LabVIEW開放神經網路互動工具包【ONNX】,大幅降低人工智慧開發門檻,實現飛速推理
前言
前面給大家介紹了自己開發的LabVIEW AI視覺工具包
一、工具包內容
這個開放神經網路互動工具包主要優勢如下:
-
簡單程式設計:圖形化程式設計,無需掌握文字程式設計基礎即可完成機器視覺專案;
-
提供多種框架生成的onnx模型匯入模組:包括pytorch、caffe、tensorflow、paddlepaddle等生成的onnx模型;
-
多種高效加速推理介面:CUDA、TensorRT對模型進行最大化的加速;
-
支援多種硬體加速:支援Nvidia GPU、Intel、TPU、NPU多種硬體加速
-
提供近百個應用程式範例:包括物體分類、物體檢測、物體測量、影象分割、 臉部辨識、自然場景下OCR等多種實用場景
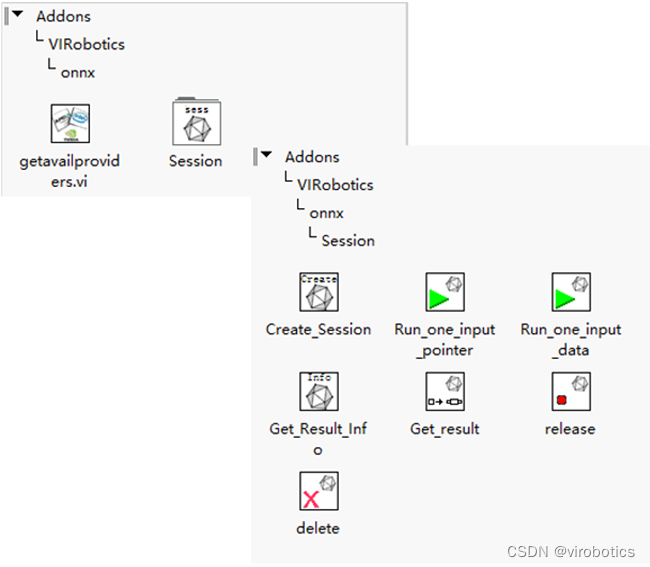
工具包中的函數選版如下:
例如,一個攝像頭採集並進行yolov5目標檢測的範例程式,只需在LabVIEW中編寫簡單的圖形化程式,即可實現。在大量簡化程式設計難度的同時,也保持了c++的高效執行特性。
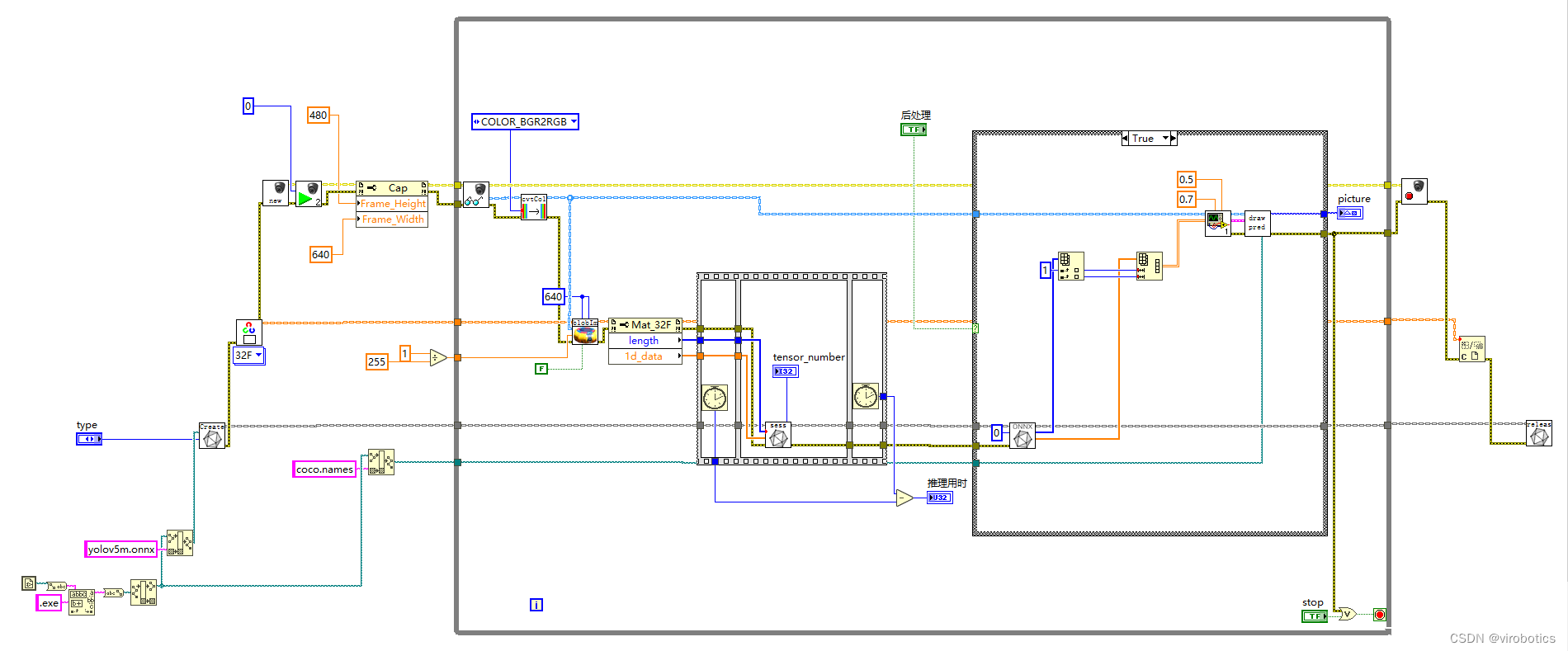
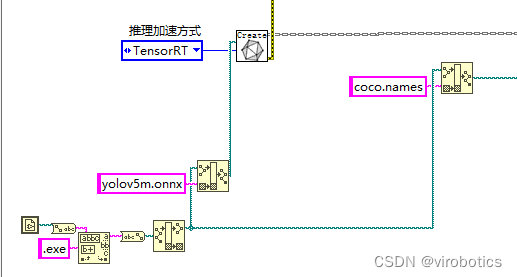
通常我們做專案,在部署過程中想要加速,無非就那麼幾種辦法,如果我們的裝置是CPU,那麼可以用openvion,如果我們希望能夠使用GPU,那麼就可以嘗試TensorRT了。