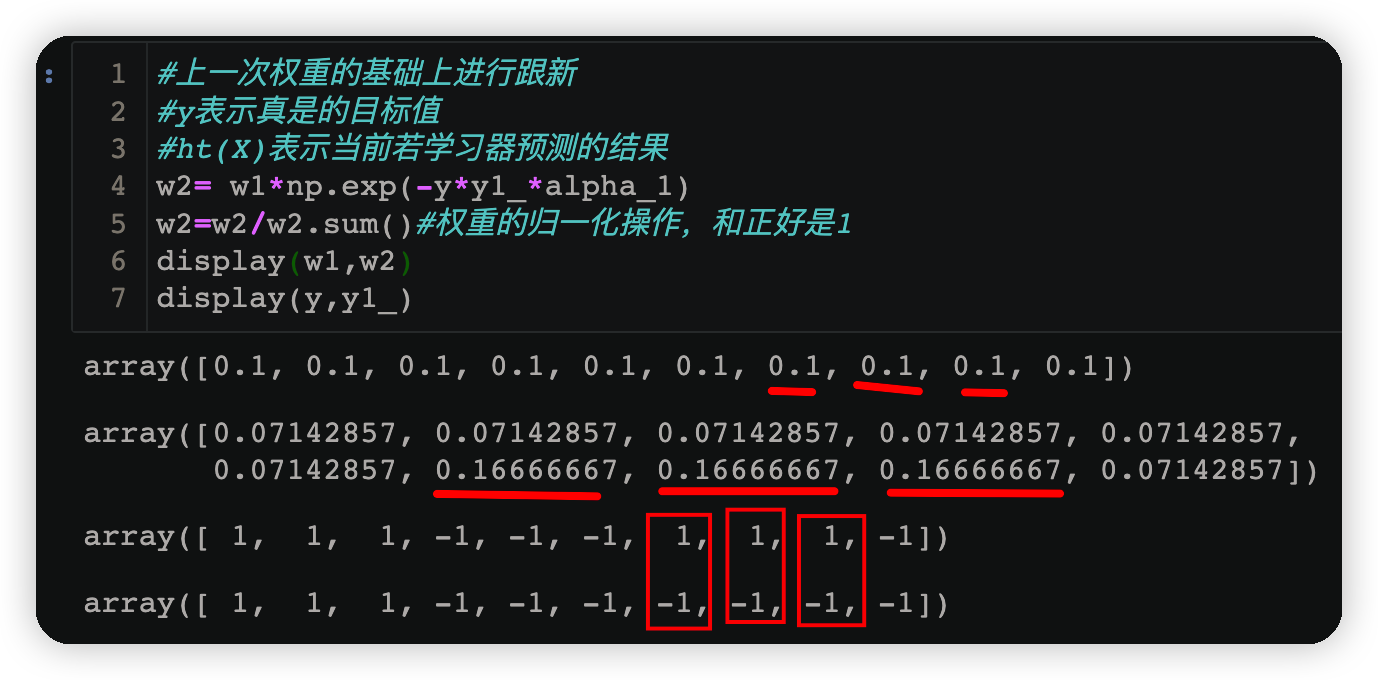
w2= w1*np.exp(-y*y1_*alpha_1)
w2=w2/w2.sum()#權重的歸一化操作,和正好是1
display(w1,w2)
display(y,y1_)
由下方執行結果可知當預測結果與原資料不相同時,該樣本對應的權值也會隨之增大;反之若預測正確則權值會減小
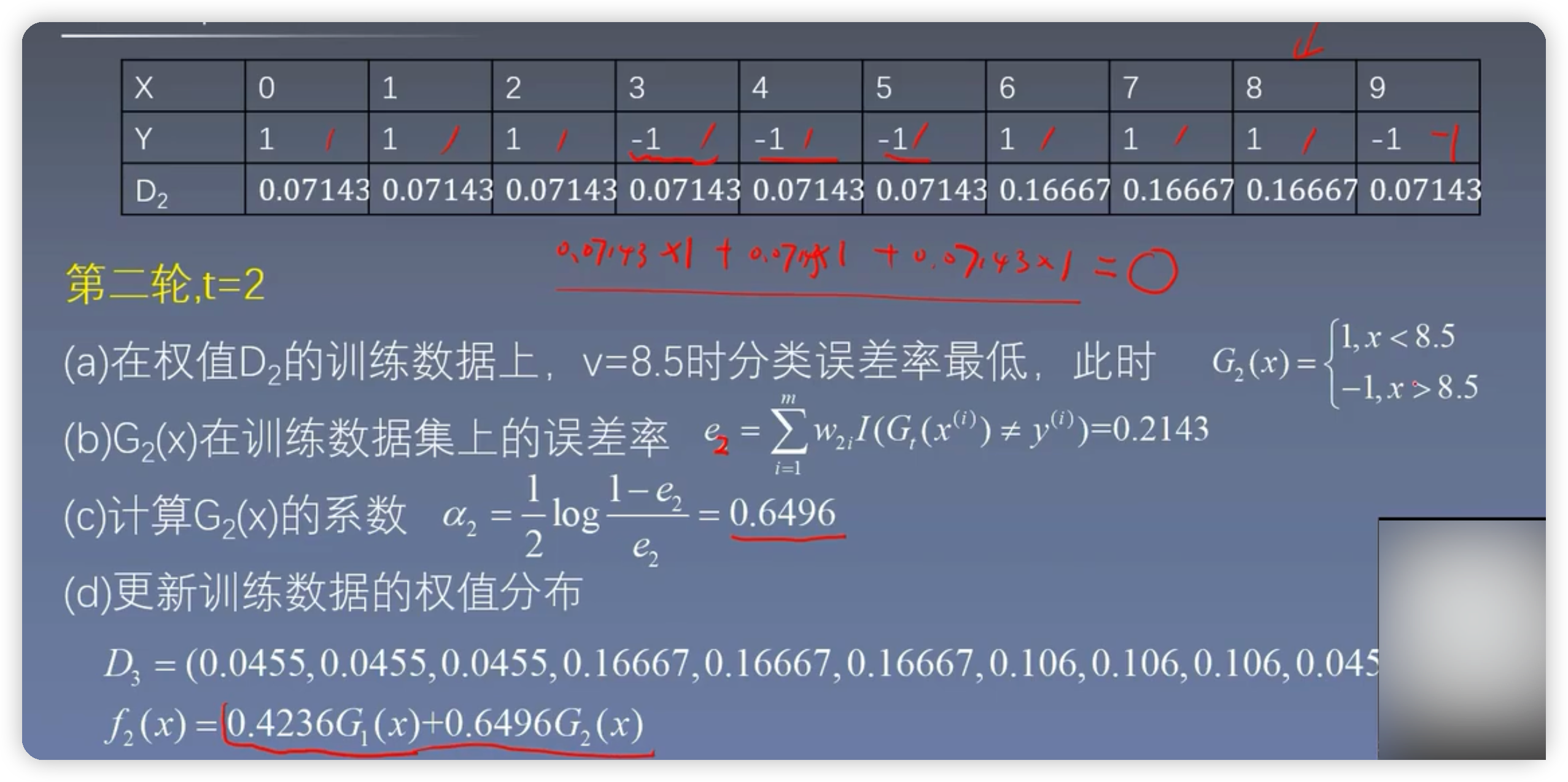
3.2第二輪的計算
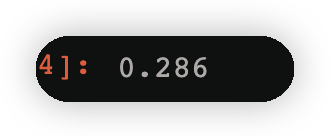
也即第二課數的計算cond=y==-1
np.round(w2[cond].sum(),3)#找到類別為-1的所有權值的和,四捨五入保留3位小數
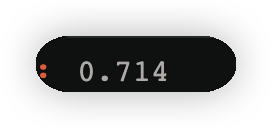
cond2=y==1
np.round(w2[cond2].sum(),3)
3.2.1 gini係數的計算
cond=y ==1 #類別1條件
p1 = w2[cond].sum()#使用新的樣本權重分佈
p2= 1-p1
display(p1,p2)
gini=p1*(1-p1)+p2*(1-p2)

3.2.2拆分的條件
gini_result=[]
best_split={}#最佳分裂條件,X[0]<=8.5
lower_gini = 1#比較
for i in range(len(X)-1):#陣列下標從0到9,10個資料一共要切九刀
split=X[i:i+2].mean()#裂開條件,就是假如一開始要將0和1裂開並取出
