java中的垃圾回收演演算法與垃圾回收器
常用的垃圾回收演演算法
標記-清除
標記清除演演算法是一種非移動式的回收演演算法,分為標記 清除 2個階段,簡而言之就是先標記出需要回收的物件,標記完成後再回收掉所有標記的記憶體物件,如下圖

可見回收後圖中被標記的物件被刪除回收了,但是碎片化比較嚴重不連續 對於下次分配大物件的時候由於記憶體不連續性影響比較大,而且每一次Gc的時候需要執行2個操作 1次標記 1次回收
標記-整理壓縮
標記整理壓縮演演算法是一種移動式的演演算法,由於上面標記清除演演算法導致記憶體不連續的問題 標記-整理演演算法就解決了這個問題。

工作原理也是2階段操作而且更復雜了,首先找出(root)根地址的物件一直尋找標記是否被參照,參照了就標記一下,標記完成後把標記的物件按順序移動排列在一起並清除掉邊界的未標記的物件,這樣就沒有記憶體碎片。
缺點
- 由於標記完成後需要移動物件 移動的過程可能會產生STW
- 2次+調整指標
複製演演算法
複製演演算法更粗暴了,邏輯也很簡單 通常直接申明瞭2塊一樣大小儲存空間,每次只使用其中1塊空間,當使用的這塊空間不夠用的時候就觸發回收操作,將存活的物件copy到另一塊空間中按順序存放,可回收的就回收刪除掉,這樣一來就不會出現記憶體碎片,但是要多浪費50%的記憶體空間,主要用於年輕代 比如s0 s1亦是如此。
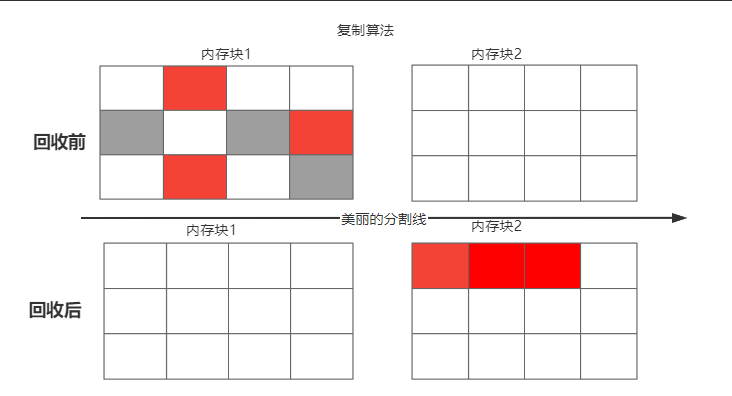
分代回收演演算法
根據物件的存活週期劃分為新生代、老年代。因此可以根據不同年代的特點使用不同的回收演演算法。分代收集目前是大部分JVM
-
新生代特點
在新生代中大量的物件產生 又有大量的物件需要銷燬,他們存活時間都比較短。基本上都是回收的時候大部分會被回收掉,只有少量的物件是存活不回收的。
存活物件少,垃圾物件多這就比較適合使用複製演演算法,複製演演算法需要用到2塊記憶體空間 每次只使用其中一塊,在jdk8中不只是單純的劃分為
s0s1二塊儲存空間,還新增了一塊Eden,s0 s1的預設大小是eden的8/1 這樣設計的目的在於每次觸發回收的時候把90(eden+其中1個s區)的區域中存活的物件copy到10%的儲存中,理論上清除了90%的空間,這樣做的好處就是不需要花50%的儲存空間,只浪費了10%的空間就實現了這個演演算法邏輯。 -
老年代特點
老年代的特點就是物件存活時間都比較長,大量的存活物件就不適合像新生代一樣用複製演演算法了 因為copy的成本太高,這種就比較適合標記清除演演算法,或者標記清除整理演演算法。
優缺點概述
演演算法名稱 優點 缺點 標記-清除 簡單 位置不聯絡 碎片化嚴重 效率低 2次掃描 標記-壓縮整理 沒有碎片 效率低 2次掃描 可能會多次重置指標 複製演演算法 沒有碎片 簡單高效 浪費空間
垃圾回收器
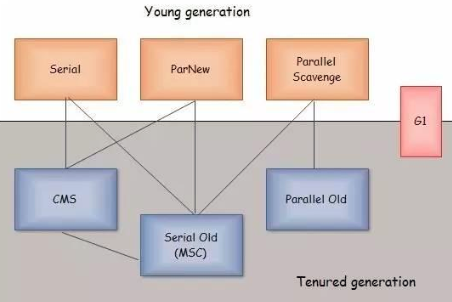
上面的垃圾演演算法僅僅只是一個理論上的演演算法 ,正在實現這些演演算法的叫垃圾回收器,在工作中具體是怎麼回收工作的可以不關心,但是需要了解不同的垃圾回收器是基於哪種演演算法實現的,有助於出現效能問題的時候有思路去引數調優,而不是盲目的問度娘。各個年輕代 老年代垃圾回收器可組合配對方式如下圖所示