那麼為什麼要選擇TensorRT呢?因為我們目前主要使用的還是Nvidia的計算裝置,TensorRT本身就是Nvidia自家的東西,那麼在Nvidia端的話肯定要用Nvidia親兒子了。
不過因為TensorRT的入門門檻略微有些高,直接勸退了想要入坑的玩家。其中一部分原因是官方檔案比較雜亂;另一部分原因就是TensorRT比較底層,需要一點點C++和硬體方面的知識,學習難度會更高一點。我們做的開放神經網路互動工具包GPU版本,直接將TensorRT一起整合到了onnx_session中,可以載入任何onnx模型,可以使用CUDA或者TensorRT加速,實現高效的推理
二、工具包下載連結
三、工具包安裝步驟
詳細安裝步驟可檢視:
四、實現物體識別
無論使用何種框架訓練物體檢測模型,都可以無縫整合到LabVIEW中,並使用工具包提供的CUDA、tensorRT介面實現加速推理,模型包括但不限於:
-
yolov5、yolov6、yolov7、pp-yoloe、yolox
-
torchvision中的影象分類、目標檢測模型等
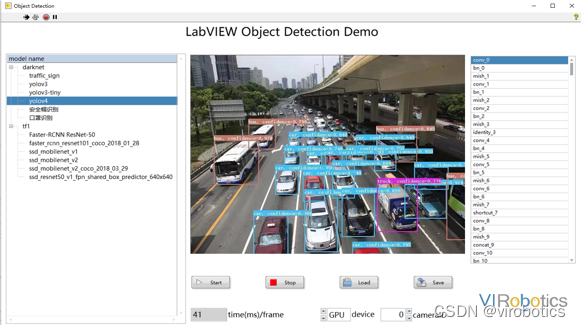
通過演演算法優化,在LabVIEW中執行模型的速度明顯好於python,這對於對效能要求較高的工業現場來說非常友好實用。比如說:工地安全帽檢測、物體表面缺陷檢測等,如下圖進行物體識別,在GPU模式下,無論是執行速度和識別率都可以達到工業級別。
-
yolov4實現目標檢測:
-