cond=(X<=split).ravel()#變成一維的,左邊資料
left=y[cond]
right=y[~cond]#取反
#left_p=cond.sum()/cond.size#這種方式計算概率適用於每個樣本的權重一樣
left_p = w2[cond]/w2[cond].sum()#歸一化,左側每個樣本在自己組內的概率
right_p=w2[~cond]/w2[~cond].sum()#歸一化,右側每個樣本在自己組內概率
#左右兩邊的gini係數
gini_left=0
gini_right=0
for j in np.unique(y):#y表示類別
cond_left=left==j#左側某個類別
p_left=left_p[cond_left].sum()#計算左邊某個類別的概率
gini_left += p_left*(1-p_left)
cond_right=right==j#右側某個類別
p_right=right_p[cond_right].sum()#計算右邊某個類別的概率
gini_right += p_right*(1-p_right)
#左右兩邊的gini係數合併
p1=cond.sum()/cond.size#左側劃分資料所佔的比例
p2=1-p1#右側劃分資料所佔的比例
gini=gini_left*p1 +gini_right*p2
gini_result.append(gini)
if gini <lower_gini:
lower_gini=gini
best_split.clear()
best_split['X[0]<=']=split
print(gini_result)
print(best_split)

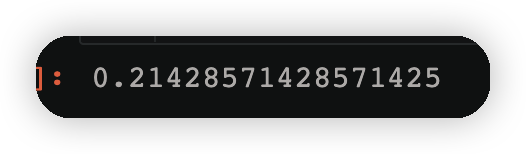
3.2.3計算誤差
y2_ = model[1].predict(X)#根據求出來的v得到預測的結果
error2=((y != y2_)*w2).sum()
error2
3.2.4計算第二個弱學習器權重
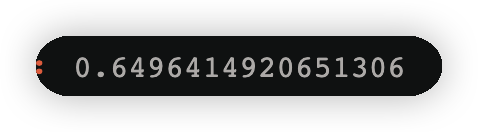
alpha_2=1/2*np.log((1-error2)/error2)
alpha_2
3.2.5跟新樣本權重
#上一次權重的基礎上進行更新
#y表示真是的目標值
#ht(X)表示當前若學習器預測的結果
w3= w2*np.exp(-y*y2_*alpha_2)
w3=w3/w3.sum()#權重的歸一化操作,和正好是1
display(w2,w3)
display(y,y2_)
3.3第三輪計算
3.3.1 gini係數
cond=y ==1 #類別1條件
p1 = w3[cond].sum()#使用新的樣本權重分佈
p2= 1-p1
display(p1,p2)
gini=p1*(1-p1)+p2*(1-p2)
gini

3.3.2拆分條件
gini_result=[]
best_split={}#最佳分裂條件,X[0]<=2.5
lower_gini = 1#比較
for i in range(len(X)-1):#陣列下標從0到9,10個資料一共要切九刀
split=X[i:i+2].mean()#裂開條件,就是假如一開始要將0和1裂開並取出
cond=(X<=split).ravel()#變成一維的,左邊資料
left=y[cond]
