並行程式設計之執行緒池
執行緒池
為什麼需要執行緒池?
如果效能允許的話,我們完全可以在 for 迴圈程式碼起很多的執行緒去幫我們執行任務,程式碼如下
public class ManyThread {
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
Thread thread = new Thread(new Task(), "thread" + i);
thread.start();
}
}
}
class Task implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + ":正在執行");
}
}
由上述程式碼來看,我們仍然可以通過以上這種笨拙的方式實現相關的需求。但這樣明顯是不合適的,如果頻繁地建立過多的執行緒來執行任務,這樣開銷實在太大,畢竟過多的執行緒會佔用太多的記憶體;但是通過執行緒池這種方式,建立固定數量的執行緒來執行任務,就能夠使執行緒複用起來,加快響應速度,並且還合理利用CPU和記憶體,還統一管理。
構造引數
| 引數名 | 型別 | 含義 |
|---|---|---|
| corePoolSize | int | 核心執行緒數 |
| maxPoolSize | int | 最大執行緒數 |
| keepAliveTime | long | 保持存活時間 |
| workQueue | BlockingQueue | 任務儲存佇列 |
| threadFactory | ThreadFactory | 當執行緒池需要新的執行緒的時候,會使用 threadFactory 來生成新的執行緒 |
| Handler | RejectedExecutionHandler | 由於執行緒池無法接受新提交的任務所指向的拒絕策略 |
-
corePoolSize : 核心執行緒數:執行緒池在完成初始化後,預設情況下,執行緒池中並沒有任何執行緒,執行緒池會等待有任務到來時,再建立新執行緒去執行任務。
-
maxPoolSize : 最大執行緒數:在 corePoolSize 的基礎上,會額外地增加一些執行緒,但是這些新增加的執行緒有一個上限,也就是執行緒的最大量。
-
keepAliveTime : 存活時間,如果執行緒池當前的執行緒數多於 corePoolSize,那麼如果多餘的執行緒空閒時間超過 keepAliveTime,它們就會被終止。
-
ThreadFactory: 新的執行緒是由 ThreadFactory 建立的,預設使用 Executors.defaultThreadFactory() 建立,建立出來的執行緒都在同一個執行緒組,擁有相同優先順序,但是不屬於守護執行緒。
-
workQueue: 常見的三種佇列型別
SynchronousQueue : 直接交接:在任務不多的情況下,只是通過佇列做簡單的中轉站;當進來一個新的任務,就會直接建立一個新的執行緒處理。這種佇列本身沒有容量的,裡面沒有辦法存放任務,如果要使用該佇列,maxPoolSize要設定相對大點,因為沒有佇列作為緩衝,會經常建立執行緒