基於onnx,yolov5使用tensorRT實現推理加速:
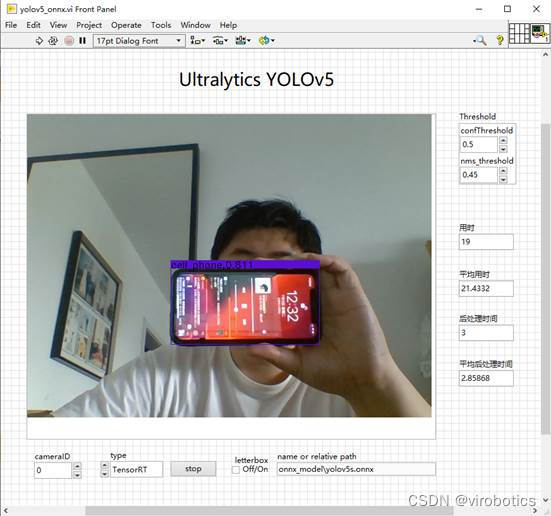
-
NI vision採集影象、tensorRT加速實現yolov5目標檢測
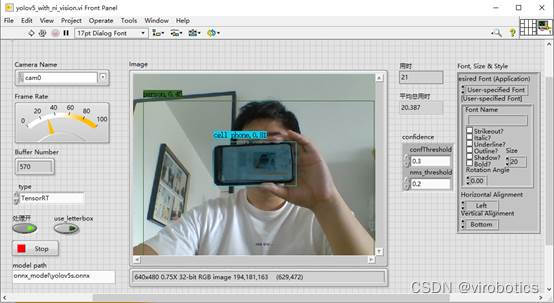
-
yolov5實現口罩檢測:
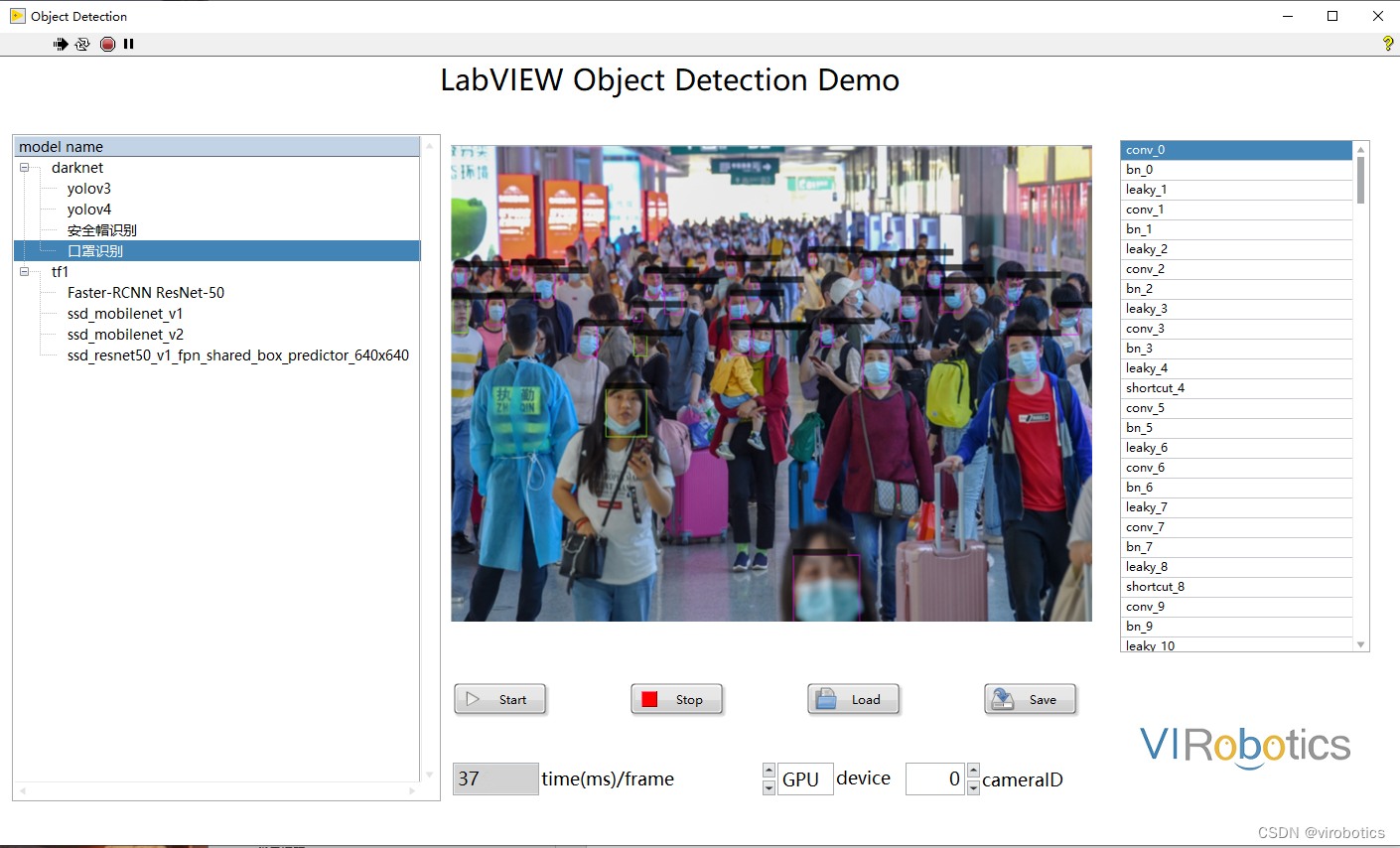
-
yolov5實現安全帽檢測:
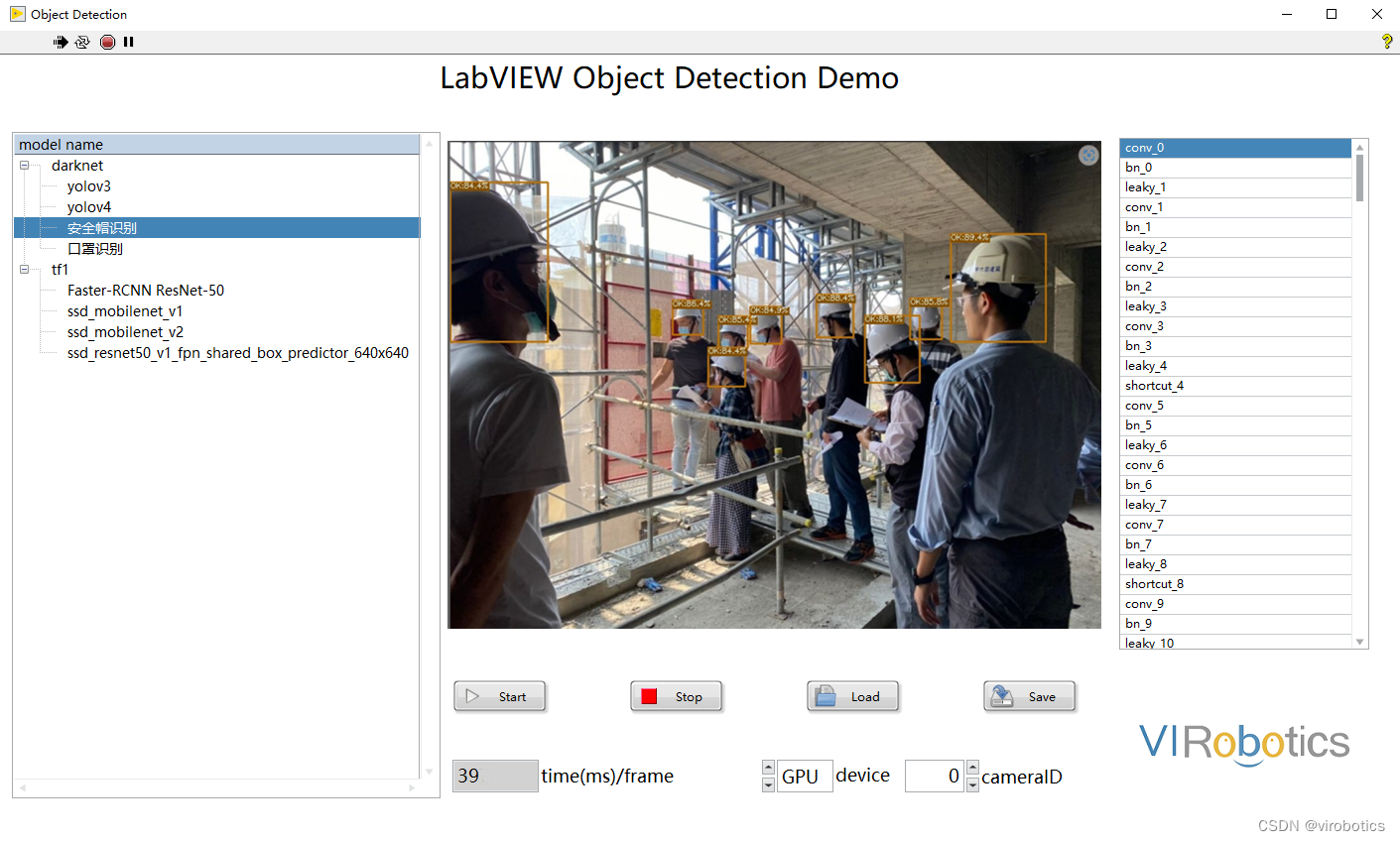
-
yolov6實現目標檢測:
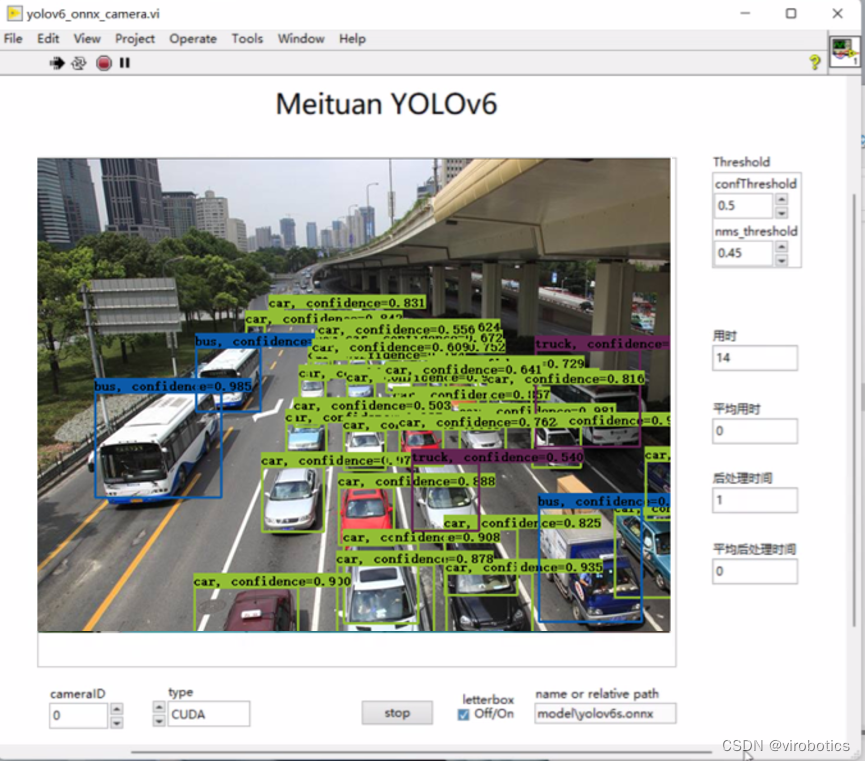
-