right=y[~cond]#取反
#left_p=cond.sum()/cond.size#這種方式計算概率適用於每個樣本的權重一樣
left_p = w3[cond]/w3[cond].sum()#歸一化,左側每個樣本在自己組內的概率
right_p=w3[~cond]/w3[~cond].sum()#歸一化,右側每個樣本在自己組內概率
#左右兩邊的gini係數
gini_left=0
gini_right=0
for j in np.unique(y):#y表示類別
cond_left=left==j#左側某個類別
p_left=left_p[cond_left].sum()#計算左邊某個類別的概率
gini_left += p_left*(1-p_left)
cond_right=right==j#右側某個類別
p_right=right_p[cond_right].sum()#計算右邊某個類別的概率
gini_right += p_right*(1-p_right)
#左右兩邊的gini係數合併
p1=cond.sum()/cond.size#左側劃分資料所佔的比例
p2=1-p1#右側劃分資料所佔的比例
gini=gini_left*p1 +gini_right*p2
gini_result.append(gini)
if gini <lower_gini:
lower_gini=gini
best_split.clear()
best_split['X[0]<=']=split
print(gini_result)
print(best_split)
3.3.3計算誤差
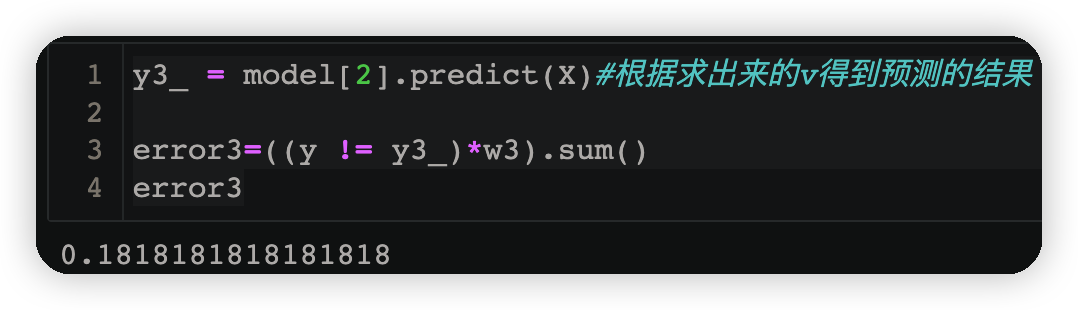