LinkedBlockingQueue :無界佇列,特指的是未指定容量的前提下,(如果在設定了指定容量的情況下,就是有界佇列);當corePoolSize已經滿的情況下,任務就會新增到這個佇列裡面來,而且是沒有容量限制的,所以 maxPoolSize 設定任何值都不會起作用。如果新增任務的時間遠遠大於執行緒執行的時間,會佔用大量的記憶體,可能會導致OOM的發生
ArrayBlockQueue :有界佇列,可以設定預設大小,如果執行緒數等於(或大於)corePoolSize 但少於maxPoolSize,則將任務放入該有序佇列。
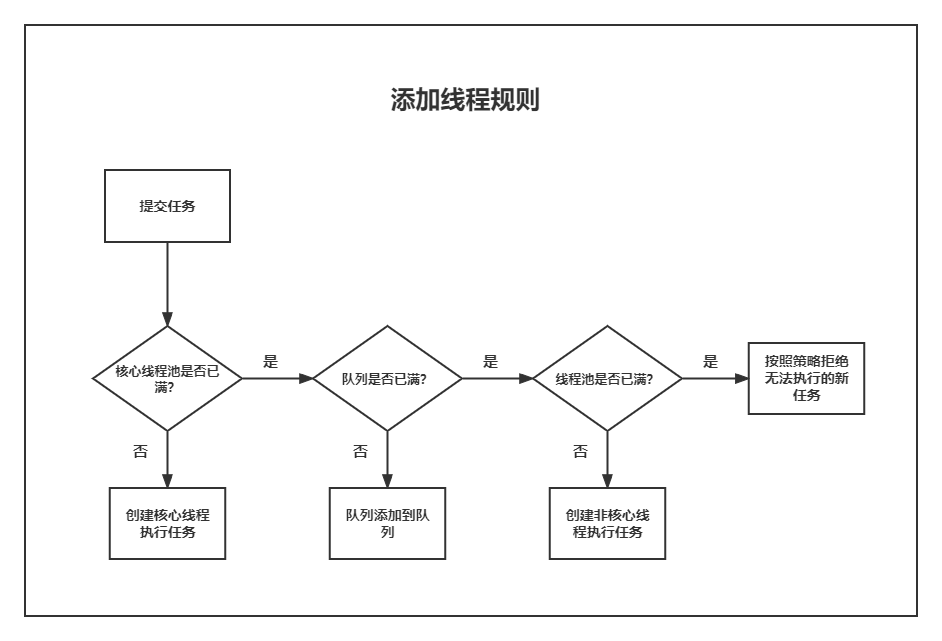
新增執行緒規則
-
如果執行緒數小於 corePoolSize ,即使其他工作執行緒處於空閒狀態,也會建立一個新執行緒來執行新任務。
-
如果執行緒數等於(或大於)corePoolSize 但少於maxPoolSize,則將任務放入佇列。
-
如果佇列已滿,並且執行緒數小於 maxPoolSize,則建立一個新執行緒來執行剛提交的任務
-
如果任務佇列沒有滿,執行緒池內執行的一直都是 corePoolSize 這個執行緒
-
如果佇列已滿,並且執行緒數大於或等於 maxPoolSize ,則拒絕該任務。
常見的ThreadPool
-
newFixedThreadPool:
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
通過原始碼,我們不難看出 corePoolSize 和 maxPoolSize 使用都是傳進來的 nThread 引數,說明建立的執行緒永遠不會超過 nThread 的範圍,然後就是 keepAliveTime 被設定為 0L,由於 maxPoolSize 和 corePoolSize 一樣大,所以在這該引數的設定是沒有意義的,然後 TimeUnit.MILLISECONDS 是時間單位,與 keepAliveTime 繫結;最後一個是 LinkedBlockingQueue ,儲存更多工的一個容器,所以無論再多的任務進來,都會放入到該佇列中執行。
由於傳進去的LinkedBlockingQueue 是沒有容量上限的,所以當請求數越來越多,並且無法及時處理完畢的時候,也就是請求堆積的時候,會容易造成佔用大量的記憶體,可能會導致OOM。
-
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
跟 newFixedThread 的原理基本一樣,用的是相同的工作佇列,預設把執行緒數直接設定成了1,所以會導致同樣的問題,也就是請求堆積的時候,會容易造成佔用大量的記憶體
-
CachedThreadPool:
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }可快取執行緒池,用了 synchronous queue 佇列,不需要儲存任務,有任務進來直接建立執行緒,具有自動回收多餘執行緒的功能。但是這個執行緒池存在一種弊端,在預設情況下,maxPoolSize 被設定為 Integer.MAX_VALUE,這可能會建立非常多的執行緒,甚至導致OOM。(注意:Cache 特指的是對執行緒的快取,如果一段時間執行緒空閒,就回收)
-
ScheduleThreadPool:支援定時及週期性任務執行的執行緒池
插曲
執行緒數量設定多少比較合適?