yolox實現目標檢測:
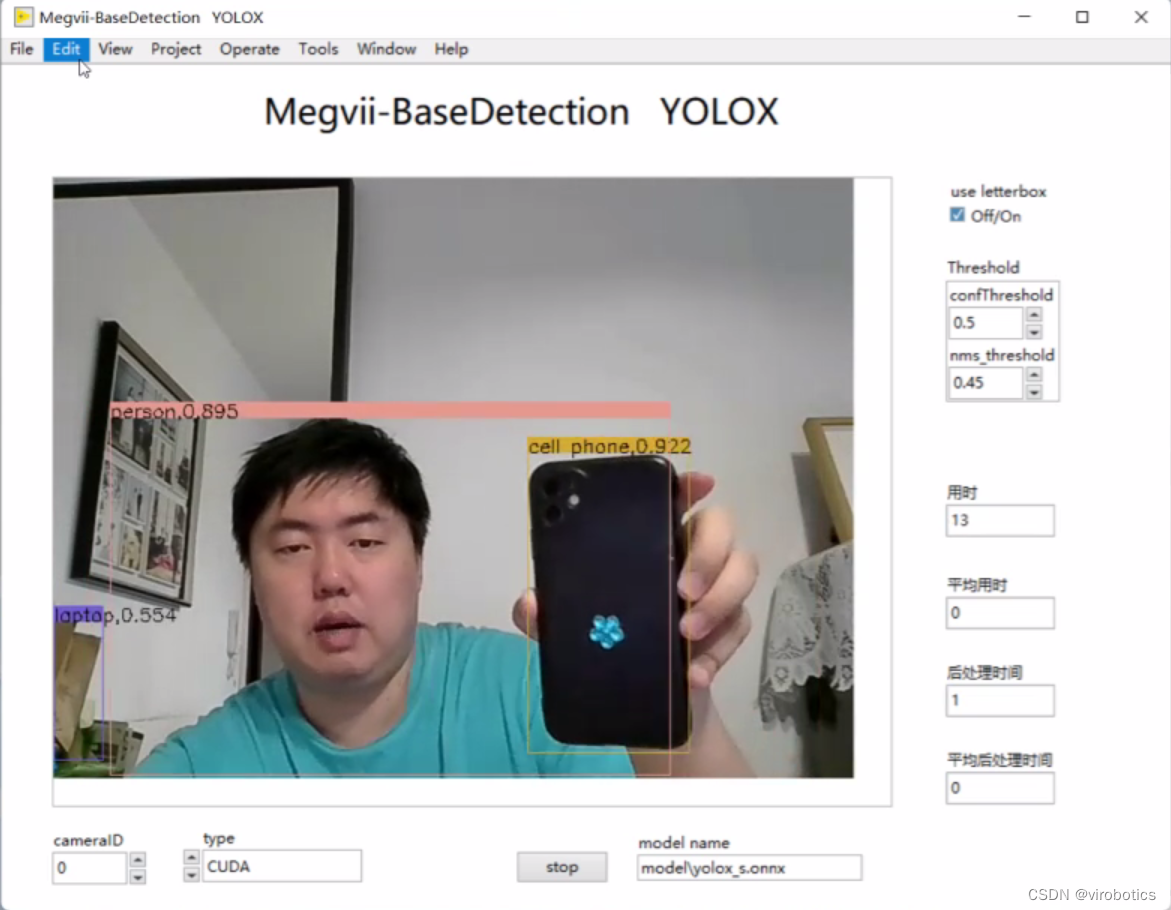
-
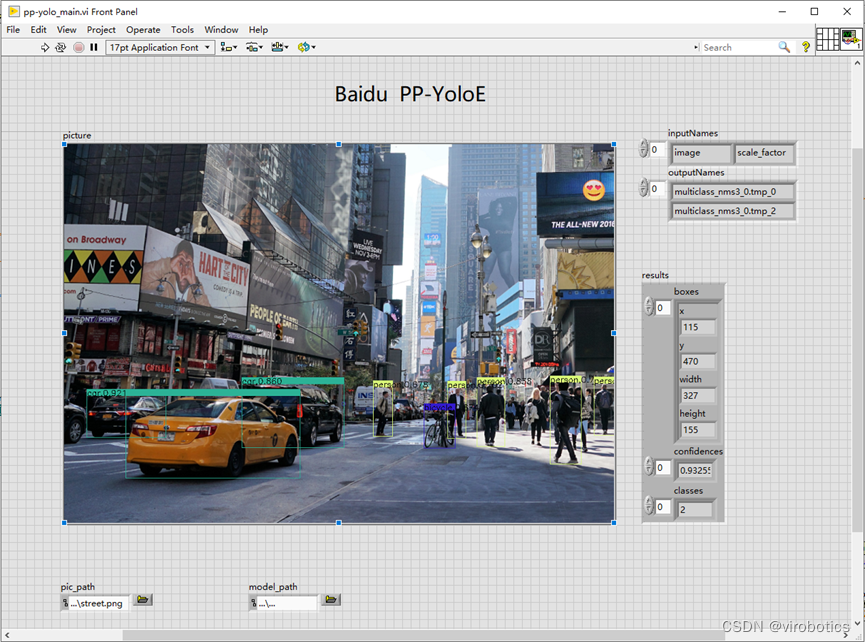
百度PP-YOLOE實現目標檢測:
五、實現影象分割
影象分割是當今計算機視覺領域的關鍵問題之一。從宏觀上看,影象分割是一項高層次的任務,為實現場景的完整理解鋪平了道路。場景理解作為一個核心的計算機視覺問題,其重要性在於越來越多的應用程式通過從影象中推斷知識來提供營養。隨著深度學習軟硬體的加速發展,一些前沿的應用包括自動駕駛汽車、人機互動、醫療影像等,都開始研究並使用影象分割技術。