serial序列收集器
serial回收器是一個序列單執行緒回收器,在進行垃圾回收的時候必須暫停使用者工作執行緒,直到回收執行緒處理完成,每次回收必然會STW。比較適合跑在client端應用

ParNew收集器
ParNew回收器是新生代垃圾回收器, 就是serial的多執行緒版本 其它基本上serial差不多的,在ps回收器沒有出來之前parNew+cms是伺服器端首選
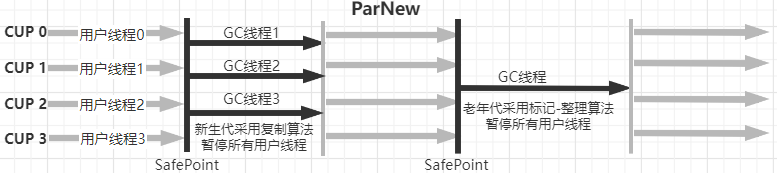
Parallel Scavenge收集器
常說的ps 收集器就算它,ps是一個新生代收集器採用複製演演算法,多執行緒並行收集。是jdk8的預設新生代回收器。
看起來和parNew有點一樣 反正效能就是比它要強,在應用吞吐量方面更優秀。ps一般是和Parallel Old配合使用

Serial Old收集器
Serial Old收集器是Serial的老年代版本,同樣它也是單執行緒收集,基於標記-整理演演算法,工作原理可以參考serial。
Parallel Old收集器
parallel old收集器是ps的老年代版本 是多執行緒收集器 基於標記-整理演演算法 彌補了serial old單執行緒的不足,工作原理參考ps收集器工作流程圖。ps+po是jdk8預設的組合 也是我在專案中實踐最多的組合。
CMS收集器
cms從jdk1.4開始引入,算是里程碑GC產品,開啟了Java領域並行(注意並行與並行parallel的區別 並行是值回收垃圾的時候和使用者執行緒一起幹活,並行是指多個GC執行緒同時回收 )回收的方案。是一個優秀的老年代垃圾回收器。
cms從名字就能看出來是基於並行的 標記-清除演演算法實現的回收器,它的回收流程分為 初始標記-並行標記-重新標記-並行清除 4個階段。
- 初始標記 (initial mark)
只是標記GC Root 根物件 會stw 但是由於只是標記了gc roots 所有很快 - 並行標記
根據第1階段的結果繼續往下標記 這個階段是並行的 不影響使用者執行緒 - 重新標記
為什麼會有重新標記這個階段?是因為並行標記的時候 由於使用者執行緒還在執行 可能產生了新的垃圾 所以需要在標記一次,當然由於第2階段標記過一次了,這一次理論上會很快 這個階段會STW - 並行清除
清理需要回收的物件 不影響使用者執行緒使用。cms有個開關(-XX:CMSFullGCsBeforeCompaction=0)預設是開啟碎片整理,由於cms清理後的空間也是有碎片存在的,所以一次清理就會整理一次碎片。此階段使用者執行緒同樣會產生新的垃圾 目前沒有解決清除 網上叫為浮動垃圾。
所以cms只有在並行標記和並行清除階段是不影響使用者執行緒停頓的。初始標記 和 重新標記 也是劃分的區域標記的,總體上能跟控制gc停頓時間 提高使用者體驗,工作原理如下
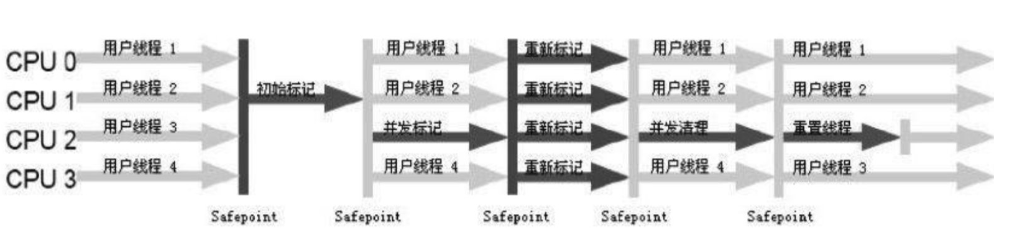
當老年代記憶體使用到92%(-XX:CMSInitiatingOccupancyFraction=92)之後出觸發cms回收一次,如果cms在回收期間中 剩餘的記憶體不夠使用者工作執行緒使用了(報異常Concurrent Mode Fail) 那麼serial old回收器就成了緊急替補隊員立即進行回收一次,當然停頓的時間就更長了。由於cms部分階段是使用者執行緒和gc執行緒一起工作,如果啟動閾值設定得太高,容易導致使用者工作執行緒不夠用觸發cmf異常,效能反而降低。