答:執行緒數 = CPU 核心數 * ( 1 + 平均等待時間/平時工作時間 )
關閉執行緒池
- shutdown:執行之後並不會停止,而是會把存量的任務都執行完畢。
- shutdownNow:立即停止執行緒,並且佇列的任務也不會執行。
拒絕策略
拒絕的時機是最大執行緒數滿
- AbortPolicy:預設的拒絕策略,直接丟擲異常
- DiscardPolicy:直接丟棄,提交執行緒不會收到任何資訊
- DiscardOldestPolicy:丟棄在佇列中等待時間最長的任務
- CallerRunsPolicy:由提交執行緒執行任務,是一種負反饋機制
執行緒池實現任務複用的原理
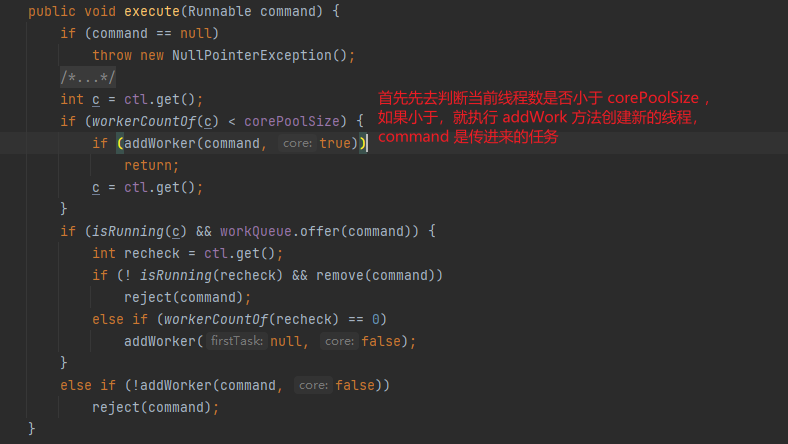
核心原理是用相同的執行緒去執行不同的任務。首先 execute 方法先去檢查當前執行緒數是否小於 corePoolSize ,如果小於的話,則執行 addWork 加一個工作執行緒,然後會執行 runWork 方法,該方法先會獲取一個任務 task ,這個 task 是 Runnable 範例,並且while迴圈中判斷這個任務是否為空,最後直接 task 呼叫 run 方法
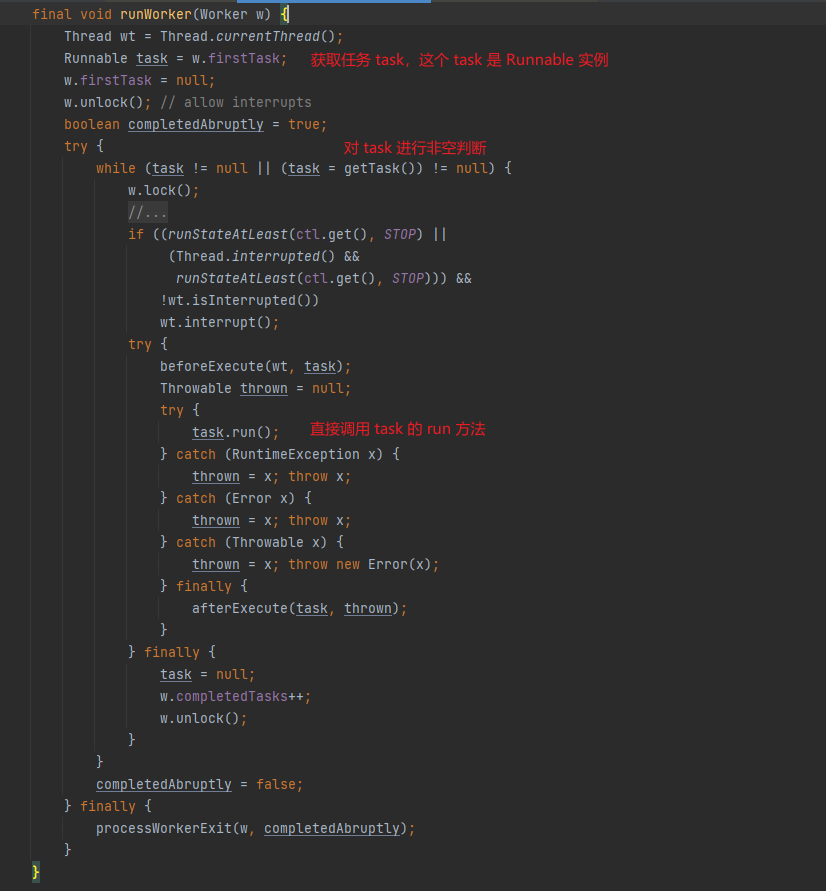
在runWork方法中,會將一個個 Runnable 範例 (也就是 task) 給拿到,然後直接呼叫 run 方法

面試題:submit 和 execute 的區別
(1)型別
execute只能接受Runnable型別的任務
submit不管是Runnable還是Callable型別的任務都可以接受,但是Runnable返回值均為void,所以使用Future的get()獲得的還是null
(2)返回值
由Callable和Runnable的區別可知:
execute沒有返回值
submit有返回值,所以需要返回值的時候必須使用submit
(3)異常
1.execute中丟擲異常
execute中的是 Runnable 介面的實現,所以只能使用 try、catch 來捕獲 CheckedException,通過實現UncaughtExceptionHander 介面處理 UncheckedException
即和普通執行緒的處理方式完全一致
2.submit中丟擲異常
不管提交的是Runnable還是Callable型別的任務,如果不對返回值Future呼叫get()方法,都會吃掉異常