y3_ = model[2].predict(X)#根據求出來的v得到預測的結果
error3=((y != y3_)*w3).sum()
error3
3.3.4計算第三個弱學習器權重
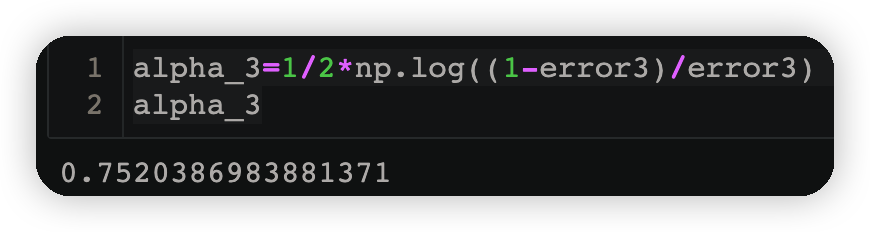
alpha_3=1/2*np.log((1-error3)/error3)
alpha_3
3.3.5跟新權重
#上一次權重的基礎上進行更新
#y表示真是的目標值
#ht(X)表示當前若學習器預測的結果
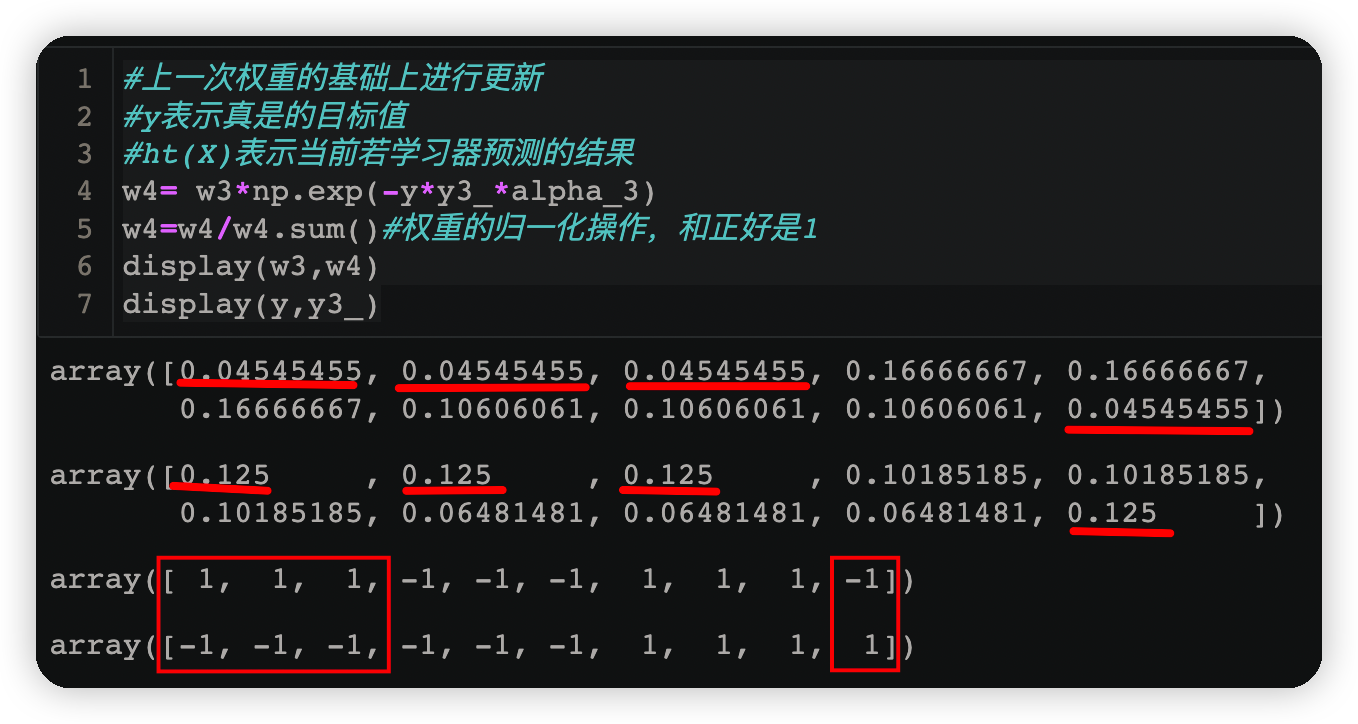
w4= w3*np.exp(-y*y3_*alpha_3)
w4=w4/w4.sum()#權重的歸一化操作,和正好是1
display(w3,w4)
display(y,y3_)
3.4弱學習器的聚合
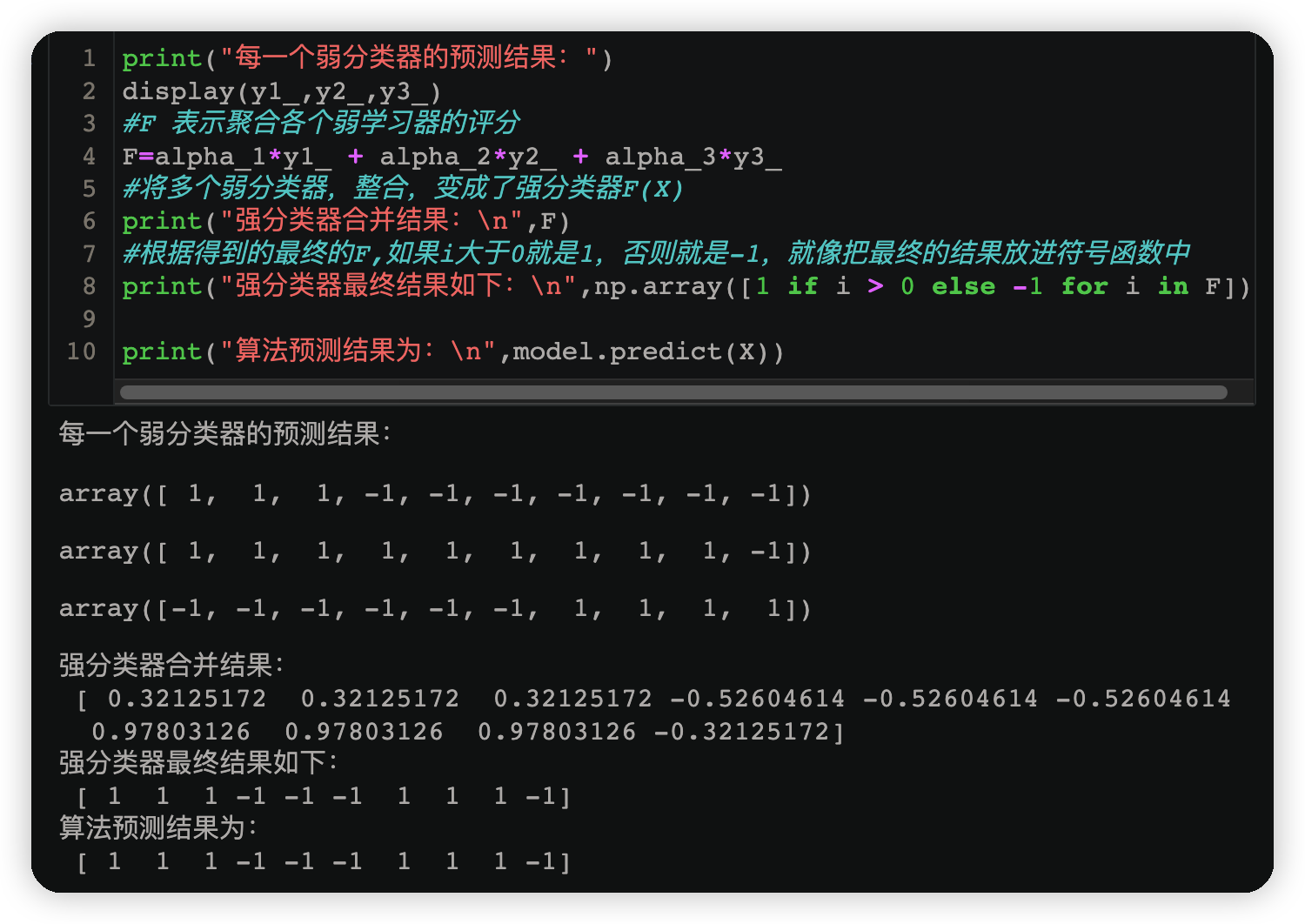
print("每一個弱分類器的預測結果:")
display(y1_,y2_,y3_)
#F 表示聚合各個弱學習器的評分
F=alpha_1*y1_ + alpha_2*y2_ + alpha_3*y3_
#將多個弱分類器,整合,變成了強分類器F(X)
print("強分類器合併結果:\n",F)
#根據得到的最終的F,如果i大於0就是1,否則就是-1,就像把最終的結果放進符號函數中
print("強分類器最終結果如下:\n",np.array([1 if i > 0 else -1 for i in F]))
print("演演算法預測結果為:\n",model.predict(X))