G1收集器
G1垃圾回收器可以同時支援年輕代、老年代,G1並沒有在物理分割區隔離,上面的提到的垃圾回收器都是物理上進行分割區的,G1是由一塊一塊大小相同的region組成,雖然沒有物理上進行分割區,但是依然保留了年輕代 老年代的概念。回收流程有點類似cms。也是分為初始標記、並行標記、最終標記、篩選回收 4個階段。
Region的大小可以通過G1HeapRegionSize引數進行設定,其必須是2的冪,範圍允許為1Mb到32Mb。基於堆記憶體的初始值和最大值的平均數計算分割區的尺寸,平均的堆尺寸會分出約2000個Region。分割區大小一旦設定,則啟動之後不會再變化。region之間採用複製演演算法,因此不容易產生記憶體碎片。每個Region都有一個Remembered Set。當對參照進行寫操作的時候,G1檢查該參照的物件是否在別的region中,是的話,則通過CardTable把相關參照資訊存到被參照物件的Remembered Set中。當進行記憶體回收時,把RememberSet加入到GC Roots根節點的列舉範圍。這樣就可以保證不全堆掃描也不會有遺漏。 記憶體結構如下

- Survivor regions(年輕代-Survivor區)
- Old regions(老年代)
- Humongous regions(巨型物件區域) 佔用了Region容量的50%以上物件 巨型物件比較大 一般在並行標記階段如果可以回收就直接回收了。
- Free resgions(未分配區域,也會叫做可用分割區)-上圖中空白的區域
G1之所以這裡厲害在於它用到了一些資料結構的技巧
TLAB(Thread Local Allocation Buffer)本地執行緒緩衝區
PLAB(Promotion Local Allocation Buffer) 晉升本地分配緩衝區
Collecion Sets(CSets)待收集集合
Card Table 卡表
Remembered Sets(RSets)已記憶集合
回收流程大致如下
-
初始標記
只是標記GC Roots根物件 會stw
-
並行標記
從上一步標記的GC Roots開始計算可達性分析並標記 這階段耗時但是是並行的 不影響使用者執行緒使用
-
最終標記
上一步執行的過程中產出的變動再一次計算和標記 會stw 短暫的停頓,JVM將這段時間物件變化記錄到Remembered Set Log中,在最終標記階段把Remembered Set Log合併到Remembered Set中。 -
篩選回收
為什麼多了一步篩選再回收,在於G1在收集的時候會優先回收比較有價值的region區域,垃圾物件比較多 存活物件比較少的region就算是有價值的 這樣就能有效的提高回收效率。因為優先回收掉有價值的region而不是一下全部把堆中的全部垃圾回收完,所以回收的時間基本上能夠把控。這個階段是並行操作但是會有短暫的STW基本感知不到。
JDK10 之前的G1中的GC只有YoungGC,MixedGC。FullGC處理會交給單執行緒的Serial Old垃圾收集器。
zgc收集器
Shenandoah
轉載請註明出處。
作者:peachyy
出處:http://www.cnblogs.com/peachyy/
出處:https://peachyy.gitee.io/
出處:https://peachyy.github.io/
公眾號: 