本次整合的工具包提供了多種影象分割的呼叫模組,並實現了GPU模式下TensorRT的加速執行。如: 語意分割:Segnet、deeplabv1~deeplabv3、deeplabv3+、u-net等; 範例分割:Mask-RCNN、PANet等 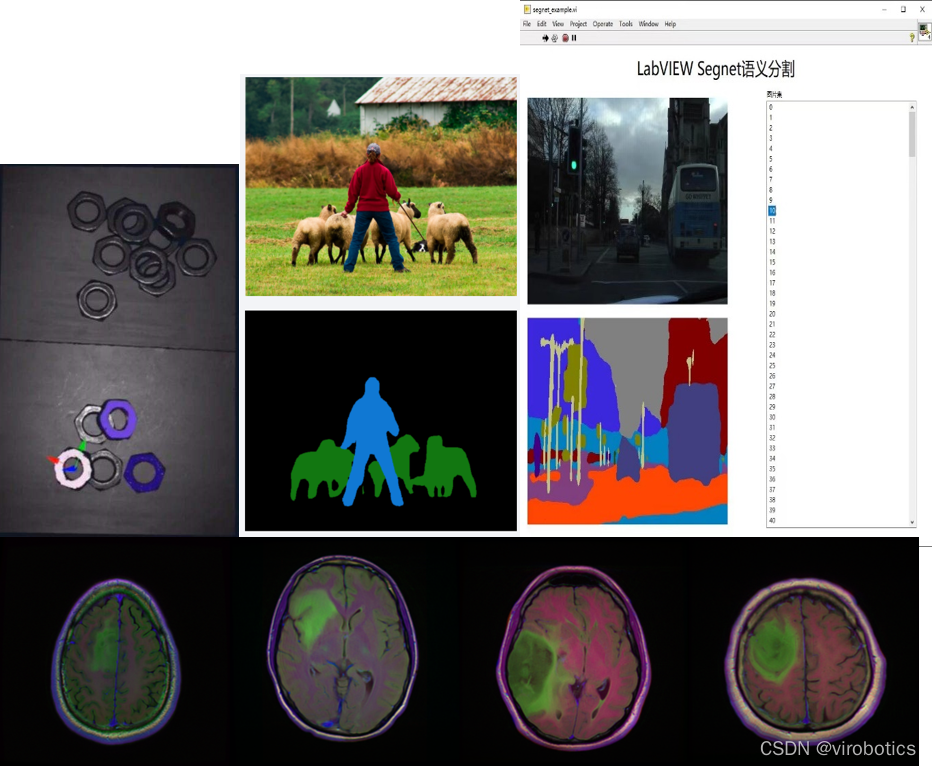
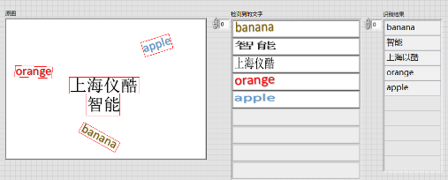
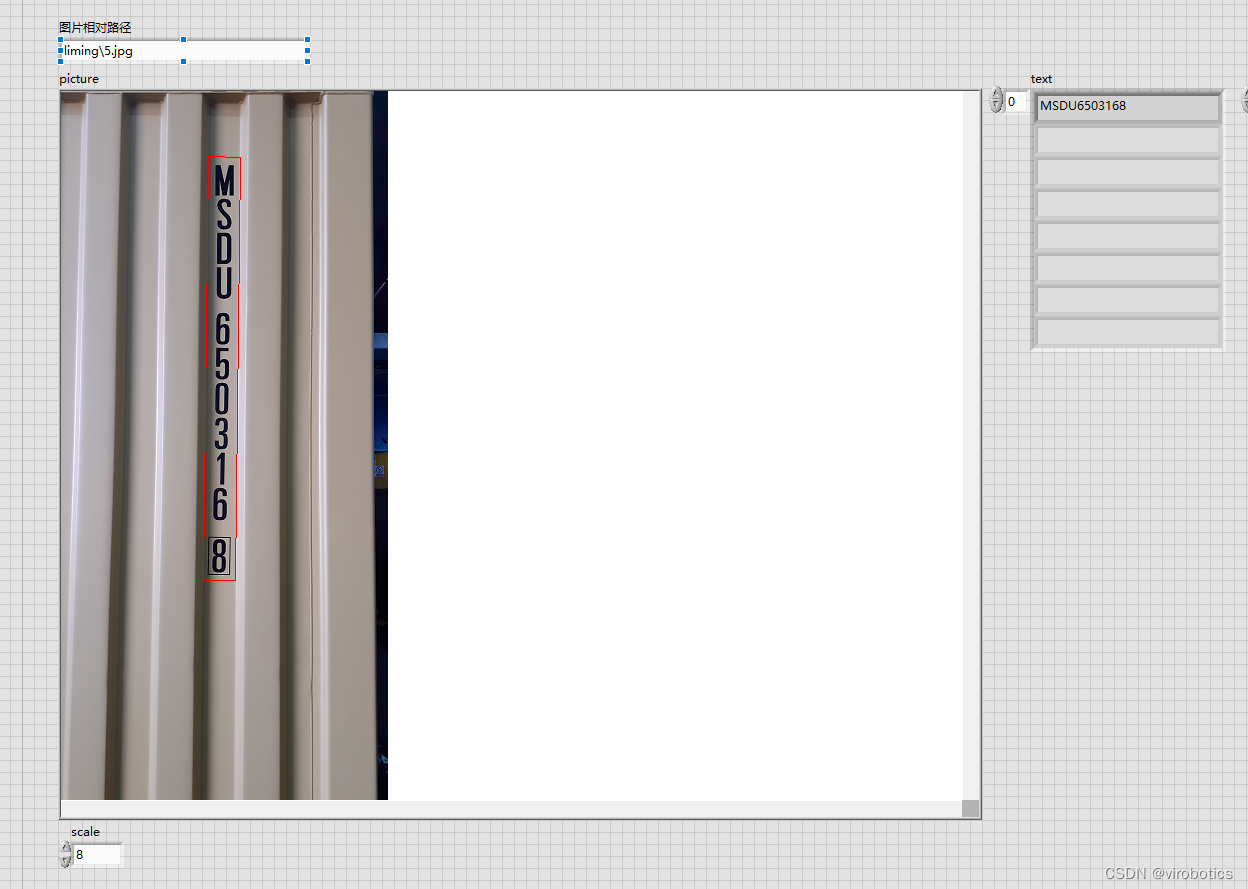
六、自然場景下的文字識別
工具包提供了文字檢測定位(DB_TD500_resnet50、EAST)、文字識別的模組(CRNN),使用者可以使用該模組實現自然場景下的中英文文字識別
應用:身份證識別、表單識別、包裝盒標籤檢測等

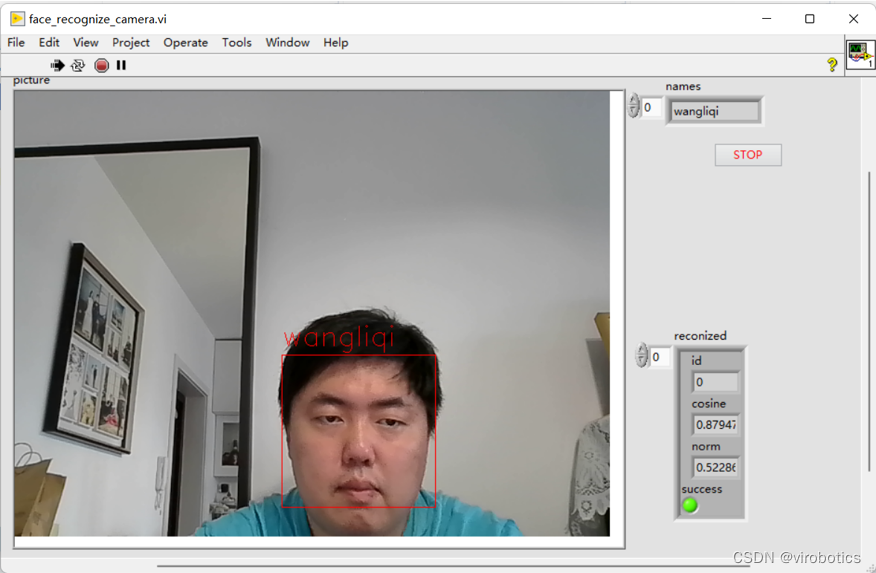
七、人臉檢測與識別
八、人體關鍵點檢測
人體骨骼關鍵點對於描述人體姿態,預測人體行為至關重要。因此人體骨骼關鍵點檢測是諸多計算機視覺任務的基礎,例如動作分類,異常行為檢測,以及自動駕駛等等。近年來,隨著深度學習技術的發展,人體骨骼關鍵點檢測效果不斷提升,已經開始廣泛應用於計算機視覺的相關領域。 本次整合的工具包提供了關鍵點檢測的呼叫模組,並實現了GPU模式下TensorRT的加速執行。

總結
工具包的具體使用可以關注博主的後續部落格,如果有問題可以在評論區裡討論,提問前請先點贊支援一下博主哦 更多問題可新增技術交流群進行進一步的探討。qq群號:705637299,,進群請備註暗號:LabVIEW機器學習